Flink 介绍(特性、概念、故障容错、运维部署、应用场景)
概述
Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态计算的框架,Flink 自底向上在不同的抽象级别提供了多种 API,并且针对常见的使用场景开发了专用的扩展库。Flink能所有常见的集群环境中运行,并能以内存速度和任意规模进行计算。
特性
- 正确性保证:通过Exactly-once状态一致性、事件时间处理和成熟的迟到数据处理机制保证结果的正确性。
- 分层API:SQL分别处理流和批、DataStream API & DataSetAPI 和 ProcessFunction(time & state)
- 聚焦运维:灵活部署、高可用、保存点
- 大规模计算:水平扩展架构、支持超大状态、增量检查点机制
- 性能卓越:低延迟、高吞吐、内存计算
概念
数据流
流是流处理的基础,其特征影响处理方式。Flink是强大的数据流处理框架。
- 有界 和 无界 的数据流:数据流分为有界和无界。Flink擅长处理两者,对无界流有强大特性,对有界流有高效算子。
- 实时 和 历史记录 的数据流:数据流分实时和历史记录两种。实时处理即在数据生成时立即进行;历史记录处理则是先将数据流存储后再批处理。Flink能同时支持这两种数据流的处理。
状态
简单来说,复杂流处理应用通常需要状态管理。这意味着它们需要在某个时间点存储接收的事件或中间结果,以便后续处理时使用。即使是最基本的业务逻辑,也可能需要在特定时间内保留这些信息。
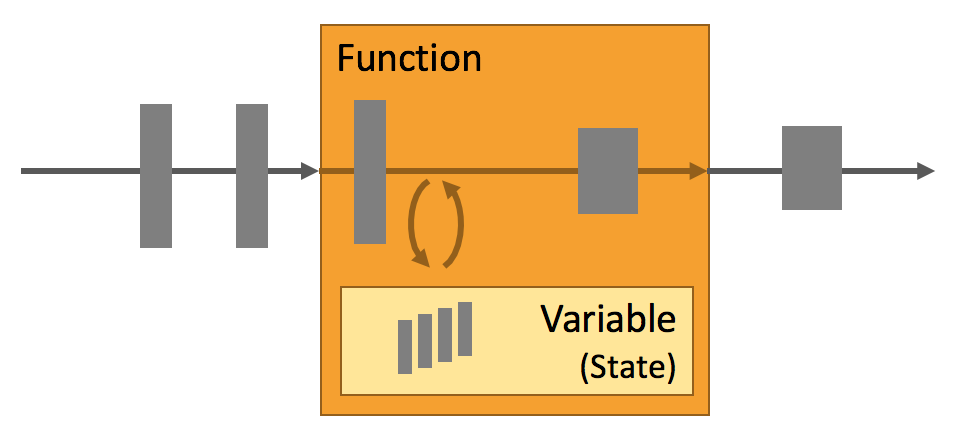
Flink提供了许多状态管理相关的状态支持,其中包括:
- 多种状态基础类型:Flink为不同数据结构提供状态基础类型,如原子值(value)、列表(list)和映射(map),开发者可根据访问方式选择最适合的类型。
- 插件化的State Backend:State Backend管理应用状态,支持checkpoint。Flink有多种存储方式,如内存和RocksDB,也支持自定义存储。
- 精确一次语义:Flink 的 checkpoint 和故障恢复算法保证了故障发生后应用状态的一致性。因此,Flink 能够在应用程序发生故障时,对应用程序透明,不造成正确性的影响。
- 超大数据量状态:Flink 能够利用其异步以及增量式的 checkpoint 算法,存储数 TB 级别的应用状态。
- 可弹性伸缩的应用:Flink 能够通过在更多或更少的工作节点上对状态进行重新分布,支持有状态应用的分布式的横向伸缩。
时间
时间是流处理应用另一个重要的组成部分。因为事件总是在特定时间点发生,所以大多数的事件流都拥有事件本身所固有的时间语义。进一步而言,许多常见的流计算都基于时间语义,例如窗口聚合、会话计算、模式检测和基于时间的 join。流处理的一个重要方面是应用程序如何衡量时间,即区分事件时间(event-time)和处理时间(processing-time)。
Flink提供了丰富的时间语义支持。
- 事件时间模式:使用事件时间语义的流处理应用根据事件本身自带的时间戳进行结果的计算。因此,无论处理的是历史记录的事件还是实时的事件,事件时间模式的处理总能保证结果的准确性和一致性。
- Watermark支持:
原文地址:https://blog.csdn.net/MCC_MCC_MCC/article/details/142835375
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!