北京大学&长安汽车发布毫米波与相机融合模型RCBEVDet:最快能达到每秒28帧
Abstract
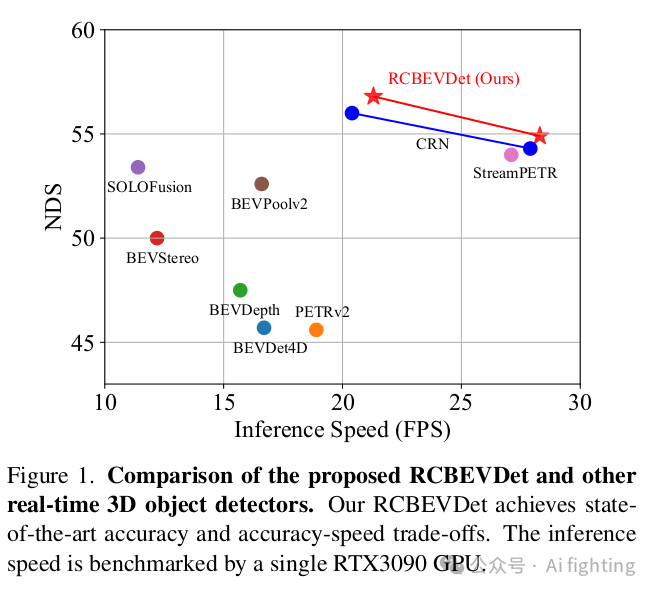
三维目标检测是自动驾驶中的关键任务之一。为了在实际应用中降低成本,提出了利用低成本的多视角相机进行3D目标检测,以取代昂贵的LiDAR传感器。然而,仅依靠相机很难实现高精度和鲁棒性的3D目标检测。解决这一问题的有效方法是将多视角相机与经济的毫米波雷达传感器相结合,以实现更可靠的多模态3D目标检测。在本文中,我们介绍了RCBEVDet,这是一种在鸟瞰视角(BEV)下的雷达-相机融合3D目标检测方法。具体而言,我们首先设计了RadarBEVNet用于雷达BEV特征提取。RadarBEVNet由一个双流雷达骨干网和一个RCS(雷达截面)感知的BEV编码器组成。在双流雷达骨干网中,提出了基于点的编码器和基于Transformer的编码器用于提取雷达特征,并通过注入和提取模块来促进两个编码器之间的通信。RCS感知的BEV编码器以RCS作为对象大小的先验信息,将点特征散布在BEV中。此外,我们提出了跨注意力多层融合模块,利用可变形注意力机制自动对齐来自雷达和相机的多模态BEV特征,然后通过通道和空间融合层进行融合。实验结果表明,RCBEVDet在nuScenes和view-of-delft(VoD)3D目标检测基准测试中实现了新的最先进的雷达-相机融合结果。此外,RCBEVDet在21~28 FPS的更快推理速度下,实现了比所有实时相机仅和雷达-相机3D目标检测器更好的3D检测结果。源代码将发布在https://github.com/VDIGPKU/RCBEVDet。
Introction
3D目标检测技术在自动驾驶领域迅速发展,多视角相机因其成本效益和提供高分辨率语义信息而受到青睐。但单一相机存在深度信息捕捉不精确和在恶劣环境下性能下降的问题。结合经济的毫米波雷达传感器,可以提供距离和速度的高精度测量,且不受天气和光照影响,实现更可靠的多模态目标检测。
毫米波雷达虽然数据稀疏且缺乏语义信息,但作为辅助传感器,与多视角相机结合使用,可提供互补信息,提高3D目标检测的准确性。近年来,这种融合方法受到广泛关注。
Method
1、RadarBEVNet
RCBEVDet的整体流程如下图所示。多视角图像被发送到图像编码器以提取特征。然后,应用视图转换模块将多视角图像特征转换为图像BEV特征。同时,通过提出的RadarBEVNet将对齐的雷达点云编码为雷达BEV特征。随后,通过跨注意力多层融合模块融合图像和雷达BEV特征。最后,融合的多模态BEV特征用于3D目标检测任务。
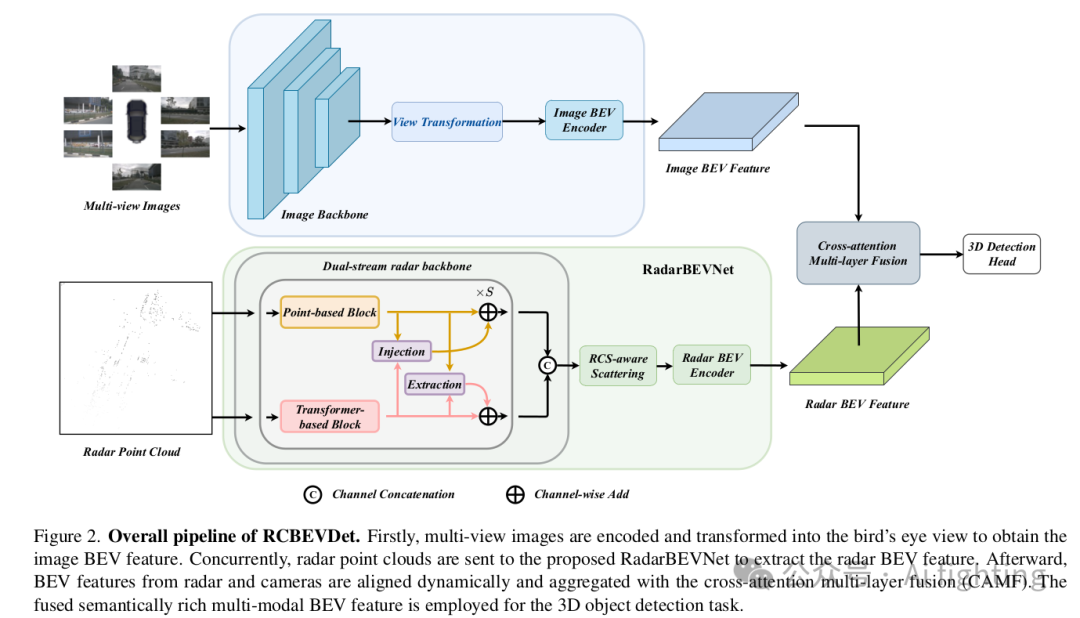
先前的雷达-相机融合方法主要采用为LiDAR点云设计的雷达编码器,如PointPillars。相反,我们提出了RadarBEVNet,特别是用于高效的雷达BEV特征提取。
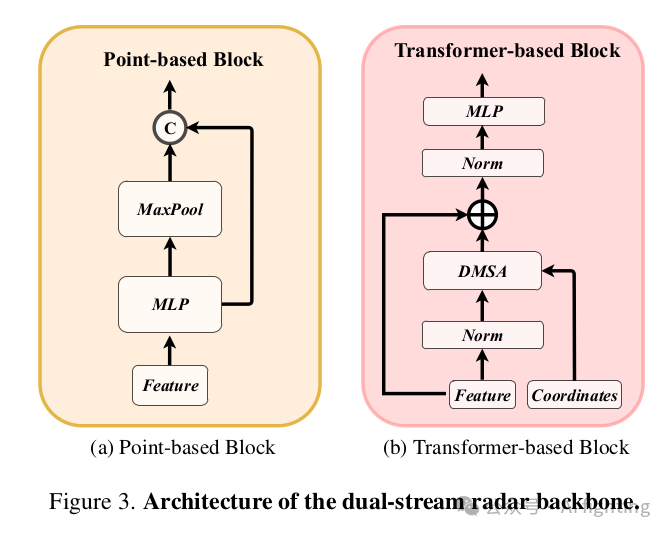
1.1 双流雷达骨干网(Dual-stream radar backbone:双流雷达骨干网有两个骨干网,即基于点的骨干网和基于Transformer的骨干网。基于点的骨干网学习局部雷达特征,而基于Transformer的骨干网捕获全局信息。具体来说,对于基于点的骨干网,我们采用类似于PointNet的简单结构。如下图所示,基于点的骨干网有S个块,每个块包含一个MLP和一个最大池化操作。输入的雷达点特征首先发送到MLP以增加其特征维度。然后,通过对所有雷达点的最大池化操作提取全局信息,并将其与高维雷达特征连接。至于基于Transformer的骨干网,它包含S个标准的Transformer块,具有注意力机制、前馈网络和归一化层,如下图所示。由于自动驾驶场景的广泛性,直接使用标准的自注意力机制可能使模型优化变得困难。为了解决这个问题,我们提出了一种距离调制自注意力机制(DMSA),以使模型在早期训练迭代中聚合邻近信息,从而促进模型收敛
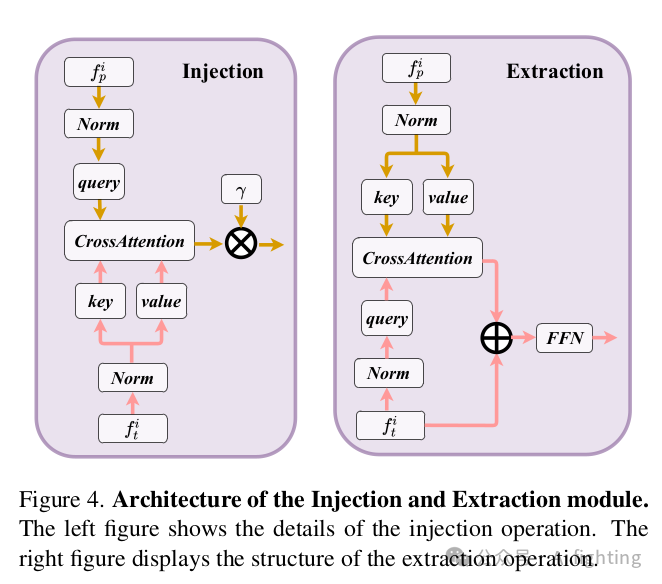
1.2 RCS感知的BEV编码器:目前的雷达BEV编码器通常根据点的3D坐标将点特征散布到体素空间,并压缩z轴以生成BEV特征。然而,生成的BEV特征是稀疏的,也就是说,大多数像素的特征是零。有些像素很难聚集特征,这可能会影响检测性能。一种解决方案是增加BEV编码器层的数量,但这通常会导致小物体的特征被背景特征平滑掉。为了解决这个问题,我们提出了一种RCS感知的BEV编码器。雷达截面积(RCS)衡量物体被雷达检测到的能力。通常,较大的物体会产生较强的雷达波反射,导致较大的RCS测量值。因此,RCS可以提供物体大小的粗略测量。RCS感知的BEV编码器的关键设计是RCS感知散布操作,它利用RCS作为物体大小的先验,将一个雷达点的特征散布到多个像素,而不是在BEV空间中的一个像素,如图5所示。
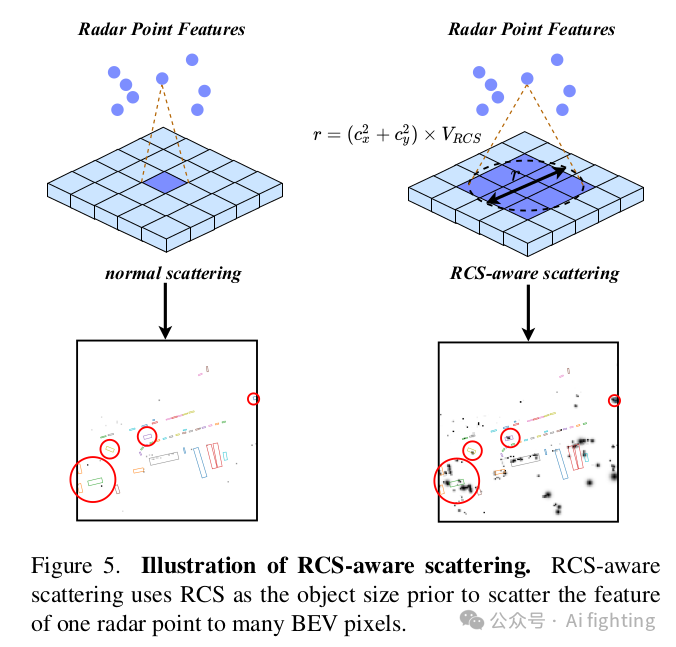
2、跨注意力多层融合模块
2.1 利用跨注意力机制进行多模态特征对齐(Multi-modal Feature Alignment with Cross-Attention)。雷达点云经常受到方位误差的影响。因此,雷达传感器可能会获取超出物体边界的雷达点。结果,由RadarBEVNet生成的雷达特征可能会分配到相邻的BEV网格上,导致来自相机和雷达的BEV特征对齐错误。为了解决这个问题,我们使用跨注意力机制动态对齐多模态特征。由于未对齐的雷达点会偏离其真实位置一定距离,我们建议使用可变形跨注意力机制来捕捉这种偏差。
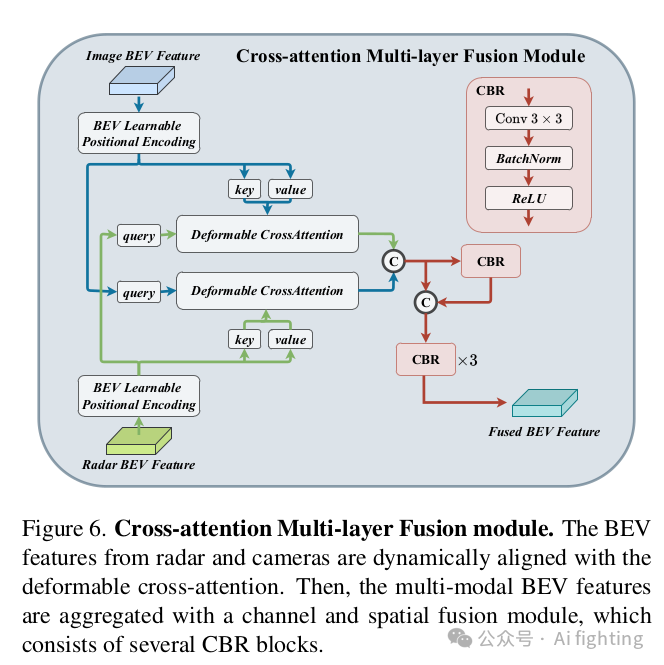
2.2 通道和空间融合(Channel and Spatial Fusion)。在通过交叉注意力对齐来自相机和雷达的BEV特征后,我们提出了通道和空间融合层来聚合多模态BEV特征.
Experiment
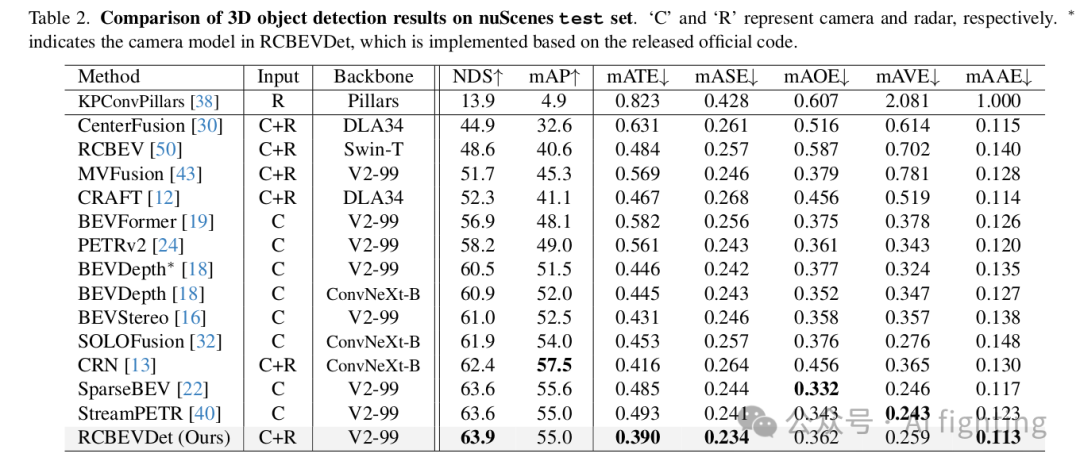
1.NuScenes 结果 :我们在 nuScenes 验证集和测试集上将提出的 RCBEVDet 与之前的最先进的 3D 检测方法进行了比较,如表 1 和表 2 所示。在各种主干设置下,RCBEVDet 在推理速度更快的情况下显示出具有竞争力的 3D 物体检测性能。值得注意的是,与之前最好的仅使用相机的方法(SOLOFusion)和雷达-相机方法(CRN)相比,RCBEVDet 使用 ResNet-50 将速度误差(mAVE)分别减少了 14.7% 和 37.5%。此外,RCBEVDet 超越了所有基于相机的 3D 检测方法,展示了使用互补雷达信息以实现更好的 3D 检测的有效性。
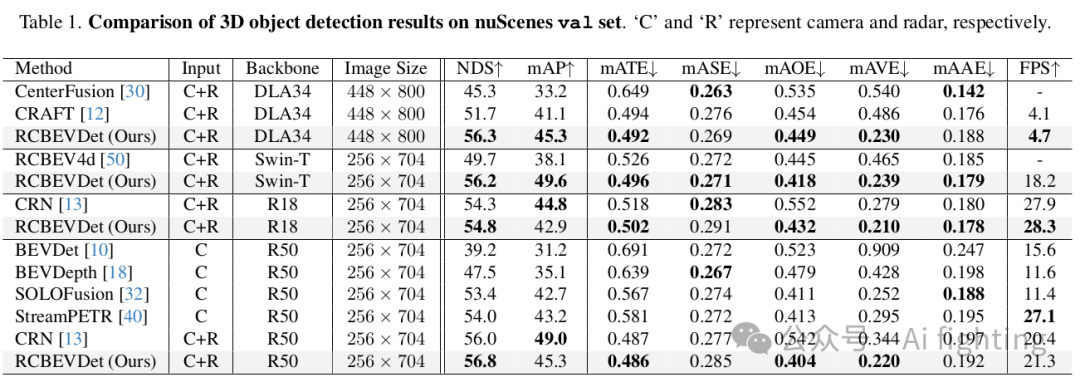
如表 1 所示,RCBEVDet 尤其在整体指标(NDS)和速度误差(mAVE)方面显示出竞争力。具体来说,RCBEVDet 在之前的雷达-相机融合方法中表现出色。
2.VoD 结果:为了进一步证明 RCBEVDet 的有效性,我们在 4D 毫米波雷达数据集 view-of-delft (VoD) 上训练了 RCBEVDet。我们在 VoD 验证集上的结果如表 3 所示。在整个区域内,RCBEVDet 比 RCFusion 高出 0.34 mAP。在感兴趣区域,RCBEVDet 也以 69.80 mAP 达到了最先进的结果。

总结
文章的主要贡献可以概括为以下几点:
- 提出了一种名为RCBEVDet的雷达-相机多模态3D目标检测器,旨在实现高精度、高效且鲁棒的检测。
- 设计了一种高效的雷达特征提取器RadarBEVNet,它包含双流雷达骨干网络,用于提取并编码雷达特征到鸟瞰视图(BEV)中。
- 引入了跨注意力多层融合模块,通过可变形跨注意力机制实现雷达和相机特征的鲁棒对齐和融合。
- RCBEVDet在nuScenes和VoD数据集上取得了雷达-相机多模态3D目标检测的先进结果,并在实时检测器中实现了精度和速度的最佳平衡。5. RCBEVDet在传感器故障情况下展现出良好的鲁棒性。
引用CVPR2024文章: RCBEVDet: Radar-camera Fusion in Bird’s Eye View for 3D Object Detection
欢迎关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
原文地址:https://blog.csdn.net/laukal/article/details/140308989
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!