性能分析-数据库(安装、索引、sql、执行过程)与磁盘知识(读、写、同时读写、内存速度测试)
数据库
数据库,其实是数据库管理系统dbms。
数据库管理系统,
常见:
- 关系型数据库: mysql、pg、
- 库的表,表与表之间有关联关系; 表二维表
- 统一标准的SQL(不局限于CRUD)
- 非关系型数据库:redis、mongodb
- 表之间没有强关联,表中数据,也没有统一的结构。
- redis: key-value
- mongodb:bson(类似json)文档
- 没有统一标准sql,不同的非关系型数据,sql语句不一样
- 时序数据:
- Prometheus 以时间序列来存储数据
数据库管理系统,管理数据。
数据:一切可以用计算书来存储都是数据。
数据对于一个项目是非常非常重要的,所以对数据的保存、数据的稳定性、数据的安全性要求是比较 高的。
如果数据存在磁盘上,希望磁盘的稳定性就要求比较高。----所以,数据库的数据存的磁盘,一般选择机械硬盘。
关系型数据库:库和表 库是数据的一个整体。
mysql数据库,库名称,就是一个文件夹名称。一个库就是一个文件夹。 表用二维表的方式栅格化数据,进行存储。
select语言的性能分析是的重点:项目中获取数据频率远远高于对数据变更的操作。
获取数据,从磁盘上读取你想要的数据。从一张表中来获取想要数据。
mysql数据库,表在磁盘上,就是文件。
我们从表中获取一条数据的过程,找到文件夹(库),找到文件(表),打开磁盘的文件(读文件),跳转到对应的位置(表中一行) 学习数据库的时候还需要有磁盘知识。
数据库安装(linux,源安装)
数据库安装: wget https://dev.mysql.com/get/mysql80-community-release-el7-7.noarch.rpm yum install -y mysql80-community-release-el7-7.noarch.rpm
如果此时 直接安装安装的就是mysql8.0.x版本,数据库安装要安装 mysql5.7.x版本
目前企业中用的mysql数据库的版本,主要是:mysql5.7.x版本或mysql8.x版本
mysql数据库在5.7的版本开始,有非常大的变化。
从mysql的官网上下载,都是mysql8.x版本。mysql5.7.37之前的版本,版本的有效时间已经过期,现在 安装的mysql版本是5.7.37以后。
yum repolist all | grep mysql 查看到当前系统mysql的源支持的mysql版本。现在是mysql8的版本
vim /etc/yum.repos.d/mysql-community.repo
[mysql57-community]
name=MySQL 5.7 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/7/$basearch
enabled=1 # 由0改成了1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql-2022
file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
[mysql80-community]
name=MySQL 8.0 Community Server
baseurl=http://repo.mysql.com/yum/mysql-8.0-community/el/7/$basearch
enabled=0 # 由1改成了0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql-2022
file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
# 安装mysql5.7
yum install mysql-community-server -y这样就能安装到最新的mysql5.7.x版本。
如果你要用mysql的rpm包安装,安装的顺序
mysql-community-common-5.7.41-1.el7.x86_64
1/6
mysql-community-libs-5.7.41-1.el7.x86_64
2/6
mysql-community-client-5.7.41-1.el7.x86_64
3/6
mysql-community-server-5.7.41-1.el7.x86_64
4/6
mysql-community-libs-compat-5.7.41-1.el7.x86_64
systemctl restart mysqld
systemctl enable mysqld这种方式安装的mysql数据库的配置文件: /etc/my.cnf
不同方式安装mysql数据库,配置文件的路径是不一样的。所以不要死记。
调整密码等级 0弱密码 1 一般 2强密码 validate_password_policy 是否开启校验
vim /etc/my.cnf
# 添加validate_password_policy配置 0(LOW),1(MEDIUM),2(STRONG)
validate_password_policy=0
# 关闭密码策略
validate_password = off修改了mysql的配置文件,要重启,才生效。
此时,不知道root密码的,找到root命令
从mysql的日志获取随机生成的root密码: grep "password" /var/log/mysqld.log
登录数据库: mysql -uroot -p 回车,输入密码,
修改密码:
alter user 'root'@'localhost' identified by '新密码';
# 开启远程访问
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '你的新密码' WITH GRANT
OPTION;
FLUSH PRIVILEGES;
exit;数据库,默认端口:3306,
数据库的运行日志:/var/log/mysqld.log
数据库的配置文件:/etc/my.cnf
数据库数据文件:/var/lib/mysql
dcoker方式安装
docker run -itd --name mysql-1 -p 3336:3306 -e MYSQL_ROOT_PASSWORD=1234567 mysql:5.7.41
创建一个库
- sql脚本创建
- 图形界面创建
创建了一个库,库在磁盘上就是一个文件夹名称
路径:/var/lib/mysql/库名称的文件夹
创建一个表
sql创建表
CREATE TABLE `vip19`.`tb_1` (
`id` INT NOT NULL,
`name` VARCHAR(45) NOT NULL,
`class` VARCHAR(45) NULL,
`teacher` VARCHAR(45) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_bin
COMMENT = '表1';图形界面创建表
- 默认时候,用的engine存储引擎,默认是InnoDB
mysql数据库的表,如果版本为5.7及以后的版本,存储引擎Engine默认就是InnoDB。如果是5.7以前的 版本,默认的存储引擎是MyISAM。
存储引擎:
- 存储引擎不一样,在磁盘上的存储方式不一样的
- InnoDB在磁盘上有两个文件:ifm\ibd
- .ifm文件,是表结构文件
- .ibd文件,是表数据+表索引文件
- MyISAM在磁盘上有三个文件: ifm\MYD\MYI
- ifm文件,是表结构文件
- .MYD文件,数据文件
- .MYI文件,是索引文件
- InnoDB在磁盘上有两个文件:ifm\ibd

- 思考一个问题:两张表结构完全相同,存储引擎为InnoDB、MyISAM,存放的数据量行数相 同,问要从这两张表中,获取一行数据,哪个快?
- MyISAM存储引擎要快。MyISAM存储引擎的表在磁盘上的文件要比InnoDB的文件要 小,所以操作速度要快。
- 问题2:既然MyISAM存储引擎更快,为什么现在用的数据库的存储引擎,默认是InnoDB,而 不是MyISAM?
- MyISAM存储引擎,是一种速度优先型,会因为速度太快,导致数据出错。
- InnoDB存储以前,是一种事务优先型,也就是说每次操作必须是一个完整事务完成 了,才能进行下一个事务操作。
- 存储引擎会决定表的锁机制:
- InnoDB表的锁是:行锁
- 行锁:每次操作数据的时候,锁定一行。其他的行还是可以被变更。表是可以被 并行变更数据
- MyISAM表的锁是:表锁
- 表锁:每次操作数据的时候,锁定整张表。
- InnoDB表的锁是:行锁
- 存储引擎,会决定表的索引机制
- InnoDB:支持B+索引
- MyISAM:支持B+索引,哈希索引

现在建表,默认存储引擎是InnoDB,哪,这个引擎是我们现在建所有表的最优选择吗?
不是。 如:项目中的一个码表\配置表(sys表)
创建数据库表的时候,存储引擎的选择,是会影响表的性能的。
数据库中,不能存在表名相同的表,但是可以存在表名不同表结构完全相同的表。
MERGE/MRG_MYISAM存储引擎:合并的表,必须是MyISAM存储引擎。这种引擎表是一个虚拟表,不存在磁盘上。
索引index
B树:是一个链表。平衡二叉树
链表:自身数据+下一个数据的地址
B+树:是在B树的基础上发展而来的。顶点:有自身数据+所有的下一个数据的地址。任何的数据,都只 需要2次io就能读取到。索引性能非常稳定。

数据库的索引,在数据量比较大时候,是很有帮助。这个帮助是帮助我们快速找数据。
索引,对数据变更或向表中插入数据、变更数据,有帮助吗?
-----会导致数据变更变慢。数据变更,甚至会导致索引无效。
表加了索引,不一定就能高表的性能。
- 1、加了索引,导致数据变更变慢
- 2、加了索引,表结构发生变化,索引需要重建。
- 3、加了索引,表在磁盘上的文件也变大,打开的速度变慢。-----索引,不要过多,够用就行
- 一张表,是可以建多个索引。
一张表建复合索引,至少是2列以上,列的顺序非常重要,建索引的时候,我们选择的列的顺序,不一定是表中列的顺序。然后在使用复合索引的时候,我们的sql语言的where条件后字段,顺序要与索引的顺序一致,不要求所有的索引字段都包含,但是顺序一定要正确,如果顺序错了,使用索引就错误。
tab_1(id,col1,col2,col3,col4,col5)
index_na col1,col5,col3
index_col1 col1
sql:
1、select * from tab_1 where id=?;
2、select * from tab_1 where col1=?; √
3、select * from tab_1 where col3=?; ×
4、select * from tab_1 where col5=?; ×
5、select * from tab_1 where col1=? and col3=?; ×
6、select * from tab_1 where col1=? and col5=?; √
7、select * from tab_1 where col3=? and col5=?; ×
8、select * from tab_1 where col5=? and col3=?; ×
9、select * from tab_1 where col1=? and col5=? and col2=? or col3=?; √
select * from tab_1 where col2=? or col3=? and col1=? and col5=?; ×
10、select * from tab_1 where col1=? or col5=?; ×
11、select * from tab_1 where col1=? and col3=? and col5=?; ×
12、select * from tab_1 where col1=? and col5=? and col3=?; √
问?这些sql中,使用率index_na这个索引的有哪些sql编号:思考? 现在工作中,项目sql问题,我们确认是sql没有使用索引,要你解决,你怎么解决?
- 是开发人员修改sql,正确的使用索引?
- 还是,我们根据开发人员写的sql语言的条件顺序,新建索引?
“存储引擎”与“存储过程”?
- 存储引擎:表的存储机制
- 存储过程:多个sql语句封装之后的sql方法
SQL

DDL:数据定义语言,操作库
DML:数据操作语言,操作表,表数据CRUD
DQL:数据查询语言,查询表数据
DCL:数据控制语言,数据库用户和权限控制
SELECT语句的执行过程
select语句是用来获取数据库中的数据。
select 字段
from 表名称
where 条件
group by 字段
having 分组过滤
oder by 字段排序
limit 限制数量select语句的执行过程怎样?
select的解析执行过程
from 表
where 条件 进行数据过滤 ----做完这一步,数据量\行数量变少了,数据是放在内存中
group by 分组字段 -----这一步,只是调整了数据的位置,数据量(行\列)都没有变化,数据是放在
内存中
having 分组过滤 ----执行完这一步,满足过滤条件的留下了,行的数量变少了,列的数量还是不变
量,数据是放在内存中
select 字段 -----执行完这一步,数据量行数量不变,列数量可能变少了
order by 字段排序 -----如果order by用的字段在select显示的字段里面,和不再里面,两种情
况。第一种情况,是很容易实现排序,第二种情况,因为select剩下字段里面没有orderby的字段,就需要
再次从磁盘上获取表的数据,这个时候,就出现了第2次读磁盘,还要再次执行sql语句前面的过滤条件,这个
时间就多消耗的,另外,我们还需要单独申请内存来临时存放这个字段的数据,这些临时数据又需要用到临时
表,多消耗了内存空间,所以,第2种情况,性能就非常差。这就是 回表查询、使用临时表。
limit 数量 -----执行这一步,如果只是简单的返回多少条数据量,这个很快,其他数据,又可以丢掉;
但如果,分页返回多少条数据量,这个时候,就可能很慢,分页越多,就会越慢。通过这个解析过程就能明白,
- 1. 写sql语言的时候,order by后面的排序字段,用select显示中的字段

- 2. limit的时候,分页数量不要太大

一个完整的sql,要被执行,要经过哪些过程?
- 1. 建立连接:数据库信息(数据库ip、端口、账户、密码、库名称)
- 2. 编写脚本
- 3. 执行脚本:二进制日志回放
- 4. 磁盘操作
我们把四个过程分为:
- 1. 连接层
- 1. 与数据库建立连接通道
- 2. 服务层:服务层提供一些接口,数据库的sql的驱动关键词,就可以认为是数据库的接口
- 1. 用户权限判断
- 2. 脚本检查
- 3. 脚本解析
- 4. 脚本优化
- 5. 其他
- 3. 引擎层:把sql进行转换,日志文件
- 1. 数据库引擎进行脚本转换
- 2. 引擎执行日志文件
- 4. 存储层:磁盘操作
- 1. 磁盘操作
磁盘
- 机械硬盘
- 光盘----可以反复擦写
- 机械臂
- 转子:现在的机械硬盘,转子的转速一般在7200r/m 14000r/m。 转速越高,从磁盘读数据 的速度,就会越快。但是因为是机械运动,不可能无限快,转速快,会发热。
- 固态硬盘
- 光盘:
- 先理解为一张白纸
- 光盘的格式化。先分区,然后格式化。
- 硬盘做分区,是可以提升数据存取速度。
- 做分区的时候,就会选择格式化。NTFS、ext4
- 磁盘的格式化,可以提高磁盘利用率,获取数据的时候,速度也更快

扇区:磁盘上的一段弧形
块:相邻的多个扇区构成块。 操作系统与磁盘进行数据交换的单位。
页page:操作系统与内存进行数据交换的单位。一页是由多个块构成。
CPU的速度是最快的,内存的速度居中,磁盘的速度是最慢的。为了配合cpu的速度,需要缓存。
- 缓存:
- buff缓冲区:由磁盘虚拟出来的,加快从磁盘读数据的速度。
- cache缓存:内存中一部分和cpu寄存器
用虚拟化参数都硬盘,都是机械硬盘,在linux中,标识机械硬盘 sd,后面跟一个字母,代表第几个硬盘 (sda第1块机械硬盘),再跟一个数字,数字代表硬盘的第几个分区(sda2第1个硬盘的第2个分区) sdb2
fdsk -l 可以看硬盘的信息,但是fdisk命令,谨慎使用(有可能符导致磁盘格式化)。

RAID磁盘矩阵:做这个,也是为了提升磁盘的性能,也可以做磁盘数据的备份。 矩阵:就会要用到多个磁盘。
RAID0:数据分片存在2块磁盘,读写速度提升2倍,主要用于SWAP\TMP,但是数据不冗余,数据恢复难
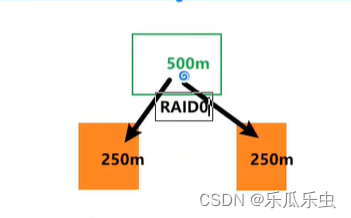
RAID1:相同数据冗余存入2块磁盘,写速度不变,读速度提升2倍,数据冗余1份,主要用于数据备份, 但磁盘利用率低
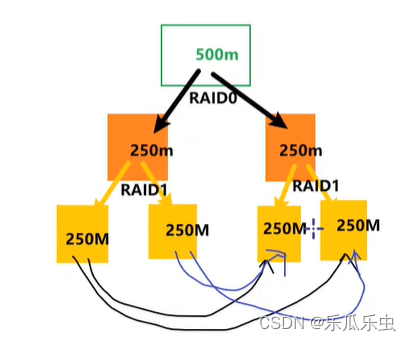
RAID5:数据分片和校验码混合存储3份,读写速度提升2倍,主要在要求高速时用,可以用于数据还原 RAID10:2块磁盘1组先做RAID1,多组RAID1,再做RAID0。读写速度N倍 n为组数
读磁盘
dd 命令
命令: dd if=/dev/sda of=/dev/null bs=20MB count=100
if 输出文件 /dev/sda 读整个磁盘
of 输出文件 /dev/null 回收站,是一个伪设备,不会有磁盘的写操作
bs 每次操作文件的大小
count 执行次数
这个命令用来测试磁盘在只有读的时候,磁盘的性能。
vmstat 命令可以看到 buff 和 cache
vmstat 1

清空缓存: echo 3 > /proc/sys/vm/drop_caches 清空缓存
执行之后,会buff清空,cache会变小。
dd if=/dev/sda of=/dev/null bs=20MB count=100

vmstat 1
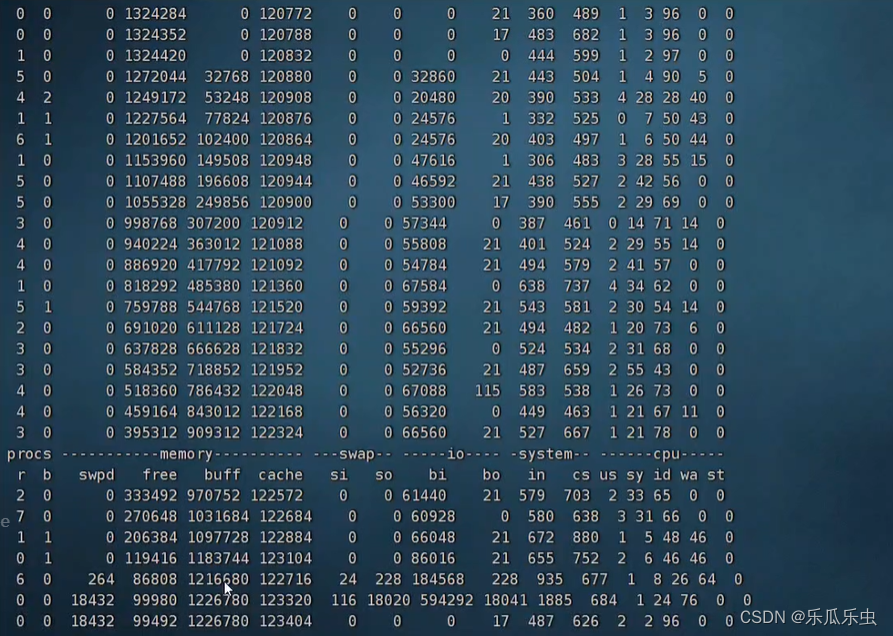
一般情况下机械硬盘的读磁盘的速度,一般在小几百MB每秒。多次测试会有偏差。
写磁盘
先清空缓存: echo 3 > /proc/sys/vm/drop_caches
vmstat 1
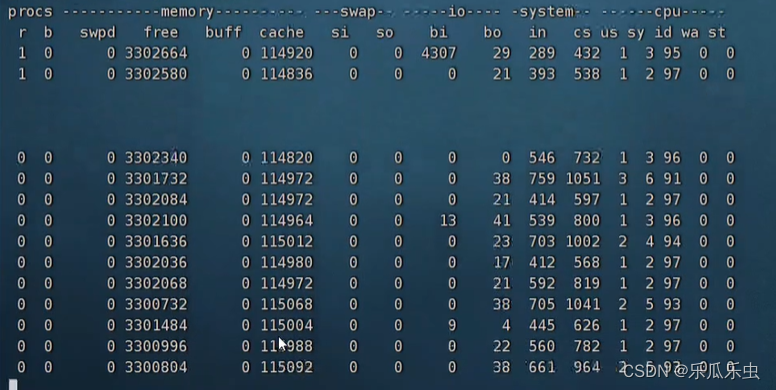
写磁盘: dd if=/dev/zero of=$PWD/outf bs=16MB count=100

buff没有变,cache是变大了。
vmstat 1
磁盘的写的速度,一般也是小几百MB每秒

同时读写磁盘
这些这些命令之前,都要去先清空缓存
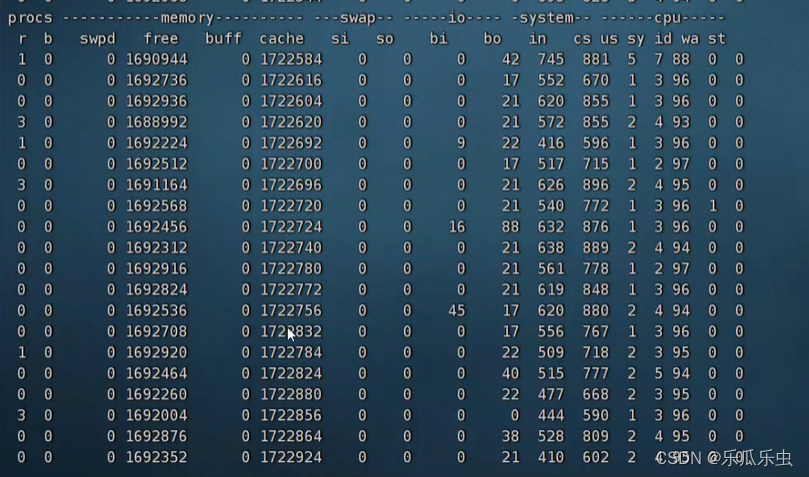
dd if=/dev/sda of=$PWD/otf bs=14MB count=100 同时有读和写磁盘操作。

这个操作buff和cach都会增大,速度,也是在小几百MB每秒,一般还会比单独的读或写的速度要慢。
内存速度测试
dd if=/dev/zero of=/dev/null bs=15MB count=100 没有读和写磁盘 ---这些数据都在内存中交换,这个命令可以测试内存的速度。

执行这个命令,看到buff和cach基本没变,得到内存的速度大概是:小几十GB每秒

内存的速度,大概是磁盘速度的十几倍。
你项目中同时有读写操作,你可以用iostat这个命令,看读写速度和等待wait,看是否有磁盘瓶颈。
现在的数据库,因为要大量读磁盘操作,读速度跟不上行,就可能导致,获取数据的响应时间偏 长,导致性能偏低。
这其实就会被大多人理解为慢sql,慢查询。
一般数据库因为磁盘瓶颈,导致的性能问题,一般比较少的换磁盘,而是考虑优化数据库。
原文地址:https://blog.csdn.net/qq_35283902/article/details/137522933
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!