Flink实战之DataStream API
接上文:Flink实战之运行架构
Flink的计算功能非常强大,提供的应用API也非常丰富。整体上来说,可以分为DataStreamAPI,DataSet API 和 Table与SQL API三大部分。
其中DataStream API是Flink中主要进行流计算的模块。 DateSet API是Flink中主要进行批量计算的模块。而Table API和SQL主要是对Flink数据集提供类似于关系型数据的数据查询过滤等功能。
在这三个部分中,DateStream API是Flink最为重要的部分。之前介绍过,Flink是以流的方式来进行流批统一的,所以这一部分API基本上包含了Flink的所有精华。
DataSet API处理批量数据,但是批量数据在Flink中是被当做有界流来处理的,DataSet API中的大部分基础概念和功能也都是包含在Flink的DataStream API中的。
而Table API和SQL 是Flink主要针对Java和Scala语言,提供的一套查询API。可以用来对Flink的流式数据进行一些类似于关系型数据的查询过滤功能。而根据官方的介绍,这一部分功能还处在活跃开发阶段,目前版本还没有完全实现全部的特性。
所以,后续的应用开发学习过程中,也需要以DataStream API为主。而对于DataSet API和table API & SQL,相对来说没有这么重要。
另外,在学习Flink编程API之前,要特别强调一点就是Flink的版本。Flink目前处在非常活跃的开发阶段,不同版本之间的API变动非常大。本文以Flink1.12版本为准。
1、Flink程序的基础运行模型
要理解DataStream API首先需要理解什么是DataStream。DataStream在Flink 的应用程序中被认为是一个不可更改的数据集,这个数据集可以是无界的,也可以是有界的,Flink对他们的处理方式是一致的,这也就是所谓的流批统一。一个DataStream和java中基础的集合是很像的,他们都是可以迭代处理的,只不过DataStream中的数据在创建了之后就不能再进行增删改的操作了。
在上一文章,其实我们已经接触到了一个简单的Flink程序。 一个Flink程序的基础运行模型是这样的:

这个模型看起来很简单对吧。其实大数据场景下的流式计算确实是很复杂的,但是经过Flink封装后,确实就简单很多了。大致来说,一个Flink的客户端应用主要分为五个阶段:
- 获取一个执行环境 Environment
- 通过Source,定义数据的来源
- 对数据定义一系列的操作,Transformations
- 通过Sink,定义程序处理的结果要输出到哪里
- 最后,提交并启动任务
在之前的演示过程中,我们也接触了一个简单的Flink应用,你可以和这几个步骤对应起来。未来更为复杂的Flink应用也是按照这几个步骤来组织的。
2、Environment 运行环境
StreamExecutionEnvironment是所有Flink中流式计算程序的基础。创建环境的方式有三种。
StreamExecutionEnvironment environment =
StreamExecutionEnvironment.getExecutionEnvironment()
StreamExecutionEnvironment.createLocalEnvironment()
StreamExecutionEnvironment.createRemoteEnvironment(String host, int port, String...
jarFiles)
通常情况下,你只需要使用getExecutionEnvironment()这一种方式就可以了。这个API会根据运行环境创建正确的StreamExecutionEnvironment对象。这样就不需要区分应用是在IDEA本地执行或者是在某一个Flink Cluster上执行。
然后,创建出来的StreamExecutionEnvironment对象,可以设置应用整体的并行度。StreamExecutionEnvironment.setParallelism。关于并行度已经在上一章节中详细做了分析,这里需要注意,并行度是贯穿整个应用的资源主线。
在StreamExecutionEnvironment对象中,还可以通过setRuntimeMode方法设置一个运行模式。可以设定一个RuntimeExecutionMode枚举类型。该类型有三个可选的枚举值:
- STREAMING:流式模式。这种模式下,所有的task都会在应用执行时完成部署,后续所有的任务都会连续不断的执行。
- BATCH: 批量模式。这是Flink早期进行批处理的方式,这种模式下,所有的任务都会周期性的部署,shuffle的过程也会造成阻塞。相当于是拿一批数据处理完了之后,再接收并处理下一批任务。
- AUTOMATIC:自动模式。Flink将会根据数据集类型自动选择处理模式。有界流下选择BATCH模式,无界流下选择STREAMING模式。
BATCH模式能够稍许提升应用的吞吐量,对于有界流,能提高执行效率。但是对于无界流就不适用了。而对于Flink,默认的STREAMING模式在有界流和无界流场景下都是适用的。
另外,这个执行模式并不建议在代码中设置,最好是在flink-conf.yaml文件中通过execution.runtime-mode属性进行整体设置,或者是在使用flink脚本提交任务时指定。这样能让应用更加灵活。例如:
bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
这两种运行模式影响到的功能还是挺多的,通常情况下,不建议做特殊的指定。
3、Source
Source和表示Flink应用程序的数据输入。Flink中提供了非常丰富的Source实现,目前主流的数据源都可以对接。
3.1 基于File的数据源
1 readTextFile(path)
一行行读取文件中的内容,并将结果以String的形式返回。
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
final DataStreamSource<String> stream = env.readTextFile("D://test.txt");
stream.print();
env.execute();
print打印出来的结果中每一行前面的数字表示这一行是哪个线程打印出来的。
2 readFile((FileInputFormat inputFormat, String filePath))
DataStreamSource<String> stream = env.readFile(new TextInputFormat(new
Path("D://test.txt")), "D://test.txt");
TextInputFormat是一个接口,OUT泛型代表返回的数据类型。TextInputFormat的返回类型
是String。PojoCsvInputFormat就可以指定从CSV文件中读取出一个POJO类型的对象。
3.2 基于Socket的数据源
这个我们上一个文章已经说明过。对接一个Socket通道,读取数据。
DataStreamSource<String> stream = env.socketTextStream("localhost", 11111);
stream.print();
env.execute("stream word count");
3.3 基于集合的数据源
1、fromCollection 从集合获取数据
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
final List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
final DataStreamSource<Integer> stream = env.fromCollection(list);
stream.print();
env.execute("stream");
2、fromElements 从指定的元素集合中获取数据
final DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5);
3.4 从Kafka读取数据
在通常情况下,流式数据最大的数据来源还是kafka。而Flink已经提供了针对kafka的Source。引入kafka的连接器,需要引入maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.12.3</version>
</dependency>
然后使用FlinkKafkaConsumer创建一个Source
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092");
properties.setProperty("group.id", "test");
final FlinkKafkaConsumer<String> mysource = new FlinkKafkaConsumer<>("flinktopic", new SimpleStringSchema(), properties);
// mysource.setStartFromLatest();
// mysource.setStartFromTimestamp();
DataStream<String> stream = env.addSource(mysource);
stream.print();
env.execute("KafkaConsumer");
这样就可以接收到kafka中的消息了

另外,Flink非常多常用组件的Connector。例如Hadoop,HBase,ES,JDBC等。 具体参见官方网站的Connectors模块。
地址:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/kafka.html
补充一个组件RocketMQ。 Flink官方并没有提供RocketMQ的Connector。但是RocketMQ社区只做了一个Flink的Connector,参见Git仓库:https://github.com/apache/rocketmq-externals
3.5 自定义Source
用户程序也可以基于Flink提供的SourceFunction,配置自定义的Source数据源。例如下面的示例,可以每一秒钟随机生成一个订单对象。
package com.roy.flink.source;
import com.roy.flink.beans.Stock;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Random;
public class UDFSource {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Stock> orderDataStreamSource = env.addSource(new MyOrderSource());
orderDataStreamSource.print();
env.execute("UDFOrderSOurce");
}
public static class MyOrderSource implements SourceFunction<Stock> {
private boolean running = true;
@Override
public void run(SourceContext<Stock> ctx) throws Exception {
final Random random = new Random();
while(running){
Stock stock = new Stock();
stock.setId("stock_"+System.currentTimeMillis()%700);
stock.setPrice(random.nextDouble()*100);
stock.setStockName("UDFStock");
stock.setTimestamp(System.currentTimeMillis());
ctx.collect(stock);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running=false;
}
}
}
注 1、流式计算的数据源需要源源不断产生数据,所以run方法通常都是一个无限循环。这时Flink强调要通过cancel方法主动停止run方法中的循环。
2、Flink还提供了另外一个RichSourceFunction接口来定义Source。这个接口提供了Source的生命周期管理。关于生命周期,在这个示例中看不出差别,在后面的章节会进行讲解。
4、Sink
Sink是Flink中的输出组件,负责将DataStream中的数据输出到文件、Socket、外部系统等。
4.1 输出到到控制台
DataStream可以通过print()和printToErr()将结果输出到标准控制台。在Flink中可以在
TaskManager的控制台中查看。
4.2 输出到文件
对于DataStream,有两个方法writeAsText和writeAsCsv,可以直接将结果输出到文本文件
中。但是在当前版本下,这两个方法已经被标记为过时。当前推荐使用StreamingFileSink。例
如:
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig.builder().withPartPrefix("prefix").withPartSuffix(".txt").build();
final StreamingFileSink<String> streamingfileSink = StreamingFileSink.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<String>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.addSink(streamingfileSink);
env.execute();
流式计算场景下的文件输出,不能直接往一个文件里不停的写。StreamingFileSink提供了流
式数据的分区读写以及滚动更新功能。Flink另外提供了多种文件格式的Sink类型。具体参见http
s://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/streamfile_sin
k.html
然后,针对流批统一场景,Flink还另外提供了一个StreamingFileSink的升级版实现,
FileSink。使用FileSink需要增加一个maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.12.5</version>
</dependency>
这样就可以使用FileSink进行流批统一的文件输出了。
package com.roy.flink.sink;
import com.roy.flink.streaming.FileRead;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import java.net.URL;
public class FileSinkDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
final StreamingFileSink<String> streamingfileSink = StreamingFileSink
.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<String>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.addSink(streamingfileSink);
// final FileSink<String> fileSink = FileSink
// .forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<String>("UTF-8"))
// .withOutputFileConfig(outputFileConfig)
// .build();
// stream.sinkTo(fileSink);
env.execute("FileSink");
}
}
通常情况下,流式数据很少会要求输出到文件当中,更多的场景还是会直接输出到其他下游组
件当中,例如kafka、es等。
4.3 输出到Socket
例如我们可以将之前从Socket读到的wordcount结果输出回Socket
package com.roy.flink.sink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.nio.charset.StandardCharsets;
public class SocketSinkDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// environment.setParallelism(1);
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
final int port = parameterTool.getInt("port");
final DataStreamSource<String> inputDataStream = environment.socketTextStream(host, port);
final DataStream<Tuple2<String, Integer>> wordcounts = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
final String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
})
.keyBy(value -> value.f0)
.sum(1);
wordcounts.print();
wordcounts.writeToSocket(host, port, new SerializationSchema<Tuple2<String, Integer>>() {
@Override
public byte[] serialize(Tuple2<String, Integer> element) {
return (element.f0 + "-" + element.f1).getBytes(StandardCharsets.UTF_8);
}
});
environment.execute("SocketSinkDemo");
}
}
这样,在socket的服务端就能收到响应信息。
4.4 输出到kafka
Flink提供的这个kafka的connector模块,即提供了FlinkKafkaConsumer作为Source消费消
息,也提供了FlinkKafkaProducer作为Sink生产消息。
package com.roy.flink.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner;
import java.util.Properties;
public class KafkaSinkDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "worker1:9092,worker2:9092,worker3:9092");
properties.setProperty("group.id", "test");
final FlinkKafkaConsumer<String> mysource = new FlinkKafkaConsumer<>("flinktopic", new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource(mysource);
stream.print();
//转存到另一个Topic
properties = new Properties();
properties.setProperty("bootstrap.servers", "worker1:9092,worker2:9092,worker3:9092");
final FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<>("flinktopic2"
, new SimpleStringSchema()
, properties
, new FlinkFixedPartitioner<>()
, FlinkKafkaProducer.Semantic.EXACTLY_ONCE
, 5);
stream.addSink(myProducer);
env.execute("KafkaConsumer");
}
}
详细情况还是可以参看官方文档说明。
4.5 自定义Sink
与Source类似,应用程序同样可以通过不带生命周期的SinkFunction以及带生命周期的
RickSinkFunction来定义自己的Sink实现。例如下面的示例中就扩展出了一个把消息存入mysql
的示例。
package com.roy.flink.sink;
import com.roy.flink.beans.Stock;
import com.roy.flink.source.UDFSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class UDFJDBCSinkDemo {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Stock> source = env.addSource(new UDFSource.MyOrderSource());
source.addSink(new MyJDBCSink());
env.execute("UDFJDBCSinkDemo");
}
public static class MyJDBCSink extends RichSinkFunction<Stock> {
Connection connection = null;
PreparedStatement insertStmt = null;
PreparedStatement updateStmt = null;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/testdb", "root", "root");
insertStmt = connection.prepareStatement("insert into flink_stock (id, price,stockname) values (?, ?, ?)");
updateStmt = connection.prepareStatement("update flink_stock set price = ?,stockname = ? where id = ?");
}
@Override
public void close() throws Exception {
insertStmt.close();
updateStmt.close();
connection.close();
}
@Override
public void invoke(Stock value, Context context) throws Exception {
System.out.println("更新记录 : "+value);
updateStmt.setDouble(1, value.getPrice());
updateStmt.setString(2, value.getStockName());
updateStmt.setString(3, value.getId());
updateStmt.execute();
if( updateStmt.getUpdateCount() == 0 ){
insertStmt.setString(1, value.getId());
insertStmt.setDouble(2, value.getPrice());
insertStmt.setString(3, value.getStockName());
insertStmt.execute();
}
}
}
}
注:SinkFunction接口只有一个invoke方法。而RichSinkFunction另外继承了RichFunction接口,增加了open\close等生命周期管理的方法。后面章节还会继续关注RichFunction。
运行这个示例,需要引入mysql的jdbc驱动包。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
另外,Flink也提供了一个JDBC的Sink工具包(不包含JDBC驱动)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>1.12.5</version>
</dependency>
有兴趣的话,可以跟踪下这个组件的实现方式。
5、Transformation
这部分是对DataStream进行数据变换的操作。大数据的一些基本的Transformation操作,在
Flink中也是一样的。具体可以参见官方文档https://ci.apache.org/projects/flink/flink-docs-re
lease-1.12/zh/dev/stream/operators/
5.1 Map
DataStream -> DataStream 处理一个元素生成另一个元素
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});
5.2 FlatMap
DataStream -> DataStream。 他与Map的区别在于会将多层嵌套的数据结构压缩成一个扁
平的Map结构。
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});
5.3 filter 过滤
DataStream -> DataStream 根据一个判断条件对数据进行过滤,不满足要求的数据将被剔
除。
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
5.4 keyBy
DataStream -> KeyedStream 对于(key,value)类型的数据,按照key进行分组,并按照给定
的计算方法将key相同的那些value聚合成一个新的value。例如我们之间进行wordcout计算时,
会将一行文本拆分出的(word,1)这样的数据,这时就可以通过keyBy将数据按照word分组,相
同word的数据放到一起,聚合后的数据形式是(word,[1,1,1,1,1])这样的格式,后续就可以用来进
行运算。
dataStream.keyBy(value -> value.getSomeKey()) // Key by field "someKey"
dataStream.keyBy(value -> value.f0) // Key by the first element of a Tuple
这里只需要注意下,对Key的类型是有一点要求的:
1、key不能是一个集合
2、key如果是一个POJO类型的对象,那么他需要重写HashCode()方法。
5.5 Reduce
KeyedStream -> DataStream 将KeyedStream中的每一个Value数组进行两两相邻的循环操
作。最终计算出一个值。
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2)throws Exception {
return value1 + value2;
}
});
5.6 Aggregations
KeyedStream -> DataStream 对KeyedStream中的数组进行一些统计计算。可以通过元祖
的序号直接选择统计的列,也可以指定元祖的列名。
keyedStream.sum(0);
keyedStream.sum("key");
keyedStream.min(0);
keyedStream.min("key");
keyedStream.max(0);
keyedStream.max("key");
keyedStream.minBy(0);
keyedStream.minBy("key");
keyedStream.maxBy(0);
keyedStream.maxBy("key");
这其中min()和minBy()的区别是,min()返回当前这一列的最小值,而minBy()返回最小值所
在的这一个数据元祖。
5.7 Connect 连接操作
DataStream,DataStream -> ConnectedStream : 连接两个保持他们类型的数据流,两个数
据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的。数据和形式不发
生任何变化,两个流相互独立。通常只作为一个中间状态,进行后续的统计。
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);
5.8 CoMap, CoFlatMap
ConnectedStream -> DataStream : 和之前的Map,FlatMap相似,只是这是作用在
ConnectedStream的版本。
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});
5.9 union 连接操作
DataStream,DataStream -> DataStream 将两个DataSteam的数据集合到一起,产生一个
包含了所有元素的新DataStream。注意下这个union操作是不去重的。
DataStreamSource<Integer> stream = env.fromElements(2, 4, 6, 8);
DataStreamSource<Integer> stream2 = env.fromElements(1, 3, 5, 7);
DataStream<Integer> union = stream.union(stream2);
在老版本的Flink中,还有一个split操作,将一个流拆分成两个流。但是在新版本这个
操作被取消了。
另外还有一些与数据分区和算子链相关的内容,就不再多说了,具体可以参考官方文
档。
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/stream/operators/
5.10 Function与RichFunction
Function是一个顶级的处理函数接口,之前用到的各种Source、Sink、Transform都是这两个接口的子实现类。Function代表一个普通的函数接口,只对数据进行计算。Function接口本身没有提供任何方法。RichFunction则是Function的一个直接子接口,包含了对任务的生命周期管理。例如open方法,是在Slot任务执行之前触发,可以用来做很多一次性的初始化工作。close方法,是在Slot任务执行之后触发,同样可以用来做很多一次性的收尾工作。而getRuntimeContext方法可以拿到方法执行的上下文,可以拿到很多任务执行时的信息,例如当前子任务的ID、当前任务的状态后端等等。
5.11 其它算子
Flink官网还提供了很多重要的算子。分布式场景下,数据倾斜是一个很常见的问题,例如在进行keyed分组时,如果数据集中大量的数据都集中在某一个key下,那就会造成各个slot之间的任务进行不平衡,会影响计算的效率。这时候Flink提供了一组重新分区的算子。最常用的是shuffle()和rebalance()两个方法。shuffle方法会计算一个随机值,根据随机值将数据在各个slot之间重新分配。而rebalance方法同样是将数据在各个slot之间重新分配,只不过他的分配策略是采用round-robin轮训的方式来分配。这也是对计算任务调优时非常重要的方法。
另外还有一些算子,就不再一一介绍了,可以自行查看官网:
https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/stream/operators/
6、Windows开窗
可以看到,在Flink的流式计算中,数据都是以DataStream的形式来表示。而对流数据的计算,基本上都是一个先分流后合流的过程。而window开窗函数可以理解为是一种更高级的分流的方法。Window将一个无限的流式数据DataStram拆分成有限大小的"Bucket"桶,通过对桶中数据的计算最终完成整个流式数据的计算。他也是处理流式数据时的一种常见的方法,在KafkaStream、Spark Streaming等这些流式框架中都有。
6.1 window类型
Flink中的Window整体上可以分为两类
- Keyed Window 针对keyedStream进行的开窗。keyed Stream会将原始的无界流切分成多个逻辑上的keyed stream。在Keyed Stream上的开窗函数window,可以指定并行度,由多个任务并行执行计算任务。所有拥有相同Key的数据将会被分配到同一个并行任务中。常见的操作是这样的:

- Non-Keyed Window 针对DataStream进行的开窗。这种开窗是将所有的流式数据生成一window,这时这个window就不能进行并行计算了,只能以并行度1,由一个单独的任务进行计算。这种开窗方式显然是不利于利用集群的整体资源的,所以通常用得比较少。常见的操作是这样的:

在这里可以看到,在API上,Keyed Window和Non-keyed Window,基本上是一致的,唯一的区别就是开窗函数window和windowAll。所以,后续分析Flink的窗口操作时,将不再区分keyed Window和Non-keyed Window。但是他们两者的区别还是要明白。
6.2 window的生命周期
简单来说,一个window,会指定一个包含数据的范围,从第一个属于他的数据到达之后就被创建出来,而等所有数据都处理完后就会被彻底移除。这个移除的时刻是由指定的窗口结束时间加上后续设定的 allowedLateness时长决定的。例如设定每分钟创建一个window,正常从每分钟的0秒开始创建一个window,然后到这一分钟的60秒就会结束这个window。但是flink允许设定一个延迟时间,比如5秒,那么这个window就会在下一秒的5秒才移除,这是为了防止网络传输延时造成的数据丢失。关于数据的时序问题,后面会有专门的分析。
在flink中,需要通过一个WindowAssigner对象来指定数据开窗的方式。例如,对于DataStream,他的开窗方式是这样的
stream.windowAll(TumblingEventTimeWindows.of(Time.seconds(60)));
//windowAll方法需要传入的是一个WindowAssigner对象。
public <W extends Window> AllWindowedStream<T, W> windowAll(WindowAssigner<? super T, W> assigner)
Flink提供了WindowAssigner的四种不同的实现方式。滚动窗口 Tumbling window,滑动窗口 Sliding window,会话窗口 Session window 以及 全局窗口 Global Window。
另外,Flink中对于还有另外一种根据消息个数开窗的方式。 对于DataStream是countWindowAll,对于KeyedStream是countwindow。这种方式是指一个窗口只包含固定条数的数据。这种方式只考虑数据的数量,没有时间的概念。之前分析过,对于无界流的计算,时间和顺序是非常重要的,所以这种根据消息个数开窗的方式,在实际场景中用得比较少。
6.3 滚动窗口 Tumbling window
滚动窗口需要指定一个固定的窗口大小window size,并且窗口之间不会重叠。
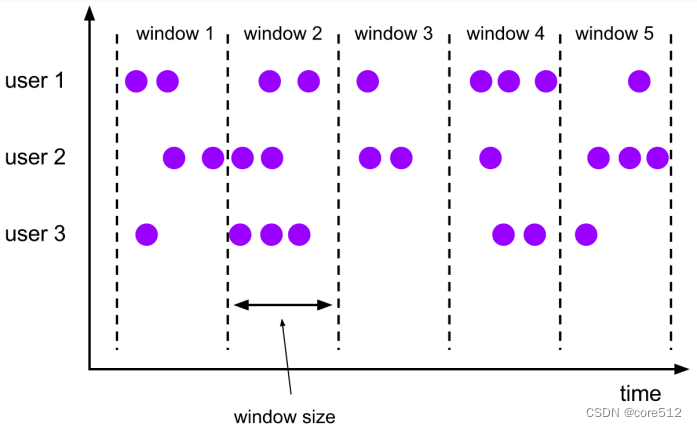
例如
DataStream<T> input = ...;
// 5秒一个窗口,根据EventTime切分。
input.keyBy(<key selector>).window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 5秒一个窗口,根据ProcessTime切分。
input
.keyBy(<key selector>)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<windowed transformation>(<window function>);
// 开窗函数还可以接受一个偏移量,表示开窗的起点与标准起点的差距。例如下面的-8表示时区。
input
.keyBy(<key selector>)
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.<windowed transformation>(<window function>);
在上面的最后一个示例中看到,滚动开窗除了接收一个window size参数外,还可以接收一个offset参数。这个表示开窗的偏移量。例如默认情况下,按照一个小时开一个窗,那么拿到的分区范围是 [1:00:00 ~ 1:59:59, 2:00:00 ~ 2:59:59 …]。但是,当你设定一个15分钟的偏移量之后,得到的分区范围就是 [1:15:00 ~ 2:14:59, 2:15:00 ~ 3:14:59 …]。
6.4 滑动窗口 Sliding widow
滑动窗口与滚动窗口一样有一个窗口大小window size,另外还有一个滑动间隔的window slide。例如,在新冠肺炎期间,我们需要每天统计14天内的行程,这样window slide就是1天,而window size就是14天。这里可以看到,只要window slide参数小于window size,那么必然就会有元素出现在多个window中。而如果window slide参与等于window size,那就是上面的滚动窗口了。

示例代码:
DataStream<T> input = ...;
// sliding event-time windows
input
.keyBy(<key selector>)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows
input
.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<windowed transformation>(<window function>);
// sliding processing-time windows offset by -8 hours
input.keyBy(<key selector>)
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1),
Time.hours(-8))).<windowed transformation>(<window function>);
这里滑动窗口依然可以接收一个偏移量的可选参数。
6.5 会话窗口 Session window
会话窗口是以session会话的方式来划分窗口。会话窗口没有窗口大小和滑动间距这样的参数,他只需要指定一个会话间隔session gap参数。这个会话间隔可以是一个固定的参数,也可以是一个计算函数。只要有相邻两个元素之间的时间间隔超过了这个会话间隔,那么就会划分为两个不同的window。
例如如果需要通过打开机记录,统计员工上下班打卡的时间,为了避免重复打卡造成的误判,就可以用session window进行开窗,在不同的窗口期内统计员工真实的上下班时间。因为员工可能在忘记自己已经打过卡后,在短时间内重复打卡。但是,上班打卡和下班打卡之间的时间间隔就会长得多。

示例代码
DataStream<T> input = ...;
// event-time session windows with static gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// event-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
// processing-time session windows with static gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<windowed transformation>(<window function>);
// processing-time session windows with dynamic gap
input
.keyBy(<key selector>)
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// determine and return session gap
}))
.<windowed transformation>(<window function>);
6.6 全局窗口Global window
全局窗口会把所有相同的元素划分到一个窗口中,而不进行主动的切分。 例如对于keyedStream,就会把所有key相同的元素划分到一个窗口中。
这种全局窗口没有对窗口进行切分,窗口范围没有开始也没有结束。因此自然也是不能直接用的。全局窗口需要自己定义一个trigger来触发窗口计算。实际上,可以把全局窗口认为是一种可自定义的窗口。上述几种类型的窗口是都全局窗口的一种实现方式。

6.7 trigger与evictor
使用全局窗口,后续至少要有一个trigger方法。trigger需要传入一个Trigger对象,这是一个抽象类,他代表的是窗口应该在何时关闭,触发计算。Flink本身提供了很多实现类:
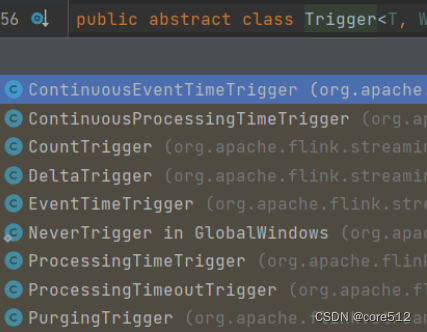
其中EventTimeTrigger和ProcessingTimeTrigger主要是根据数据的时间语义来触发,这两个Trigger在理解完后面的时间语义后,自然就理解了。
CountTrigger是一个比较浅显易懂的示例,如果想要深入理解如何定制Trigger,那么这CountTrigger就是一个很好的参考。
简单理解,就是通过Trigger中的各种onxxx方法,来响应流式数据,然后通过返回TriggerResult对象来决定是否需要出发窗口切换。
CountTrigger需要传入一个参数,表示消息的个数,当消息个数达到阈值后进行窗口划分。
/**
* Creates a trigger that fires once the number of elements in a pane reaches the
given count.
*
* @param maxCount The count of elements at which to fire.
* @param <W> The type of {@link Window Windows} on which this trigger can operate.
*/
public static <W extends Window> CountTrigger<W> of(long maxCount) {
return new CountTrigger<>(maxCount);
}
DeltaTrigger可以根据自定义的方式来设计窗口划分的指标以及阈值,也是非常好用的一个实现类。DeltaTrigger需要提供一个DeltaFunction函数以及一个threshold阈值。他的实现方式类似于Session window。也是通过计算两个相邻数据之间的间隔来划分窗口。只不过这个间隔就不再是一个固定的时间,而是由DetaFunction计算出来的一个Delta指标。Delta指标大于threshold阈值时,就会触发一次窗口划分。相当于是Session Window的定制版本。
/**
* Creates a delta trigger from the given threshold and {@code DeltaFunction}.
*
* @param threshold The threshold at which to trigger.
* @param deltaFunction The delta function to use
* @param stateSerializer TypeSerializer for the data elements.
* @param <T> The type of elements on which this trigger can operate.
* @param <W> The type of {@link Window Windows} on which this trigger can operate.
*/
public static <T, W extends Window> DeltaTrigger<T, W> of(
double threshold, DeltaFunction<T> deltaFunction, TypeSerializer<T>
stateSerializer) {
return new DeltaTrigger<>(threshold, deltaFunction, stateSerializer);
}
对于WindowedStream和AllWindowedStream,还有一个evictor函数也经常会用到。evictor函数需要传入一个Evictor对象。Evictor是用来对窗口中的对象进行剔除的。

其中,TimeEvictor需要传入一个偏移时长 keep_time,所有时长早于 (当前时间 - 偏移时长)的元素就会被从windows中驱逐。例如需要每10分钟开一次窗,但是只需要统计每个窗口内后8分钟的数据,这时就可以通过一个偏移时长为8分钟的evictor加一个10分钟的滚动窗口来实现。
CountEvictor则只保留窗口内固定个数的消息。
DeltaEvictor基于一个DeltaFunction函数以及一个threshold阈值来进行过滤,这跟DetaTrigger是类似的。过滤时,以窗口中的第一个元素为起点,Delta指标超过threshold阈值的元素将会被剔除。这个Delta就是由DeltaFunction计算出来的一个指标。用户可以自定义DeltaFunction的实现。例如可以以时间作为指标,那就是统计一定时间范围内的元素。
其实通过这些示例可以看到,通过全局窗口+Trigger+Evictor的方式进行定制更自由更复杂的窗口切分方案。
6.7 开窗聚合算子
对流式数据进行开窗的目的,肯定是为了对窗口内的数据进行统计计算。这些统计方法和基础的DataStream统计是很类似的。
1 Window Apply
WindowedStream , AllWindowed Stream -> DataStream 给窗口内的所有数据提供一个整体的处理函数,可以称为全窗口聚合函数。例如下面是求和的示例。
windowedStream.apply (new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>
() {
public void apply (Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>
() {
public void apply (Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
2 Window Reduce
Windowed Stream -> DataStream 同样是通过两个相邻元素的处理,来叠加完成整个集合的处理。
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String,
Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});
3 Aggregations on Window
Windowed Steam -> DataStream 在整个window上进行一些整体的统计。
windowedStream.sum(0);
windowedStream.sum("key");
windowedStream.min(0);
windowedStream.min("key");
windowedStream.max(0);
windowedStream.max("key");
windowedStream.minBy(0);
windowedStream.minBy("key");
windowedStream.maxBy(0);
windowedStream.maxBy("key");
同样 min是返回所选列中最小的数据,而minBy是返回所选列最小的这一行。
4 自定义窗口聚合函数
对于WindowedStream,也可以通过aggregate方法传入一个自定义的AggregateFunction实现类来实现自定义的窗口聚合。
// WindowFunction的四个泛型依次表示: 传入数据类型、返回结果类型、key类型、窗口类型。
windowedStream.apply(new WindowFunction<Stock, Tuple2<String,Integer>, String,
TimeWindow>() {
//四个参数依次表示:当前数据的key,当前窗口类型,当前窗口内所有数据的迭代器、输出结果收集器
@Override
public void apply(String s, TimeWindow window, Iterable<Stock> input,
Collector<Tuple2<String,Integer>> out) throws Exception {
final int count = IteratorUtils.toList(input.iterator()).size();
out.collect(new Tuple2<>(s,count));
}
})
在这里重点是需要理解下apply与aggregate两种聚合方式的区别。
apply聚合方式会持续收集窗口内的数据,待窗口的数据全部收集完成后,拿到整个窗口期内的数据,进行整体处理。相当于是一个批处理的过程。可以称之为全窗口聚合。
而aggregate聚合方式则是来一条数据处理一次,并将结果保存到累加器中。当窗口结束后,直接从累加器中返回当前窗口的计算结果。可以称之为流式聚合。
这两种聚合机制,aggregate流式聚合的方式效率会更高,而apply全窗口聚合能够拿到计算过程中更多的信息,因此会更为灵活。当需要定制时,可以根据业务场景灵活取舍。并且,在具体编码实现时,我们只需要记住这两种机制,就不需要完全记住编码的方式了。
7、CEP编程模型
Flink CEP即 Flink Complex Event Processing,是基于DataStream流式数据提供的一套复杂事件处理编程模型。你可以把他理解为基于无界流的一套正则匹配模型,即对于无界流中的各种数据(称为事件),提供一种组合匹配的功能。

上图中,以不同形状代表一个DataStream中不同属性的事件。以一个圆圈和一个三角组成一个Pattern后,就可以快速过滤出原来的DataStream中符合规律的数据。举个例子,比如很多网站需要对恶意登录的用户进行屏蔽,如果用户连续三次输入错误的密码,那就要锁定当前用户。在这个场景下,所有用户的登录行为就构成了一个无界的数据流DataStream。而连续三次登录失败就是一个匹配模型Pattern。CEP编程模型的功能就是从用户登录行为这个无界数据流DataStream中,找出符合这个匹配模型Pattern的所有数据。这种场景下,使用我们前面介绍的各种DataStream API其实也是可以实现的,不过相对就麻烦很多。而CEP编程模型则提供了非常简单灵活的功能实现方式。
使用CEP编程模型首先需要引入maven依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_2.12</artifactId>
<version>1.12.5</version>
</dependency>
CEP编程的基本流程是这样的:
DataStream<Event> input = ......; //1、获取原始事件流
Pattern<Event,?> pattern = .......; //2、定义匹配器
PatternStream<Event> patternStream = CEP.pattern(input, pattern); //3、获取匹配流
//4、将匹配流中的数据处理形成结果数据流
DataStream<Result> resultStream = patternStream.process(
new PatternProcessFunction<Event, Result>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Result> out) throws Exception {}
});
这四个关键步骤中,最为关键的就是第2步,定义匹配器。其次就是第4步对匹配数据流进行处理。
7.1 定义匹配器
定义匹配器的基本方式都是通过Pattern类,以流式编程的方式定义一个完整的匹配器。
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getId() == 42;
}
}
).next("middle").subtype(SubEvent.class).where(
new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent subEvent) {
return subEvent.getVolume() >= 10.0;
}
}
)
定义匹配器的API主要分成两组,一组是begin、next、followby这样的模式组合API,主要是用来定义匹配器的组成顺序。另一种是where、or这样的条件判断API,用来判断当前步骤的匹配条件。使用时必须在每个流程组织API后接一个或一组条件判断API。在此基础上,再加上一些特殊的模式操作API,共同组成一个匹配器。
一个匹配器Pattern需要传入两个Class泛型,第一个Class泛型是匹配器需要处理的数据类型,第二个泛型必须是第一个泛型的子类型,表示在模式匹配过程中,可以扩展出来的处理数据类型。这里需要注意的是,如果数据类型是自定义的POJO类型,那这个POJO对象最好要重写equals和hashcode方法,因为Flink的CEP模式需要通过对POJO对象进行比较来实现模式匹配。
1 模式组合API
所有的Pattern都需要以Pattern.begin方式开头,定义匹配器的开始事件,显然,这个开始事件是必不可少的。接下来可以通过一组组合API,组成匹配器的事件序列。这些API包括。

在定义匹配器的模式组合时,最重要的是要理解一下next和followby的区别。next表示是严格连续,表示两个相邻的匹配模式之间必须是严格连续的,中间不能有其他的匹配模式。而followby表示是非严格连续,表示相邻的两个匹配模式之间不是严格连续的,中间可以有其他的匹配模式。例如网站在判断恶意登录用户时,往往有两种规则,一种是连续三次登录失败,就认为是恶意登录,这就是典型的连续匹配。另一种规则是1分钟内三次登录失败,就认为是恶意登录,这就是非连续的匹配。
显然,这种非连续的匹配模式通常都需要有一个时间范围,而这个时间范围就可以通过within方法指定。在一个匹配器中,每一个单独的匹配模式都可以添加一个within时间范围,但是,很显然,一个匹配器上定义多个时间范围是没有意义的,最终整个匹配器只会取最小的一个时间范围。
2 条件判断API
这一组API主要是判断每一个模式匹配的条件标准。主要是以下一组API



这一组API中,主要是以where来构成一个基础的条件,然后通过在基础条件下进行相关组合形成更为复杂的判断条件。这一块还是比较容易理解的。其中有点难以理解的是subType方法。这个方法只能声明一个处理的子类,也就是在这一个匹配模式当中,可以将原始数据类型转换成他的一个子类,并且在后续的where处理方法中,也需要使用这个子类的类型来定义判断标准。
7.2 对匹配数据流进行处理
1 找出匹配的数据,放入PatternStream
完成了匹配器Pattern的定义后,就可以使用CEP.pattern方法获取匹配数据流PatternStream了。在CEP.pattern方法中,除了正常传入DataStream和Pattern外,还有一个重载的方法,可以传入一个EventComparator比较器,用来判断事件是否匹配。
2 处理PatternStream,转成DataStream
对于匹配数据流,PatternStream,还是需要处理转换成为DataStream。最常用的是通过Pattern的process方法传入一个PatternProcessFunction函数来处理。在函数定义时,需要传入两个泛型,分别代表传入的数据类型以及输出的数据类型。
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT>
out) throws Exception;
IN startEvent = match.get("start").get(0);
IN endEvent = match.get("end").get(0);
out.collect(OUT(startEvent, endEvent));
}
}
核心的processMatch有三个参数,其中context主要用来访问时间语义以及侧输出流,这部分会在下一个文章介绍。
Map<String,List> match 这个参数表示匹配到的数据。其中,String类型的key,就是Pattern中定义的各个匹配模式的名字。后面的List就是每个模式匹配到的数据。
Collector out 参数就是结果收集器。对PatternStream数据的处理结果都通过这个out对象收集到结果的DataStream中。
另外,当一个匹配器Pattern通过within参数加上了窗口长度后,部分匹配到的事件序列就有可能因为超过窗口长度而被丢弃。这个时候,可以使用 TimedOutPartialMatchHandler 接口来处理超时的这一部分匹配。显然,这一部分匹配到的数据是不能和主输出一起使用的,因此,只能通过Context对象将结果输出到侧输出流,单独收集,单独处理。
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT>
implements TimedOutPartialMatchHandler<IN> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT>
out) throws Exception;
...
}
@Override
public void processTimedOutMatch(Map<String, List<IN>> match, Context ctx) throws
Exception;
IN startEvent = match.get("start").get(0);
ctx.output(outputTag, T(startEvent));
}
}
关于测输出流的使用,会在下一个章节再做介绍,在这里,你需要理解的是CEP的整个事件处理流程。其实关于CEP,你如果对照Java的正则表达式的内容来进行比对,就会比较容易掌握他的处理思想。
关于CEP更详细的资料参见官方文档: https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/libs/cep.html
原文地址:https://blog.csdn.net/taotao_guiwang/article/details/135702938
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!