python爬虫之下载小说(3)
import requests
from bs4 import BeautifulSoup
def geturl():
url = 'https://www.biqg.cc/book/6909/' # 目标访问网站url
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"}
req = requests.get(url = url, headers = header)
req.encoding = "utf-8"
html = req.text
bes = BeautifulSoup(html,"lxml")
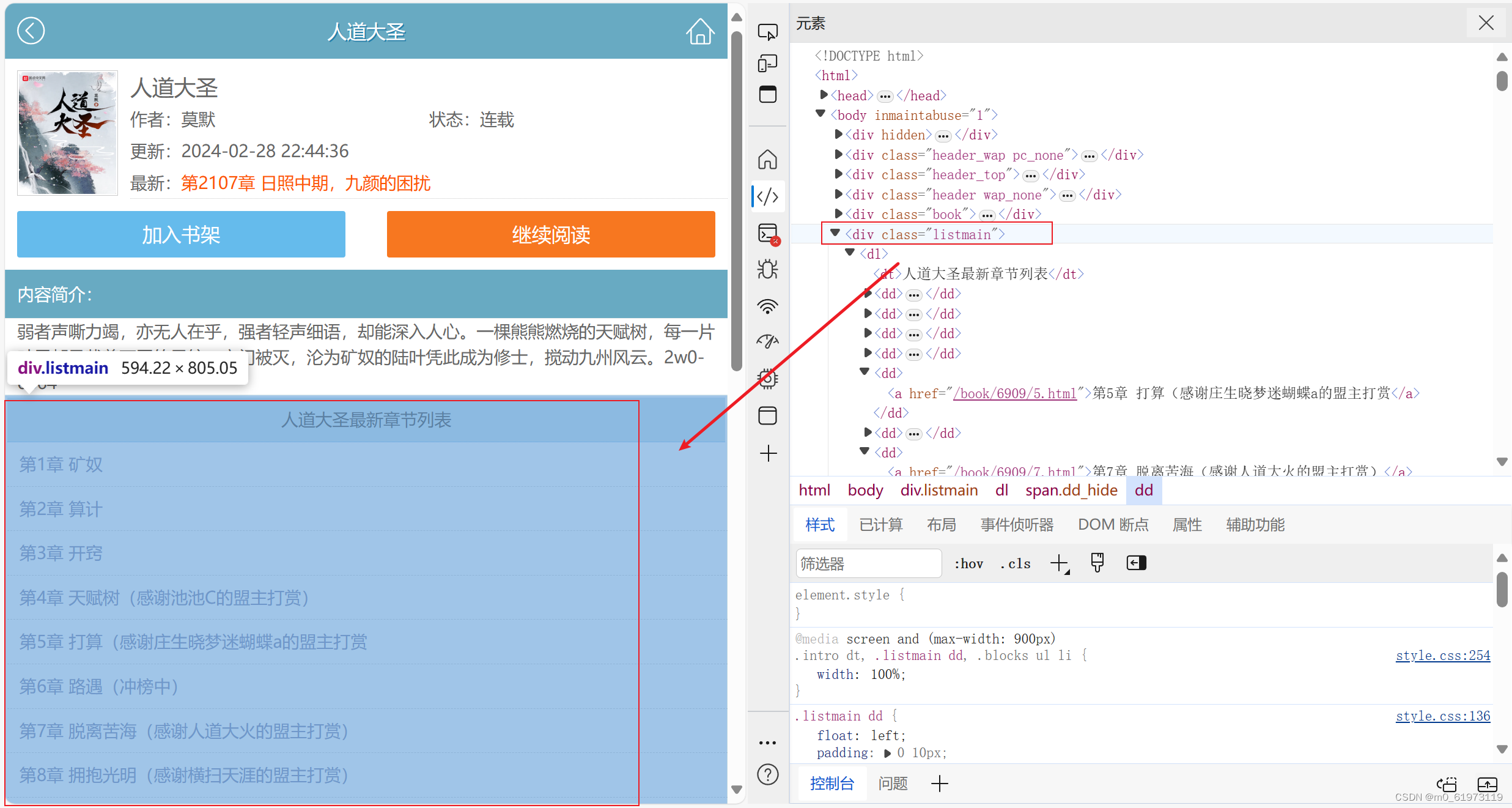
texts = bes.find("div", class_="listmain")
chapters = texts.find_all("a") #该函数可以返回list下的标签为a的所有信息
words = [] #创建空的列表,存入每章节的url与章节名称
##对标签a内的内容进行提取
for chapter in chapters:
name = chapter.string #取出字符串,可以看出字符串只有章节号与章节名称,刚好符合我们所需
#其中存在一条这个语句,我们需要把他剔除,所以加入if判断<a rel="nofollow" href="javascript:dd_show()"><<---展开全部章节--->></a>
#url: https://www.biqg.cc/book/6909/2109.html
#get("href"): /book/6909/2109.html
#split("/")[-1]: 2109.html
if "book" in chapter.get("href"):
url1 = url + chapter.get("href").split("/")[-1]
word = [url1, name] #以列表格式存储
words.append(word) #最终加入总的大列表中并返回
return words
if __name__ == '__main__':
target = geturl()
header = {"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"}
for tar in target:
print(tar)
req = requests.get(url=tar[0],headers = header)
req.encoding = 'utf-8'
html = req.text
bes = BeautifulSoup(html,"lxml")
texts = bes.find("div", id="chaptercontent",class_ = "Readarea ReadAjax_content")
texts_list = texts.text.split("\xa0"*4)
texts_list = texts.text.split("\u3000" * 2)
with open("D:/novels/"+ tar[1] + ".txt","w") as file: #写入文件路径 + 章节名称 + 后缀
for line in texts_list:
file.write(line+"\n")
原文地址:https://blog.csdn.net/m0_61973119/article/details/137876362
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!