【AIGC】通义千问生成问答数据集
好久没有更新跟实际应用相关的内容了(主要是因为公司知识产权问题未能立即公开,目前只能挑选一些脱敏内容与各位分享),如标题所示本期将跟大家讲一下如何通过通义千问生成问答数据集的。
在之前使用 Autokeras 的 RNN 训练时提到,数据是人工智能训练的生命线。数据质量和数据体量决定了人工智能模型的好与坏,因此如何大批量获取高质量数据是一件非常头痛的事情。
虽然可以通过一些数据平台获取训练数据,但对于一些小众领域数据量依然不够。面对这种情况我能想到的就只有“用魔法打败魔法”一条路了。思路如下:
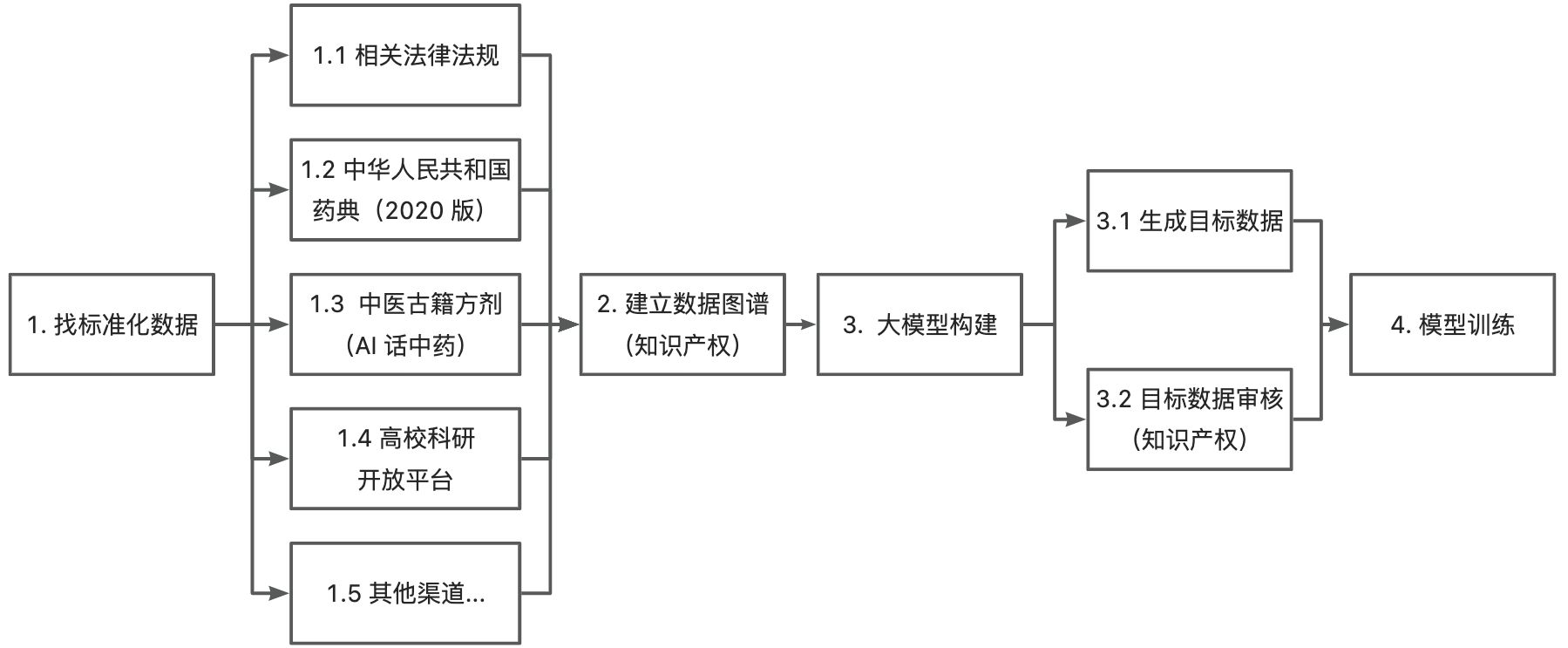
如上图所示,第 1 步“找标准化数据”是比较简单的。难就难在第 2 步,除了要对第 1 步产生的数据进行 ETL 处理外,还要思考如何建立相关的数据图谱。这里将会涉及到一些专业领域的内容,由于中药材它是一个非标品,因此不是简单地用字符特征进行提取关联就可以的。
就举一个最简单的例子,同一个药材品种,道地药材和非道地药材在药效、用法、用量上都存在差异,因此需要专家的介入提供专业意见。
然而以上这些都不是今天的重点,就像前面 Autokeras 训练时所说的,我们的目标是要做一个人工智能问答小助手,因此需要大量的问答数据作为训练支撑,现在我们只有标准化的数据,接下来需要通过大模型对标准化数据进行二次构建,生成“问答”数据,也就是上面的第 3 步内容。
但是,目前几乎所有的大模型都需要“买 token”来使用,没钱怎么办(叹气)?就在一筹莫展的时候发现阿里家的通义千问居然有限时免费!!
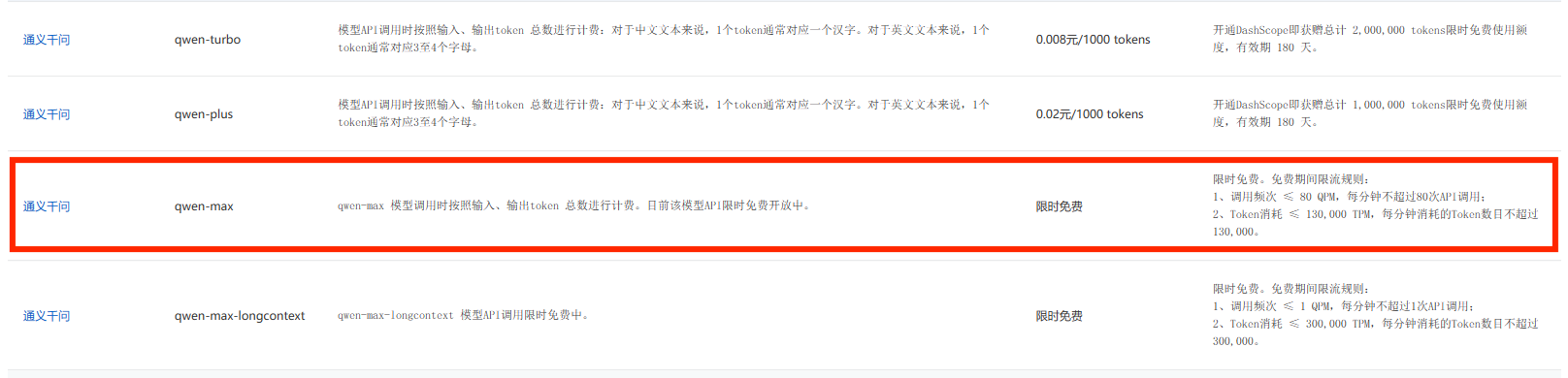
PS:现在通义千问也要收费的了,这个图是之前它还免费的时候截的。如果要免费使用,建议还是本地部署一个 Qwen 1.5 72B 开源版本来用吧(至于如何在本地应用 Qwen1.5 开源模型这个放在之后的一篇文章中分享)
(回归正题)赶紧申请 key,写个 python 马上做个信息转换,如下图:
import requests
import time
import json
import os
project_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
import sys
sys.path.append(project_dir)
import mysql_util as mu
# 设置递归深度
sys.setrecursionlimit(1000000)
# 每个批次生成 20 条记录
gen_batch_size = 20
# 循环 40 次
loop_batch = 40
# 停顿 5 秒
wait_sec = 5
# 通义千问配置信息
qwen_url = 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation'
qwen_id = 'sk-xxxxxxxxxxxxxxxxxxxx'
qwen_assist = '这里要以英文方式提供前置提示'
qwen_type = 'qwen-max'
"""
通过 MySQL 查询标准数据集并通过循环遍历生成样例问题向 Qwen 进行提问,并将结果保存到数据库
"""
def query_integration_info():
# 查询获取数据图谱数据集
result_set = query_standard_dataset()
# 可以根据自己需要的数据总量定义需要执行的循环次数
for i in range(1, loop_batch):
# 遍历数据集(这里只是例子,为了方便理解只提取了部分字段)
for chinese_name, meridians_chinese, class_chinese in result_set:
# 记录开始时间和执行批次
print("Now the "+str(i)+" batch is being processed. The processing variety is:" +
chinese_name+", and start at:" + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
# 在正式请求前需要先暂停,避免频繁请求
time.sleep(wait_sec)
# 根据字段组装提问信息
medical_ask = '请生成'+str(gen_batch_size)+'条关于中药材“'+chinese_name+'”问答且统一按照“问题:xxx \n 答案:xxx”格式返回。信息如下:【品名】' + \
chinese_name + \
check_variable('【归经】', meridians_chinese) + \
check_variable('【药物分类】', class_chinese)
medical_ask = medical_ask.replace("\n", "").replace("\u3000", "")
# 调用通义千问接口进行数据生成并保存
call_qwen_message(medical_ask, chinese_name, i)
"""
一个调用带有医疗信息、中文名称和索引的Qwen消息的函数。
此函数将RESTful请求发送到具有给定数据和标头的指定URL,然后解析响应以提取答案。
然后,如果提取的答案满足某些标准,则对其进行处理并将其插入数据库表中。
Parameters:
medical_info (str): 请求中要包含的医疗信息。
chinese_name (str): 与数据关联的中文名称。
i (int): 索引参数
Returns:
None
"""
def call_qwen_message(medical_info, chinese_name, i):
# 记录开始时间
start_time = time.time()
# 初始化返回内容变量
resp_text = ''
# 整理请求格式和 header
datas = {
"model": qwen_type,
"input": {
"messages": [
{"role": "system", "content": qwen_assist},
{"role": "user", "content": medical_info}
]
},
"parameters": {}
}
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer '+qwen_id
}
try:
# 进行 restful 请求(注意,由于 qwen-max 大模型面对大量 tokens 输入的时候响应速度较慢,因此最好设定好 timeout 参数)
response = requests.post(url=qwen_url, data=json.dumps(
datas), headers=headers, timeout=120)
# 有正常返回的时候就直接解析返回的 json 就可以提取到答案了
if response.status_code == 200:
json_data = json.loads(response.text)
resp_text = json_data["output"]["text"]
if resp_text != '':
batch_data = []
# 整理数据文本对“\n\n”进行切割
each_qa_str = resp_text.split('\n\n')
# 遍历切割后的数据集再进行问题(question)和答案(answer)的整理
for qa_arr in each_qa_str:
qaa_arr = qa_arr[1].split('\n')
question = qaa_arr[0]
answer = ''.join(qaa_arr[1:])
# 将数据整理成数据数组
batch_data.append((
question.split(".")[-1].replace(" ","").replace("问题:", ""),
answer.replace(" ", "").replace("答案:", "").replace("-", ""),
chinese_name,
i))
# 如果数组数据大于 0 的时候就可以进行批量插入了
if len(batch_data) > 0:
batch_save_data(batch_data)
else:
print("Herb "+chinese_name +" request error,please try again later...")
except Exception as e:
print(f"Call the Qwen API falise, please try again later... {e}")
finally:
# 获取结束时间并打印整个方法的耗时输出
execution_time = time.time() - start_time
print(f"Qwen generate execution time: {execution_time} seconds")
"""
批量保存函数
Parameters:
batch_data (list): 包含要插入数据库的数据的元组列表。
Returns:
int: 受插入操作影响的行数。
"""
def batch_save_data(batch_data):
counter = 0
insert_sql = "INSERT INTO model_transfor_data (QUESTION,ANSWER,TAG,BATCH_NUM) VALUES (%s, %s, %s, %s)"
conn = mu.get_connection()
cursor = conn.cursor()
try:
counter = cursor.executemany(insert_sql, batch_data)
conn.commit()
except Exception as e:
conn.rollback()
print(f"Error: {e}")
finally:
cursor.close()
conn.close()
return counter
"""
从data_graph表中查询标准数据集的函数。
此函数连接到数据库,检索按chinese_name排序的所有行,
并将结果集作为元组列表返回。
"""
def query_standard_dataset():
result_set = ''
conn = mu.get_connection()
cursor = conn.cursor()
try:
cursor.execute("SELECT * FROM data_graph ORDER BY chinese_name ASC")
result_set = cursor.fetchall()
except Exception as e:
print(f"Error: {e}")
finally:
cursor.close()
conn.close()
return result_set
"""
一个函数,用于检查变量,如果变量不是None或空字符串,则将其与静态变量连接。
Parameters:
static_var(any):要连接的静态变量。
var(any):要检查和连接的变量。
Returns:
str:static_var和var的串联字符串,如果var为None或空字符串,则为空字符串。
"""
def check_variable(static_var, var):
if var is None or len(str(var)) == 0:
return ''
else:
return static_var+var
if __name__ == '__main__':
query_integration_info()
具体实现如上所示,代码只是单线程执行,若需要以多线程执行可以 import threading 包实现,其实都非常方便。通过大模型生成的问答数据其实也难免会出现“胡说八道”的情况(幻觉),这个时候就需要做数据审核了。数据审核分两种,一种是自动化数据审核,一种是人工审核。具体实现目前我还不能明说,等有机会再跟大家分享如何做自动化审核的内容吧。
以上就是我这个穷逼想到的成本几乎为 0 的数据补充大法,希望也能够帮助到正在阅读的你吧。
原文地址:https://blog.csdn.net/kida_yuan/article/details/137511344
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!