【机器学习笔记】1 线性回归
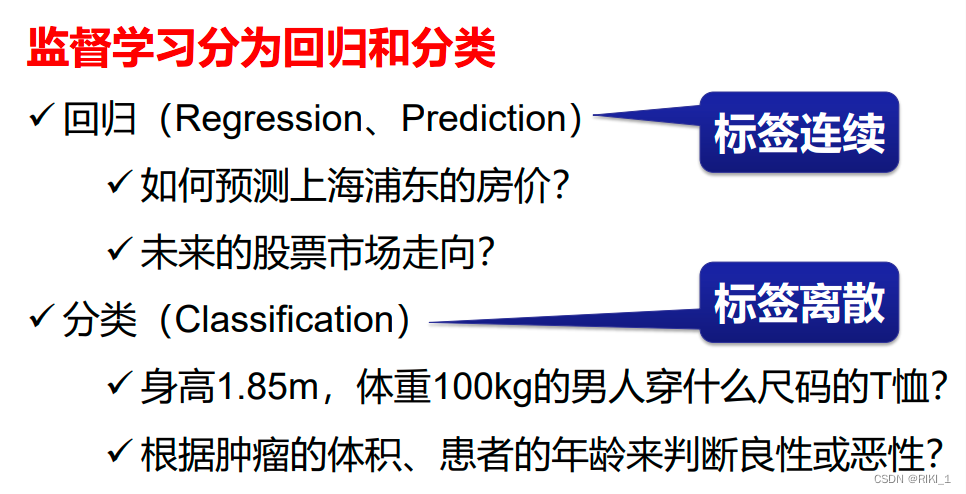
回归的概念
 二分类问题可以用1和0来表示
二分类问题可以用1和0来表示
线性回归(Linear Regression)的概念
是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化(点越靠近这条线越好)

线性回归的符号约定
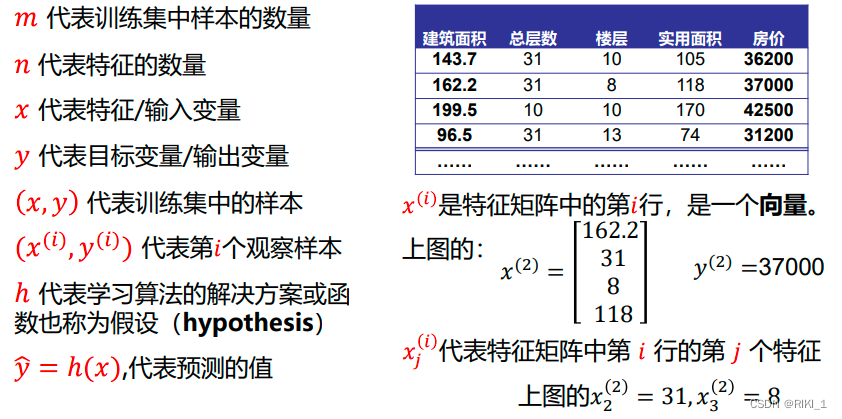
如上表所示m行记录,标签(房价)是y,前面几列列名是特征x,有n=4个特征
线性回归-算法流程
训练数据利用机器学习算法得到模型,输入特征经过模型计算得到预测结果

损失函数(Loss Function)
度量单样本预测的错误程度,损失函数值越小,模型就越好。常用的损失函数包括:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等

损失函数采用平方和损失:

要找到一组 𝑤(𝑤0, 𝑤1, 𝑤2, . . . , 𝑤𝑛) ,使得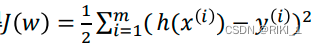 (残差平方和)最小。
(残差平方和)最小。
注:损失函数的系数1/2是为了便于计算,使对平方项求导后的常数系数为1,这样在形式上稍微简单一些。有些教科书把系数设为1/2,有些设置为1,这些都不影响结果。
代价函数(Cost Function)
度量全部样本集的平均误差。常用的代价函数包括均方误差、均方根误差、平均绝对误差等。
目标函数(Object Function)
代价函数和正则化函数,最终要优化的函数。
线性回归求解方式-最小二乘法(LSM)


梯度下降
基本思想

###梯度下降的三种形式
-
批量梯度下降(Batch Gradient Descent,BGD)
梯度下降的每一步中,都用到了所有的训练样本

-
随机梯度下降(Stochastic Gradient Descent,SGD)
梯度下降的每一步中,用到一个样本,在每一次计算之后便更新参数 ,而不需要首先将所有的训练集求和
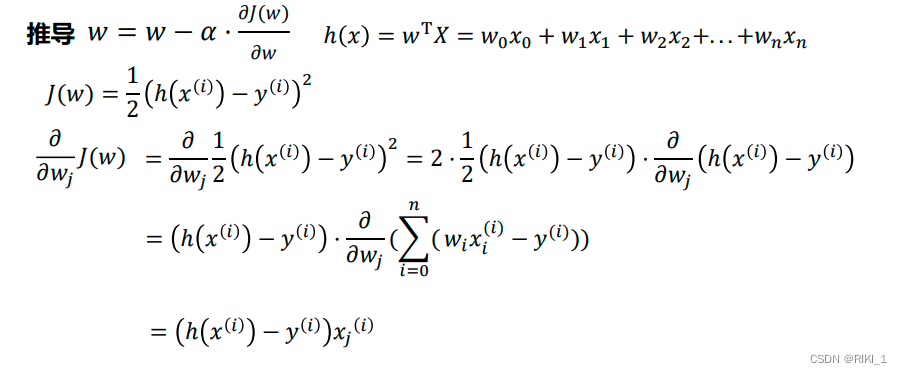
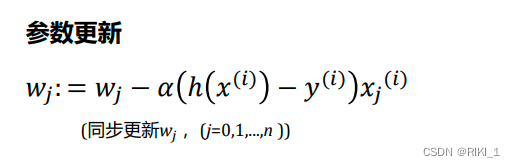
-
小批量梯度下降(Mini-Batch Gradient Descent,MBGD)
梯度下降的每一步中,用到了一定批量的训练样本,每计算常数𝑏次训练实例,便更新一次参数w
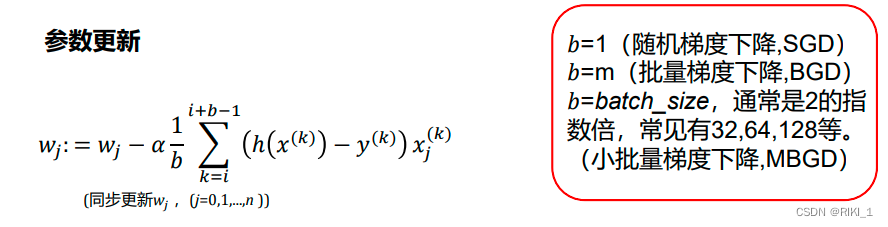
梯度下降与最小二乘法的比较
梯度下降:需要选择学习率𝛼,需要多次迭代,当特征数量𝑛大时也能较好适用,适用于各种类型的模型。
最小二乘法:不需要选择学习率𝛼,一次计算得出,需要计算 𝑋𝑇𝑋−1,如果特征数量𝑛较大则运算代价大,因为矩阵逆的计算时间复杂度为𝑂(𝑛3),通常来说当𝑛小于10000 时还是可以接受的,只适用于线性模型,不适合逻辑回归模型等其他模型。
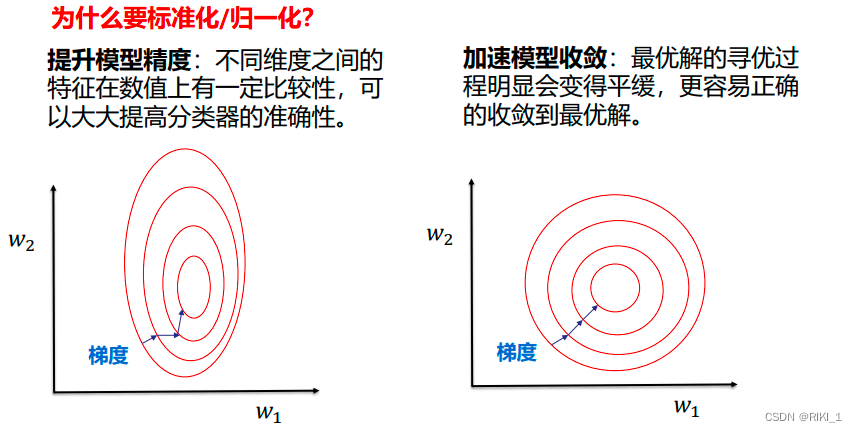
数据归一化/标准化
解决特征尺度不一样的问题
归一化(最大-最小规范化)
数据归一化的目的是使得各特征对目标变量的影响一致,会将特征数据进行伸缩变化,所以数据归一化是会改变特征数据分布的。

Z-Score标准化
数据标准化为了不同特征之间具备可比性,经过标准化变换之后的特征数据分布没有发生改变。就是当数据特征取值范围或单位差异较大时,最好是做一下标准化处理。

- 需要做数据归一化/标准化
线性模型,如基于距离度量的模型包括KNN(K近邻)、K-means聚类、感知机和SVM。另外,线性回归类的几个模型一般情况下也是需要做数据归一化/标准化处理的。 - 不需要做数据归一化/标准化
决策树、基于决策树的Boosting和Bagging等集成学习模型对于特征取值大小并不敏感,如随机森林、XGBoost、LightGBM等树模型,以及朴素贝叶斯,以上这些模型一般不需要做数据归一化/标准化处理。
拟合相关

过拟合的处理
- 获得更多的训练数据
使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。
 通过这张图可以看出,各种不同算法在输入的数据量达到一定级数后,都有相近的高准确度。于是诞生了机器学习界的名言:成功的机器学习应用不是拥有最好的算法,而是拥有最多的数据!
通过这张图可以看出,各种不同算法在输入的数据量达到一定级数后,都有相近的高准确度。于是诞生了机器学习界的名言:成功的机器学习应用不是拥有最好的算法,而是拥有最多的数据! - 降维
即丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)。 - 正则化
正则化(regularization)的技术,保留所有的特征,但是减少参数的大小(magnitude),它可以改善或者减少过拟合问题。

最后一种是把L1正则化和L2正则化混合

图上面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为L1、L2正则化给出的限制。
可以看到在正则化的限制之下, 𝐋𝟏正则化给出的最优解w是使解更加靠近原点,也就是说𝐋𝟐正则化能降低参数范数的总和。
𝐋𝟏正则化给出的最优解w是使解更加靠近某些轴,而其它的轴则为0,所以𝐋𝟏正则化能使得到的参数稀疏化。 - 集成学习方法
集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险。
欠拟合的处理
- 添加新特征
当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘组合特征等新的特征,往往能够取得更好的效果。 - 增加模型复杂度
简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。例如,在线性模型中添加高次项,在神经网络模型中增加网络层数或神经元个数等。 - 减小正则化系数
正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数
回归的评价指标
均方误差(Mean Square Error,MSE)

均方根误差 RMSE(Root Mean Square Error,RMSE) 平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差(Mean Absolute Error,MAE)

R方 [𝑅𝑆𝑞𝑢𝑎𝑟𝑒𝑑(𝑟2𝑠𝑐𝑜𝑟𝑒)]


越接近于1,说明模型拟合得越好

原文地址:https://blog.csdn.net/qq_44894943/article/details/135869809
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!