爬虫入门,爬取豆瓣top250电影信息
import requests
import csv
import parsel
import time
f = open('豆瓣top250.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['电影名','导演','主演','年份','国家','类型','简介','评分','评分人数'])
for page in range(0,250,25):
time.sleep(2)
page_new = page/25+1
print(f'正在爬取第{page_new}页内容')
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
# print(response.text)
selector = parsel.Selector(response.text)
li_list = selector.css('.grid_view li')
for li in li_list:
title = li.css('.info .hd span.title:nth-child(1)::text').get() # 获取电影的名字
movie_info_list = li.css('.bd p:nth-child(1)::text').getall() # 获取电影信息,getall获取的是列表数据
introduce = li.css('.inq::text').get() # 电影的简介
rate = li.css('.rating_num::text').get() # 电影评分
comment_num = li.css('.star span:nth-child(4)::text').get().replace('人评价', '') # 评论人数
actor_list = movie_info_list[0].strip().split(' ')
if len(actor_list) > 1:
actor_1 = actor_list[0].replace('导演: ','') # 导演
actor_2 = actor_list[1].replace('主演: ','') # 主演
actor_2 = actor_2.replace('...','')
movie_info = movie_info_list[1].strip().split(' / ')
movie_year = movie_info[0] # 年份
movie_country = movie_info[1] # 国家
movie_type = movie_info[2] # 类型
else:
actor_1 = actor_list[0]
actor_2 = 'None'
print(title,actor_1,actor_2,movie_year,movie_country,movie_type,introduce,rate,comment_num,sep='|')
csv_writer.writerow([title,actor_1,actor_2,movie_year,movie_country,movie_type,introduce,rate,comment_num])结果展现:
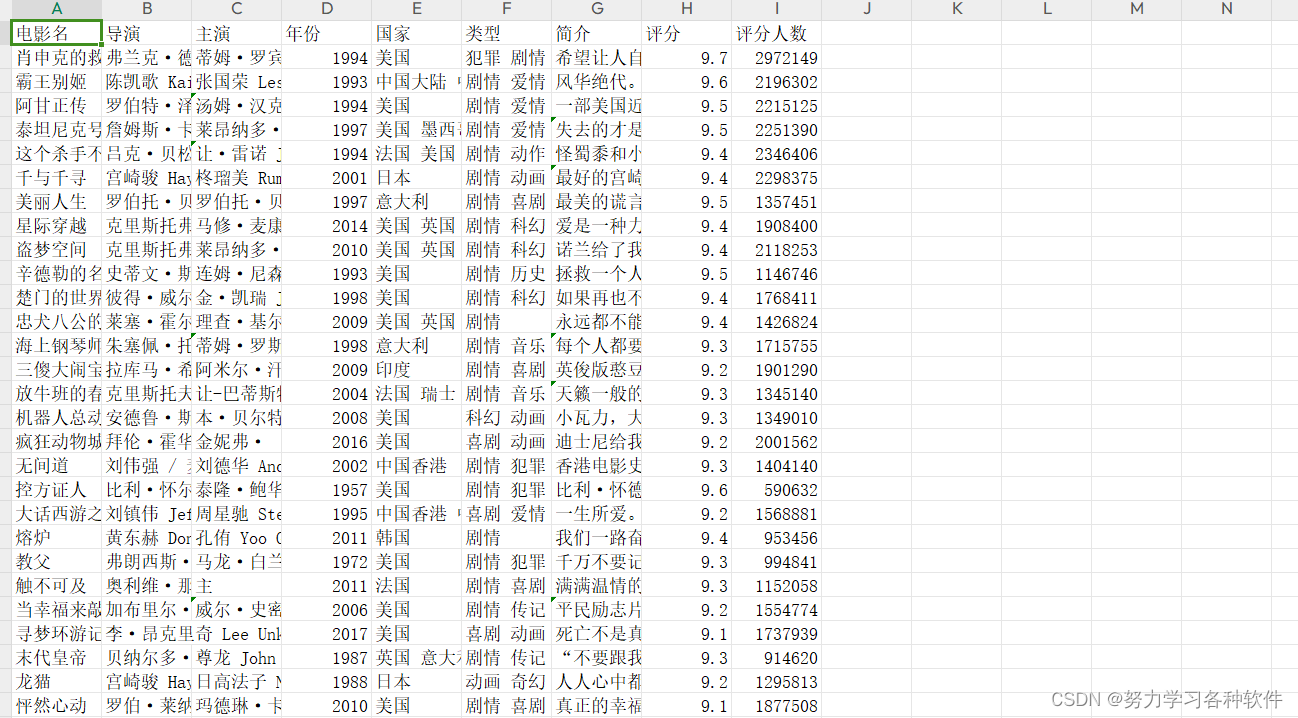
原文地址:https://blog.csdn.net/m0_57265868/article/details/135704145
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!