APE自动化指令集构建代码实现
Automatic Prompt Engineer(APE)
paper: 2023.3, LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
一语道破天机: prompt逆向工程,根据输入和输出让模型生成并寻找更优的prompt
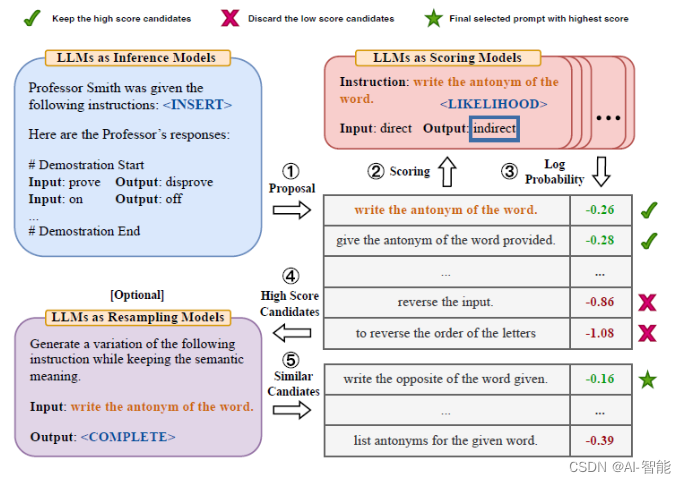
指令生成
这里作者基于原始的输入+输出,部分样本只有输出,例如自由生成类的任务,来让大模型预测,原始指令是什么。作者把指令生成的模板分成了3类,不过个人感觉其实只要一类即可,就是few-shot样本在前,待生成的指令在最后的向前生成类型,如下图

原始论文使用的是text-davinci-002来完成这个指令生成的任务,每个样本使用5条few-shot样例作为上下文,让模型输出可能的指令。这里我把生成指令的模型改成了ChatGPT(只是因为便宜),prompt模板也根据ChatGPT的特点做了调整。核心是ChatGPT作为对话模型比davinci-002,003废话要多。如果还按上面的指令来写,你可能会得到ChatGPT的回答是:我认为这个朋友收到的指令时blablabla.....
在实际测试中我还发现了几个有意思的点
-
对于相对抽象,偏生成类的任务,few-shot样本要给够,模型才有可能猜到'无偏'的指令
例如相似新闻标题生成任务:我输入了2条样本作为few-shot如下,模型预测:"将输入中的公司或组织名称规范化为全称"

我又采样了两条样本如下,模型预测:"将公司公告或新闻标题简化成简短的标题,包括公司名称和主要内容"

哈哈预测的指令确实都没毛病,只不过都是相似新闻标题生成的子集,所以你需要根据任务输入输出的多样性程度来调整你的few-shot样本数,多样性越高你需要的few-shot样例越多
-
构建指令样本,说人话很重要
例如我把以上的相似标题生成任务,简化成了判断两个标题是否描述同一事件的分类任务。最初我的输入如下。看起来也没毛病是不是?然模型的预测是:"我无法确定这个任务指令的具体内容,但它可能与文本分类或者自然语言处理相关。给出输入文本,需要判断该文本是否符合某种特定的模式或标准,从而得出输出结果"
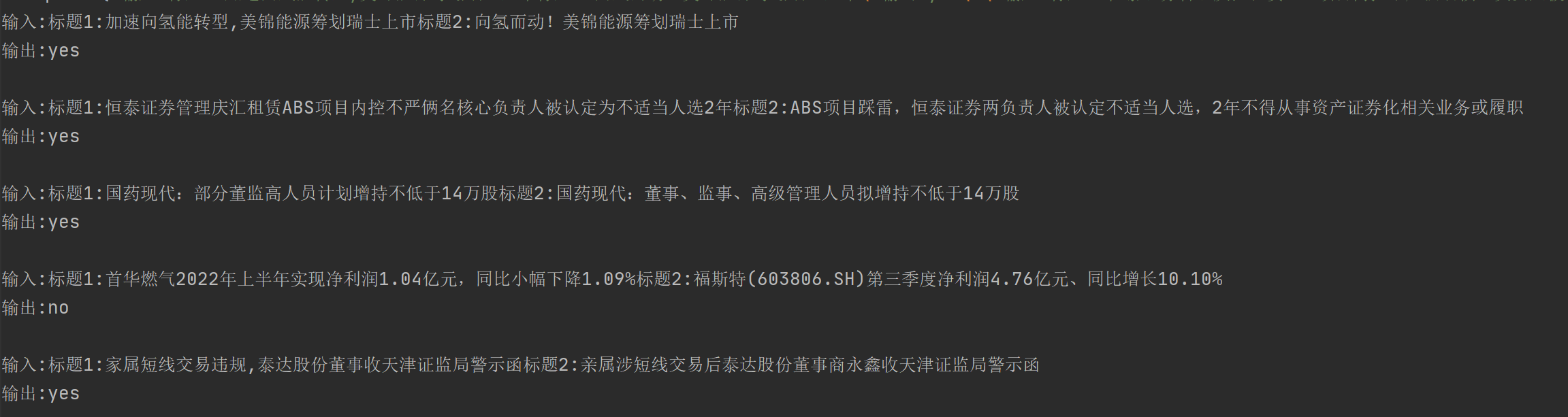
但是当我把样本中的输出改成符合任务语意的相同/不相同时,模型预测是:"判断两个新闻标题是否相同,如果相同输出"相同",否则输出"不相同"

当然考虑生成模型解码的随机性,我在第一类样本构建上多次采样也得到了类似相似度判断的指令,但整体效果都差于下面的构建方式,所以和MRC构建很相似,一切以符合语意为第一标准
-
不要你以为,要模型以为!
最初我对这种机器生成指令的方式是不太感冒的,但是在医学术语标准化这个任务上,我对比了APE得到的最优指令,和我人工写的指令,在单测时确实是模型指令,得到正确答案的概率更高。所以我大胆猜测,因为模型之间的一致性,所以合理使用模型生成的指令,能提供更精准的上下文任务描述,且理论上都应该不差于人类指令。
指令打分
这里作者使用了两种打分方式,来评估多组样本生成的多个候选指令的优劣
-
Accuracy:使用模型预测的正确率,例如对于QA问题,根据不同指令在相同样本上模型回答的准确率来评价指令的效果。
-
Log Probability:使用模型预测的logprobs作为评价指标。注意这个指标有些tricky,我最初认为和上面的Accuracy一样是让模型去预测,把预测正确的token的logprobs求和。后来发现是把输入+输出+指令都喂给模型,计算模型生成原始输出的概率,很好解决了生成类任务解码随机不同指令无法比较的问题。
如何调openai接口获取输入的logprobs: 把echo=True,logprobs=1, 就能返回所有采样token的logprobs,logprobs取值对应TopN的返回,openai最多只给你返回Top5 token,包括实际被采样的token。max_tokens=0, 不让模型生成新的文本,就可以让模型原样返回我们喂进去的输入,以及对应的模型计算的每个token的条件概率啦
同时作者加入了随机搜索,既对模型生成的指令,过滤低分的部分,对于高分的指令集,让模型基于以下指令模板,为高分指令生成相似的指令,和原始生成的指令一起排序选出最优指令。
这块实现时,我把相似指令的部分拿掉了,改成人工加入,针对得到的高分指令,补充上自己认为缺少核心的信息后使用log prob的打分方式来评估是否有提升。所以应用里,我把Generated Prompt的窗口改成了可交互的,可以直接对生成的指令做修改,再Eval效果即可。
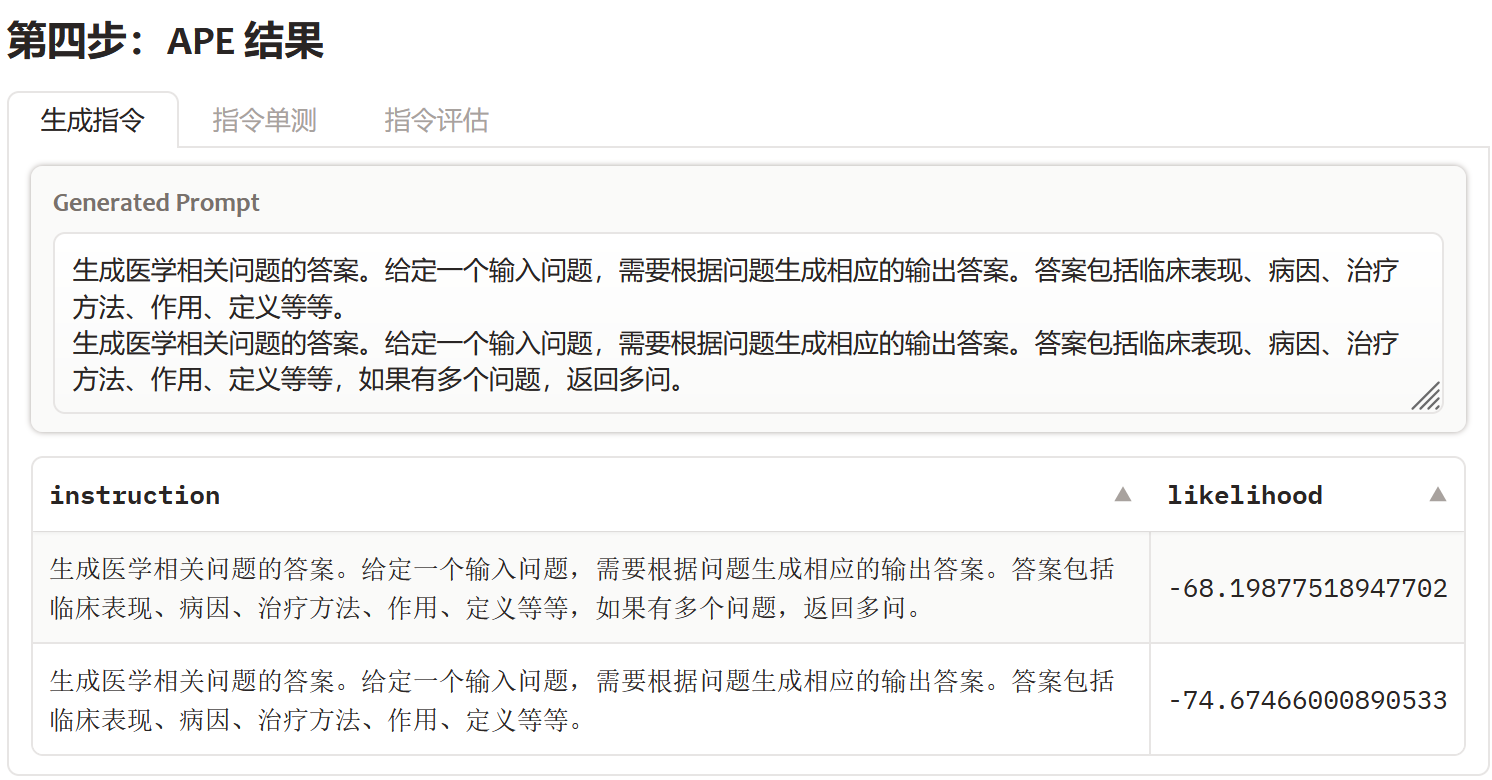
例如在医疗搜索意图的任务上,很明显模型无法理解"多问"标签是啥意思,所以最初多组样本得到的最优指令是下图的第二个,而我人工加入"多问"的指令后,得到了效果更好的第一个指令
效果
这里作者使用了REF[1]里面使用的24个指令任务,每类任务挑选5对样本,使用以上的方案得到最优的指令,再在剩余样本上,和人工指令以及REF[1]论文中使用的方案(没有搜索和打分排序的APE)以下称为greedy,进行效果对比。APE的效果在24个任务上基本可以打平人工模板甚至在部分任务上还要超越人工指令。在BigBench这类难度更高的样本上,APE在17(共21)个任务上也超越了人工指令的效果。
我在4个医学数据集上APE+人工优化得到的最优指令如下
| 任务 | 指令 |
|---|---|
| 搜索意图 | 生成医学相关问题的答案。给定一个输入问题,需要根据问题生成相应的输出答案。答案包括临床表现、病因、治疗方法、作用、定义等等,如果有多个问题,返回多问 |
| 医疗术语标准化 | 将医学手术名称的术语表述标准化。输入是医学手术的名称,输出是对该手术的名称进行修正、标准化,以供医学专业人员更好地理解 |
| 医疗药物功能实体抽取 | 给定药品信息和用途说明,根据用途说明提取出药品的主治功能。 |
| 医疗文献QA生成 | 训练一个问答系统,给定一些医学文本,能够回答用户提问关于该文本内容的问题。每个输入-输出对是一组文本和对应的问题及答案。输出的形式是以下Json格式{"问题":问题,"回答":问题,"回答":回答} |
以医学术语标准化为例我简化了APE提供的gradio应用,效果如下

原文地址:https://blog.csdn.net/2401_82469710/article/details/135688939
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!