Linux 开发工具vim、gcc/g++、makefile
目录
Linux编辑器-vim
1. 基本概念
- 控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 last line mode
- 只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
- 文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。 在命令模式下,shift+: 即可进入该模式。要查看你的所有模式:打开vim,底行模式直接输入 :help vim-modes
2. 基本操作
- $ vim test.c ,进入vim之后,是处于[正常模式],要切换到[插入模式]才能够输入文字。
- 输入a
- 输入i
- 输入o
- 目前处于[插入模式],就只能一直输入文字,如果发现输错了字,想用光标键往回移动,将该字删除,可以先按一下「ESC」键转到[正常模式]再删除文字。当然,也可以直接删除。
- 「shift + ;」, 其实就是输入「:」
- : w (保存当前文件): wq (输入「wq」,存盘并退出vim)
- : q! (输入q!,不存盘强制退出vim)
3. 正常模式命令集
- 按「i」切换进入插入模式「insert mode」,按“i”进入插入模式后是从光标当前位置开始输入文件;
- 按「a」进入插入模式后,是从目前光标所在位置的下一个位置开始输入文字;
- 按「o」进入插入模式后,是插入新的一行,从行首开始输入文字。
- 按「ESC」键。
- vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、
- 「l」,分别控制光标左、下、上、右移一格
- 按「G」:移动到文章的最后
- 按「 $ 」:移动到光标所在行的“行尾”
- 按「^」:移动到光标所在行的“行首”
- 按「w」:光标跳到下个字的开头
- 按「e」:光标跳到下个字的字尾
- 按「b」:光标回到上个字的开头
- 按「#l」:光标移到该行的第#个位置,如:5l,56l
- 按[gg]:进入到文本开始
- 按[shift+g]:进入文本末端
- 按「ctrl」+「b」:屏幕往“后”移动一页
- 按「ctrl」+「f」:屏幕往“前”移动一页
- 按「ctrl」+「u」:屏幕往“后”移动半页
- 按「ctrl」+「d」:屏幕往“前”移动半页
- 「x」:每按一次,删除光标所在位置的一个字符
- 「#x」:例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符
- 「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符
- 「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符
- 「dd」:删除光标所在行,dd+p实现剪切
- 「#dd」:从光标所在行开始删除#行
- 「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
- 「#yw」:复制#个字到缓冲区
- 「yy」:复制光标所在行到缓冲区。
- 「#yy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。
- 「p」:将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。
- 「r」:替换光标所在处的字符。
- 「R」:替换光标所到之处的字符,直到按下「ESC」键为止。
- [shift+r] :进入替换模式
- 「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次回复。
- 「ctrl + r」: 撤销的恢复
- 「cw」:更改光标所在处的字到字尾处
- 「c#w」:例如,「c3w」表示更改3个字
- 「ctrl」+「g」列出光标所在行的行号。
- 「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
大小写切换
- [shift] + [~] 按住不动可连续进行大小写转换。
4. 末行模式命令集
- 「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。
- 「#」:「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。
- 「/关键字」: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按 「n」会往后寻找到您要的关键字为止。
- 「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直 按「n」会往前寻找到您要的关键字为止。
- 「q」:按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。
- 「wq」:一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。
- !+q/w/wq 强制执行命令
不退出vim执行命令
- !+命令
5. 其他操作
- 使用vim打开一个不存在的文件,对该文件进行编辑后保存,vim会自动帮你创建该文件。
- vs + 文件名:在当前窗口创建一个新的垂直分屏,并在其中打开指定的文件。
6. 简单vim配置
- 在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。
- 而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:“.vimrc”。例如,/root目录下,
- 通常已经存在一个.vimrc文件,如果不存在,则创建之。
- 切换用户成为自己执行 su ,进入自己的主工作目录,执行 cd ~
- 打开自己目录下的.vimrc文件,执行 vim .vimrc
- 设置语法高亮: syntax on
- 显示行号: set nu
- 设置缩进的空格数为4: set shiftwidth=4
Linux编译器-gcc/g++
1、基本概念
gcc是GNU Compiler Collection(GNU编译器集合)的缩写,是一个广泛使用的编程工具,用于编译和链接C、C++、Objective-C和其他语言的源代码。
gcc主要用于将高级编程语言(如C、C++等)的源代码转换为可执行文件或库文件。它执行以下主要任务:
-
编译:
gcc将源代码文件(如.c、.cpp等)编译为机器代码文件(如.o、.obj等)。编译过程将源代码转换为汇编语言,然后再转换为机器代码。 -
链接:
gcc将编译生成的目标文件(.o、.obj等)以及所需的库文件链接在一起,生成最终的可执行文件或库文件。链接过程将解析和解决符号引用,将多个目标文件和库文件组合成一个完整的可执行文件。
除了编译和链接源代码,gcc还提供了许多选项和功能,用于优化代码、调试程序、生成调试信息、处理预处理指令等。
2、程序翻译的过程
- 预处理(进行去注释、宏替换、头文件展开、条件编译)
- 编译(C/C++ >>> 汇编)
- 汇编(汇编 >> 可重定向二进制目标文件)
- 连接(链接多个 .o .obj 合并形成可执行文件.exe)
3. gcc如何完成程序翻译
格式 gcc [选项] 要编译的文件 [选项] [目标文件]
- 预处理功能主要包括宏定义,文件包含,条件编译,去注释等。
- 预处理指令是以#号开头的代码行。
- 实例: gcc -E hello.c -o hello.i
- 选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
- 选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序,-o后面紧跟生成的目标文件。
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查
- 无误后,gcc 把代码翻译成汇编语言。
- 选项“-S”:从现在开始进行程序的翻译,如果编译完成就停下来。
- 实例: gcc –S hello.i –o hello.s
- 汇编阶段是把编译阶段生成的“.s”文件转成目标文件(二进制文件)。
- 选项“-c”从现在开始进行程序的翻译,如果汇编完成就停下来。
- 实例: gcc –c hello.s –o hello.o
- 在成功编译之后,就进入了链接阶段。
- 实例: gcc hello.o –o hello
4、动静态库
- 在我们的C程序中,虽然没有定义“printf”函数的实现,且在预编译中包含的“stdio.h”中只有该函数的声明,但实际上,“printf”等标准库函数的实现被存放在名为
libc.so.6的库文件中。 - 当使用gcc编译时,如果没有特别指定,它会默认在系统的搜索路径(通常是
/usr/lib)下查找这个库文件。通过链接到libc.so.6,程序能够实现对“printf”等函数的调用,这就是链接阶段的作用。
在Linux系统中,库文件主要有两种形式:动态库(.so文件)和静态库(.a文件)。相应地,在Windows系统中,这两种类型的库文件分别以.dll(动态库)和.lib(静态库)作为后缀名。
静态库在编译链接过程中,将库文件中的代码全部加入到生成的可执行文件中。这种方式会导致可执行文件体积较大,但好处是运行时不再依赖外部的库文件。静态库文件在Linux中一般以.a作为后缀名。
动态库的处理方式则不同,它在编译链接时不会将库文件的代码直接加入到可执行文件中。
- 相反,程序在运行时会动态地加载所需的库文件。这种方式可以减少系统资源的占用,因为多个程序可以共享同一个库文件的单个副本。
- 动态库文件在Linux中的后缀名通常为
.so,例如之前提到的libc.so.6便是一个动态库。 - 在编译时,GCC默认采用动态库链接,从而生成的二进制程序通常是动态链接的。这一点可以通过使用
file命令来验证。例如,编译生成可执行文件的命令可以是:gcc hello.o -o hello,这里GCC会默认链接到动态库。
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
- -S 编译到汇编语言不进行汇编和链接
- -c 编译到目标代码
- -o 文件输出到 文件
- -static 此选项对生成的文件采用静态链接
- -g 生成调试信息。GNU 调试器可利用该信息。
- -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库.
- -O0 -O1 -O2 -O3
- 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
- -w 不生成任何警告信息。
- -Wall 生成所有警告信息。
Linux项目自动化构建工具-make/Makefile
1、背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
2、创建makefile
要使用Makefile,您可以按照以下步骤进行:
1. 创建Makefile文件:在项目的根目录或适当的位置创建一个名为“Makefile”(或“makefile”)的文件。
2. 定义目标和规则:在Makefile中,定义您的目标和相应的规则。每个目标表示一个输出文件,而规则则指定如何生成目标。
target: dependencies//依赖关系
command//依赖方法例如,如果您有一个C程序(如“hello.c”)需要编译成可执行文件(如“hello”),Makefile可能如下所示:
hello: hello.o
gcc hello.o -o hello
hello.o: hello.c
gcc -c hello.c -o hello.o- hello: hello.o 就是依赖关系
- gcc hello.o -o hello,就是依赖方法
3. 运行make命令:在命令行中,进入到包含Makefile的目录,并运行`make`命令。
make这将根据Makefile中的规则自动构建项目。
这样,Makefile就会根据定义的规则构建和管理您的项目。这对于大型项目和多文件项目的构建过程特别有用。
3、原理
hello: hello.o
gcc hello.o -o hello
hello.o: hello.s
gcc -c hello.s -o hello.o
hello.s: hello.i
gcc -S hello.i -o hello.s
hello.i: hello.c
gcc -E hello.c -o hello.i
.PHONY:clean
clean:
rm -f hello.i hello.s hello.o hello- 上面的文件 hello ,它依赖 hell.o
- hello.o , 它依赖 hello.s
- hello.s , 它依赖 hello.i
- hello.i , 它依赖 hello.c
- 寻找Makefile:Make首先在当前目录下寻找名为“Makefile”或“makefile”的文件。
- 确定目标文件:在Makefile中,Make会查找第一个目标(target),例如“hello”,并将其作为构建过程的最终目标。
- 检查文件依赖和更新:如果目标文件“hello”不存在,或者它依赖的文件(如“hello.o”)比“hello”更新(这可以通过
touch命令模拟),Make将执行相应的命令来生成“hello”文件。 - 递归解析依赖:如果“hello”依赖的“hello.o”文件不存在,Make会在Makefile中寻找生成“hello.o”的规则,并递归地解析直到所有依赖都被构建。这个过程类似于堆栈操作,Make会一层层地解析文件依赖关系,直到所有必需的文件都被编译或更新。
- 编译和构建:在所有的C文件和H文件存在的情况下,Make将根据规则生成“hello.o”文件,然后使用它来完成最终目标“hello”的构建。
Make的核心在于管理文件之间的依赖关系。它会一步步地检查和满足这些依赖,直到达到最终的构建目标。如果在解析依赖的过程中遇到无法找到的文件,Make会停止并报错。然而,对于命令执行错误或编译失败,Make不会中断其过程,因为它主要关注的是文件依赖性。
总结来说,Make通过逐层解析和满足文件依赖,自动化地管理编译过程。这种方式极大地简化了复杂项目的构建过程,使开发者能够专注于代码开发,而不是构建过程的每一个细节。
5、项目清理
工程是需要被清理的。
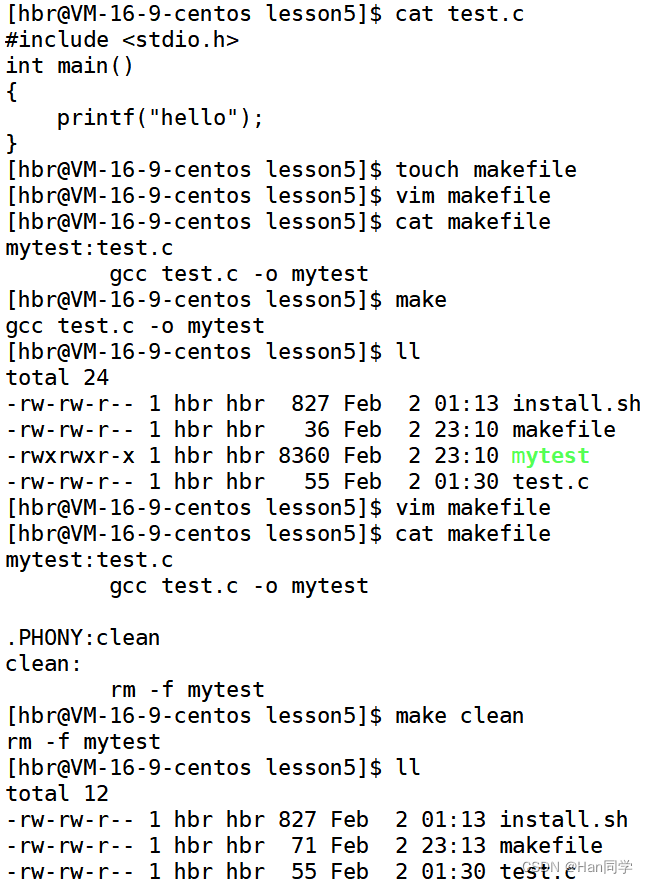
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行, 不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被执行的,总是会根据依赖关系执行依赖方法。
例: 链接三个文件
其中makefile如下:
[hbr@VM-16-9-centos lesson5]$ cat makefile
mytest:test.o main.o
gcc -o mytest test.o main.o
test.o:test.c
gcc -c test.c -o test.o
main.o:main.c
gcc -c main.c -o main.o
.PHONY:clean
clean:
rm -f *.o mytest
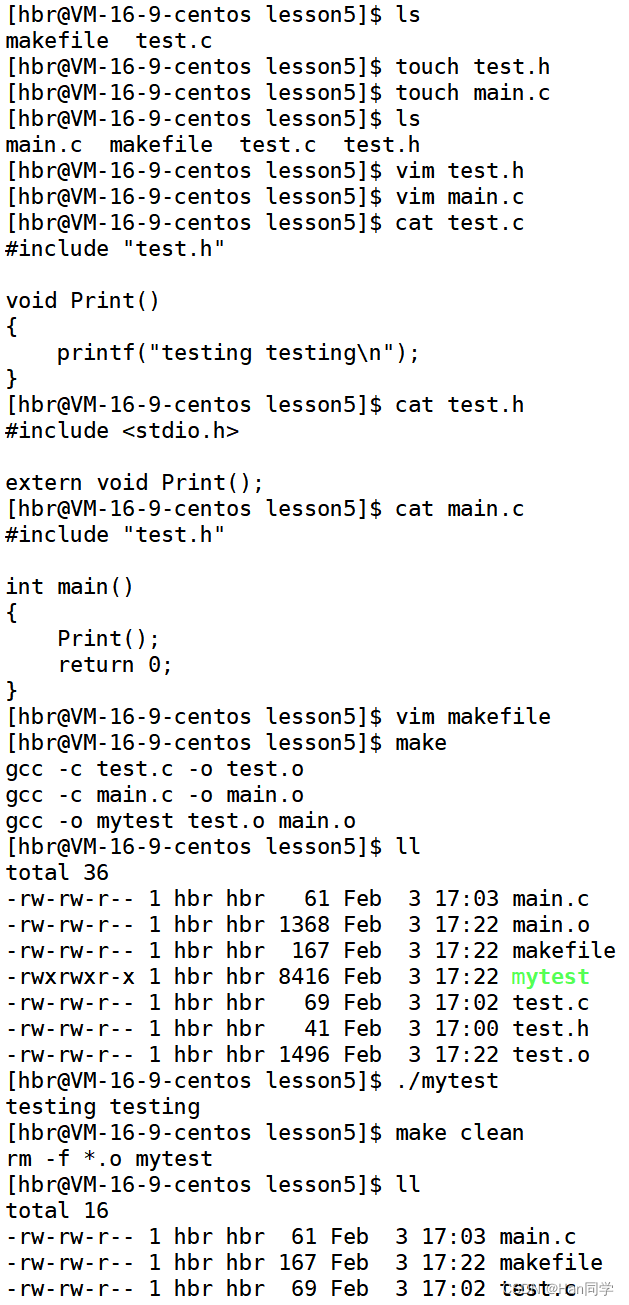
进度条小程序
1、缓冲区刷新
[hbr@VM-16-9-centos program1]$ touch test.c
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello\n");
sleep(3);
return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ls
a.out makefile proc proc.c test.c
[hbr@VM-16-9-centos program1]$ ./a.out
hello
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello");
sleep(3);
return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out 第一次输出时:先输出Hello然后3秒后结束。
第二次去掉“\n”输出时:先等待三秒然后输出Hello后结束。
当第一次执行编译后的程序时,程序会立即输出"hello",然后等待3秒钟后结束。这是因为printf函数遇到换行符\n时,会立即刷新输出缓冲区,使得"hello"紧接着被输出到屏幕上。
而在第二次执行时,由于从printf的字符串中移除了换行符\n,输出的行为有所不同。
- 在这种情况下,
printf输出的"hello"首先被存储在输出缓冲区中,并不会立即显示。 - 由于C语言的输出缓冲区是根据特定的刷新策略来刷新的,对于到显示器这种设备,其一般的刷新策略是在遇到换行符
\n时进行刷新。 - 因此,当没有换行符引导的直接刷新时,输出缓冲区会等待直到程序结束或遇到其他刷新条件才进行刷新。这就是为什么在移除
\n后,"hello"会在等待了3秒后才显示出来的原因。
2、原理
\n换行本质上是:换行(到下一行)+回车(到行首),先看代码。
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>
int main()
{
int n = 6;
while(n >= 0)
{
printf("n=%d\n",n);
n--;
sleep(1);
}
return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out
n=6
n=5
n=4
n=3
n=2
n=1
n=0
[hbr@VM-16-9-centos program1]$ vim test.c //\n换成\r
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out //没有输出结果
[hbr@VM-16-9-centos program1]$ vim test.c
[hbr@VM-16-9-centos program1]$ cat test.c
#include <stdio.h>
#include <unistd.h>
int main()
{
int n = 6;
while(n >= 0)
{
printf("n=%d\r",n);
n--;
fflush(stdout);
sleep(1);
}
return 0;
}
[hbr@VM-16-9-centos program1]$ gcc test.c
[hbr@VM-16-9-centos program1]$ ./a.out
[hbr@VM-16-9-centos program1]$//会按照倒计时输出,此处不方便展示效果- 第一个示例中,
\n用于在每次输出后换行并回到行首,这是标准的行为,使得每个输出结果都在新的一行显示,因此可以看到从n=6递减到n=0的过程,每个数字都在新的一行上。 - 然而,将
\n替换为\r时,行为发生了变化。在计算机中,\r是回车符,它的作用是将光标移回行首,但不会进入新行。这意味着如果只用\r而不是\n,所有的输出都会在同一行上发生,而且后面的输出会覆盖前面的输出。 - 在没有
fflush(stdout);的情况下,由于输出缓冲区不会因\r而刷新,可能在程序执行完毕之前看不到任何输出。这是因为输出缓冲区通常在满了或者程序结束时才会自动刷新,导致在第二次尝试中看不到输出结果。 - 引入
fflush(stdout);后,每次调用printf之后立即强制刷新输出缓冲区,使得即使是\r也能即时看到效果。这导致光标回到行首,然后用新的数字覆盖旧的数字,实现了一个简单的倒计时效果。因为光标每次都回到行首,而且立即刷新,所以你可以看到n的值从6递减到0,但这个过程中你只会在屏幕上看到一个数字的变化,而不是多行输出。
3、实现
该程序的可视化效果是一个逐步填充的进度条,旁边有一个旋转的符号表示进度正在进行,直到进度条完全填满,并显示100%。通过这种方式,可以在执行较长时间的操作时给用户一个视觉上的反馈。
[hbr@VM-16-9-centos program1]$ tree
.
├── makefile
├── proc.c
└── test.c
0 directories, 3 files
[hbr@VM-16-9-centos program1]$ cat makefile
proc:proc.c
gcc -o proc proc.c
.PHONY:clean
clean:
rm -f proc
[hbr@VM-16-9-centos program1]$ vim proc.c
[hbr@VM-16-9-centos program1]$ cat proc.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#define NUM 51
int main()
{
char bar[NUM];
memset(bar,0,sizeof(bar));
const char *lable="|/-\\";
int i=0;
while(i<=50)
{
printf("[%-50s][%d%%] %c\r",bar,i*2,lable[i%4]);
bar[i++]='#';
fflush(stdout);
usleep(30000);
}
printf("\n");
return 0;
}
[hbr@VM-16-9-centos program1]$ make
gcc -o proc proc.c
[hbr@VM-16-9-centos program1]$ ls
makefile proc proc.c test.c
[hbr@VM-16-9-centos program1]$ ./proc
[##################################################][100%] -在proc.c中,定义了一个进度条,使用字符数组bar来模拟进度条的填充情况,并通过循环逐渐增加bar数组中的#字符数量来表示进度的增加。下面是代码的逐行解释:
- 包含必要的头文件
stdio.h(用于输入输出)、string.h(用于内存操作),和unistd.h(用于usleep函数,暂停执行)。 - 定义宏
NUM为51,这个值用于定义字符数组bar的长度。 - 在
main函数中,声明字符数组bar并通过memset函数将其初始化为全0,这意味着开始时进度条是空的。 - 定义一个字符串
lable,包含四个字符"|/-\\",用于在进度条旁边显示旋转的效果,模仿一个正在进行的操作。 - 使用
while循环,条件为i小于等于50,这意味着进度条的最大填充长度为50个#字符。 - 在循环内部,使用
printf函数打印进度条。[%-50s]用于左对齐打印字符串bar,宽度固定为50个字符;[%d%%]显示当前进度的百分比,因为循环是到50,所以用i*2来计算百分比;%c用于打印旋转符号,通过lable[i%4]选择"|/-\\"中的一个字符,随着i的增加而变化。 - 每次循环时,将
bar[i]设置为#,通过递增i来模拟进度条的填充。 - 使用
fflush(stdout)强制刷新标准输出,确保每次循环的输出都能立即显示而不是等缓冲区满。 usleep(30000)暂停30毫秒(30000微秒),这样用户可以看到进度条的逐步填充和旋转符号的动态变化。- 循环结束后,打印一个换行符
\n,以避免在命令行提示符出现之前光标停留在进度条的末尾。 - 函数返回0,表示程序正常结束。
原文地址:https://blog.csdn.net/m0_73800602/article/details/135983303
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!