昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要
昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要
1. 环境设置
本项目可以沿用前两个项目的相关环境设置。首先,登陆昇思大模型平台,并进入对应的开发环境:
https://xihe.mindspore.cn/my/clouddev
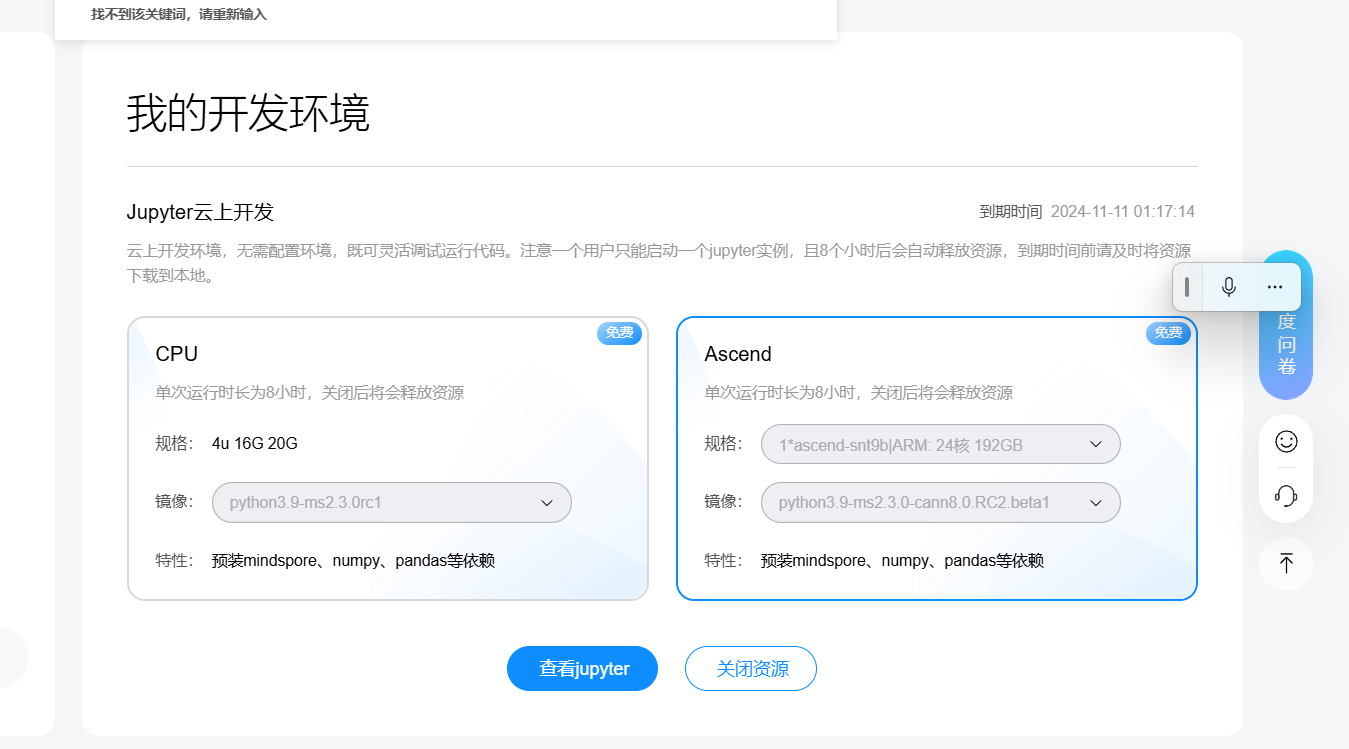
接着,启动Ascend环境,然后点击“查看Jupyter”,这样就可以进入我们的开发环境。
为了帮助大家熟悉环境,我们每次都会重申这个步骤。熟练掌握环境的启动方法对于后续的学习非常有帮助。
2. 介绍GPT2模型
GPT2(Generative Pretrained Transformer 2)是由OpenAI开发的语言模型,它通过大规模无监督预训练和微调(Fine-tuning)在多个自然语言处理任务中取得了显著的效果。GPT2模型主要采用自回归的Transformer架构,可以生成连贯的文本,适用于文本摘要、文本生成等任务。
在本次实验中,我们将使用GPT2模型来进行文本摘要任务。
3. 数据集加载与处理
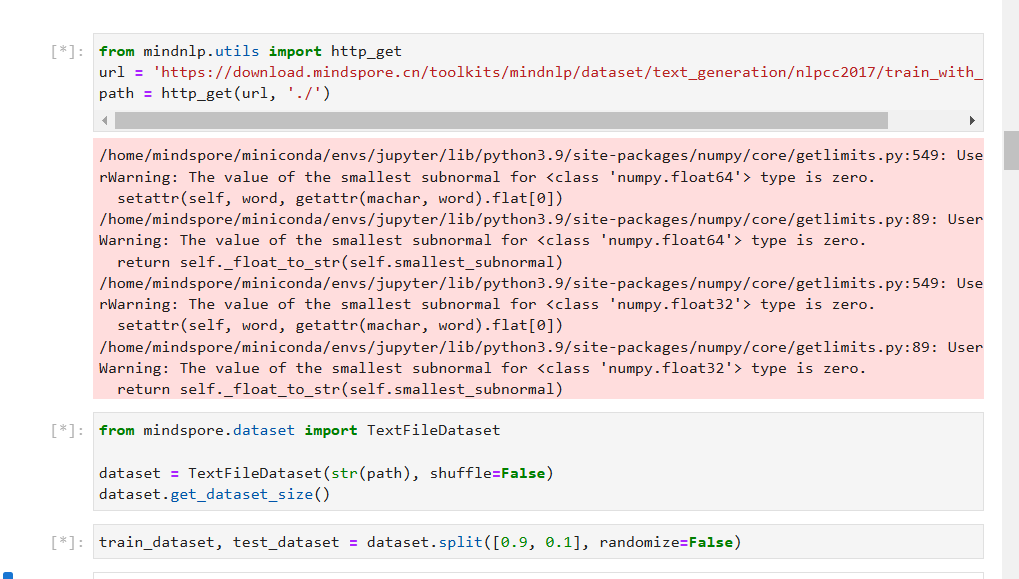
1. 数据集加载
本次实验使用的nlpcc2017摘要数据集,该数据集包含新闻正文及其对应的摘要,总共有50000个样本。数据集包含了丰富的新闻内容,可以为模型提供足够的训练数据。
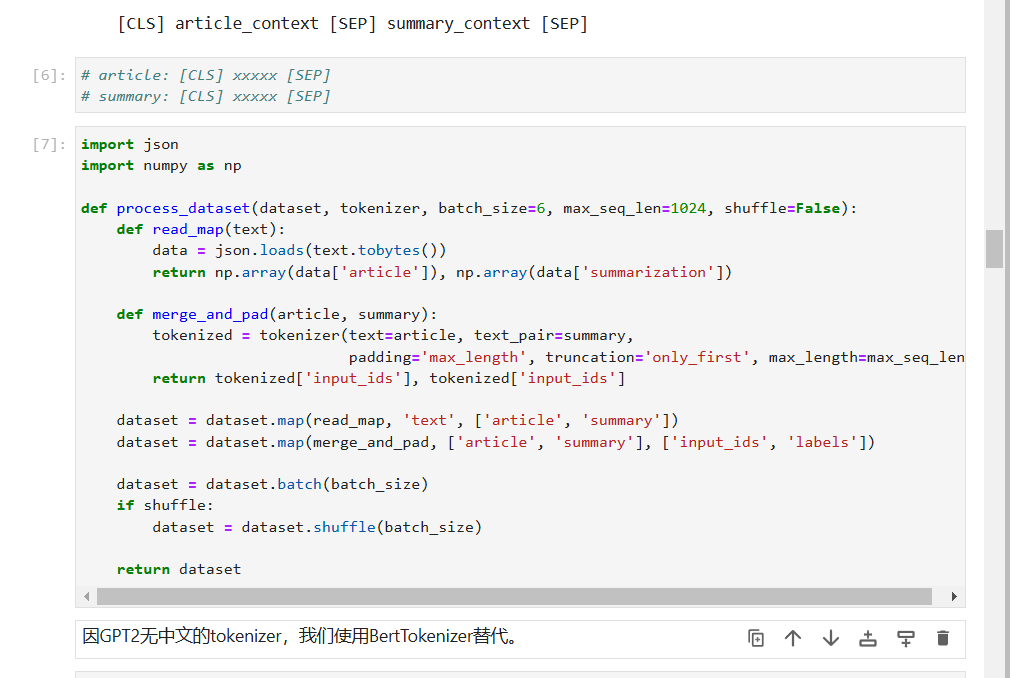
2. 数据预处理
原始数据的格式如下:
article: [CLS] article_context [SEP]
summary: [CLS] summary_context [SEP]
为了方便模型处理,我们对数据进行了预处理,将其转换为以下格式:
[CLS] article_context [SEP] summary_context [SEP]
通过这种格式,模型可以同时读取文章和摘要内容,从而生成摘要。数据预处理的核心是将文本进行tokenization,并且确保每个样本都能通过统一格式输入到模型中。
4. 模型构建
1. 构建GPT2ForSummarization模型
在这个实验中,我们基于GPT2构建了用于文本摘要的模型——GPT2ForSummarization。在训练过程中,需要特别注意shift right的操作,即生成摘要时,模型的目标是预测下一个词,并且在训练时,输入序列的目标会与输出序列的目标错开一个位置。
这一操作是生成任务中的关键,能够帮助模型有效地学习如何生成符合上下文的摘要。
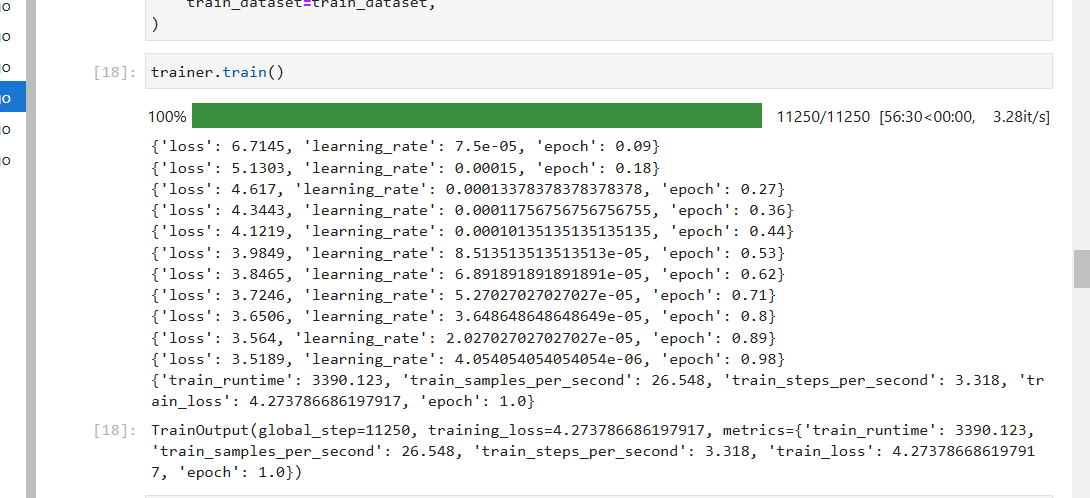
2. 模型训练与评估
训练过程中,模型的效果逐步提高,虽然训练时间相对较长,但最后的训练效果相当不错。随着训练的进行,模型能够较好地理解新闻文章与其摘要之间的关系,生成准确且简洁的摘要内容。
训练时需要使用适当的评估指标,如ROUGE分数,来衡量模型生成摘要的质量。ROUGE分数是文本摘要任务中常用的评估指标,能够有效评估生成摘要与参考摘要之间的重叠度。
5. 总结
通过本项目,我们使用了MindSpore平台中的GPT2模型来完成文本摘要任务。该项目的成功实施展示了GPT2在文本摘要领域的强大能力,同时也展示了如何在MindSpore平台上快速构建和训练自然语言处理模型。
整个实验过程中,我们重点讲解了数据预处理、模型构建以及训练过程中的关键操作,如shift right。虽然训练时间较长,但模型的效果证明了该方法在文本摘要中的有效性。
本项目通过在MindSpore平台上实现GPT2模型的训练和应用,完成了新闻文章的自动摘要生成,为自然语言处理任务提供了一个实际且有效的解决方案。
原文地址:https://blog.csdn.net/weixin_54227557/article/details/143668055
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!