Shell之(数组)
目录
一、shell数组
1.数组的定义
由多个元素之间以空格分隔的元素组成
数组的元素可使用的数据类型可以是:数字 或 “字符串” / ’字符串‘;元素存在下标等于n-1.
2.定义数组的方法
第一种
数组名=(值1 值2 值3 ... )
以空格间隔,如果值为字符类型,需要加单引号或双引号[root@localhost ~]# a=(1 2 3 4 5 6)
[root@localhost ~]# echo ${a[@]}
1 2 3 4 5 6
[root@localhost ~]# echo ${a[*]} # @和*作用都一样查看数组全部
1 2 3 4 5 6
[root@localhost ~]# echo ${a[0]} # 通过下标查看具体值
1
[root@localhost ~]# echo ${a[1]}
2
[root@localhost ~]# echo ${a[2]}
3
[root@localhost ~]#

查看下标
-
[root@localhost ~]# echo ${!a[*]} # !显示下标 0 1 2 3 4 5
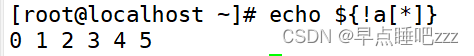
获取元素长度
-
[root@localhost ~]# echo ${#a[*]} # 添加#显示长度 6

第二种
2.数组名=([0]=值 [1]=值 [2]=值 ...)
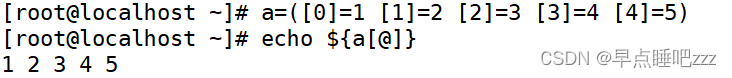
第三种
列表名="value0 value1 value2 ..."
数组名=($列表名)
第四种
数组名 [0]="value"
数组名 [1]="value"
数组名 [2]="value" echo ${z[*]} #所有元素展开
echo ${#z[*]} #查看长度
echo ${!z[*]} #查看下标
3.数组分片
echo ${数组名[@]:下标:长度}
echo ${数组名[*]:下标:长度}
echo ${z[*]:1:2} 2:保留几位
1:从指定下标开始4. 数组字符替换
临时替换,字符串替换而不是替换元素组内容
echo ${数组名[@]/旧字符/新字符}
数组名=(${数组名[*]/旧字符/新字符}) 通过重新定义的方式实现永久替换
临时替换
echo ${数组名[*]/被替换的字符或字段/新的字符或字段} 
永久替换
数组名=(${数组名[*]/旧字符/新字符})
5.删除数组
根据下标删除某个下标和删除整个数组
unset 数组名[下标] 删除数组的某个下标
unset 数组名 删除数组删除指定的下标

删除整组

6.数组遍历和重新定义
zz=(2 4 6 8 10)
n=0
for i in ${zz[@]}
do
arr[$n]=$[i*2]
let n++
done7.数组追加元素
方式一:指定位置添加
数组名[新下标]=新元素方法二: 末尾追加元素
格式: 数组名[${#数组名[*]}] =新元素 或 数组名[${#数组名[@]}] =新元素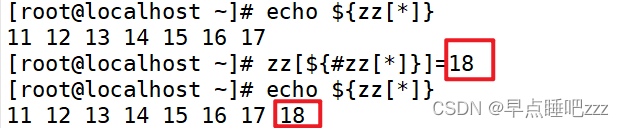
方式三:进行末尾多元素追加
数组名=("${数组名[@]}" 新元素1 新元素2 ....)
方法四:直接末尾追加多元素且格式最为简单
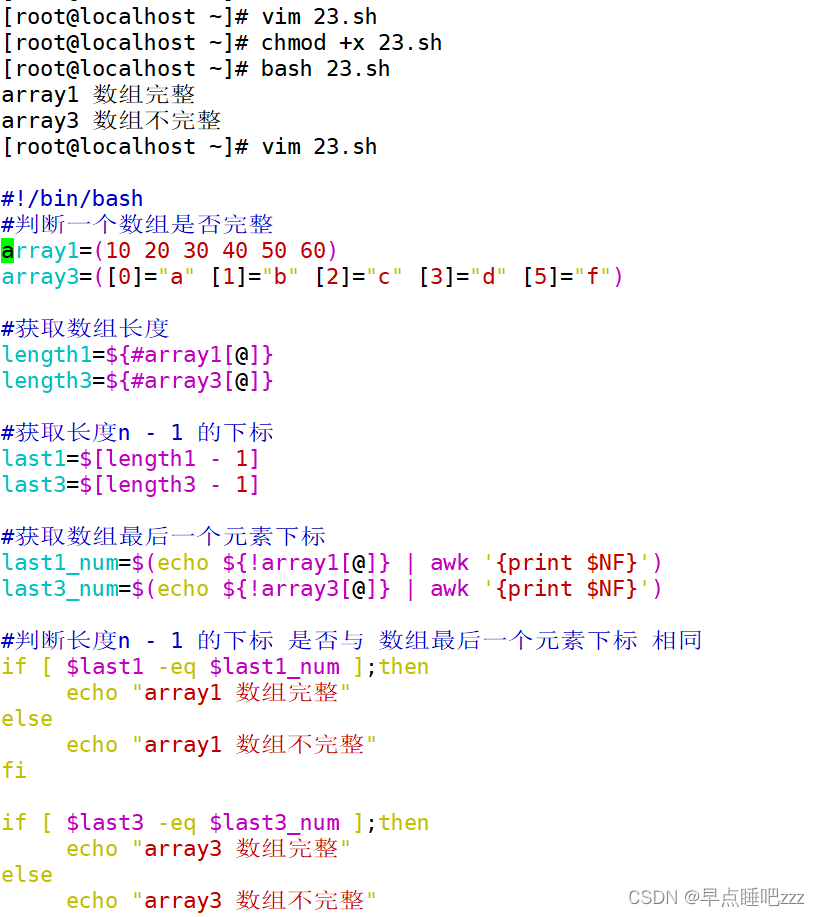
数组名=("${数组名[@]}" 新元素1 新元素2 ....) 8.用函数判断数组是否完整

#!/bin/bash
#判断一个数组是否完整
array1=(10 20 30 40 50 60)
array3=([0]="a" [1]="b" [2]="c" [3]="d" [5]="f")
#获取数组长度
length1=${#array1[@]}
length3=${#array3[@]}
#获取长度n - 1 的下标
last1=$[length1 - 1]
last3=$[length3 - 1]
#获取数组最后一个元素下标
last1_num=$(echo ${!array1[@]} | awk '{print $NF}')
last3_num=$(echo ${!array3[@]} | awk '{print $NF}')
#判断长度n - 1 的下标 是否与 数组最后一个元素下标 相同
if [ $last1 -eq $last1_num ];then
echo "array1 数组完整"
else
echo "array1 数组不完整"
fi
if [ $last3 -eq $last3_num ];then
echo "array3 数组完整"
else
echo "array3 数组不完整"
fi
函数名() {
数组2=($@) #在函数体内将传入的列表重新组成数组
....
}
函数名 ${数组1[@]} #在函数体外将数组分解成列表传入
9. Shell向函数传数组参数
函数名() {
数组2=($@) #在函数体内将传入的列表重新组成数组
....
}
函数名 ${数组1[@]} #在函数体外将数组分解成列表传入
10.Shell从函数返回数组
函数名(){
....
echo ${数组2[@]} #在函数体内以列表形式返回值
}
数组1=(函数名 参数) #在函数体外将函数执行的结果重新组合成数组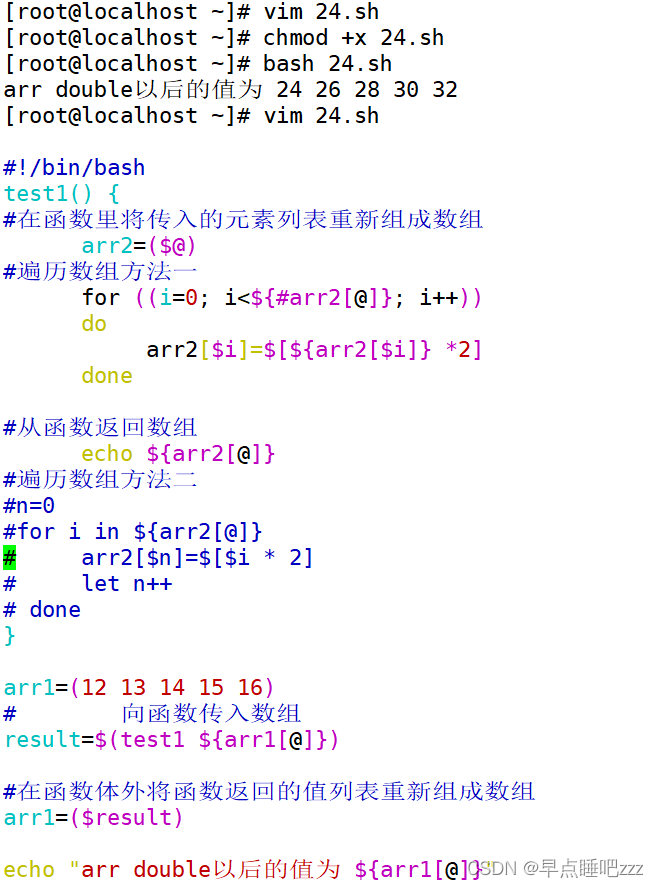
二.数组排序算法(拓展)
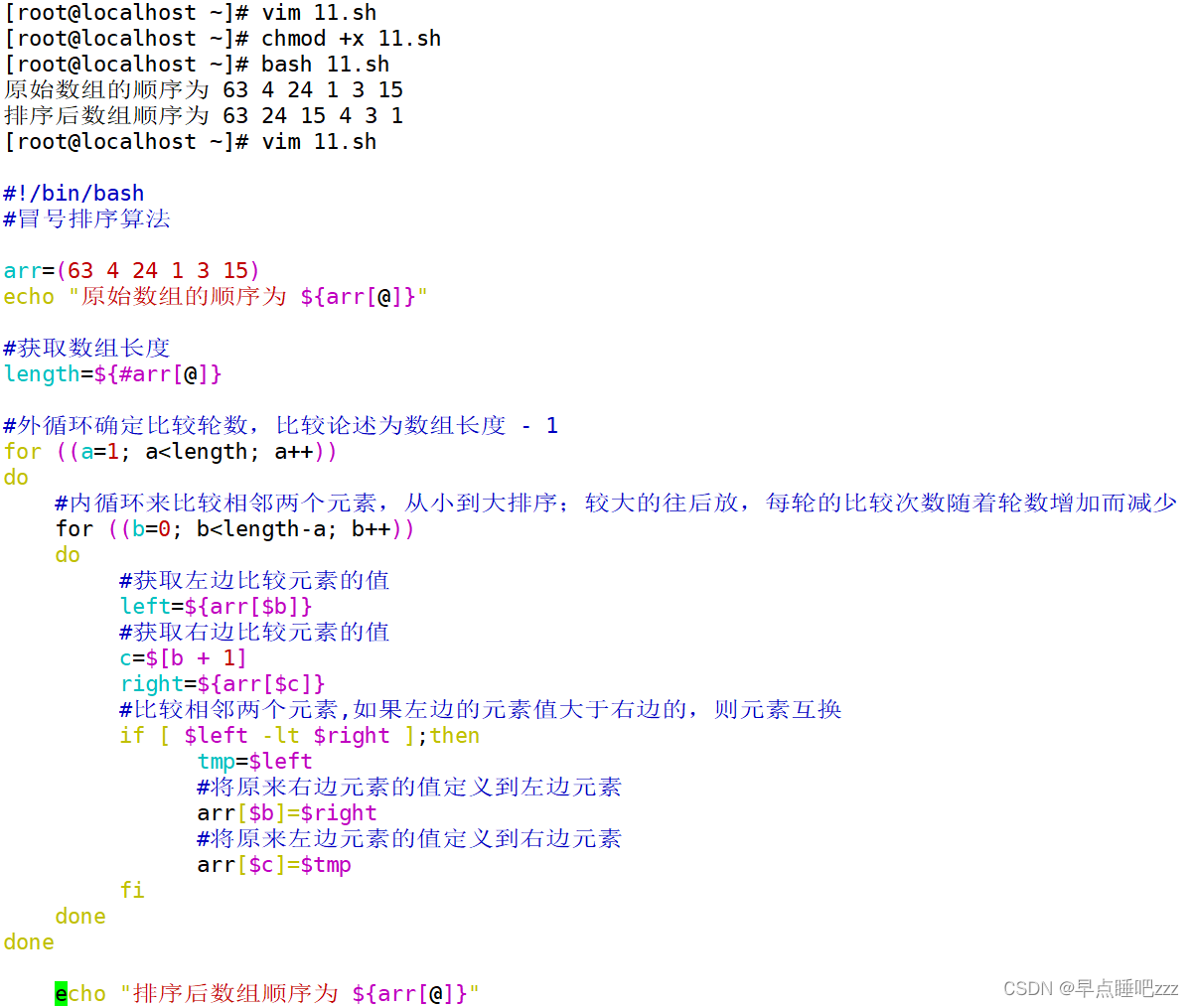
1.冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断地向前移动。
基本思想
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到
数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部
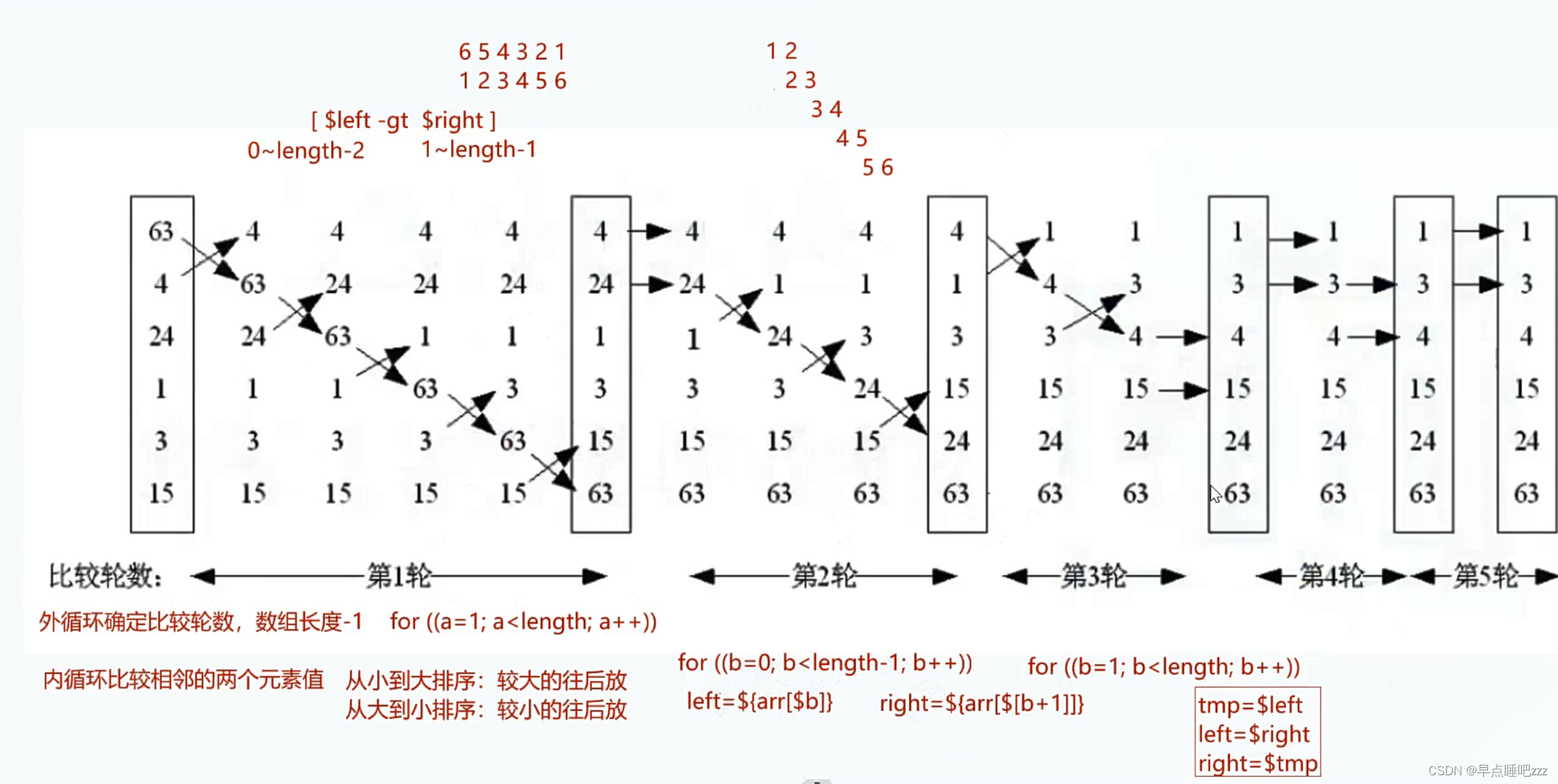
算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因
为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用
于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少
2.直接选择排序
与冒泡排序相比,直接选择排序的交换次数更少,所以速度会快些。
基本思想:
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。
实操

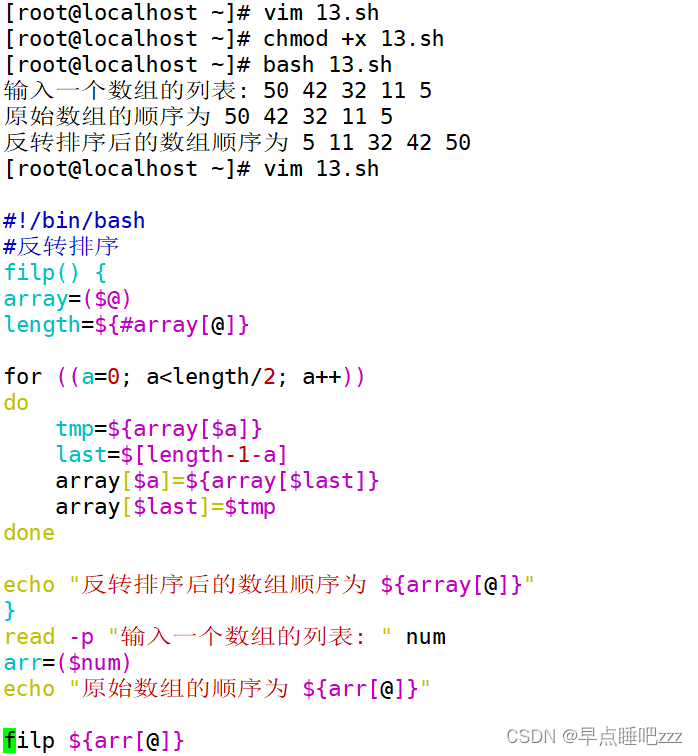
3.反转排序
概述
以相反的顺序把原有数组的内容重新排序
把数组最后一个元素与第一个元素替换,倒数第二个元素与第二个元素替换,以此类推,直到把所
有数组元素反转替换
实操↓
原文地址:https://blog.csdn.net/aran2002/article/details/138872557
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!