transformer学习
原理学习
与CNN、RNN的特点对比
CNN:对相对位置敏感,对绝对位置不敏感。
卷积时通常把序列分成很多小窗口,每个窗口的权重是一样的,即权值共享,在窗口内进行加权求和。前后没有关联性,可并行计算且平移不变形。是局部关联性建模,依靠多层堆积进行长程建模。
RNN:依次有序递归建模,当前时刻输出依赖于当前时刻输入和之前时刻输出。
对顺序敏感,串行计算耗时大,不能长程建模,计算复杂度与序列长度呈线性关系,单步计算复杂度不变,对相对位置和绝对位置都敏感。
transformer:
- 无局部假设,对相对位置不敏感,可并行计算。
- 无有序假设,对绝对位置不敏感,所以需要位置编码来反映位置变化对特征的影响。
- 不论远近,任意两个字符都可以建模,擅长长短程建模,但是所用的自注意力机制是序列长度的平方级别复杂度。
- 数据量的要求与先验假设的程度成反比。
transformer结构
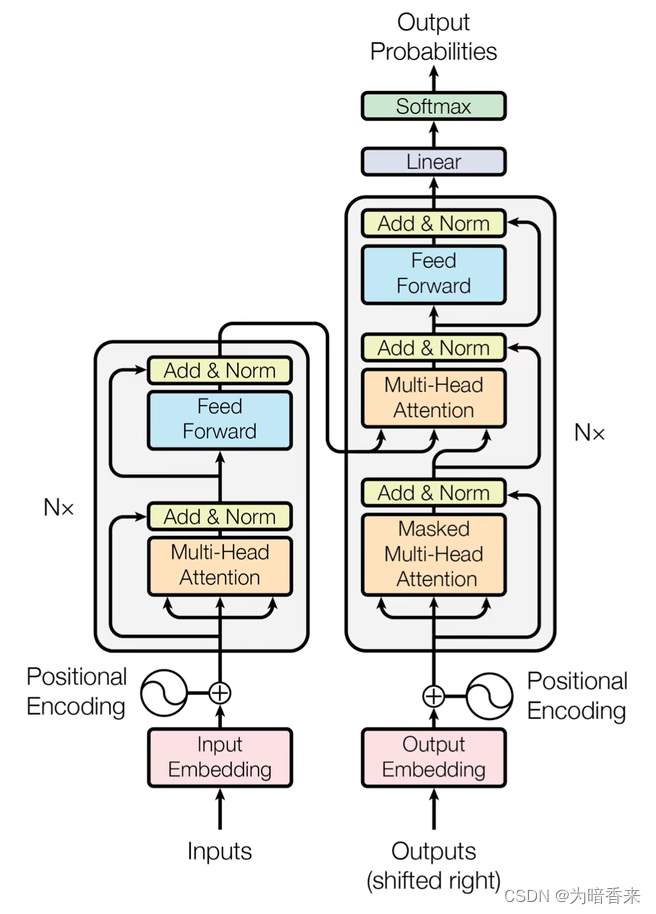
transformer模型结构由Encoder和Decoder两部分构成。
- Encoder部分首先接收输入字符的词编码Word_Embedding和位置编码Position_Embedding,然后由N个block构成,首先Multi-Head Attention是对输入序列自身的表征运算,然后通过前馈神经网络。
- Decoder部分首先接收目标序列的词编码和位置编码,然后也是N个block,内部首先是Masked Multi-Head Attention,对序列自身表中运算,但是要符合因果,即当前字符不能获取到之后的字符。然后再通过一个Multi-Head Attention,将Decoder模块和Encoder模块关联起来,再通过前馈神经网络。N个blok之后通过线性层进入映射到概率空间,分类到每个单词。
除此之外,每个模块还有残差连接,保证位置编码信息充分传到上层。
Encoder
- Input Word Embedding:由稀疏的one-hot进入一个不带bias的FFN得到一个稠密的连续向量,节约内存,表征更加丰富。
- Position Encoding:为了使得不同序列长度句子的每个位置的编码是确定的,而且对于不同的句子相同位置的距离要一致,还可以推广到更长的测试句子。因此通过sin/cos来固定表征,由于sin/cos的特点,所以pe(pos+φ)可以写成pe(φ)的线性组合。
- Multi-Head Attention:多头注意力机制,可以捕捉到更多的位置与位置之间的关系,使得建模能力更强,表征空间更丰富。计算由多组Q(Query)、K(Key)、V(Value)构成,每组单独计算一个attention向量,再把每组的attention向量拼起来,进入FFN得到最终向量,可以得到每个字符与其他所有字符的关系。
- Feed-Forward Network:只考虑每个单独位置进行建模,不同位置参数共享,1×1的卷积。FFN层与Multi-Head Attention的区别是Multi-Head Attention是将字符位置进行融合,FFN是将特征进行融合。
Decoder
- Output Word Embedding、Position Encoding:与Encoder部分类似,输入为预测序列。
- Masked Multi-Head Attention:带掩码的注意力机制,对于目标序列的输入,当前位置字符不能观察到之后位置的字符,只能观察到之前的字符,所以mask矩阵是一个下三角矩阵。
- Multi-Head Attention:这里是交叉注意力机制,即要结合Encoder和Decoder部分,其中Q来自Decoder,K和V来自Encoder。
- Feed-Forward Network:与Encoder类似。
- Softmax:预测输出单词概率。
使用类型
- Encoder:BERT、分类任务、非流式任务
- Decoder:GPT系列、语言建模、自回归生成任务、流式任务
- Encoder&Decoder:机器翻译、语音识别
代码实现部分结构,以序列建模为例(其字符以其在词表的索引的形式表示)
1. 初始化
batchsize设为2表示原序列与目标序列的句子个数
单词表大小设为8
模型特征大小设为8
序列最大长度设为5
序列长度可随机初始化(注释掉了),这里使用固定长度
import torch
import numpy
import torch.nn as nn
import torch.nn.functional as F
# word embedding 序列建模
# source sentence 和 target sentence 离散的
# 构建序列,其字符以其在词表的索引的形式表示
batch_size = 2
# 单词表大小
max_num_src_words = 8
max_num_tgt_words = 8
# 模型特征大小
model_dim = 8
# 序列最大长度
max_src_seq_len = 5
max_tgt_seq_len = 5
# 序列中的最大位置长度
max_position_len = 5
# src_len = torch.randint(2, 5, (batch_size,)) # 随机生成原序列长度,2到5之间
# tgt_len = torch.randint(2, 5, (batch_size,)) # 随机生成目标序列长度
# 固定长度
src_len = torch.tensor([2, 4]).to(torch.int32)
tgt_len = torch.tensor([4, 3]).to(torch.int32)
构建单词索引构成的句子,padding为最大长度,默认补零,然后将原序列与目标序列的句子合并为矩阵。
# 单词索引构成的句子(pad为最大长度,默认为0)
src_seq = [F.pad(torch.randint(1, max_num_src_words, (L, )), (0, max_src_seq_len-L)) for L in src_len]
tgt_seq = [F.pad(torch.randint(1, max_num_tgt_words, (L, )), (0, max_tgt_seq_len-L)) for L in tgt_len]
# 句子合并为2维矩阵
src_seq_d = torch.stack(src_seq)
tgt_seq_d = torch.stack(tgt_seq)
2. 构建word embedding
构建原序列和目标序列的word embedding(因为词表是1-8,padding为0,所以max_num_src_words要+1)
生成的embedding表为max_num_src_words+1行model_dim列(9行8列)
# 构造embedding
src_embedding_table = nn.Embedding(max_num_src_words+1, model_dim) # 因为词表是1-8,padding为0,所以max_num_src_words要+1
tgt_embedding_table = nn.Embedding(max_num_tgt_words+1, model_dim)
src_embedding = src_embedding_table(src_seq_d)
tgt_embedding = tgt_embedding_table(tgt_seq_d)
print(src_embedding_table.weight)
print(src_seq_d)
print(src_embedding)
print(tgt_embedding_table.weight)
print(tgt_seq_d)
print(tgt_embedding)
3. 构造position embedding(原理如图所示)
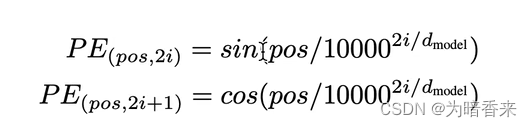
其中pos 是词语在序列中的位置(从0开始),i 是维度索引(从0开始),dmodel是模型的维度大小,PE 是位置编码矩阵
初始化位置编码表,并根据公式计算出奇数列与偶数列填入编码矩阵
pos_mat = torch.arange(max_position_len).reshape((-1, 1)) # 1列,是词语在序列中的位置(从0开始)
i_mat = torch.arange(0, max_num_src_words, 2).reshape((1, -1))/model_dim # i是维度索引(从0开始)
i_mat = torch.pow(10000, i_mat)
pe_embedding_table = torch.zeros(max_position_len, model_dim) # 初始化位置编码表
pe_embedding_table[:, 0::2] = torch.sin(pos_mat / i_mat) # 填入偶数列
pe_embedding_table[:, 1::2] = torch.cos(pos_mat / i_mat) # 填入奇数列
创建嵌入层,将 pe_embedding_table 设置为嵌入层的权重矩阵
pe_embedding = nn.Embedding(max_position_len, model_dim) # 创建嵌入层
pe_embedding.weight = nn.Parameter(pe_embedding_table, requires_grad=False) # 将 pe_embedding_table 设置为嵌入层的权重矩阵
为每个序列生成位置编码索引,获取位置编码并调整维度为(batch_size,max_position_len,model_dim)(2,5,8),将位置编码position_embedding添加到词嵌入word_embedding中。
src_positions = torch.arange(max(src_len)).unsqueeze(1).expand(-1, max_src_seq_len) # 为每个序列生成位置编码索引
tgt_positions = torch.arange(max(tgt_len)).unsqueeze(1).expand(-1, max_tgt_seq_len)
# 获取位置编码
src_pe = pe_embedding(src_positions)
tgt_pe = pe_embedding(tgt_positions)
# 根据实际序列长度调整位置编码
src_pe = src_pe[:batch_size, :, :]
tgt_pe = tgt_pe[:batch_size, :, :]
# 将位置编码添加到单词嵌入中
src_embedding_with_pe = src_embedding + src_pe
tgt_embedding_with_pe = tgt_embedding + tgt_pe
4. 构造encoder的self-attention的mask
shape为:[batch_size, max_src_len, max_src_len], 值为1或-inf,目的是掩盖不同长度序列所Padding的多余部分。
先构建有效编码位置valid_encoder_pos,它的维度是[batch_size, max_src_len, 1],将它乘以它的转置得到有效编码位置矩阵,再用1减去它得到无效矩阵进而转为bool类型,得到mask_encoder_self_attention。
valid_encoder_pos = torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max_src_seq_len - L)), 0) for L in src_len]) # padding有效位置张量
valid_encoder_pos = torch.unsqueeze(valid_encoder_pos, 2) # 扩第“2”维保证它乘它的转置为[batch_size, max_src_len, max_src_len]形状
valid_encoder_pos_matrix = torch.bmm(valid_encoder_pos, valid_encoder_pos.transpose(1, 2)) # bmm三维矩阵相乘
invalid_encoder_pos_matrix = 1 - valid_encoder_pos_matrix # 无效矩阵
mask_encoder_self_attention = invalid_encoder_pos_matrix.to(torch.bool)
score = torch.randn(batch_size, max_src_seq_len, max_src_seq_len)
masked_score = score.masked_fill(mask_encoder_self_attention, -1e9)
prob = F.softmax(masked_score, -1)
# print(src_len)
# print(score)
# print(masked_score)
# print(prob)
5. 构造intra-attention的mask
Q*K^T shape:[batch_size, tgt_seq_len, src_seq_len]
类似操作构建valid_encoder_pos和valid_decoder_pos,valid_decoder_pos乘以valid_encoder_pos的转置,再用类似方法得到mask_cross_attention。
valid_encoder_pos = torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max_src_seq_len - L)), 0) for L in src_len])
valid_encoder_pos = torch.unsqueeze(valid_encoder_pos, 2)
valid_decoder_pos = torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max_tgt_seq_len - L)), 0) for L in tgt_len])
valid_decoder_pos = torch.unsqueeze(valid_decoder_pos, 2)
valid_cross_pos_matrix = torch.bmm(valid_decoder_pos, valid_encoder_pos.transpose(1, 2))
invalid_cross_pos_matrix = 1 - valid_cross_pos_matrix
mask_cross_attention = invalid_cross_pos_matrix.to(torch.bool)
# print(valid_encoder_pos)
# print(valid_decoder_pos)
# print(valid_cross_pos)
6. 构造decoder self-attention的mask(遮住答案,预测某个字符时只给出一个特殊字符和它前面的字符)
valid_decoder_tri_matrix构造成下三角矩阵,shape:(batch_size, max_tgt_seq_len, max_tgt_seq_len),后面方法同上。
valid_decoder_tri_matrix = torch.cat([torch.unsqueeze(F.pad(torch.tril(torch.ones((L, L))), (0, max_tgt_seq_len - L, 0, max_tgt_seq_len - L)), 0) for L in tgt_len])
invalid_decoder_tri_matrix = 1 - valid_decoder_tri_matrix
mask_decoder_self_attention = invalid_decoder_tri_matrix.to(torch.bool)
score = torch.randn(batch_size, max_tgt_seq_len, max_tgt_seq_len)
masked_score = score.masked_fill(mask_decoder_self_attention, -1e9)
prob = F.softmax(masked_score, -1)
print(valid_decoder_tri_matrix)
print(valid_decoder_tri_matrix.shape)
print(tgt_len)
print(prob)
7. 构建scaled self-attention
计算公式如图:
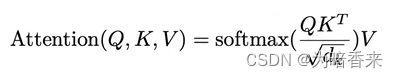
shape of Q,K,V:(batch_size * num_head, seq_len, model_dim / num_head)
attn_mask即为6,5,4得到的3种mask。
def scaled_dot_product_attention(Q, K, V, attn_mask): # shape of Q,K,V:(batch_size * num_head, seq_len, model_dim / num_head)
score = torch.bmm(Q, K.transpose(-2, -1)) / torch.sqrt(model_dim) # transpose(-2, -1)表示交换张量的后两个维度
masked_score = score.masked_fill(attn_mask, -1e9)
prob = F.softmax(masked_score, -1)
context = torch.bmm(prob, V)
return context
scaled的重要性:可以降低方差,避免雅可比矩阵值太小梯度消失
alphal1 = 0.1
alphal2 = 10
score = torch.randn(5)
prob1 = F.softmax(score*alphal1, -1)
prob2 = F.softmax(score*alphal2, -1)
def softmax_func(score): # 雅可比矩阵
return F.softmax(score)
jaco_mat1 = torch.autograd.functional.jacobian(softmax_func, score*alphal1)
jaco_mat2 = torch.autograd.functional.jacobian(softmax_func, score*alphal2)
print(jaco_mat1)
print(jaco_mat2)
8. Masked Loss
计算预测结果与标签的交叉熵,保证padding部分为0
logits = torch.randn(2, 3, 4) # batch_size=2, seq_len=3. vocab_size=4 两个句子每个句子有3个单词
logits = logits.transpose(1, 2)
label = torch.randint(0, 4, (2, 3))
score_loss1 = F.cross_entropy(logits, label) # 平均交叉熵
score_loss2 = F.cross_entropy(logits, label, reduction='none')
tgt_len_m = torch.tensor([2, 3]).to(torch.int32)
mask = torch.cat([torch.unsqueeze(F.pad(torch.ones(L), (0, max(tgt_len_m) - L)), 0) for L in tgt_len_m])
score_loss_mask = F.cross_entropy(logits, label, reduction='none') * mask
print(logits)
print(label)
print(score_loss1)
print(score_loss2)
print(mask)
print(score_loss_mask)
原文地址:https://blog.csdn.net/lsh2678227571/article/details/139217048
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!