leetcode82:删除排序链表中的重复节点||
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
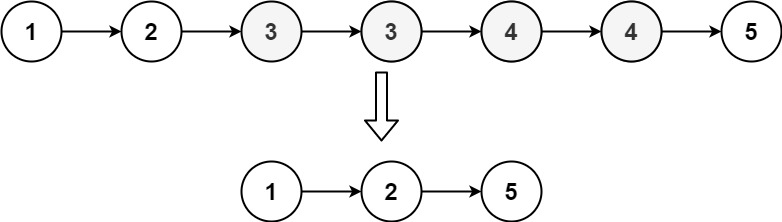
输入:head = [1,2,3,3,4,4,5] 输出:[1,2,5]
示例 2:
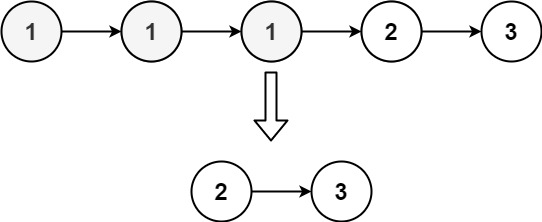
输入:head = [1,1,1,2,3] 输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
步骤1:问题定义
给定一个已排序的链表,要求删除所有重复出现的节点,保留链表中每个元素仅出现一次的节点。该链表是单向的,且数据已按升序排列。目标是构造一个不含重复值的链表并返回其头节点。
输入条件:
- 链表头节点
head。 - 链表节点数量在
[0, 300]范围内。 - 每个节点的值在
[-100, 100]之间。
输出条件: 返回一个去除所有重复元素的链表头节点。
边界条件:
- 空链表:
head为空指针,返回nullptr。 - 所有节点都重复的情况:如
[1, 1, 1, 1],应返回空链表。 - 链表不含重复元素:如
[1, 2, 3],应返回原链表。
步骤2:解题思路
这道题可以使用“指针遍历”的方法处理重复节点,因为链表已排序,重复的元素会相邻出现。遍历链表,检测连续相同的元素并移除整个重复区域。
具体步骤:
- 初始化一个伪头节点
dummy,指向原链表的头节点,方便在head本身为重复节点时处理边界情况。 - 定义两个指针:
prev:指向已检查并不包含重复的最后一个节点。current:用于遍历链表。
- 遍历链表,检查
current与其后一个节点的值是否相同:- 如果相同,继续遍历直到找到最后一个相同的节点。
- 如果不相同,将
prev的next指针跳过整个重复区域。
- 如果
current和current->next不相同,直接移动prev和current。 - 最后,返回
dummy->next作为新的链表头。
算法复杂度:
- 时间复杂度:
O(n),其中n是链表节点数量。遍历每个节点最多一次。 - 空间复杂度:
O(1),只使用了有限的指针,无额外的空间需求。
步骤3:代码实现

步骤4:算法启发
通过解决此问题,我们得到了处理有序链表中重复元素的一种高效方法。对于单链表操作,借助伪头节点和双指针的应用使代码更简洁,避免了重复元素头部在链表中的特殊处理。
此外,链表去重是常见的链表操作之一,此题中的逻辑也可以扩展到其他变种链表问题中,例如反转链表或合并排序链表。
步骤5:实际应用
链表去重在数据库、数据处理和通信系统中非常重要。例如,通信系统中可以通过此算法实现数据包的重复检测并去除冗余数据包。具体实现如下:
- 通信系统中会传输大量数据包,可能出现重复的情况。链表结构能高效追踪数据包顺序及是否重复。
- 通过上述算法,重复数据包会被跳过,保证数据只被接收或存储一次,降低系统开销。
在实际应用中,这种重复检测和过滤算法广泛应用于金融交易、传感器数据分析、网络流量管理等场景中,以确保数据的准确性和高效传输。
原文地址:https://blog.csdn.net/D2510466299/article/details/143666249
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!