spark3.0.0单机模式安装
注:此安装教程基于hadoop3集群版本
下载安装包
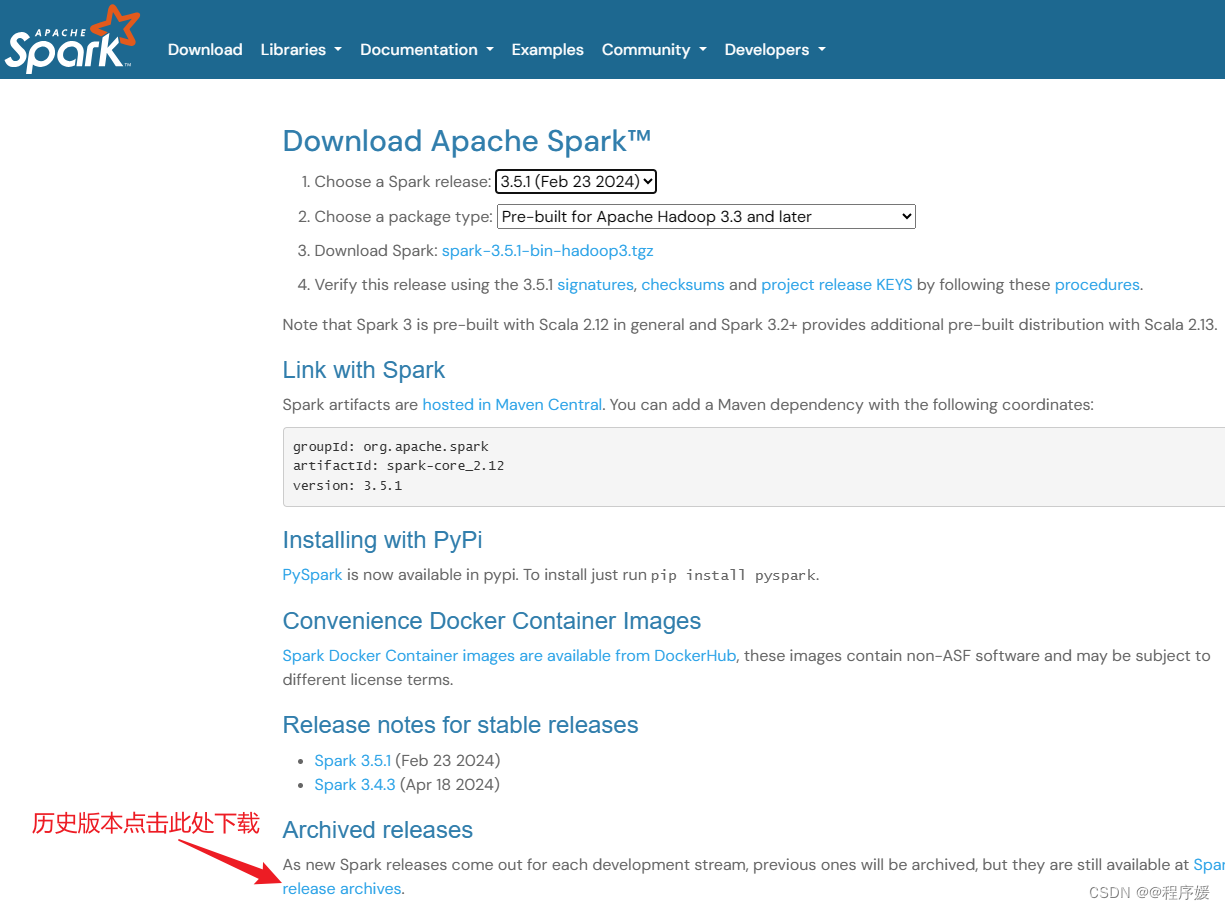
下载spark3.0.0版本,hadoop和spark版本要对应,否则会不兼容
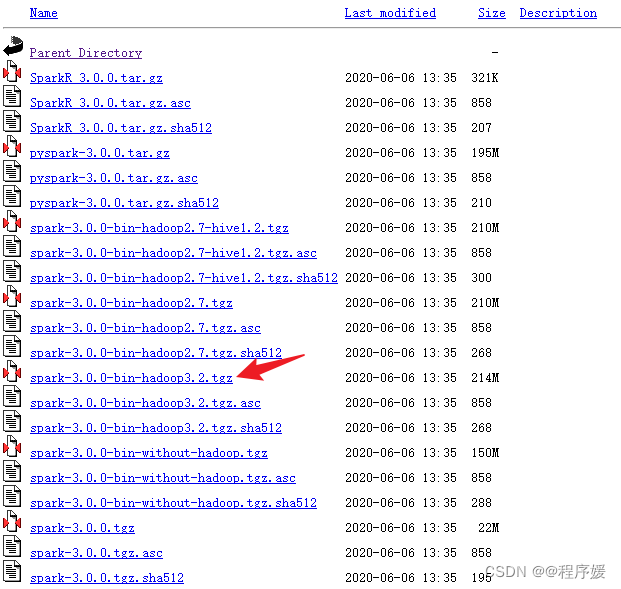
用xftp上传Linux虚拟机,上传目录/bigdata(可修改)

解压
tar -zxvf /bigdata/spark-3.0.0-bin-hadoop3.2.tgz 添加软链接(可选)
ln -s /bigdata/spark-3.0.0-bin-hadoop3.2.tgz /bigdata/spark修改环境变量
sudo vim /etc/profile
export SPARK_HOME=/bigdata/spark
export $PATH:$SPARK_HOME/bin 别忘记source /etc/profile
修改spark配置文件
cd /bigdata/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh添加以下内容,/bigdata/hadoop就是hadoop的路径,可根据自己的实际情况修改
export SPARK_DIST_CLASSPATH=$(/bigdata/hadoop/bin/hadoop classpath)验证是否安装成功
run-example SparkPi 2>&1 | grep "Pi is" 这是一个求Π的示例程序,输出如下
![]()
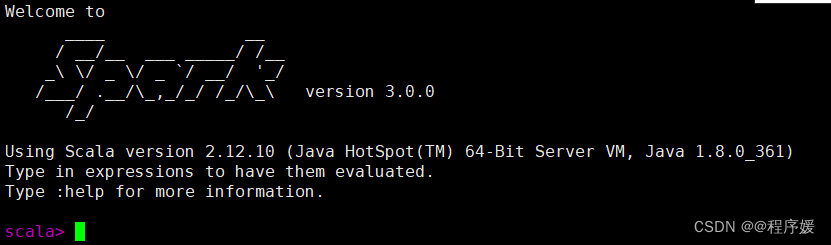
打开spark shell终端
spark-shell如下图
原文地址:https://blog.csdn.net/m0_64825044/article/details/138157385
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!