【bug】使用mmsegmentaion遇到的问题
利用mmsegmentaion跑自定义数据集时的bug处理(使用bisenetV2)
- 1. ValueError: val_dataloader, val_cfg, and val_evaluator should be either all None or not None, but got val_dataloader={'batch_size': 1, 'num_workers': 4}, val_cfg={'type': 'ValLoop'}, val_evaluator=None
- 2. IndexError: The shape of the mask [497, 512] at index 0 does not match the shape of the indexed tensor [1080, 1920] at index 0
- 3. NotImplementedError: device must be 'cpu' , 'gpu' or 'npu', but got GPU
使用的环境是cuda11.3+pytorch1.11.0+torchaudio0.11+torchvison0.12.0
1. ValueError: val_dataloader, val_cfg, and val_evaluator should be either all None or not None, but got val_dataloader={‘batch_size’: 1, ‘num_workers’: 4}, val_cfg={‘type’: ‘ValLoop’}, val_evaluator=None

1.1报错原因
由于之前用自己数据集跑过internImage,想投机取巧把internImage自定义的配置文件拿过来直接用,果不其然报错了。
1.2 解决方案
还是借鉴mmsegmentaion中/configs/base/datasets/ade20k.py,将文件修改成适合自己数据集的配置
# -*- coding: utf-8 -*-
# @Author: Zhao RuiRui
# @Time : 2024/4/16 上午11:24
# @Describe:
# dataset settings
dataset_type = 'CoalDataset' # 修改自定义数据集名称
data_root = '/media/amax/Newsmy1/A_data/mmseg_coalFlow' # 修改数据集路径
img_scale = (1920, 1080)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(
type='RandomResize',
scale=img_scale,
ratio_range=(0.5, 2.0),
keep_ratio=True),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='PackSegInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', scale=img_scale, keep_ratio=True),
# add loading annotation after ``Resize`` because ground truth
# does not need to do resize data transform
dict(type='LoadAnnotations'),
dict(type='PackSegInputs')
]
train_dataloader = dict(
batch_size=4,
num_workers=4,
persistent_workers=True,
sampler=dict(type='InfiniteSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='images', seg_map_path='masks'),
ann_file='/media/amax/Newsmy1/A_data/mmseg_coalFlow/train.txt', #我使用的是txt组织形式,里面只存有图像前缀,修改成训练集的txt路径
pipeline=train_pipeline)
)
val_dataloader = dict(
batch_size=1,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
data_prefix=dict(
img_path='images', seg_map_path='masks'),
ann_file='/media/amax/Newsmy1/A_data/mmseg_coalFlow/val_test.txt',# 这里修改成验证集的txt路径
pipeline=test_pipeline) # 注意这块是test_pipeline
)
test_dataloader = val_dataloader
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
test_evaluator = val_evaluator
2. IndexError: The shape of the mask [497, 512] at index 0 does not match the shape of the indexed tensor [1080, 1920] at index 0
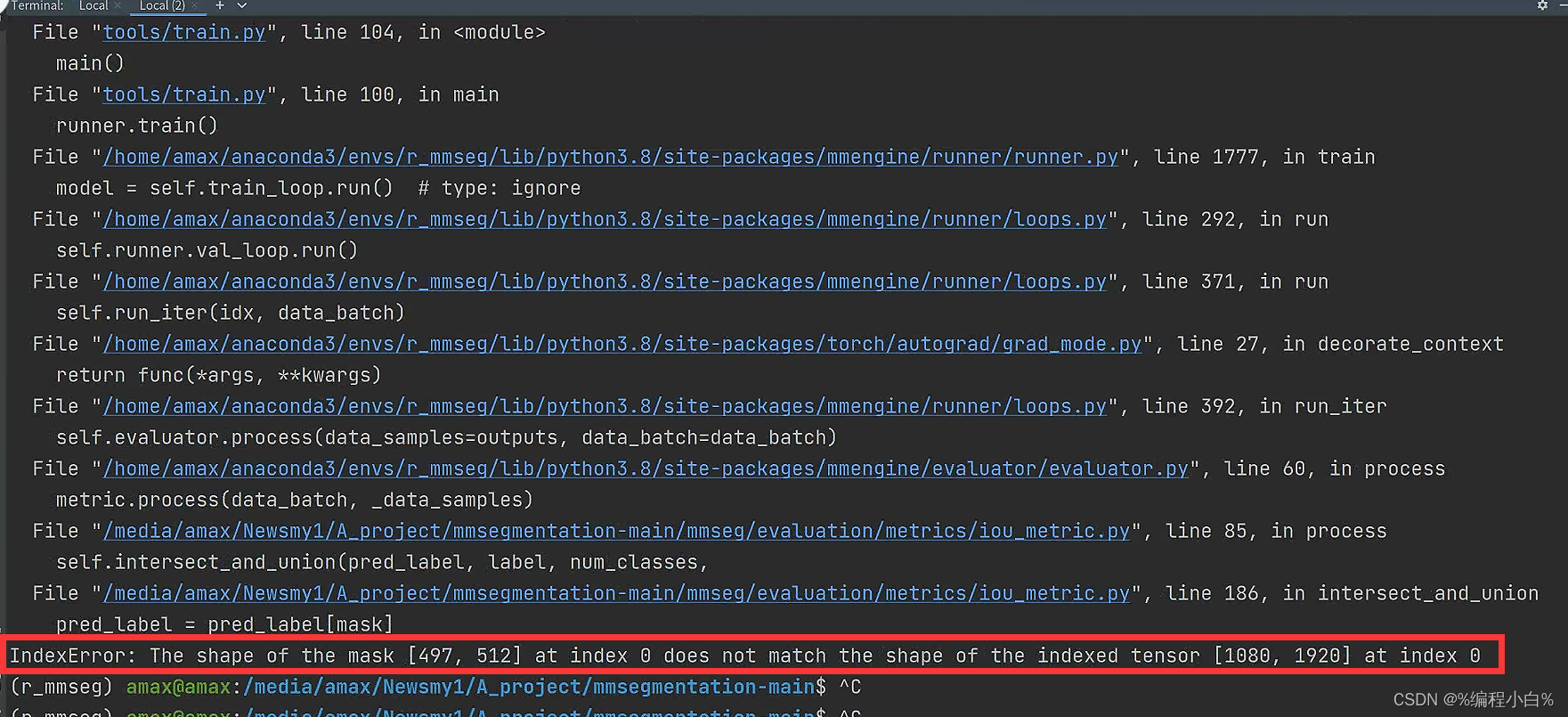
训练是正常的,但是评估会报错;
2.1报错原因
- 不管将scale修改成什么数字,都会报这个错误;
- 尝试使用internImage训练过的数据集进行训练测试,如果可以训练,就说明不是数据集问题,再进行debug调试(好,漂亮,不是数据集问题)
- 将训练batch_size设置为2,num_workers=2;测试batch_size=1,num_workers=2(不OK)
后来,我在github提了issue问题描述,有个回复是这样的
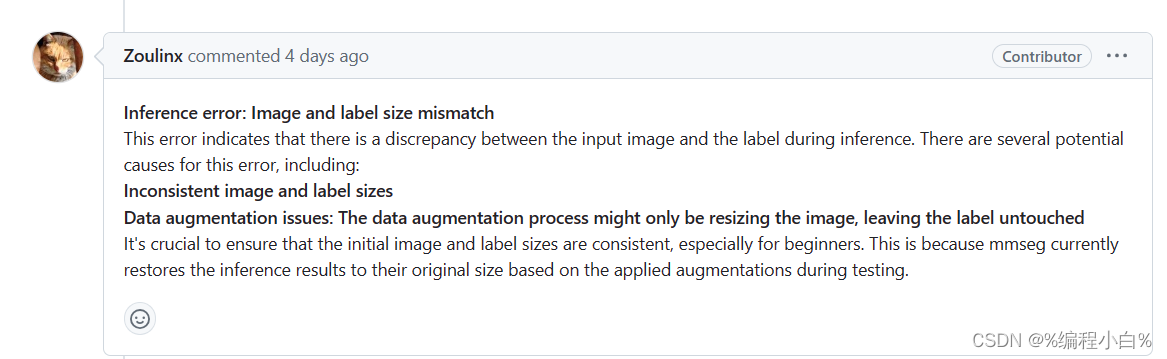
大概意思是出现这个情况有两种原因:
- 图像和标签尺寸大小不匹配
- 数据增强过程中可能只是调整了图像大小,而没有改变标签大小
针对第一个问题,检查了图像相应的标签尺寸大小
# -*- coding: utf-8 -*-
# @Author: Zhao Rui
# @Time : 2024/4/22 上午9:38
# @Describe: 检查图像和标签大小是否匹配
import os
from PIL import Image
img_dir = "/media/amax/Newsmy1/A_data/mmseg_coalFlow/images"
ann_dir = "/media/amax/Newsmy1/A_data/mmseg_coalFlow/masks"
img_files = os.listdir(img_dir)
ann_files = os.listdir(ann_dir)
for img_file in img_files:
if img_file.endswith(".jpg"): # 检查图像文件是否以.jpg结尾
ann_file = img_file.replace(".jpg", ".png") # 构建对应的标注文件名
ann_path = os.path.join(ann_dir, ann_file)
if os.path.exists(ann_path):
img_path = os.path.join(img_dir, img_file)
img = Image.open(img_path)
ann = Image.open(ann_path)
img_size = img.size
ann_size = ann.size
if img_size == ann_size:
print(f"Image {img_file} and annotation {ann_file} have the same size: {img_size}")
else:
print(f"Image {img_file} and annotation {ann_file} have different sizes: {img_size} and {ann_size}")
else:
print(f"Annotation file {ann_file} does not exist for image {img_file}")
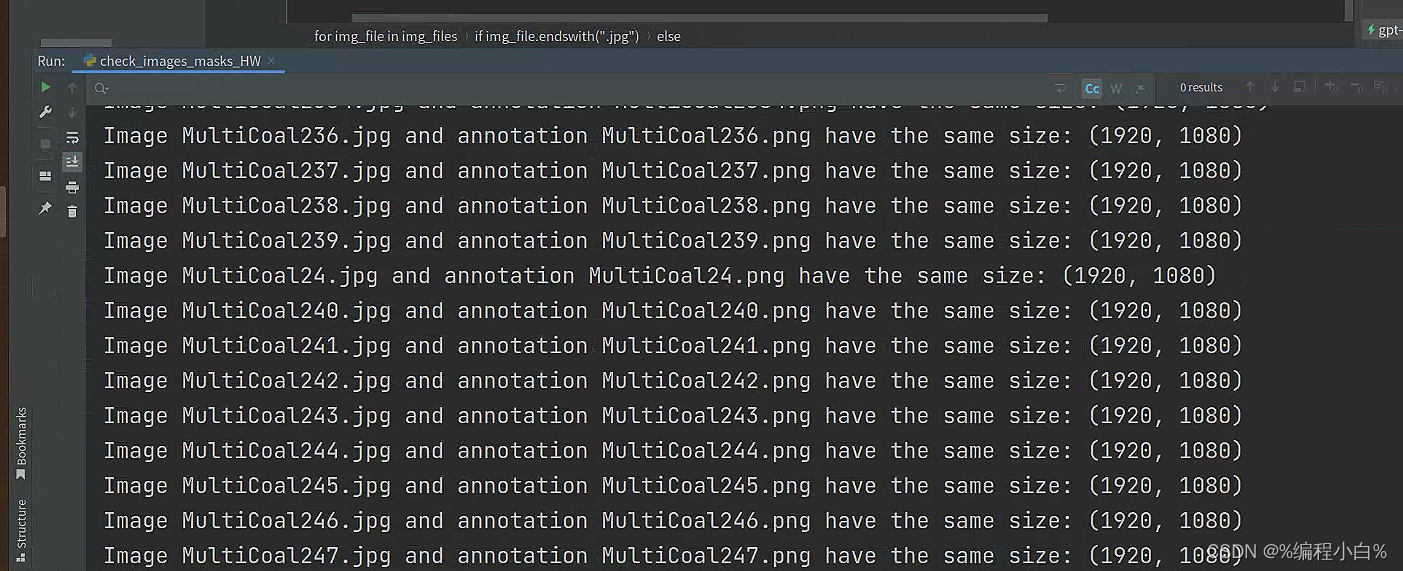
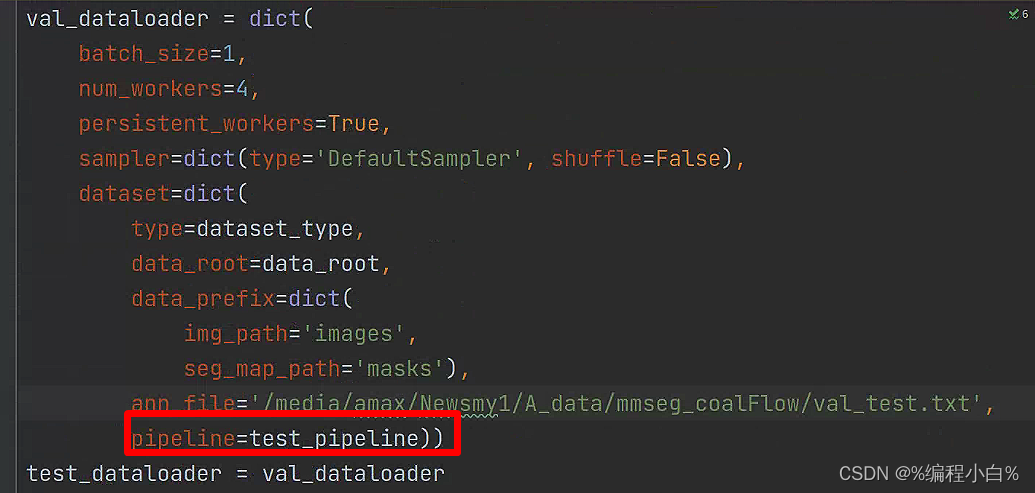
所有的输出都是合适的,图像和标签大小没有问题,将问题转到配置文件中数据增强部分也就是自定义的configs/base/datasets/coalDataset.py配置文件,与其他配置对比之后发现自己将val_dataloader里面的pipeline写成了train_pipeline,以后还是得长点心哇,这个bug卡太久了。
2.2 解决方案
将val_dataloader里面的pipeline修改为test_pipeline
3. NotImplementedError: device must be ‘cpu’ , ‘gpu’ or ‘npu’, but got GPU

和问题二一样,在训练时没有问题,到了评估出指标时就开始报错。
3.1报错原因
验证时好像没有用到GPU(这个原因是我猜的)
3.2 解决方案
验证了我的torch环境是合适的
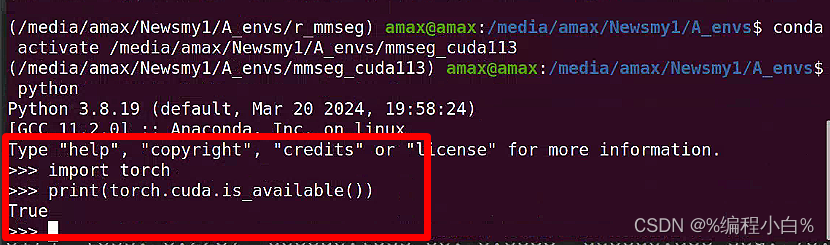 将问题定位到dist.py中line942,原本没有‘GPU’
将问题定位到dist.py中line942,原本没有‘GPU’
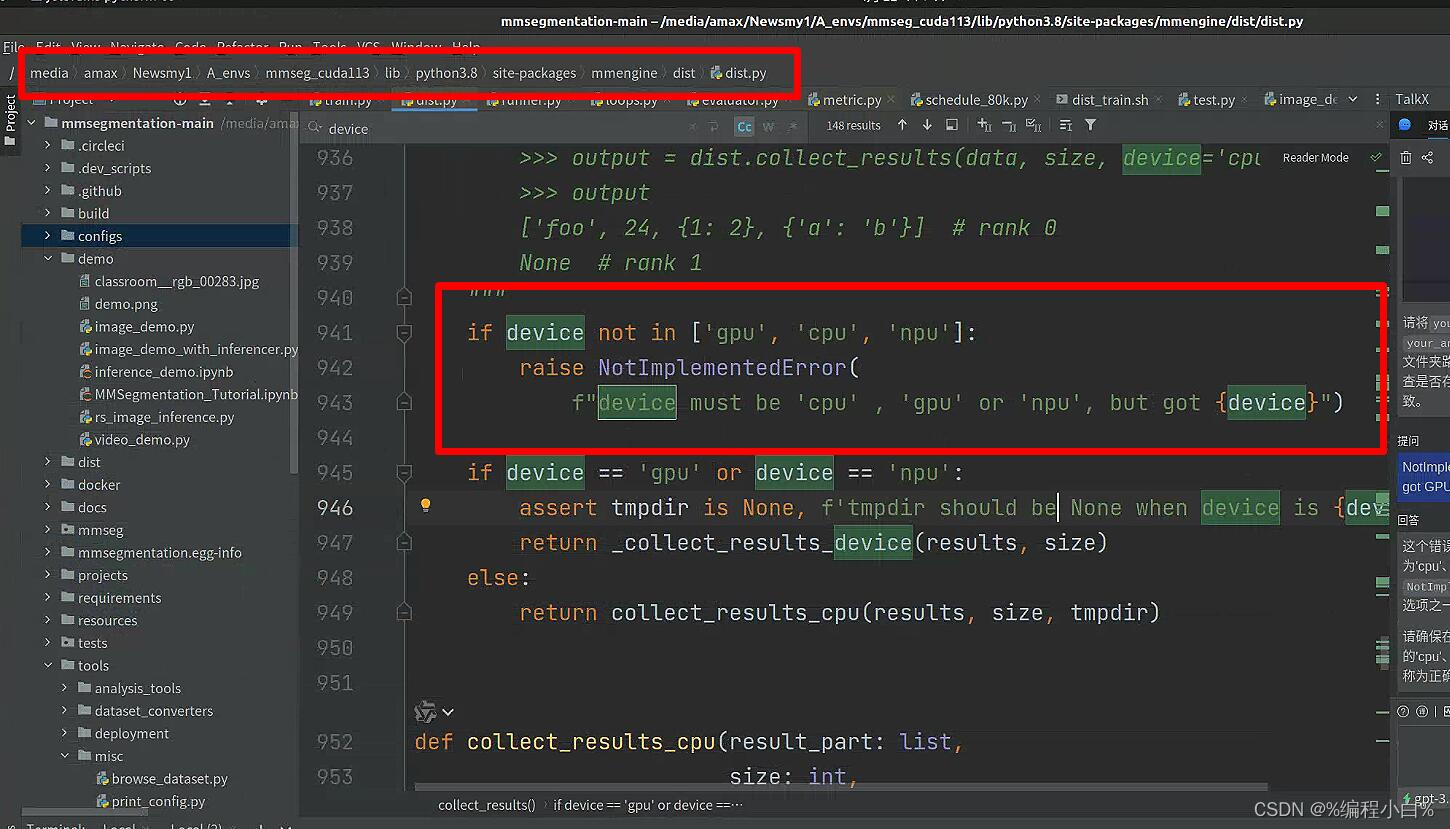
好,那么我就给它加上GPU试试
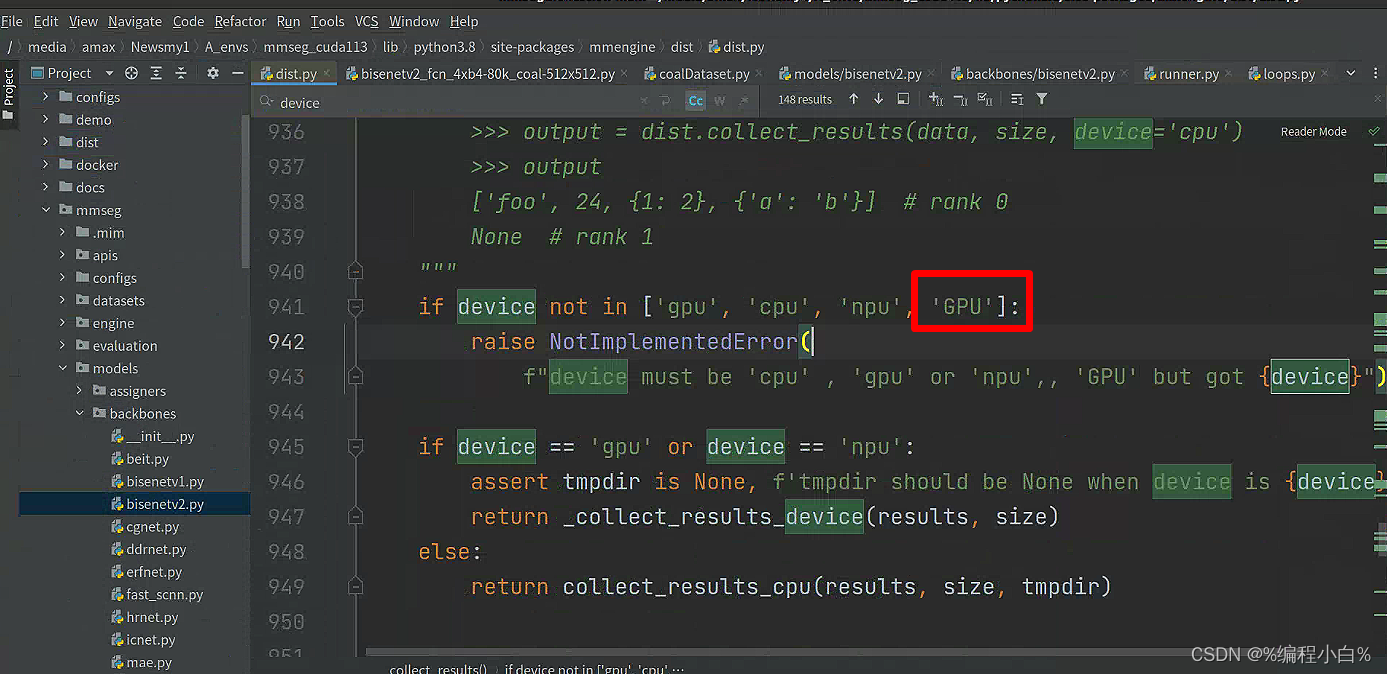
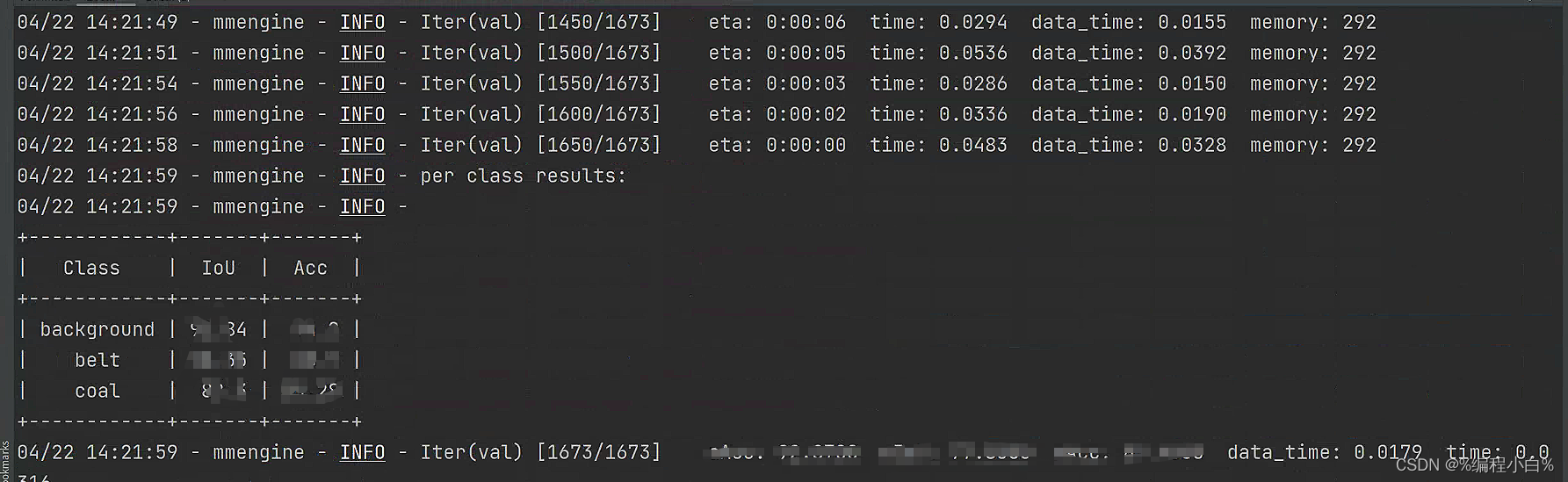
ok,跑通验证,完美。
原文地址:https://blog.csdn.net/m0_49519243/article/details/138075334
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!