记录一个hive中因没启yarn导致的spark引擎跑insert语句的报错
【背景说明】
刚在hive中配置了Spark引擎,在进行Hive on Spark测试时报错,
报错截图如下:

[atguigu@hadoop102 conf]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.3.4/bin:/opt/module/hadoop-3.3.4/sbin:/opt/module/hive-3.1.3/bin :/opt/module/kafka/bin:/opt/module/efak/bin:/home/atguigu/.local/bin:/home/atguigu/bin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.3.4/bin:/opt/module/hadoop-3.3.4/sbin:/opt/modu le/hive-3.1.3/bin:/opt/module/kafka/bin:/opt/module/efak/bin:/opt/module/spark/bin)
Hive Session ID = 4b43a439-6dee-4295-a467-7182adb64f04
Logging initialized using configuration in file:/opt/module/hive-3.1.3/conf/hive-log4j2.properties Async: true
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
Hive Session ID = 6dbba42a-f926-4cee-8368-646383608b57
hive (default)> create table student(id int, name string);
OK
Time taken: 0.948 seconds
hive (default)> insert into table student values(1,'abc');
Query ID = atguigu_20240420093653_68ffa538-97fa-4864-9d92-18dfc9def1c6
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 885f9da9-d447-4d55-a411-aca9c832703b)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 885f9da9-d447-4d55-a411-aca9c832703b
Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 885f9da9-d447-4d55-a411-aca9c832703b)'
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 885f9da9-d447-4d55-a411-aca9c832703b
【原因】
百度说是这个报错意味着Hive无法为Spark会话创建Spark客户端。可能是由于配置问题导致的。建议检查Hive配置文件中关于Spark的设置是否正确,特别是关于Spark执行引擎的配置。
【解决】
这次没有创建SparkClient失败是因为我的yarn没启,Spark运行需要yarn进行资源调度。好,启动yarn:start-yarn.sh
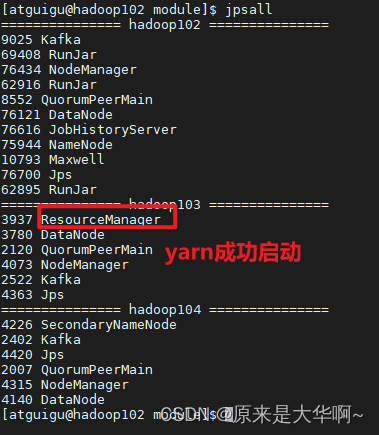
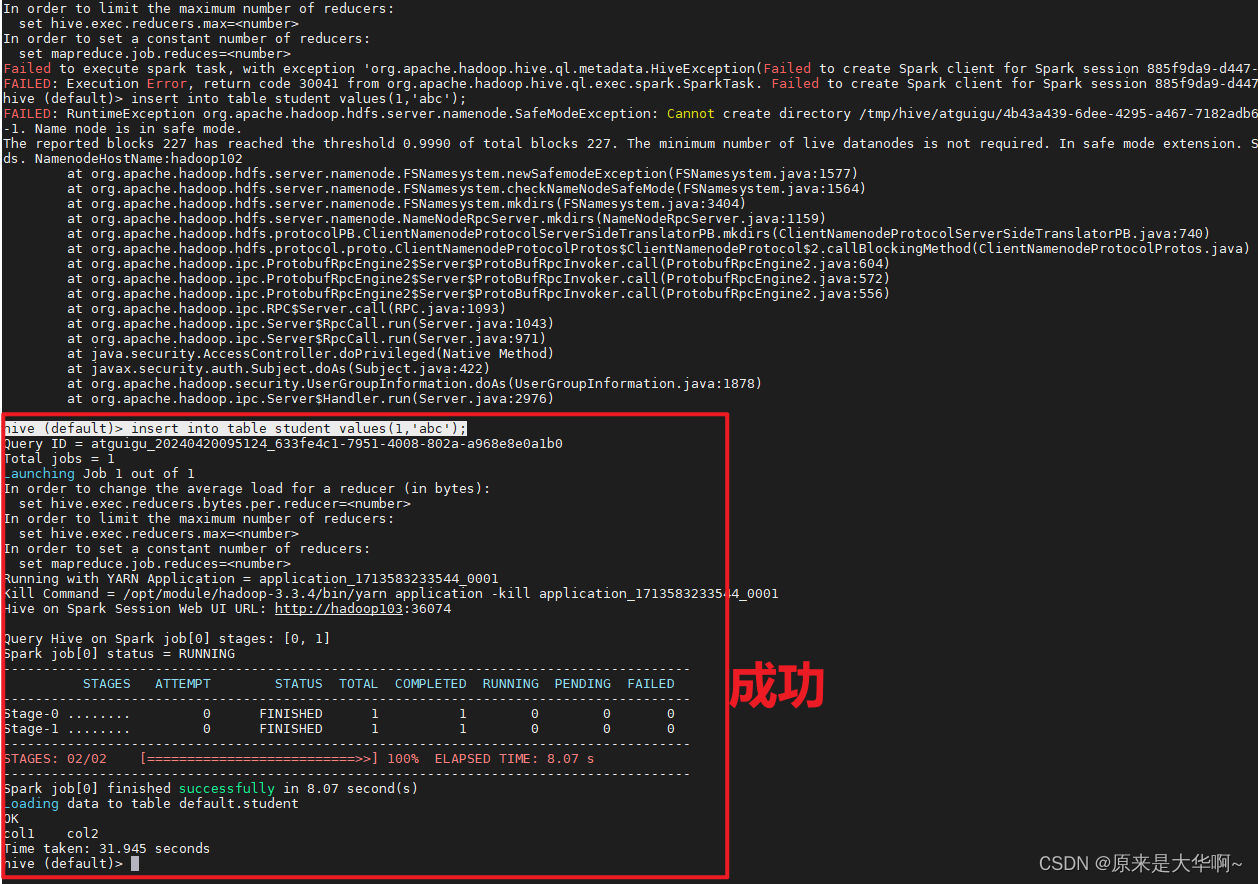
再跑:hive (default)> insert into table student values(1,'abc');
原文地址:https://blog.csdn.net/yuanlaishidahuaa/article/details/137958329
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!