【伪造检测】Noise Based Deepfake Detection via Multi-Head Relative-Interaction
一、研究动机
[!note]
动机:目前基于噪声的检测是利用Photo Response Non-Uniformity (PRNU)实现的,这是一种由于相机感光传感器而造成的缺陷噪声,主要用图像的源识别,在伪造检测的任务中并没有很好的表现。因此在文中提出了一种基于伪造噪声痕迹的检测算法。
实现原理:通过提取伪造视频的伪造噪声痕迹特征检测。
模型创新点:提出多头相关交互方法评估前景和背景对在多个角度下交互程度和相似性、关键帧的提取
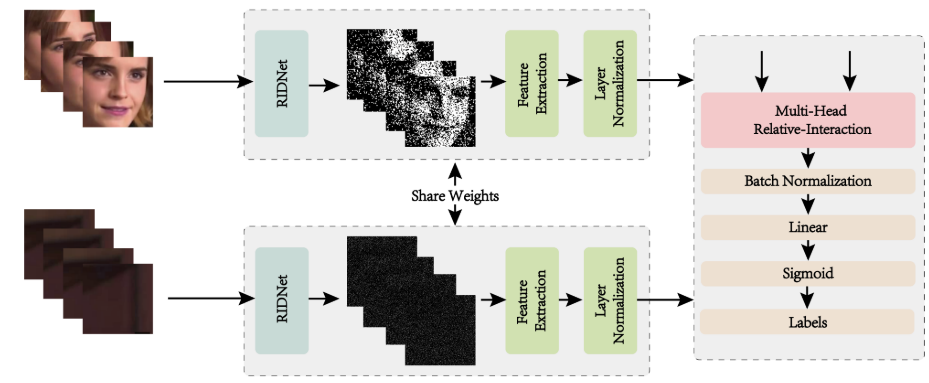
二、检测模型
[!tip]
① 提取视频关键帧;
② 裁剪前景和背景信息;
③ 采用
Siamese network和RIDNet denoiser模型提取伪造噪声痕迹
2.1 预处理
- 关键帧提取
动机:对图像帧实现视频压缩,采用FFmpeg工具对视频关键帧进行提取
一个视频可以被划分为关键帧、预测帧、双向预测帧:
关键帧:帧的所有信息
预测帧:只记录变化的部分
双向预测帧:不仅记录前一帧的变化,还利用后一帧的信息压缩数据
- 图像裁剪
伪造人脸图像只会对人脸进行操作,为了能够防止在背景信息中也提取到被操作的像素,在选取背景区域时选择离人脸最远的区域

2.2 模型实现
- 模型细节
① Siamese网络结构在两个分支中的可学习的权重是共享的,用于噪声特征的提取,在该结构中采用预训练的RIDNet更好的实现噪声特征的提取
② 只有假图会存在伪造噪声痕迹,因此对假图分支采用可分离卷积层实现噪声特征的投影,而真图分支采用CNN;
- RIDNet
由一层卷积层,四个
EAM模块组成实现特征提取,最后由一个卷积层以输出一个干净的图像
在这个任务中是提取图像噪声,并不是设法去消除图像的噪声,通过原图以及生成的干净图像即可实现噪声特征的提取:
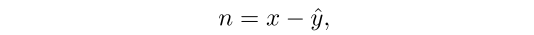
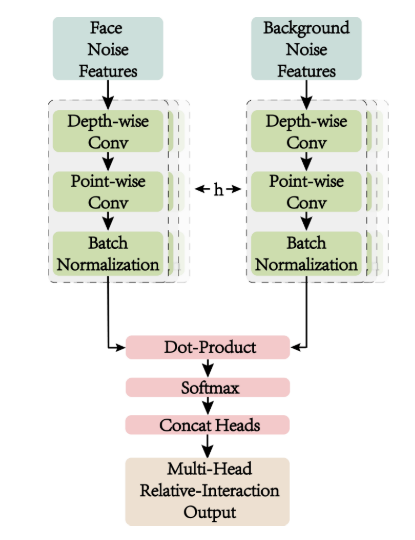
- Mutil-Head Relative-Interaction
[!note]
提出动机:传统算法基本都是采用余弦计算相似度的,然而,由于输出的图像的噪声数据,只采用单一的余弦值作为相似度判断会导致信息损失,因此,文章提出了多头交互方法学习人脸和背景的噪声特征的相似度,从多个维度学习相似度;并采用深度可分离卷积而不是常规的卷积层是为了以更少的参数实现可学习人脸和背景噪声特征的卷积投影
单头的相关交互可以被认为是对人脸和背景的噪声(
N
f
,
N
b
N_f,N_b
Nf,Nb)特征实现卷积操作,映射为
F
f
,
F
b
F_f, F_b
Ff,Fb,对两个特征实现点积操作,并通过
d
F
(
1
/
2
)
d_F^{(1/2)}
dF(1/2)防止由于点积操作的值爆炸,最后通过softmax操作输出相似度。
通过设计不同的卷积(权值随机初始化)操作实现不同维度的相似度学习,从而实现多头相似度交互算法
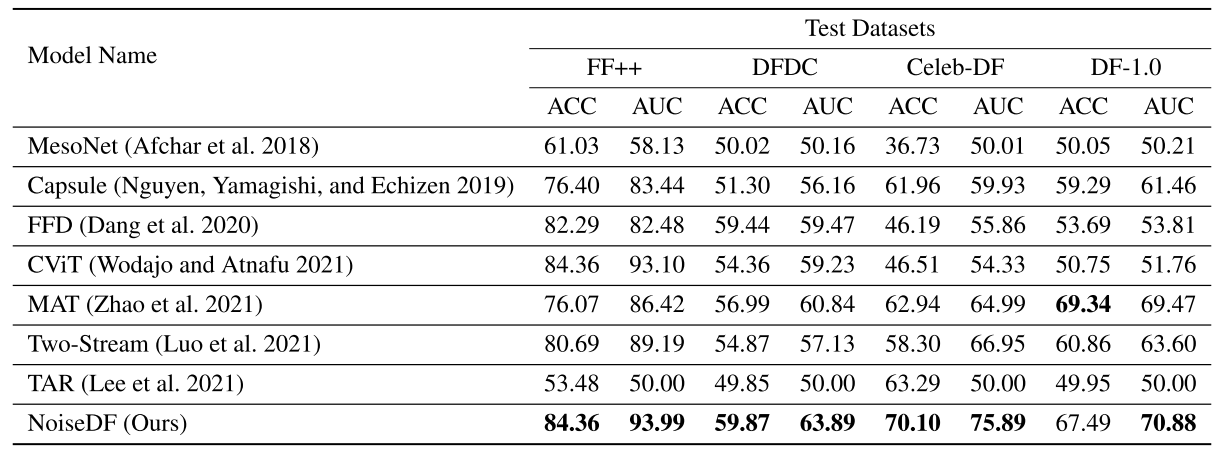
三、实验结果
- 不同模型在不同数据集上的对比
- 真实图像和伪造图像的噪声对比可视化

原文地址:https://blog.csdn.net/weixin_51908696/article/details/143839558
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!