分库分表后如何解决唯一主键问题?
在单库单表时,业务 ID 可以依赖数据库的自增主键实现,现在我们把存储拆分到了多处,如果还是用数据库的自增主键,势必会导致主键重复。但要是利用加锁来处理,又会严重拖垮效率。
实际开发中主要有三种方式
UUID
虽然可以生成唯一主键,但是并不合适,因为它是36位的字符串,太长了,会让每一行数据变长,那不利于B+树节点的存储和搜索。另外UUID无序,插入很复杂。
Snowflake
Snowflake 是 Twitter 开源的分布式 ID 生成算法,由 64 位的二进制数字组成,一共分为 4 部分:
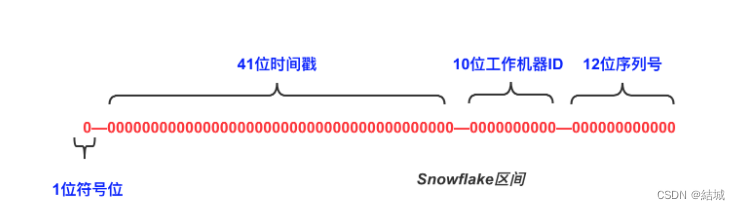

因为服务器的本地时钟并不是绝对准确的,在一些业务场景中,比如在电商的整点抢购中,为了防止不同用户访问的服务器时间不同,则需要保持服务器时间的同步。为了确保时间准确,会通过 NTP 的机制来进行校对,NTP(Network Time Protocol)指的是网络时间协议,用来同步网络中各个计算机的时间。
如果服务器在同步 NTP 时出现不一致,出现时钟回拨,那么 SnowFlake 在计算中可能出现重复 ID。除了 NTP 同步,闰秒也会导致服务器出现时钟回拨,不过时钟回拨是小概率事件,在并发比较低的情况下一般可以忽略。关于如何解决时钟回拨问题,可以进行延迟等待,直到服务器时间追上来为止。
配置自增区间
淘宝的TDDL等数据库中间件使用的主键生成策略。首先在数据库中创建 sequence 表,其中的每一行,用于记录某个业务主键当前已经被占用的 ID 区间的最大值。sequence 表的主要字段是 name 和 value,其中 name 是当前业务序列的名称,value 存储已经分配出去的 ID 最大值。接下来插入一条行记录,当需要获取主键时,每台服务器主机从数据表中取对应的 ID 区间缓存在本地,同时更新 sequence 表中的 value 最大值记录。比如我们这里设置步长为 200,原先的 value 值为 1000,更新后的 value 就变为了 1200。取到对应的 ID 区间后,在服务器内部进行分配,涉及的并发问题可以依赖乐观锁等机制解决。有了对应的 ID 增长区间,在本地就可以使用 AtomicInteger 等方式进行 ID 分配。不同的机器在相同时间内分配出去的 ID 可能不同,这种方式生成的唯一 ID,不保证严格的时间序递增,但是可以保证整体的趋势递增,在实际生产中有比较多的应用。
原文地址:https://blog.csdn.net/pige666/article/details/135617094
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!