K-Means聚类简介及示例
K-Means聚类是一种无监督机器学习算法,它将未标记的数据集分组到不同的聚类中。
K-Means聚类
无监督机器学习是教计算机使用未标记、未分类数据,并使算法能够在没有监督的情况下对这些数据进行操作的过程。在没有任何先前的数据训练的情况下,机器在这种情况下的工作是根据平行、模式和变化来组织未排序的数据。
聚类的目标是将总体或数据点集划分为多个组,以便每个组中的数据点彼此之间更具可比性,并且与其他组中的数据点不同。它本质上是一个基于事物之间相似和不同程度的分组。
我们得到了一个数据集的项目,具有某些特征,以及这些特征的值(如向量)。任务是将这些项目分类到组中。为了实现这一点,我们将使用K-means算法,一种无监督学习算法。算法名称中的“K”表示我们希望将项目分类到的组/聚类的数量。
该算法将项目分类为k组或相似性聚类。为了计算相似度,我们将使用欧几里得距离作为度量。
该算法的工作原理如下:
- 首先,我们随机初始化k个点,称为均值或聚类质心。
- 我们将每个项目分类为其最接近的平均值,并更新平均值的坐标,这是迄今为止该集群中分类的项目的平均值。
- 我们对给定的迭代次数重复这个过程,最后,我们得到了聚类。
上面提到的“点”被称为平均值,因为它们是其中分类的项目的平均值。要初始化这些方法,我们有很多选择。一个直观的方法是在数据集中的随机项处初始化均值。另一种方法是将均值初始化为数据集边界之间的随机值(如果对于一个特征x,项目的值在[0,3]中,我们将用x的值在[0,3]中初始化均值)。
上述伪代码中的算法如下:
随机初始化k值
-->对于给定的迭代次数:
-->遍历项目:
-->通过计算找到最接近项目的平均值
项与每个均值的欧氏距离
-->将项目分配给平均值
-->通过将其移动到该集群中项目的平均值来更新平均值
示例1:
导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
使用make_blobs创建自定义数据集并绘制它
X,y = make_blobs(n_samples = 500,n_features = 2,centers = 3,random_state = 23)
fig = plt.figure(0)
plt.grid(True)
plt.scatter(X[:,0],X[:,1])
plt.show()
初始化随机质心
k = 3
clusters = {}
np.random.seed(23)
for idx in range(k):
center = 2*(2*np.random.random((X.shape[1],))-1)
points = []
cluster = {
'center' : center,
'points' : []
}
clusters[idx] = cluster
clusters
输出
{0: {'center': array([0.06919154, 1.78785042]), 'points': []},
1: {'center': array([ 1.06183904, -0.87041662]), 'points': []},
2: {'center': array([-1.11581855, 0.74488834]), 'points': []}}
用数据点绘制随机初始化中心
plt.scatter(X[:,0],X[:,1])
plt.grid(True)
for i in clusters:
center = clusters[i]['center']
plt.scatter(center[0],center[1],marker = '*',c = 'red')
plt.show()

定义欧氏距离
def distance(p1,p2):
return np.sqrt(np.sum((p1-p2)**2))
创建分配和更新集群中心的函数
#Implementing E step
def assign_clusters(X, clusters):
for idx in range(X.shape[0]):
dist = []
curr_x = X[idx]
for i in range(k):
dis = distance(curr_x,clusters[i]['center'])
dist.append(dis)
curr_cluster = np.argmin(dist)
clusters[curr_cluster]['points'].append(curr_x)
return clusters
#Implementing the M-Step
def update_clusters(X, clusters):
for i in range(k):
points = np.array(clusters[i]['points'])
if points.shape[0] > 0:
new_center = points.mean(axis =0)
clusters[i]['center'] = new_center
clusters[i]['points'] = []
return clusters
创建函数以预测数据点的聚类
def pred_cluster(X, clusters):
pred = []
for i in range(X.shape[0]):
dist = []
for j in range(k):
dist.append(distance(X[i],clusters[j]['center']))
pred.append(np.argmin(dist))
return pred
分配、更新和预测集群中心
clusters = assign_clusters(X,clusters)
clusters = update_clusters(X,clusters)
pred = pred_cluster(X,clusters)
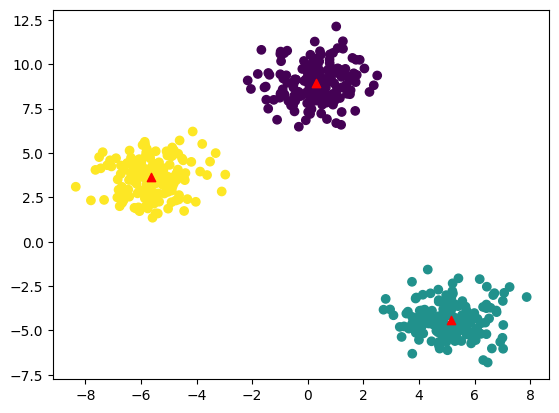
用预测的聚类中心绘制数据点
plt.scatter(X[:,0],X[:,1],c = pred)
for i in clusters:
center = clusters[i]['center']
plt.scatter(center[0],center[1],marker = '^',c = 'red')
plt.show()
示例2:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
加载数据集
X, y = load_iris(return_X_y=True)
找到将数据划分成的理想组数是任何无监督算法的基本阶段。计算k的理想值最常用的方法之一是肘部方法。
#Find optimum number of cluster
sse = [] #SUM OF SQUARED ERROR
for k in range(1,11):
km = KMeans(n_clusters=k, random_state=2)
km.fit(X)
sse.append(km.inertia_)
绘制肘图以找到最佳聚类数
sns.set_style("whitegrid")
g=sns.lineplot(x=range(1,11), y=sse)
g.set(xlabel ="Number of cluster (k)",
ylabel = "Sum Squared Error",
title ='Elbow Method')
plt.show()
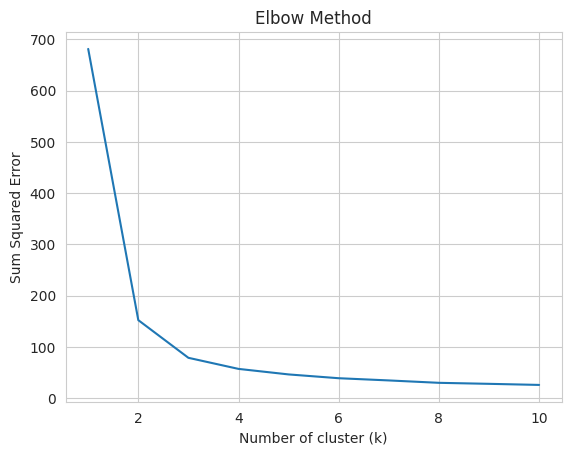
从上图中,我们可以观察到在k=2和k=3时的肘状情况。因此,我们考虑K=3
构建Kmeans聚类模型
kmeans = KMeans(n_clusters = 3, random_state = 2)
kmeans.fit(X)
找到集群中心
kmeans.cluster_centers_
输出
array([[5.006 , 3.428 , 1.462 , 0.246 ],
[5.9016129 , 2.7483871 , 4.39354839, 1.43387097],
[6.85 , 3.07368421, 5.74210526, 2.07105263]])
预测集群组:
pred = kmeans.fit_predict(X)
pred
输出
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2,
2, 2, 2, 1, 1, 2, 2, 2, 2, 1, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 2, 2,
2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1], dtype=int32)
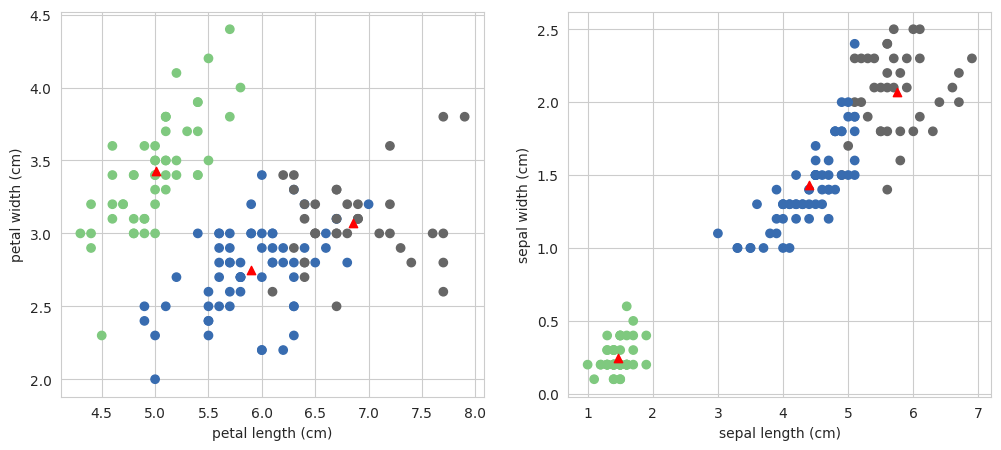
用数据点绘制聚类中心
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.scatter(X[:,0],X[:,1],c = pred, cmap=cm.Accent)
plt.grid(True)
for center in kmeans.cluster_centers_:
center = center[:2]
plt.scatter(center[0],center[1],marker = '^',c = 'red')
plt.xlabel("petal length (cm)")
plt.ylabel("petal width (cm)")
plt.subplot(1,2,2)
plt.scatter(X[:,2],X[:,3],c = pred, cmap=cm.Accent)
plt.grid(True)
for center in kmeans.cluster_centers_:
center = center[2:4]
plt.scatter(center[0],center[1],marker = '^',c = 'red')
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.show()
原文地址:https://blog.csdn.net/qq_42034590/article/details/134166906
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!