Spark集群搭建
Spark集群搭建
现有机器:master01,master02,worker01
需提前开启服务
# hdfs服务
start-dfs.sh
# yarn服务
start-yarn.sh
# zookeeper
zkServer.sh start
一:基本的配置【一台服务器上进行】
先在一台机器上进行配置:master01
# 1、将spark-3.1.2-bin-hadoop3.2.tgz安装包放置虚拟机中的/opt/download目录下
命令:cd /opt/download
# 2、解压缩至/opt/software目录下,并改名为spark-3.1.2
解压缩:
tar -zxvf /opt/download/spark-3.1.2-bin-hadoop3.2.tgz -C /opt/software/
重命名:
mv spark-3.1.2-bin-hadoop3.2/ spark-3.1.2
# 3、环境变量
vim /etc/profile.d/myenv.sh
#---------------------------------------------------
# spark 3.1.2
export SPARK_HOME=/opt/software/spark-3.1.2
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
#---------------------------------------------------
激活:
source /etc/profile
# 4、配置spark-env.sh文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv spark-env.sh.template spark-env.sh
vim spark-env.sh
选择一:spark standalone版本【独立部署,由 Spark 自身提供计算资源】
#--------------------新添内容------------------------
export JAVA_HOME=/opt/software/jdk1.8.0_171
export HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
# 主机配置
SPARK_MASTER_HOST=master01
SPARK_MASTER_PORT=7077
# 历史服务配置
SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=9091
-Dspark.history.fs.logDirectory=hdfs://master01:8020/spark_event_log_dir
-Dspark.history.retainedApplications=30
"
#---------------------------------------------------
# 5、配置workers文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv workers.template workers
vim workers
#---------将原有的内容覆盖掉【只保留以下内容】---------------
master01
master02
worker01
#------------------------------------------------------
# 6、配置spark-defaults.conf文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
选择一:spark standalone版本
#---------------新添内容---------------
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master01:8020/spark_event_log_dir
#-------------------------------------
Spark HA Install补充配置
用处:HA 高可用集群,避免单点故障问题
在上面配置的基础上,进行以下补充配置:
配置spark-env.sh文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv spark-env.sh.template spark-env.sh
vim spark-env.sh
选择二:spark standalone-HA版本【高可用集群,避免单点故障问题】 ✔
#--------------------新添内容------------------------
export JAVA_HOME=/opt/software/jdk1.8.0_171
export HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
# 主机配置
# SPARK_MASTER_HOST=master01 #注释掉
# SPARK_MASTER_PORT=7077 #注释掉
# 历史服务配置
SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=9091
-Dspark.history.fs.logDirectory=hdfs://master01:8020/spark_event_log_dir
-Dspark.history.retainedApplications=30
"
# WEB端口号
SPARK_MASTER_WEBUI_PORT=9090
# 高可用配置
SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master01,master02,worker01
-Dspark.deploy.zookeeper.dir=/spark
"
#---------------------------------------------------
Spark on Yarn Cluster补充配置
配置原因:Spark 是计算引擎,其框架更擅长运算,资源调度则不是强项,而 Yarn 是非常成熟的资源调度框架
在上面配置的基础上,进行以下补充配置:
配置spark-env.sh文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv spark-env.sh.template spark-env.sh
vim spark-env.sh
选择二:spark standalone-HA版本【高可用集群,避免单点故障问题】 ✔
#--------------------新添内容------------------------
export JAVA_HOME=/opt/software/jdk1.8.0_171
export HADOOP_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
# + spark on yarn 必配,且需保证 HADOOP 环境变量已经正确配置
YARN_CONF_DIR=/opt/software/hadoop-3.1.3/etc/hadoop
# 主机配置
# SPARK_MASTER_HOST=master01 #注释掉
# SPARK_MASTER_PORT=7077 #注释掉
# 历史服务配置
SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=9091
-Dspark.history.fs.logDirectory=hdfs://master01:8020/spark_event_log_dir
-Dspark.history.retainedApplications=30
"
# WEB端口号
SPARK_MASTER_WEBUI_PORT=9090
# 高可用配置
SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master01,master02,worker01
-Dspark.deploy.zookeeper.dir=/spark
"
#---------------------------------------------------
# 配置spark-defaults.conf文件
cd /opt/software/spark-3.1.2/conf/
重命名:mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
选择二:spark on yarn ✔
#---------------新添内容---------------
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master01:8020/spark_event_log_dir
# 添加 spark 和 yarn 关联
spark.yarn.historyServer.address=master01:9091
spark.history.ui.port=9091
#-------------------------------------
二:拷贝spark配置至其他服务器
# 拷贝spark文件
/bin/bash remote_copy.sh /opt/software/spark-3.1.2/
# 拷贝环境变量
/bin/bash remote_copy.sh /etc/profile.d/myenv.sh
/bin/bash remote_call.sh "source /etc/profile"
三:启动spark集群
start-all.sh
四:WEB访问界面
WEB访问:http://master01:9090/
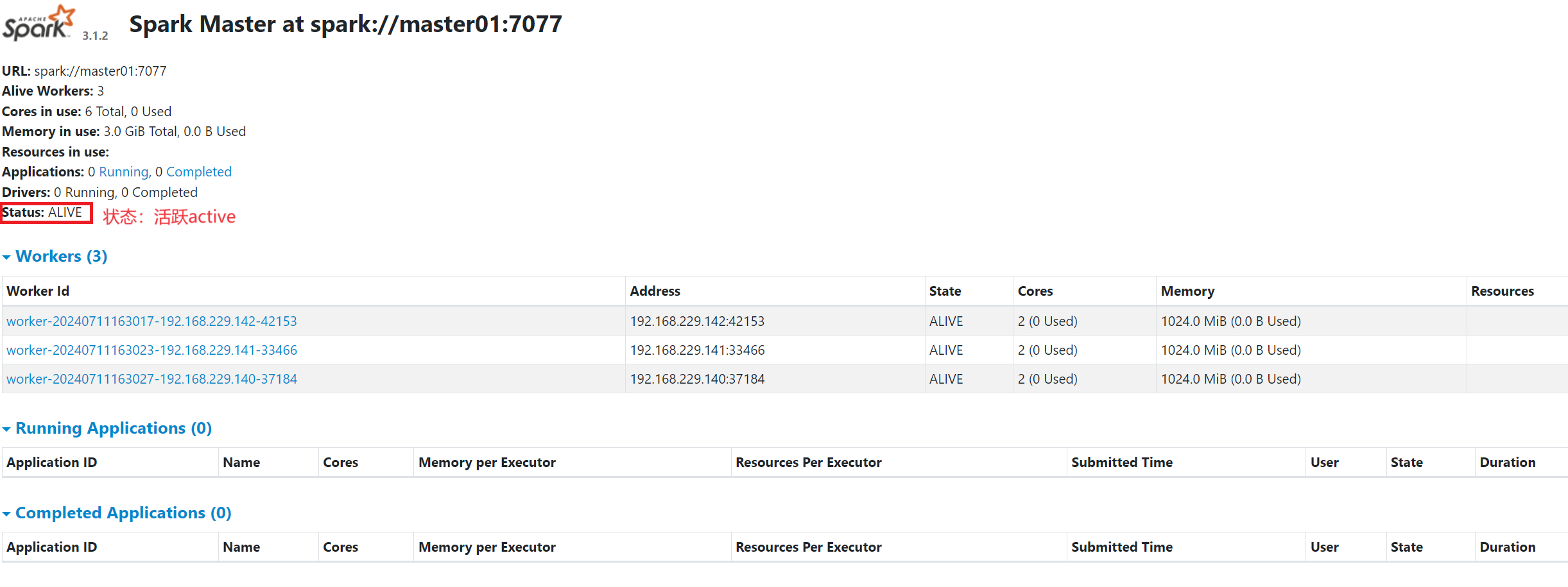
五:高可用Spark-HA的应用
开启master服务
高可用:开启master02中的master服务
ssh root@master02 "start-master.sh"
原来状态:
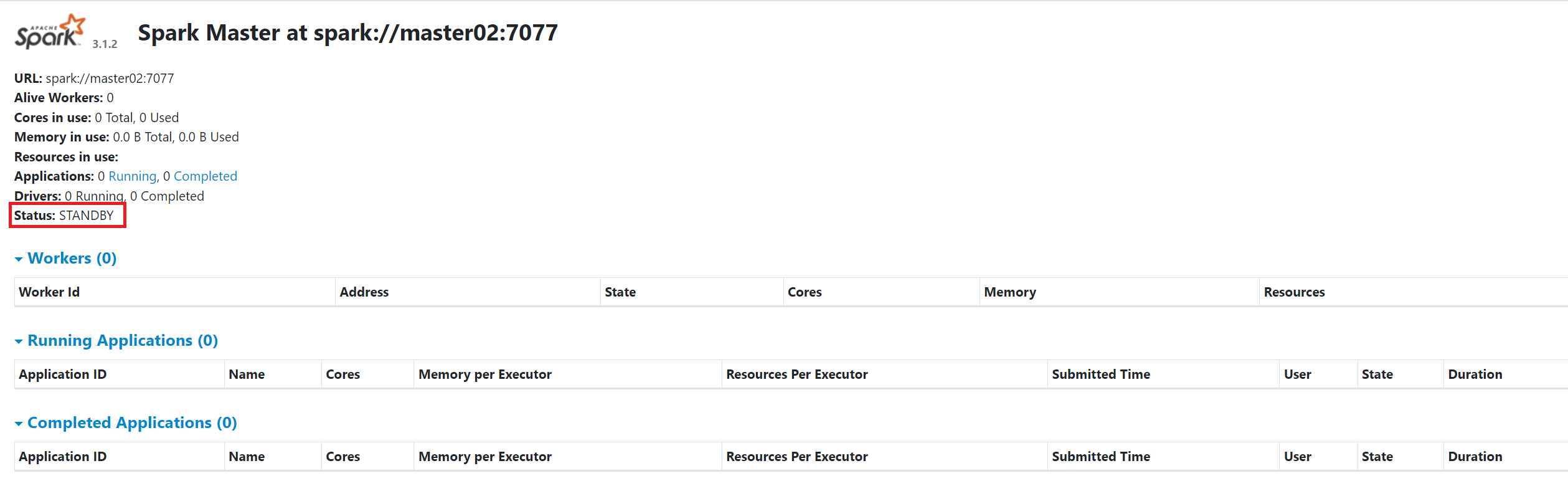
开启后状态:
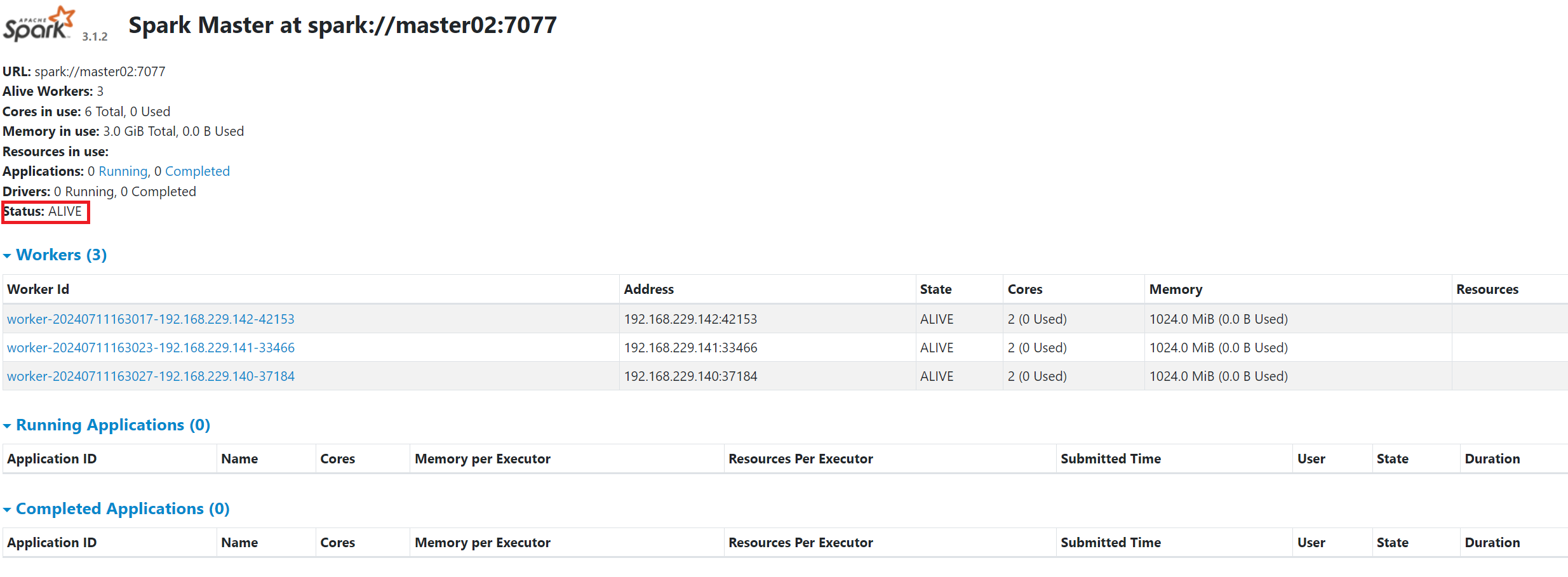
关闭master服务
stop-master.sh
六:启动和关闭spark集群服务
启动spark集群
# 启动 zookeeper
zkServer.sh start
# 启动 hadoop hdfs
start-dfs.sh
# 启动 hadoop yarn
start-yarn.sh
# 启动spark
start-all.sh
关闭spark集群
# 关闭spark服务
stop-all.sh
# 关闭yarn服务
stop-yarn.sh
# 关闭hdfs服务
stop-dfs.sh
# 关闭zookeeper服务
zkServer.sh stop
八:任务提交
standalone【spark standalone】
spark-submit \
--class envtest.ProductAnalyzer \
--master spark://master01:7077 \
--name park-sql-product \
/root/spark/spark_sql_maven-1.3.jar \
hdfs://master01:8020/spark/data/products.txt \
hdfs://master01:8020/spark/result/product_result
yarn-cluster【yarn on yarn cluster】✔
前提:关闭spark服务 => 【stop-all.sh】
因为spark是计算引擎,其框架更擅长运算,资源调度则不是强项,而yarn是非常成熟的资源调度框架。
vim yarn-site.xml
-----------------------------------
<!--是否启动线程,检查每个任务正在使用的 物理和虚拟内存使用量,若超出分配,直接杀死任务进程-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
-----------------------------------
命令:
spark-submit \
--class envtest.ProductAnalyzer \
--master yarn \
--deploy-mode cluster \
--name park-sql-product \
/root/spark/spark_sql_maven-1.3.jar \
hdfs://master02:8020/spark/data/products.txt \
hdfs://master02:8020/spark/result/product_result
原文地址:https://blog.csdn.net/qq_73339471/article/details/140503163
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!