Meta视频生成论文解读
10月4日,meta发布了视频生成的最新研究成果–Movie Gen,一组SOTA的多模态LLM,对应多个惊艳的高质量生成图像、视频示例,支持不同长宽比和同步音频,包括了文本到视频生成、基于用户图像的个性化视频生成、基于精确指令的视频编辑、视频到音频生成和文本到音频生成。多模态LLM有了这些能力无疑离产业级应用又前进了一大步。
本文将从技术的角度对meta发布的长达92页的论文进行归纳总结,帮读者用更低的成本吸收这篇论文的精华。由于这篇论文涉及的面太广,每一节背后都涉及大量的相关工作,小编已经尽力消化加工了,如果仍觉得部分内容未讲清楚,大概率得通过原文的参考文献进一步深挖背景和细节,后续也可能会将其中的部分topic抽离出一个小专题详细展开。
meta主要通过Movie Gen Video和Movie Gen Audio两大模型实现上述这些功能。简单讲,先通过文生图、文生视频数据联合建模Movie Gen Video,后再通过post training使得Movie Gen Video模型具备视频个性化和视频编辑功能;
另外通过视频和文本生成音频数据建模Movie Gen Audio。
接下来我会分几期分别对每一部分详细介绍。本期介绍最关键的Movie Gen Video模块。
1、Movie Gen Video
由于图像可以看作只有一帧的视频,多个连续图像就组成了视频,考虑到大规模的图文数据比视频-文字数据更容易获取,联合建模文生图和文生视频是很自然的想法。
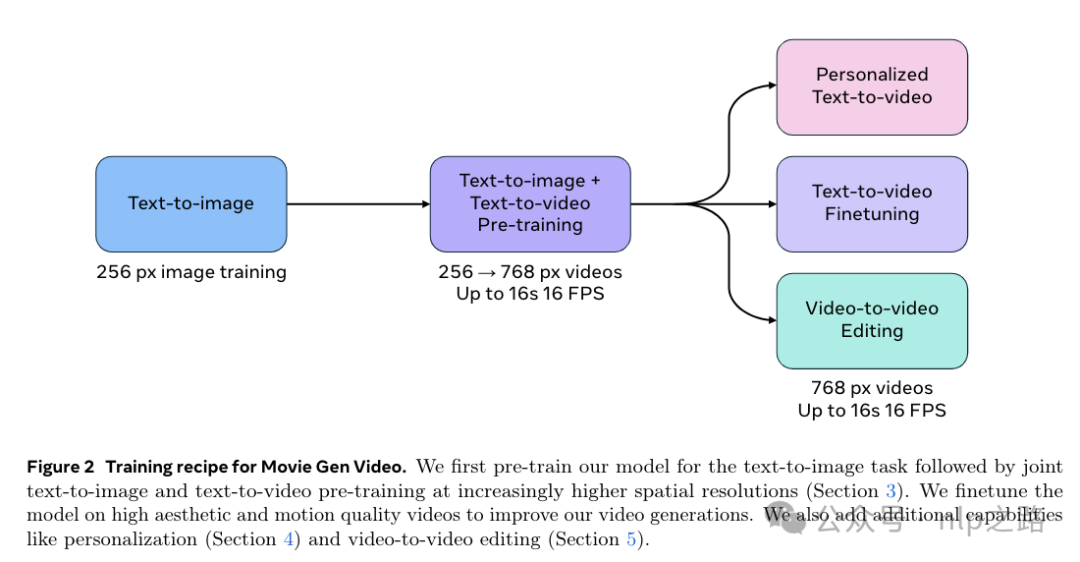
联合训练流程如下图。为加速收敛,分为多阶段训练。首先在256*256的低分辨率文字-图像数据上训练冷启,然后在768*768的高分辨率文字-图像数据和文字-视频数据上继续联合训练,最后在高质量的文字-视频数据上做sft提高视频生成效果,同时为实现个性化视频和视频编辑功能也额外设计了训练流程。
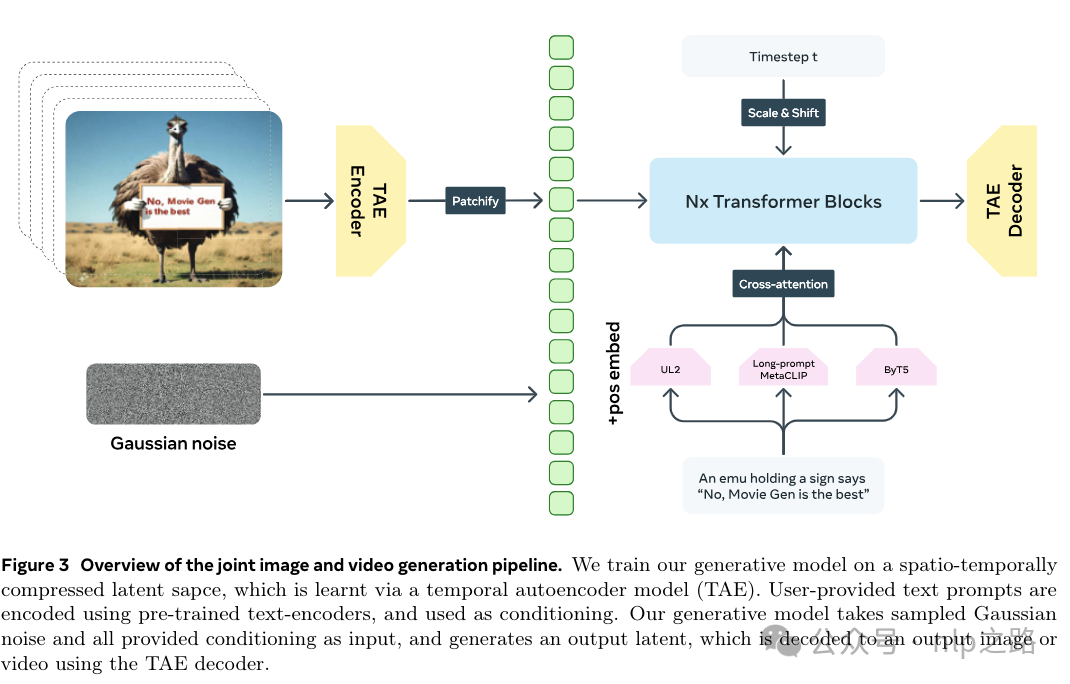
如下图,prompt通过预训练好的文本encoder获取embedding,图片和视频通过temporal autoencoder(TAE)获取隐向量空间和生成图像/视频帧的能力。LLM通过Flow Matching的损失函数优化,输入prompt embedding和高斯噪声,输出隐向量空间,隐向量再通过TAE的decoder生成回图像/视频帧。
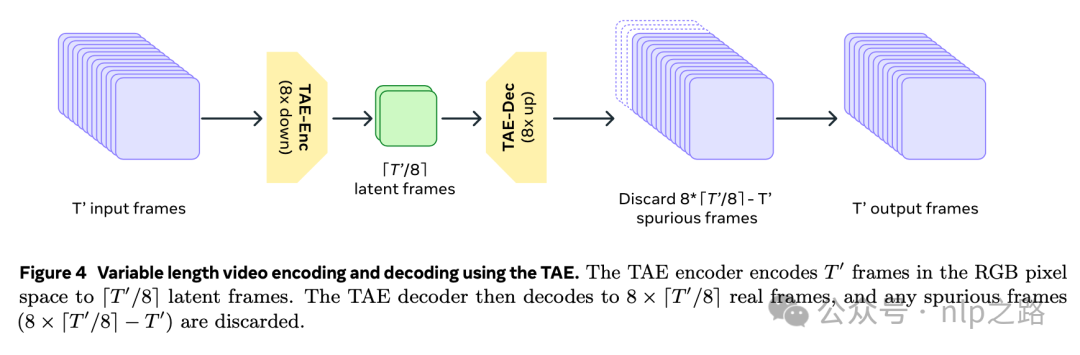
TAE基于预训练好的图像VAE参数初始化,再通过时间维度膨胀(每个2D空间conv后加1D时间conv,每个空间attention后加1D时间attention),通过stride为2的卷积层下采样将视频从T’ x 3 x H’ x W’的像素空间压缩为T x C x H x W的隐变量空间,其中T’/T=H’/H=W’/W=8,大大降低了LLM的计算压力,通过卷积层后接最近邻插值进行上采样能生成原生的长时间高分辨率视频;且channel数C越大,重构和生成效果越好(此处设为16)。这种方法替换掉之前的插帧(frame-interpolation)模型方案,大大简化了模型。参数膨胀后,按1个图像batch和3个视频batch的比例联合训练TAE。
meta团队还发现用标准的diffusion模型的训练目标函数容易导致解码后的像素空间视频中存在“斑点”,如图5所示。

经检查发现,模型输出的隐编码在某些位置存在高范数(norm),meta认为这是模型通过在这些点中储存重要的全局信息来抄捷径,处理的思路是加正则惩罚隐变量中的离群点–Outlier Penalty Loss。
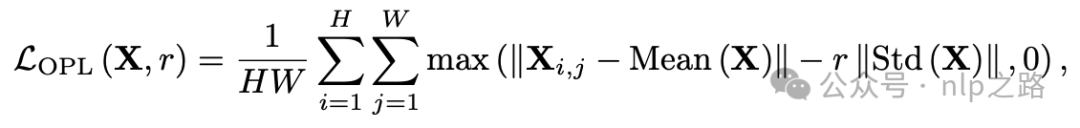
其中是缩放因子,表示潜在变量值需要偏离标准差多远才会被惩罚,实践中设为3。图像数据上述公式直接用,视频数据时间T被合并到batch维度。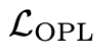 通
通
过加权项添加到标准的VAE loss中可以消除斑点,权重设为1e5。
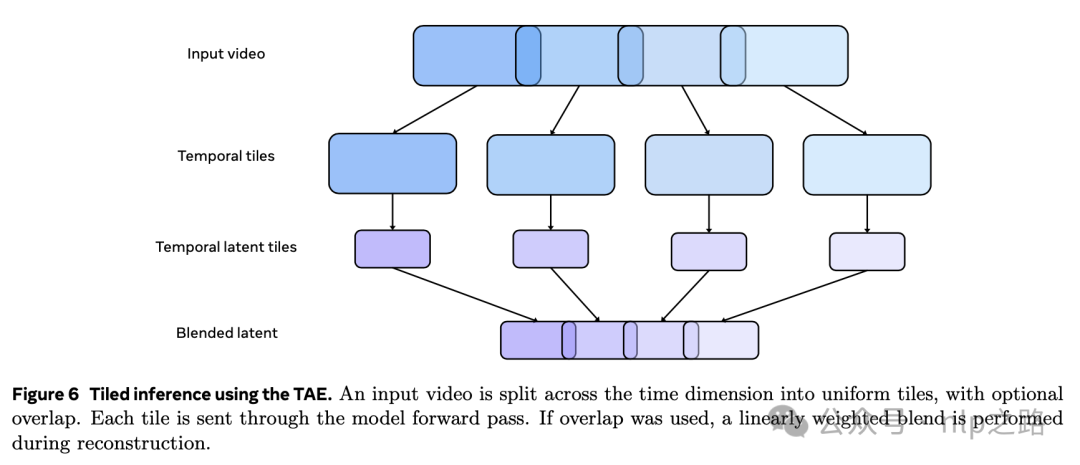
由于内存限制,直接编码/解码高分辨率长视频(如1024*1024px和256帧)不可行。meta提出的解法是沿着时间维度将输入视频和隐变量都划分成块,分别对每个块进行处理,在输出处拼接结果。分块时可以在块之间包含一些重叠部分,拼回去时在相邻块之间加权混合。重叠和混合可以用与encoder和decoder,并具有消除边界伪影的效果,但会增加额外计算成本。实践中,encoder用的块大小是32个原始帧/4个潜变量帧,不重叠,decoder用重叠16个原始帧/2个潜变量帧;混合用帧i和i+1的线性组合,其中是在个重叠帧上的索引,并且。
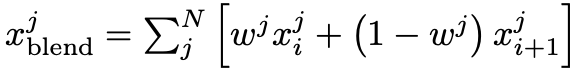
大多数视频生成模型用diffusion公式训练。近期研究表明,terminal信噪比为0的diffusion noise schedules对视频生成非常重要,而标准的diffusion noise schedules不能保证这点,meta团队使用了Flow Matching框架。训练时,给定一个视频样本的隐空间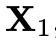 ,根据logit-normal分布采样一个时间步
,根据logit-normal分布采样一个时间步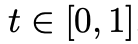 ,以及从标准高斯分布中采样一个噪声
,以及从标准高斯分布中采样一个噪声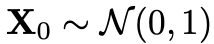 ,通过线性插值或最优传输路径构建一个训练样本
,通过线性插值或最优传输路径构建一个训练样本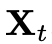 :
:
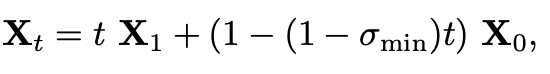
其中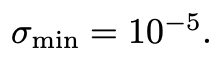 则
则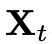 运动到
运动到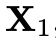 的速度的ground truth为:
的速度的ground truth为:
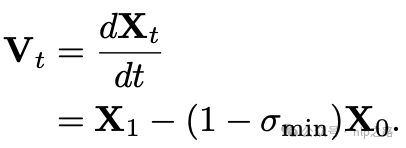
模型被训练来预测速度,使得能够将样本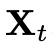 往
往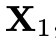 的方向移动,是谓“流匹配“。通过MSE loss拟合(P为prompt embedding,
的方向移动,是谓“流匹配“。通过MSE loss拟合(P为prompt embedding,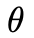 为模型参数):
为模型参数):
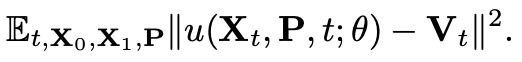
推理阶段,首先采样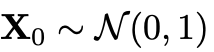 ,用一个常微分方程(ODE)求解器,根据模型预测的速度值计算。实践中,选了一阶欧拉ODE求解器,并且针对模型定制了离散的N个时间步。
,用一个常微分方程(ODE)求解器,根据模型预测的速度值计算。实践中,选了一阶欧拉ODE求解器,并且针对模型定制了离散的N个时间步。
而时间步参数t控制了信噪比,t=0时保证了信噪比也为0。意味着,训练时模型接收到了纯粹的高斯噪声样本,并被训练去预测速度,推理时t=0时也是接收到纯粹的高斯噪声,保证了训练推理的一致性,从而提高模型的效果。
前面提到,TAE编码后的隐变量空间是T x C x H x W,为了兼容LLM模型的输入,用了一个3D卷积层进行分块,卷积核大小为且步长等于核大小,则可以展平为一个token数为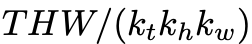 的1D序列,其中,
的1D序列,其中,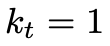 ,
,
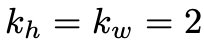 。
。
为使 LLM能够接受任意大小、宽高比和视频长度的输入,设计了分解的可学习的position embedding。绝对embedding的维可以表示为一个映射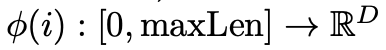 ,其中i为patch的索引。我们将分块后的token,即3D卷积层的输出转换为空间h、w和时间t坐标的单独embedding,并为每个维度设置了maxLen,最终的position embedding为3个维度的位置embedding相加,并且添加到LLM的所有层比只添加到第一层可以有效减少失真和变形伪影,特别是时间维度上。通过这个设计,模型支持生成多个尺寸(如1:1,9:16, 16:9),多时长(4~16秒)的768*768高分辨率视频。而通过Spatial Upsampler可以进一步增强为1080p分辨率!
,其中i为patch的索引。我们将分块后的token,即3D卷积层的输出转换为空间h、w和时间t坐标的单独embedding,并为每个维度设置了maxLen,最终的position embedding为3个维度的位置embedding相加,并且添加到LLM的所有层比只添加到第一层可以有效减少失真和变形伪影,特别是时间维度上。通过这个设计,模型支持生成多个尺寸(如1:1,9:16, 16:9),多时长(4~16秒)的768*768高分辨率视频。而通过Spatial Upsampler可以进一步增强为1080p分辨率!
LLM的backbone基于LLaMA3结构,以利用LLaMA3相对成熟&稳定的技术优势,比之前的视频生成模型backbone模型好,训练也更稳定。最大30B参数:

针对使用流匹配进行视频生成的用例,meta对 LLaMa3 Transformer block进行了三项更改:
(1)为了实现prompt embedding作为输入条件,每个Transformer的self-attention模块和FFN之间新增一个cross-attention模块。用了UL2、ByT5、MetaCLIP共三个文本编码器抽取prompt embedding,UL2用海量纯文本训练,拥有较强的文本推理能力,MetaCLIP由于文本和图像模态已做对齐训练,有利于多模态生成,ByT5捕捉prompt中需要在结果中显示生成的字符串,如具体的某个物体。三个文本encoder优势互补,embedding拼接后;
(2)添加自适应归一化层,以将时间步t纳入Transformer;
(3)用完全双向注意力,而非decoder only LLM中用的因果注意力,因此也没有采用因果attention mask,没有用GQA来提高推理性能;
meta还用一个单独的空间上采样器(Spatial Upsampler)模型将768*768px视频转换为全高清(1080p)分辨率,降低了高分辨率生成的总体计算成本。
如图 7 所示,将空间上采样设计为一个视频到视频的生成任务,即根据一个较低分辨率的输入视频生成一个高清输出视频。
低分辨率视频首先在像素空间中使用双线性插值进行空间上采样到期望的输出分辨率。接下来,视频通过VAE模型被转换到隐变量空间。我们使用一个逐帧的 VAE 作为上采样器,以提高像素清晰度。最后,潜在空间模型根据低分辨率视频的隐变量生成高清视频的隐变量,生成的高清视频隐变量随后使用 VAE 解码器逐帧解码到像素空间。
具体而言,空间上采样器模型架构是在1024px训练的文生图模型初始化的文生视频Transformer(7B参数),编码后的视频与生成输入在通道方向上进行拼接,并被送入空间上采样器 Transformer。由于拼接,输入处的额外参数被初始化为零。我们在400K高清视频上以 24FPS 对 14 帧的剪辑训练我们的空间上采样器。我们应用一个二阶退化过程来模拟输入中的复杂退化,并训练模型生成高清输出视频。在推理时,我们将在已经使用 TAE 解码的视频上使用我们的空间上采样器。为了最小化这种潜在的训练 - 测试差异,我们随机用 TAE 产生的伪影替换二阶退化。由于强输入条件,即低分辨率视频,我们观察到模型使用少至 20 个推理步骤就能产生良好的输出。这个简单的架构可以用于各种倍数的超分辨率;然而,对于我们的情况,我们训练一个2X空间超分辨率模型。与 TAE 分块类似,我们使用一个滑动窗口方法对视频进行上采样,窗口大小为 14,重叠为 4 个潜在帧。
内存限制使我们无法在更长的视频上训练空间上采样器。因此,在推理时,我们以滑动窗口方式对视频进行上采样,这导致在边界处出现明显的不一致。为了防止这种情况,我们利用多扩散(Multi - Diffusion),这是一种无需训练的优化方法,它确保在不同生成过程中在一组共同约束下的一致性。具体来说,我们在每个去噪步骤中使用重叠帧的潜在的加权平均,促进连续窗口之间的信息交换,以增强输出的时间一致性。
下面是介绍下工程训练的一些细节和优化。
- 训练配置:6144块H100 GPU,每块都对应700W TDP和80G HBM3,用Meta的Grand Teton AI server platform。一个server有8块GPU,通过NVSwitches均匀连接。跨server的GPU通过400Gbps RoCE RDMA NICs连接。训练任务通过Meta global-scale traing scheduler调度。

-
分布式并行训练优化
-
张量并行(TP):将线性层的权重沿着列或行进行分片,使得参与分片的每个 GPU 执行更少的FLOPs,对于列并行分片生成更少的激活,对于行并行分片消耗更少的激活。代价是在forward(行并行)和backward(列并行)传递中增加了所有reduce通信开销。
-
序列并行(SP):建立在 TP 之上,也允许对复制的层在序列维度上对输入进行分片,在这些层中每个序列元素可以被独立处理。例如 LayerNorm 这样的层,否则会执行重复的计算并在 TP 组中生成相同(所以重复了)激活。
-
上下文并行(CP):使得对于序列相关的 softmax - 注意力操作在序列维度上能够进行部分分片。CP 利用了这样一个insight:对于任何给定的(source(contetx),target(query))序列对,softmax-attention仅在context上是序列相关的,而不是在query上。因此,在自注意力的情况下,其中输入source和target序列是相同的,CP 允许在正向传递中仅对 K 和 V 投影进行all-gather(而不是 Q,K 和 V)来执行注意力计算,并且在反向传递中对其相关梯度进行reduce-scatter。此外,由于 Q、K、V分别进行projection的,CP 的性能不仅在上下文长度上是可变的,而且在上下文维度的大小上也是可变的。这导致了 Movie Gen Video 和最先进的 LLMs(如 LLaMa3)之间在缩放性能和开销特性上的差异,LLaMa3 使用 GQA 并因此生成更小的 K,V 张量进行通信(例如,对于 LLaMa3 - 70B,K、V张量小 8 倍)。
-
完全分片数据并行(FSDP):在所有数据并行的 GPU 上对模型、优化器和梯度进行分片,在每个训练步骤中同步地gather和scatter参数和梯度。
-
重叠通信与计算。
虽然并行技术可以通过在 GPU 之间划分 FLOP 和内存需求来实现对大型序列 Transformer 模型的训练,但直接实现可能会引入开销和低效性。我们构建了一个分析框架来对计算和通信时间进行建模,识别需要 GPU 间通信的重复激活,从而设计出一种高度优化的模型并行解决方案。我们新的自定义模型并行实现,用 PyTorch 编写并编译为 CUDAGraphs,实现了强大的激活内存缩放,并最小化了暴露的通信时间。
一、预训练
预训练数据
预训练数据集由亿级视频-文本对和十亿级图像-文本对组成。采用了与 (Dai et al., 2023) 类似的图像-文本数据筛选策略,本节中专注于视频数据的筛选。
最初的数据池包括4秒至2分钟长的视频,涵盖了不同领域的概念,如人类、自然、动物和物体。我们的数据筛选流程产生了最终的预训练集,每个剪辑都与一个文本提示配对,每个剪辑时长在4秒至16秒之间,采用单次拍摄相机和非平凡运动。我们的数据筛选流程如图9所示。它包括三个过滤阶段:1) 视觉过滤,2) 运动过滤,和3) 内容过滤,以及一个字幕生成阶段。筛选出的视频剪辑附有平均100字的详细生成字幕。我们在下面详细描述每个阶段。
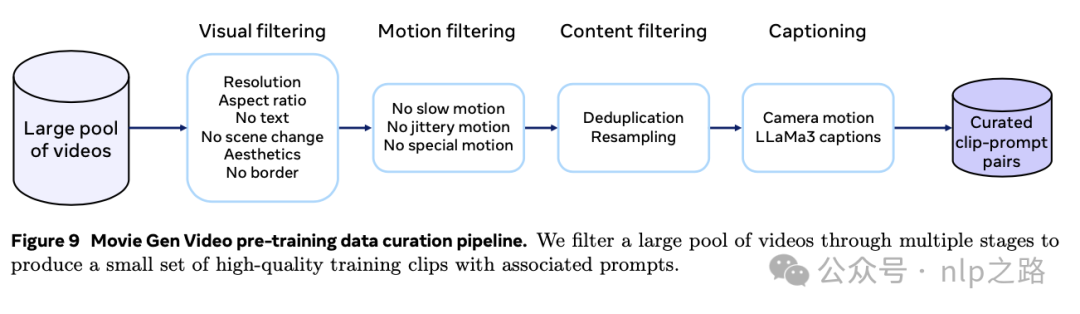
视觉过滤。用了6个过滤器来移除视觉质量差的视频:
(1)过滤宽度或高度小于720像素的视频
(2)按比例过滤,以获得60%的风景和40%的人像视频。风景视频的持续时间更长、美学更好且运动更稳定,因此更倾向于风景视频。
(3)使用视频OCR模型来移除含有过多文字的视频。
(4)使用FFmpeg (FFmpeg Developers) 进行场景边界检测,从这些视频中提取4至16秒长的视频片段,保证无场景切换。
(5)然后我们训练简单的视觉模型,以获取基于帧级视觉美学、视觉质量、大边框和视觉特效的过滤预测信号。
(6)按照Panda-70M (Chen et al., 2024) 的方法,移除了视频开始部分与视频开头重合的剪辑的最初几秒钟,因为开头通常包含不稳定的相机运动或过渡效果。
运动过滤。我们遵循先前的工作 (Girdhar et al., 2024) 来自动过滤低运动视频。
(1)用内部静态视频检测模型来移除没有运动的视频。
(2)根据的VMAF运动得分和运动向量 (FFmpeg Developers) 识别出基于“合理”运动的视频。为了移除频繁抖动的相机运动视频,我们使用了PySceneDetect (PySceneDetect Developers) 库中的镜头边界检测。
(3)移除了具有特殊运动效果的视频,例如幻灯片视频。
内容过滤。为确保预训练集中的多样性,我们使用copy-detection embedding空间中的相似性来移除感知上重复的剪辑。我们还通过重新采样来减少主导概念的普遍性,创建我们的训练集。我们对视频-文本联合embedding模型的语义embedding进行聚类,以识别细粒度的概念集群。接下来,我们合并重复的集群,并根据集群大小的平方根倒数抽样剪辑。
字幕生成。用LLaMa3-Video (Dubey et al., 2024) 为视频剪辑创建准确和详细的文本提示。我们对8B和70B变体的模型进行了视频字幕任务的微调,并使用这些模型为整个训练集的视频剪辑生成字幕。我们的训练集包括70%的8B字幕和30%的70B字幕。为了实现电影级别的摄像机运动控制,我们训练了一个摄像机运动分类器,共16类,例如,zoom-out,左移等。在推理过程中,允许用户指定明确的摄像机控制以生成视频。
多阶段数据筛选。我们策划了3个预训练数据集的子集,这些子集具有逐渐严格的视觉、运动和内容阈值,以满足不同阶段预训练的需求。首先,我们策划了一组最低宽度和高度为720像素的视频剪辑用于低分辨率训练。接下来,我们筛选出一组最低宽度和高度为768像素的视频用于高分辨率训练。最后,我们策划了新视频来扩充我们的高分辨率训练集。我们的高分辨率集有80%的风景和20%的人像视频,其中至少60%包含人类。还建立了一个包含600个人体动词和表达的分类体系,用该分类体系进行了zero-shot的文本到视频检索,以从人类视频中选择视频。在内容重采样过程中保留了这些人像视频的频率。有关策划这些视频的阈值的详细信息,请参见附录B.1。
变时长/尺寸分桶。为了适应多样化的视频长度和长宽比,我们根据长宽比和长度对训练数据进行分桶处理。同一个桶中的视频中的每个视频有完全相同的隐变量shape,从而便于训练数据的批量处理。图像和视频数据集一共用了五个长宽比桶,如,1024×576的风景和576×1024的人像。还定义了五个时长桶(4秒-16秒),并根据视频长度调整潜在帧的数量。引入FPS控制,通过在文本字幕中添加FPS标记来控制生成视频的长度。在预训练中,我们以原始FPS采样视频剪辑,最低为16 FPS。在微调中,我们以两个固定的FPS值16和24采样剪辑。
训练
下面介绍30B参数模型的训练细节。为了提高训练效率和模型可扩展性,采用多阶段训练过程,类似于 (Girdhar et al., 2024)。包括三个主要步骤:
-
在文本到图像(T2I)任务上进行初始训练,然后进行文本到图像和文本到视频(T2V)任务的联合训练;
-
从低分辨率256像素数据逐步扩展到高分辨率768像素数据;
-
使用改进的数据集和优化的训练配方进行持续训练,同时考虑计算和时间限制。
维护一个未见过的视频验证集,并在整个训练过程中监控验证损失。模型的验证损失与人类评估的视觉质量高度相关。
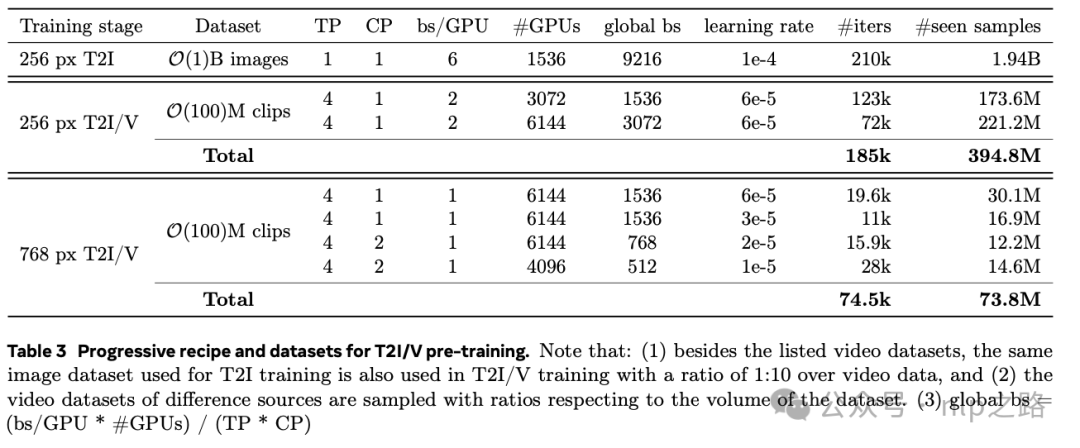
文本到图像预热训练。联合训练T2I/V模型比单独训练T2I模型更慢,也更耗费内存,主要是因为隐变量的token长度要长得多(32倍)。此外,直接从零开始训练T2I/V模型会比用T2I模型初始化的收敛速度慢得多。首先进行T2I预热训练阶段且在较低的分辨率(256像素)上训练,为了能够用更大的batch size和相同的训练计算资源训练更多的训练数据。
T2I/V联合训练。在T2I预热训练之后,再进行文本到图像和文本到视频的联合训练。为了使联合训练成为可能,加了新的时间位置嵌入层以支持多达32个隐变量帧,从T2I模型初始化空间位置嵌入层,将其扩大2倍,以适应不同的长宽比。首先用256像素分辨率的图像和视频进行T2I/V联合训练。对于768像素阶段,我们将空间位置embedding层扩大3倍。表3总结了训练过程。
-
256像素T2I/V阶段。用batch size=1536和6e-5的较大的学习率,使得训练稳定。经过123k次迭代后,将GPU的数量翻倍,使得global batch size翻倍,验证损失显著下降。在185k次迭代后停止训练,过了395M(4+epoch)视频样本。
-
768像素T2I/V阶段。在最初的10k次迭代中验证损失迅速下降,然后波动,见图15。因此在19.6k次迭代时将学习率减半,进一步降低了损失。继续训练模型,并在验证损失稳定时降低学习率。
二、SFT
与之前的工作 (Dai et al., 2023; Girdhar et al., 2024) 一样,通过在少量的人工标注精选视频&字幕数据上对预训练模型进行SFT来提高生成视频的运动和美学质量。在这个阶段,我们训练多个模型,并通过模型平均方法将它们组合成最终模型。
SFT数据制作。目标是收集一组具有良好运动、真实感、美学、广泛概念和高质量字幕的微调视频集。为了找到这样的视频,我们从一大池视频中开始,并应用自动和手动过滤步骤。有四个关键阶段依次运行:
(1) 建立候选视频集。用设置了严格美学、运动、场景变化阈值的自动过滤器。此外,用对象检测模型 (Zhou et al., 2022) 在帧上移除小主题的视频。这个阶段产生了几百万个视频,但概念分布不平衡。
(2) 平衡视频中的概念。这个阶段的目标是获得一个足够小的、概念平衡的视频子集,以便在接下来的步骤中进行手动筛选。我们使用在前文中定义的人类动词和表达的分类体系,通过文本检索视频kNN方法从候选池中检索每个概念的视频。手动挑选了几个视觉上吸引人的种子视频,每个概念一个,并执行视频检索视频kNN以获得概念平衡的视频子集。对于kNN所用embedding,来自视频-文本联合embedding模型。
(3) 手动筛选电影化视频(保高准召)。在这里,我们确保剩余的视频具有自然阳光或摄影棚照明、生动(但不要过度饱和)的颜色、无杂物、非平凡运动、无相机抖动,以及没有编辑效果或叠加文本。在这个阶段,注释者还会剪辑视频到所需的持续时间,通过剪取视频中最精彩、最引人注目的部分来训练。
(4) 手动给视频添加字幕。标注者通过修复不正确的细节并确保包含某些关键视频细节来完善LLaMa3-Video生成的字幕。这些包括相机控制、人类表情、主体和背景信息、详细的运动描述和照明信息。在这个阶段,人类注释者额外注释了6个相机运动和位置类型。视频数据50%在16s左右,50%在10.6s~16s之间。
SFT训练策略。基于预训练checkpoint初始化,但使用相对较小的batch size和64个节点(512个H100 GPU),并使用余弦学习率。与预训练阶段一样,对于16秒的视频,以16 FPS训练,对于10.6秒到16秒的视频,以24 FPS训练。因此,模型被训练以最佳支持生成10秒和16秒的视频。
模型平均。实验揭示了不同的微调数据集、超参数以及预训练检查点的选择对模型行为的关键方面有显著影响,包括运动、一致性和相机控制。为了利用这些模型的不同优势,采用了模型平均方法。
三、推理
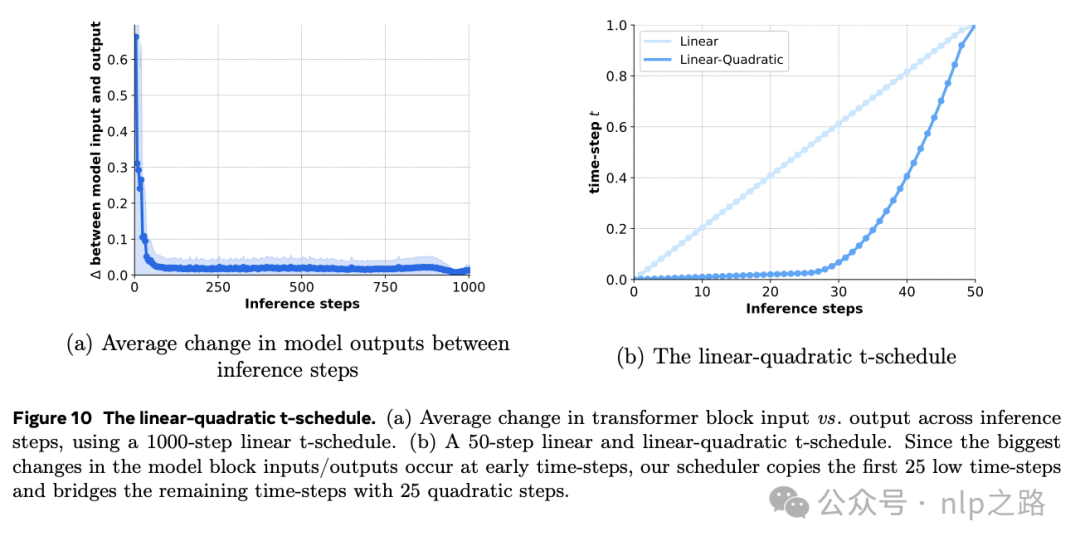
在本节中,我们描述了从Movie Gen Video采样的不同超参数和设置。对于与先前工作的比较,我们使用了一个文本分类器自由的指导比例为7.5,线性-二次t-schedule,用50步(模拟250个线性步骤)来模仿。我们还对输入文本进行推理提示重写。
推理提示重写
推理阶段的输入prompt的写作风格和长度差异很大。例如,大多数用户通常输入少于10个单词,比训练字幕的平均长度短。为了缩小训练和推理时文本分布的差距,用LLaMa3将原始输入提示改写为更详细的提示。关键细节如下:
-
采用标准化的信息架构来重写提示,确保视觉组合的一致性。
-
通过用更易于访问和直接的术语替换复杂词汇来完善重写的提示,从而提高它们的清晰度和可理解性。
-
过度详细的运动细节描述可能会导致生成的视频中引入伪影,突出了在描述丰富性和视觉保真度之间折中的重要性。
为了提高推理重写模型的计算效率,设计了一种教师-学生蒸馏方法。最初,基于LLaMa3 70B模型构建了一个prompt重写教师模型,通过详细的指令说明和上下文学习示例,对大量prompt进行推理;然后,标注者在质量标准的规范下标注,将通过评估的数据收集为human-in-the-loop(HITL)微调数据。最后,在HITL提示重写对上微调了一个8B LLaMa3模型,作为最终的提示重写模型,以减少整个系统的延迟负担。
提高推理效率
经验表明,欧拉采样器的性能优于midpoint或类似Dopri5的自适应采样器,可以更高效的采样视频。meta观察到,生成的运动的质量与提示对齐对推理步骤的数量更敏感。用250、500或1000个线性步骤生成的视频在场景组合和运动质量方面显示出明显差异。虽然可以使用额外的训练(如蒸馏)来加速模型推理,但需要额外训练。meta采用了一种简单的只需在推理阶段调整的技术,通过几行代码可实现高达约20倍的加速。
通过linear-quadratic t-schedule,仅仅50步就能达到近似N步视频生成过程的质量。前25个时间步骤与原来N步的前25步一样,再用25个quadratic步骤来近似剩余的N-25步。linear-quadratic策略是因为观察到模型块输入/输出之间的平均变化在每个推理步骤中变化的规律,如图10(a)所示。由于模型块输入/输出之间的最大变化发生在最初的时间步骤中,因此采用N步计划的前几个线性步骤,然后跟随更大的步骤就足以近似完整的N步结果。后续步骤的二次间距至关重要,它强调了流匹配序列中早期阶段的重要性。在实践中,我们使用一个50步的线性-二次计划,模拟N = 250个线性步骤,以获得最佳结果。
四、评估
评估维度
(1)文本对齐。衡量生成视频与提供的提示之间的一致性。输入提示可以包括对主体外观、运动、背景、相机运动、照明和风格的广泛描述。评估员还被要求基于两个正交维度说明理由:主体匹配:衡量主体外观、背景、照明和风格的匹配;运动匹配:衡量与运动相关的描述的匹配。
(2)视觉质量。运动是视频特有的维度。因此,在文本到视频视觉质量评估中,专注于衡量模型生成在输出视频中一致、自然和足够量的运动的能力。为了捕捉这些关键方面,提出了以下四个子维度:
-
帧一致性:评估生成内容的时间一致性。不符合的情况可能表现为变形伪影、模糊或扭曲的物体,或者突然出现或消失的内容。帧一致性是衡量模型理解对象框架和运动中对象关系的关键指标,因为不一致或扭曲通常出现在模型未能准确表示对象之间的相互作用或它们环境时。此外,帧一致性反映了模型处理具有挑战性任务的能力,例如,需要快速运动内容的prompt(例如,在体育场景中),在这些任务中保持一致的外观尤其困难;或者推理遮挡,例如,在遮挡后重新出现的物体。
-
运动完整性:衡量输出视频是否包含足够的运动。当提示涉及分布之外或不寻常的主题(例如,怪物、鬼魂)或现实世界对象有不寻常的行为(例如,人飞行,熊猫弹钢琴)时,可能会出现运动不完整的情况。由于这些场景的训练数据有限,模型可能难以生成足够的运动量,导致视频静态或只有相机运动。运动完整性评估视频中运动量的大小。在这方面获胜表明运动量更大,即使它包括扭曲、快速运动或看起来不自然。
-
运动自然性:评估模型生成自然和真实运动的能力,表现出对现实世界物理定律的理解。涵盖了自然肢体运动、面部表情和遵守物理定律等方面。看起来不自然或怪异的运动将受到惩罚。
-
整体质量:对于一对比较的视频,上述三个指标可能不会得出相同的获胜者。为了解决这个问题,我们引入了整体质量维度,其中人类评估员被要求选择在给定前三个子轴的情况下具有更好“整体”质量的视频。这是一个全面度量,要求人类注释者使用他们的感知,并平衡前面的信号,以捕捉生成视频的整体质量。
(3)真实性和美学。真实性和美学评估模型生成具有美学上令人愉悦的内容、照明、颜色、风格等的照片般逼真视频的能力。人类评估员沿着两个维度评估:
-
真实性:衡量比较的视频中哪一个更接近真实视频。对于训练集分布之外的幻想性提示(例如,描绘幻想生物或超现实场景),真实性定义为模仿遵循现实艺术风格的电影剪辑。评估员还需说明选择背后的原因,即“主体外观更真实”或“运动更真实”。
-
美学:衡量哪一个生成的视频具有更有趣和引人注目的内容、照明、颜色和相机效果。同样,要求评估员提供选择的理由,从“内容更具吸引力/有趣”和“照明/颜色/风格更具吸引力”。
评估基准
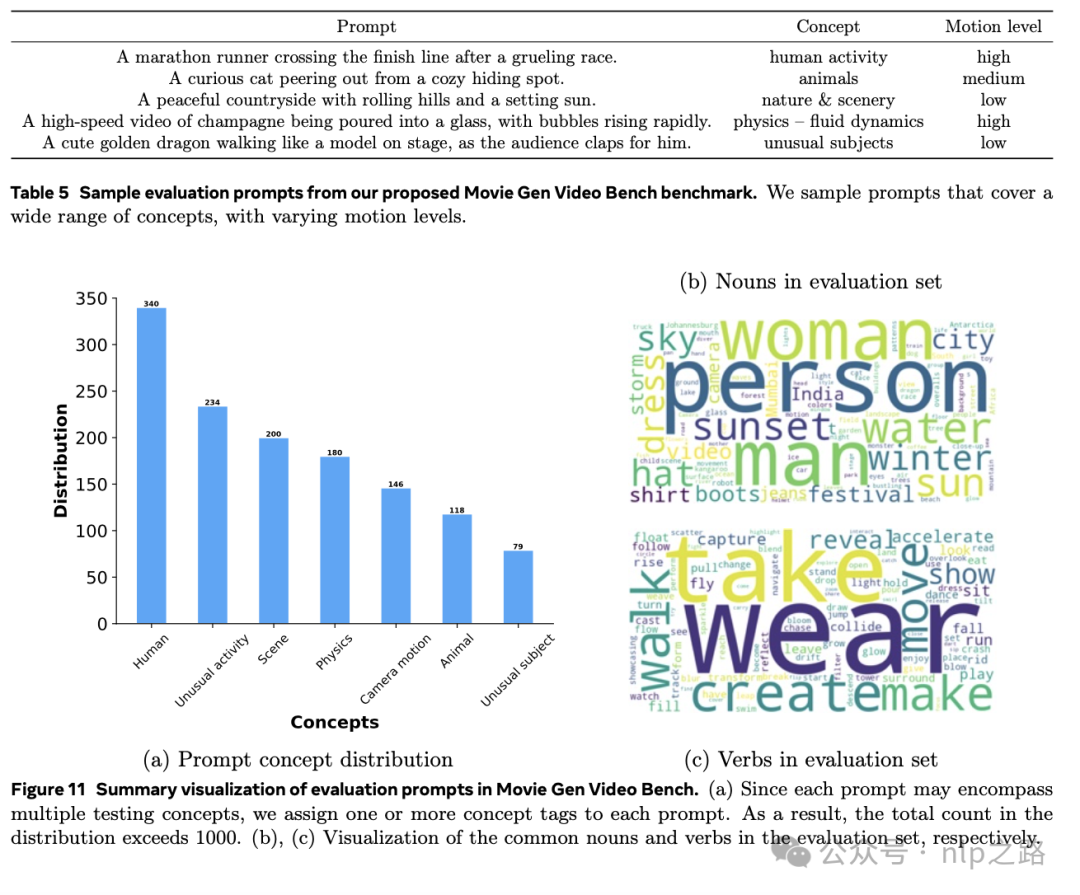
为了全面评估视频生成,meta提出了一个基准测试–Movie Gen Video Bench,包含1000个提示,涵盖了上文总结的所有不同测试方面,比先前工作 (Singer et al., 2023; Girdhar et al., 2024) 中用于评估的提示集大三倍以上。特别包括了捕捉以下概念的提示:
(1)人类活动(肢体和嘴部运动、情感等);
(2) 动物;
(3) 自然和风景;
(4) 物理(流体动力学、重力、加速度、碰撞、爆炸等);
(5) 不寻常的主题和不寻常的活动。
为了测试不同运动水平下的生成质量,还为每个提示标记了高/中/低运动。表5中展示了在Movie Gen Video Bench中使用的评估提示示例,并在图11中展示了评估提示在概念上的分布。
自动化指标如FVD (Unterthiner et al., 2019) 和IS (Salimans et al., 2016) 与视频质量的人类评估分数不相关,因此无法为模型开发或比较提供有用的信号。还是任务太难了,需要依赖人类评估,为降低个人偏好、标准理解程度导致的评估方程,meta采取了下面四个关键步骤:
(1) 为人类评估员提供了详细的评估指南和视频示例,将评估维度和子维度的定义范围缩小到最小,以最小化主观性。此外,受到JUICE指标 (Girdhar et al., 2024) 的启发,让评估员指出他们选择背后的原因有助于减少注释方差并提高评估员之间的一致性。
(2) 在涵盖广泛概念的大量提示上评估模型(保证测试用例的覆盖)。
(3) 使用多数投票系统,每个文本对齐和视觉质量问题有三份注释的多数投票,以及真实性和美学问题的六份注释的多数投票,因为这些更主观。
(4) 对人类注释进行充分和频繁的审核,以解决边缘情况和纠正错误标记。
评估结果
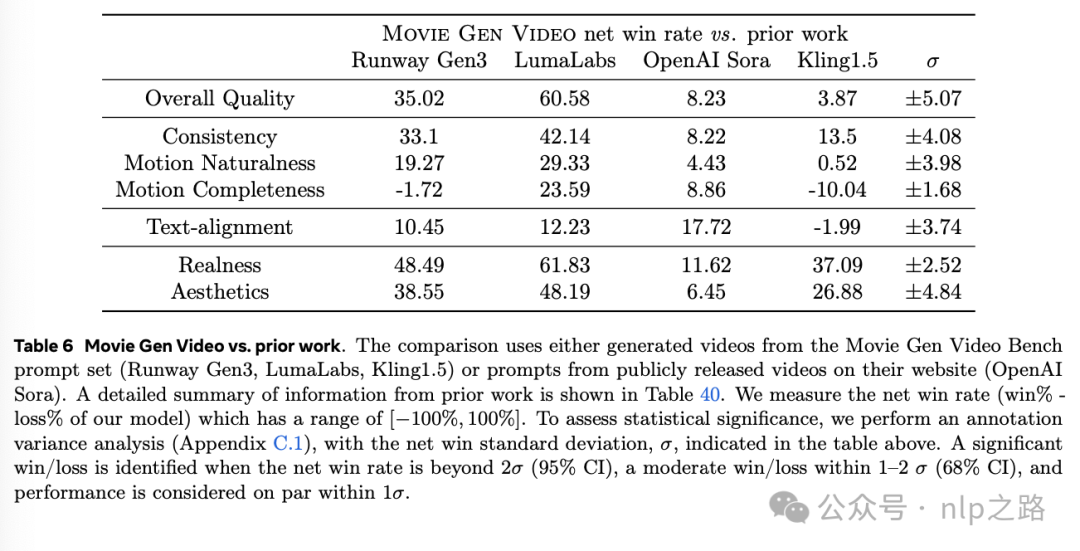
与先前工作的比较
首先需要为先前的文生视频方法获得Movie Gen Video Bench提示集的生成视频,包括通过他们网站提供API访问的黑盒商业模型:Runway Gen3 (RunwayML, 2024)、LumaLabs (LumaLabs, 2024)、Kling1.5 (KlingAI, 2024)。还与闭源文本到视频方法 (OpenAI Sora) 进行了比较,我们唯一的选择是比较他们公开发布的示例中的提示和视频。为了公平比较,通过从Movie Gen Video为每个提示生成的五个候选视频中手动选择一个与OpenAI Sora进行比较。通过在每次比较中将Movie Gen Video的视频下采样到与先前工作相匹配的分辨率和长宽比来减少评估员的偏见。
评估结果显著好于已有的工作。


消融研究
消融基线模型设置。使用一个更小的5B参数版本的Movie Gen Video,训练它产生352×192像素的4-8秒视频。使用TAE,每个时空维度上进行8倍压缩,产生形状为16×24×44的隐变量空间。这个更小的Movie Gen Video模型在transformer中有32层,嵌入维度为3072,24个head。
消融基线训练设置。使用两阶段训练流程:(1) 文本到图像预训练;(2) 文本到图像和文本到视频联合训练。为简单起见,使用了一个包含2100万个视频的较小数据集,这些视频由LLaMa3-Video 8B生成字幕,并具有恒定的风景长宽比用于视频训练。首先,在图像数据集上训练模型,学习率为0.0003,在512个GPU上global batch size为9216,迭代96K次。接下来,进行文本到图像和文本到视频的联合训练,迭代比例为0.02:1,其中global batch size图像4096,视频256。使用5e-5的学习率,训练100K次迭代。
消融结果 - 训练目标。将流匹配训练目标与扩散训练目标进行了比较。按照 (Girdhar et al., 2024) 的做法,使用了扩散的v-pred和终端零信噪比公式进行训练,这对视频生成非常有效。表8a表明,流匹配在整体质量和文本对齐方面都优于扩散模型,同时控制了所有其他因素。这个结果在不同模型规模上都成立,因此使用流匹配来训练模型。
消融结果 - 视频字幕的效果。为了评估视频字幕的重要性,将基于LLaMa3-Video 8B的视频字幕方案与基于图像的字幕方案进行比较,后者也基于LLaMa。这个基于图像的字幕模型对视频剪辑的前三帧进行字幕处理,然后使用LLaMa将这三个基于图像的字幕重写为一个视频字幕。将这个模型称为LLaMa3-FramesRewrite。视频字幕模型能够准确地描述更细粒度的动作细节。这些细粒度的细节为训练视频生成模型提供了更强的监督信号,显著提高了整体提示对齐度,提高了10.8%(表8b),其中大部分增长来自运动对齐(+10.7%),特别是在需要视频中高度运动的提示上(+16.1%)。

消融结果 - 模型架构。与视频生成常用的Diffusion Transformer (Peebles and Xie, 2023) 模型比较,如表9。
如表8c所示,基于LLaMa3的架构在质量和文本对齐方面都显著优于Diffusion Transformer。那么就可以利用LLaMa3相对成熟的scaling law扩展模型规模继续提高性能了。
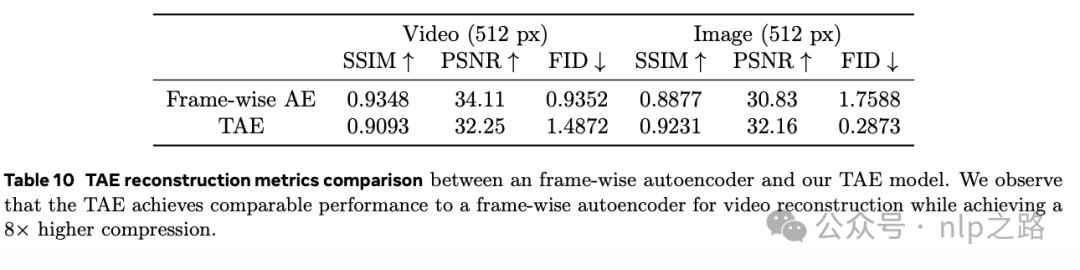
TAE结果
对于评估,论文报告了从训练集分割出来的2秒、4秒、6秒和8秒长的视频剪辑的重建峰值信噪比(PSNR)、结构相似性(SSIM) (Wang et al., 2004) 和Fréchet Inception距离(FID) (Heusel et al., 2017)。还测量了图像验证集上的相同指标。对于视频重建评估,指标是在整个视频帧上平均的。
图16中展示了原始视频和TAE的重建帧。TAE可以在保留视觉细节的同时重建视频帧。TAE重建质量在图像和视频帧中的高频空间细节以及快速运动时会降低。

表10比较了TAE与不执行任何时间压缩的基线Frame-wise autoencoder。基线模型还产生了一个8通道潜在空间,与先前工作保持一致。在视频数据上,TAE在实现相当的性能的同时,实现了8倍更高的时间压缩。在图像上,TAE的表现优于Frame-wise模型,可以归因于隐变量空间的通道尺寸增加(8比16)。
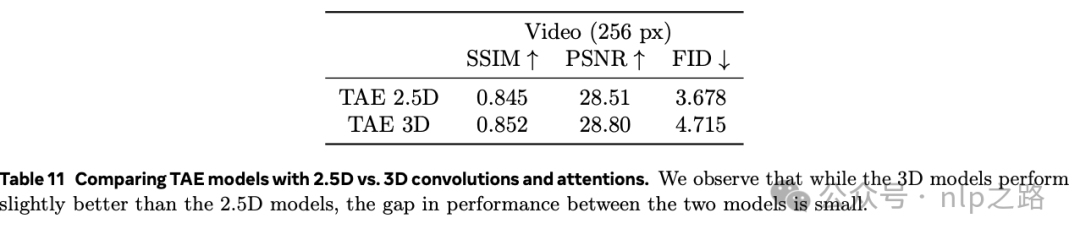
消融基线设置。为简单起见,使用一个更小的4倍压缩比的TAE模型,它产生了一个8通道潜在空间。
对比2.5D与3D注意力和卷积。比较了在TAE中使用2.5D,即2D空间注意力/卷积后面跟着1D时间注意力/卷积与使用3D时空注意力/卷积。在表11中,3D时空注意力略微提高了重建指标,但需要更大的内存和计算成本。综合考虑,meta选择用2.5D。
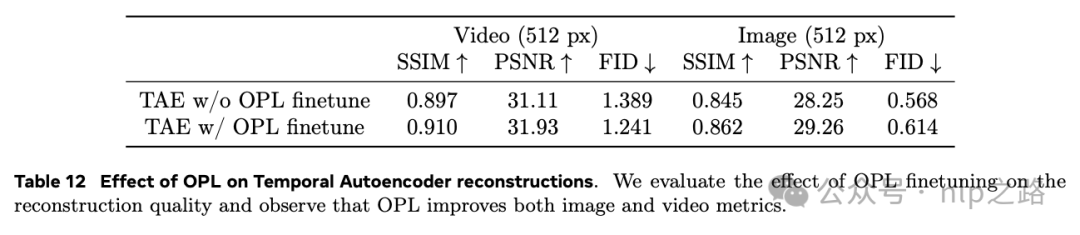
OPL loss的加入不仅提高重构质量,且有效减少了生成结果的斑点现象。
五、文本生成图像
Movie Gen模型是联合训练视频和图像的,因此能够生成两者。为了进一步验证模型的图像生成能力,使用Movie Gen模型作为初始化,并将TAE替换为图像autoencoder。然后在文本到图像生成任务上训练模型,允许它基于文本描述生成图像。最终分辨率为1024像素。对于后训练,我们策划了总共约1000张由内部艺术家创作的图像,用于质量调整,遵循 (Dai et al., 2023) 中概述的方法。对模型进行了6k步的sft,学习率为0.00001,batch size为64。使用了constant lr scheduler,warm-up step为2000。
为了衡量我们的文本到图像生成结果的质量,人类评估员通过成对比较评估以下维度:(a) 文本忠实度,和 (b) 视觉质量。评估员在做出决定之前被要求寻找生成中的缺陷,例如,手指或手臂的数量错误,或视觉文本拼写错误。
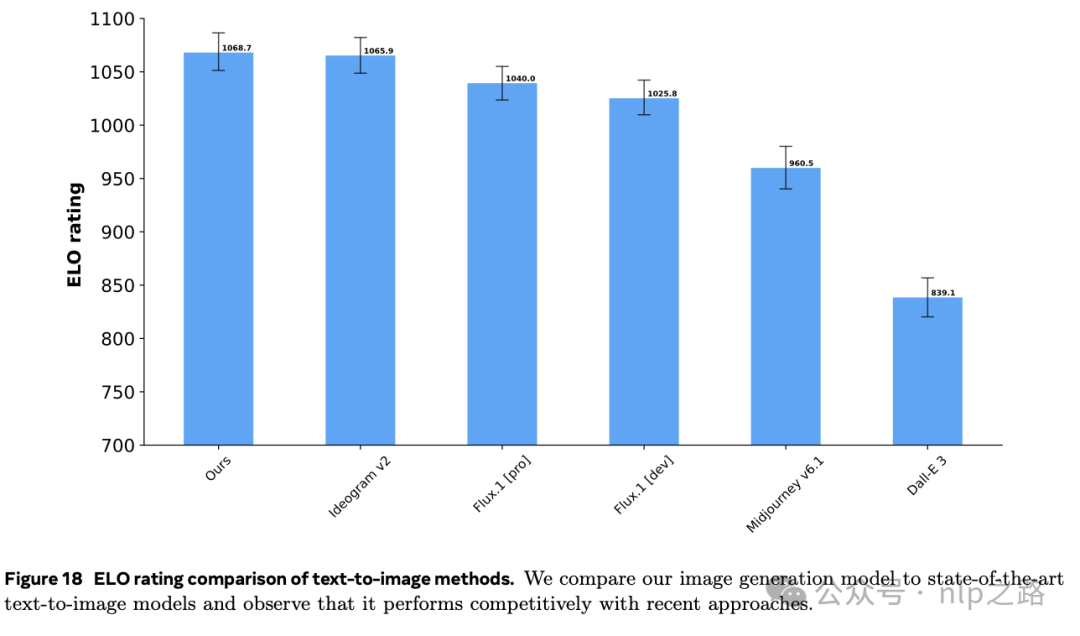
图18显示,图像生成任务中,也达到了SOTA。
基于用户图像的个性化视频生成、基于精确指令的视频编辑、视频到音频生成和文本到音频生成部分会在后续的文章继续介绍。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
原文地址:https://blog.csdn.net/Everly_/article/details/143003770
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!