vLLM×Milvus:如何高效管理GPU内存,减少大模型幻觉

大语言模型(LLM)是功能丰富且强大的 AI 系统,能够解决各个领域内的众多问题。它们的发展速度非常快,新模型不断被频繁推出。通常,新推出的 LLM 在处理各种任务时的性能更好。例如 Mistral、Llama、OPT 和 Qwen 等模型都是开源模型,我们可以针对内部数据商用这些模型。
然而,在使用这些开源 LLM 时,Serving阶段可能会出现挑战。由于托管 LLM 需要多个GPU,因此其运营成本尤其昂贵。因此,在 Serving 阶段实现有效的内存管理至关重要。一个可行的解决方案是通过 PagedAttention 算法。本文将重点探讨这种解决方案。
01.
LLM 推理(Inference)问题
本质上,LLM 由大量的 Transformer 解码器堆叠而成。基于 Transformer 解码器的架构按顺序生成文本。这意味着生成的文本越长,运行这些 LLM 所需的 GPU 内存就越多。
举个例子,根据 GPT-4 的定价,一个 8k 上下文窗口的模型比 128k 上下文窗口的模型更便宜。这种价格差异反映了输出文本越多,成本越高。此外,我们还需要考虑模型的大小。如下图所示,当在 NVIDIA A100 上托管一个具有 13B 参数的 LLM 时,65% 的 GPU 内存将被用于存储模型的权重,30% 用于键值(KV)缓存(或上下文窗口),其余的用于模型的激活。
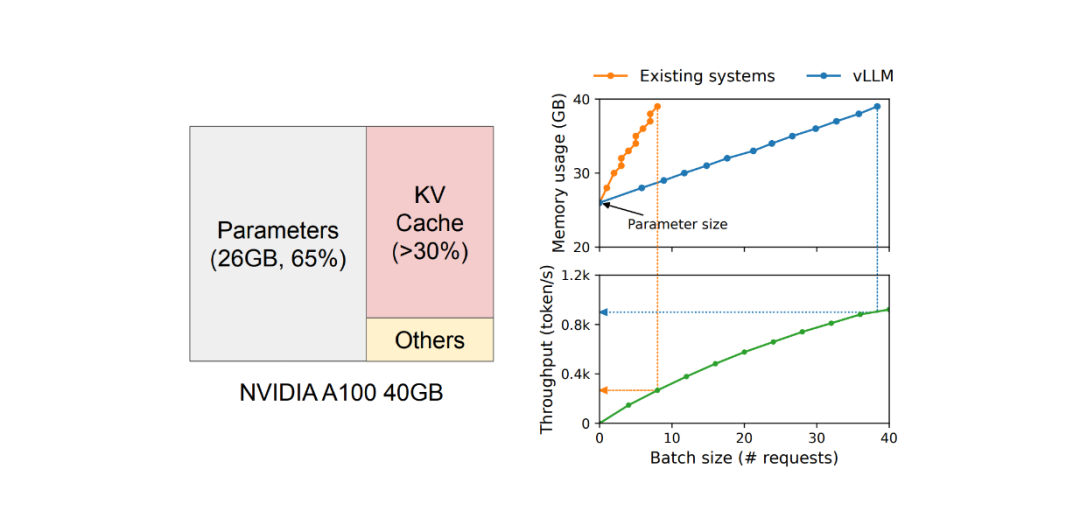
众所周知,运行一个开源 LLM 作为托管服务非常昂贵,并且需要多个 GPU。因此,提高吞吐量和降低每个请求的成本至关重要。那么我们如何实现这一点呢?从 GPU 内存消耗的角度来看,模型的权重是固定的,我们对此无能为力。与此同时,激活只占用了一小部分 GPU 内存。因此,优化键值(KV)缓存中的内存管理应该是提高吞吐量的主要关注点。
然而,优化 KV 缓存的主要挑战在于 LLM 输出生成的性质。如前所述,Transformer 解码器按顺序生成文本输出,这可能导致在推理过程中的 GPU 利用率低。
提高 GPU 内存利用率和吞吐量的明显改进方式是执行批量请求。然而,在 LLM 中实现批量请求困难有两个原因:
请求可能在不同时间到达。一个简单的批量策略要么让早期请求等待后期请求,要么延迟到达的请求直到早期请求完成,但这会导致排队延迟。
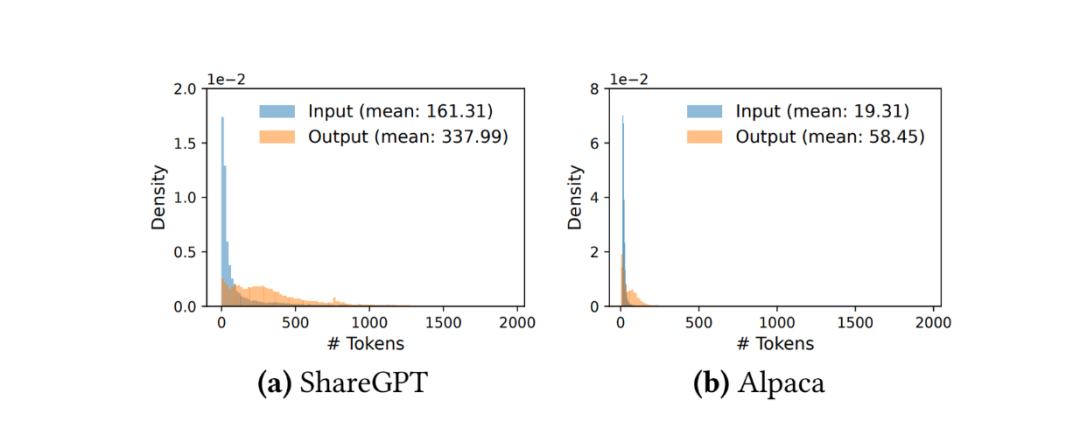
请求可能具有不同的输入和输出长度。下图展示了 ShareGPT 和 Alpaca 数据集中的 Token 分布。最直接的解决方案是实现填充(Padding),使得每个请求具有相似的长度,但这会浪费内存。
为了解决这些问题,我们可以采用一种称为 cellular batching 和 iteration-level scheduling 的方法。这些方法根据迭代运行而不是在请求级别上运行。与等待整个批次完成不同,一旦一个迭代完成,就可以立即处理新的请求。
尽管 cellular batching 和 iteration-level scheduling 解决了与 GPU 内存利用相关的问题,但一批中可以处理的请求数量仍然受到 GPU 内存容量的限制。但好消息是,KV 缓存的工作方式的特性为还存在改进空间。在实现过程中,KV 缓存在消耗 GPU 内存方面具有独特的特性:随着模型生成新 token,它可以动态地增长和缩小,并且其长度是事先无法预知的。
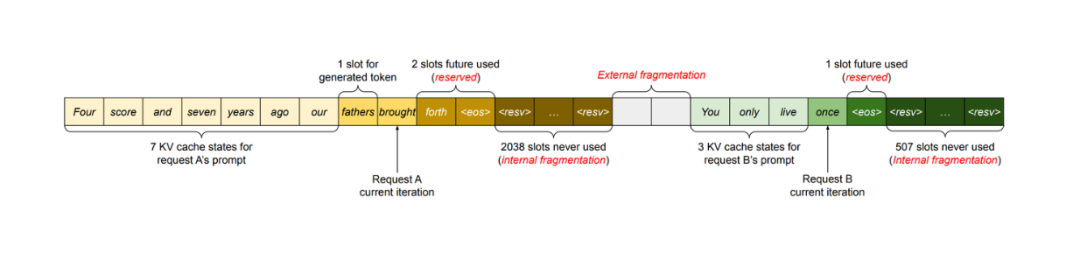
在使用 LLM 进行推理时,我们通常需要设置一个生成 Token 的最大数量(例如,1000、2048 等)。然后 GPU 根据这个最大长度分配一个连续的内存块。这种方法可能会浪费内存,因为在大多数情况下,生成的 Token 比最大长度短得多。
如下图所示,性能分析结果表明,实际用于存储 token 的 KV 缓存内存只有 20.4% 到 38.4%。
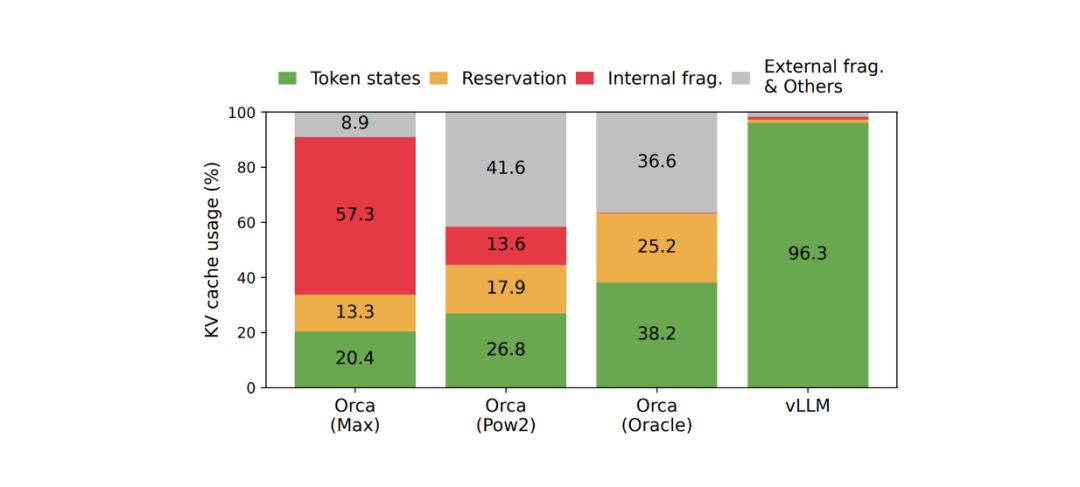
第二个改进方式与 KV 缓存的内存共享有关。LLM 可以为每个请求的单个 Prompt 生成多个版本的输出。如果 KV 缓存能够在多个输出版本之间共享,那么就可以优化 GPU 内存消耗情况。然而,目前是无法实现内存共享的,因为每个请求的 KV 缓存存储在单独的连续空间中。
为了解决这些问题,我们可以引入一种称为 PagedAttention 的方法,我们将在下一节中详细讨论。
02.
PagedAttention 和 vLLM 的工作原理
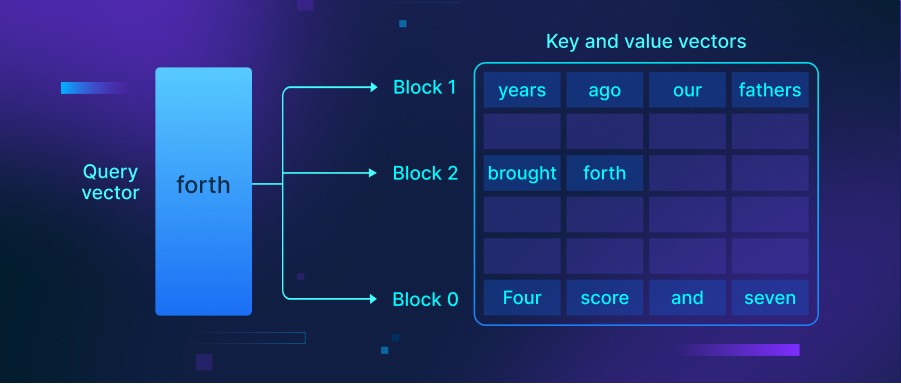
PagedAttention 是一种能够在非连续内存空间存储连续 KV 对的方法。以请求 Prompt_“Four score and seven years ago, our fathers brought forth.”_为例。
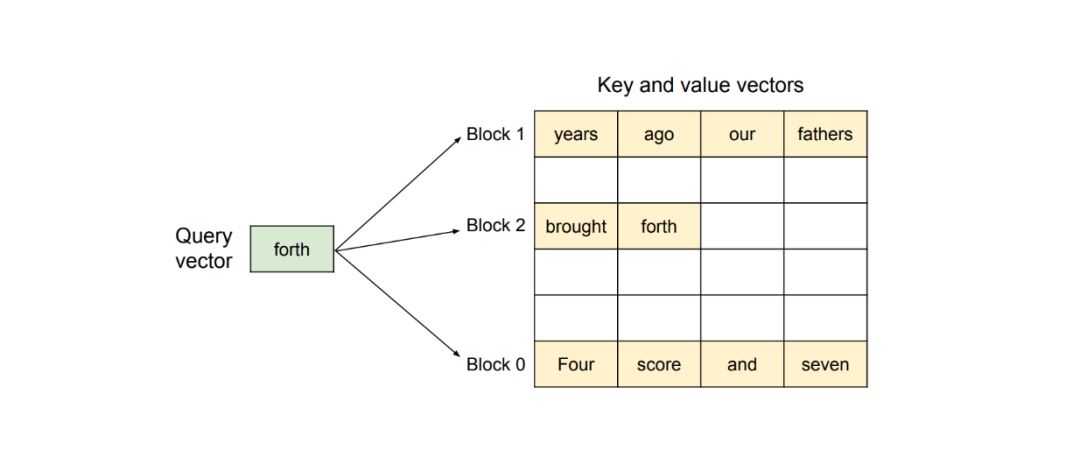
PagedAttention 方法首先将这个请求的 KV 缓存分割成 KV 块。每个 KV 块包含固定数量 token 的 KV 向量。
如上图所示,PagedAttention 将我们的 Prompt 分割成三个在物理内存中的非连续 KV 块。在计算过程中,该方法分别识别并获取每个 KV 块,以计算下一个可能的 token 相对于之前 token 的注意力。
这种 PagedAttention 方法是在 vLLM —— LLM 服务引擎内部实现的,论文中也介绍了该引擎。
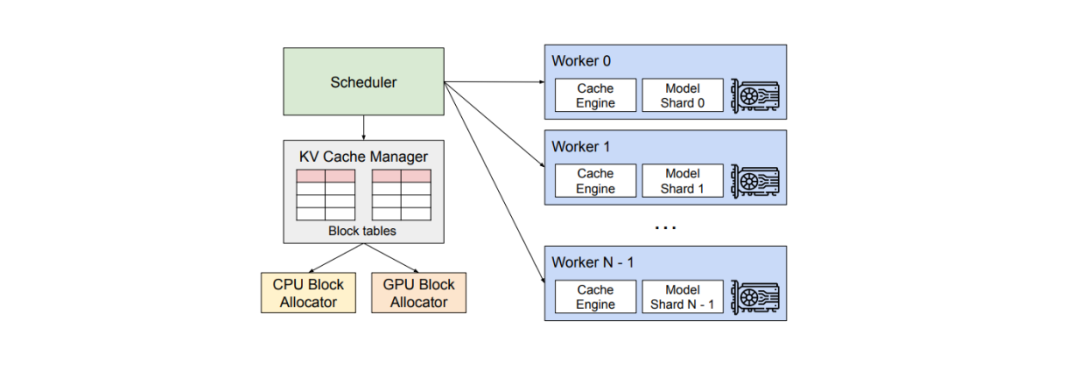
vLLM 包含一个集中调度器,用于协调分布式 GPU 工作器的执行,以及一个 KV 缓存管理器。KV 缓存管理器的主要目标是以分页方式有效管理 KV 缓存。这个管理器的实现灵感来自于操作系统(OS),它们将内存分割成固定大小的页面,并创建用户程序从逻辑页面到物理页面的映射。
这种实现的好处是连续的逻辑页面可以对应于非连续的物理页面。这意味着我们不需要像传统的 KV 缓存系统那样提前预留物理内存,从而消除了 GPU 利用中的内存浪费。
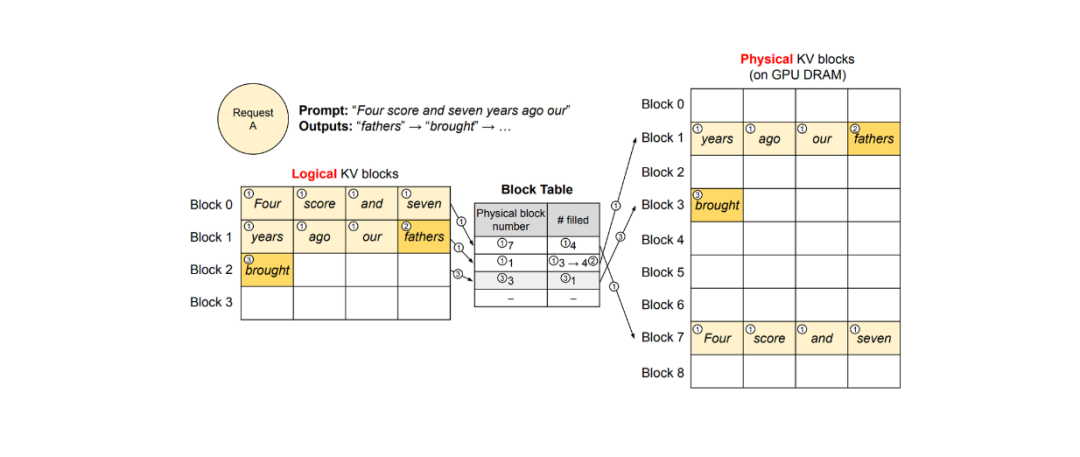
为了在每个请求中将逻辑页面映射到物理页面,KV 缓存管理器使用一个块表。块表记录了逻辑页面和物理页面中每个 KV 块的位置,以及填充和未填充位置的数量,如下所示。
2.1.使用 PagedAttention 和 vLLM 的解码过程
在这小节中,我们将详细查看 PagedAttention 和 vLLM 如何处理单个请求。
假设我们发出一个包含 7 个 token 的 Prompt 请求,如上面的图片所示,每个 KV 块可以存储 4 个 token。在这种情况下,vLLM 最初分配 2 个逻辑块来存储我们 Prompt 的 KV,我们将称之为块 0 和块 1。然后 vLLM 将这些逻辑块映射到 2 个物理 KV 块(图中的块 1 和块 7)并在块表中记录这个映射。
在文本生成过程中,由于逻辑块 1 的最后一个槽位仍然可用,vLLM 将新生成的 token 存储在那里。接下来,块表中的 #filled 记录会更新,如图中第 2 步所示。
在第二次迭代中,当所有逻辑块的槽位都填满时,vLLM 分配一个新的逻辑块。然后它将新 token 存储在那里,分配一个新的物理块(图中的块 3),并在块表中记录这个映射。一旦请求完成,其对应的 KV 块就可以释放供其他请求使用。
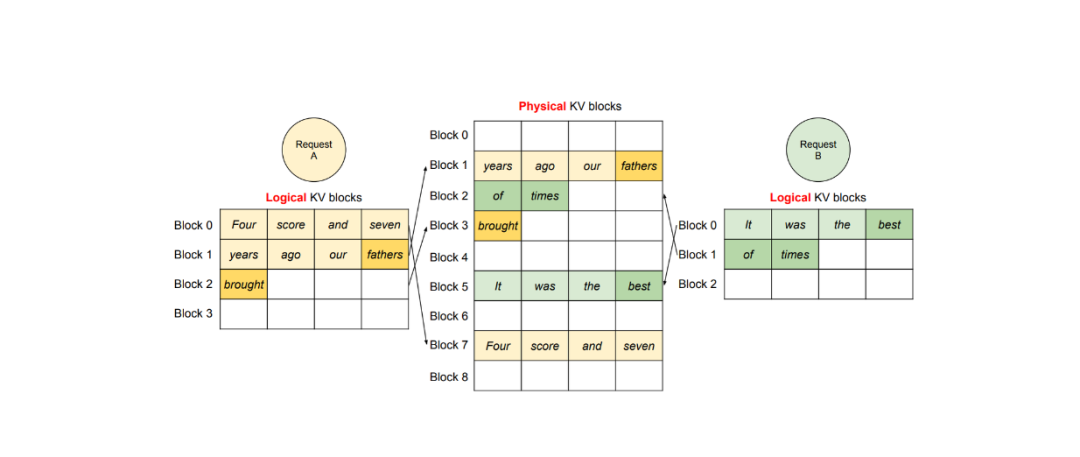
这种方法允许 GPU 内存接收更多请求,并确保没有 GPU 内存被浪费。在多个请求的情况下,不同请求的逻辑块将被映射到不同的物理块,如下所示。
2.2.并行采样(Parallel Sampling)
vLLM 和 PagedAttention 还可以处理许多其他高级解码场景,例如并行采样。
当我们希望一个 LLM 输出多个版本的输出时,vLLM 提供了一个高效的解决方案,允许一个 Prompt 的 KV 缓存被共享从而生成多个输出。主要思想是,一个物理块可以映射到多个逻辑块,因此,vLLM 加入了一个称为引用计数(reference count)的变量。
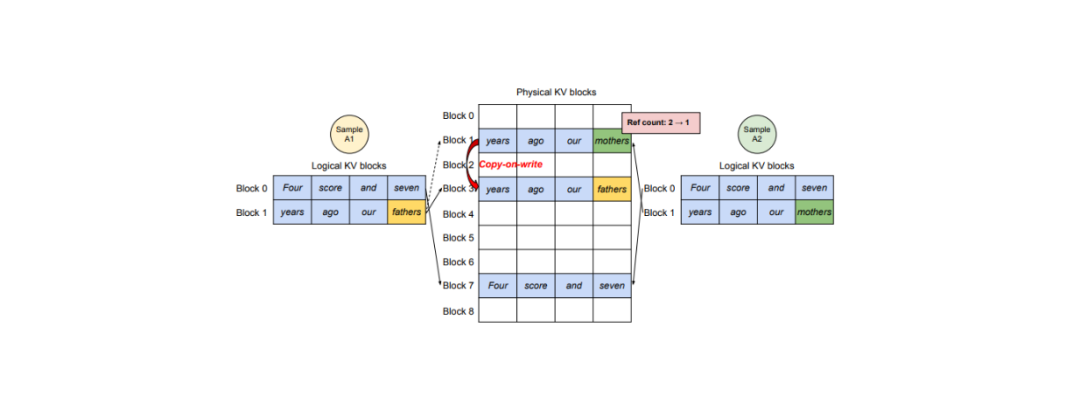
引用计数表示有多少逻辑块映射到特定的物理块。如果我们希望 LLM 生成两个版本的输出,A 和 B,那么特定物理块的引用计数将是 2。
在文本生成阶段,如果样本 A 需要写入其逻辑块的最后一个槽位,vLLM 会检查其对应物理块的引用计数。如果引用计数大于 1,vLLM 会在一个新的物理块中创建该块的副本,并将引用计数减少到 1。随后,如果样本 B 需要写入其最后一个逻辑块,新的 KV 缓存可以存储在原始物理块内,因为现在引用计数是 1。
并行采样的概念在创建系统 prompt 的场景中也很有用。系统 prompt 是一组我们提供给 LLM 作为输入的指令和任务,这个系统 prompt 可能在多个请求中都不会改变。在这种情况下,vLLM 可以保留物理块来存储系统 prompt 的 KV 缓存,然后执行多个文本生成,类似于上面的步骤。
在并行采样的实现过程中,vLLM 不仅支持共享 prompt 块,还支持共享不同样本之间的其他块。这在集束搜索(beam search)场景中特别有用,因为这种情况下,我们通常希望在文本生成的每次迭代中保留前 k 个候选。
调度(Scheduling)和抢占(Preemption)
在托管 LLM 进行推理时,我们可能会遇到流量请求超过系统容量的情况。在这种情况下,vLLM 通过先到先得(first-come-first-served,FCFS)的调度方式,确保优先处理最早的请求。
然而,这种调度方式可能会导致一些问题。例如,我们可能会遇到 vLLM 在 GPU 中没有足够的物理块来存储某个请求新创建的 KV 缓存的情况。在这种情况下,解决方案是丢弃一些物理块以释放空间。为了实现这一点,vLLM 实施了一种方法,即一次性丢弃属于序列的所有物理块。
这种方法引发了一个重要的问题:如果我们将来需要被丢弃的块怎么办?有没有办法恢复它们?vLLM 实施了两种方法来解决这个问题:
交换(Swapping):vLLM 的架构包括一个 CPU 分配器。当块从 GPU 内存中被丢弃时,vLLM 将它们复制到这个 CPU 内存中以备将来使用。
重新计算(Recomputation):如果需要,vLLM 可以简单地重新计算请求序列的 KV 缓存。
03.
vLLM 在基准数据集上的性能
为了评估 vLLM 与其他 LLM 服务方法的性能,我们使用不同的 LLM 和数据集进行了几项测试。
在测试中使用了两种不同的 LLM 类型:具有 13B、66B 和 175B 参数的 OPT 模型,以及具有 13B 参数的 LLAMA。使用的数据集包括 ShareGPT 数据集,该数据集包含用户与 ChatGPT 共享的对话;以及 Alpaca 数据集,该数据集包含由 GPT-3.5-instruct 生成的数据。
在论文中与 vLLM 比较的方法有 FasterTransformer 和不同设置下自行实现的 Orca:
Orca (Oracle):假设系统知道请求中生成的 token 数量。
Orca (Pow2):假设系统超额预留的空间内存最多是实际生成 token 的 2 倍。
Orca (Max):假设系统预留的空间内存由事先定义的生成 token 的最大长度决定(例如,2048 个 token)。
在使用 OPT 175B 模型进行基本采样(即每个请求输出一个样本)的情况下,根据下图,在 ShareGPT 数据集上,vLLM 的吞吐量比 Orca (Oracle) 高出 1.7x - 2.7x,比 Orca (Max) 高出 2.7x - 8x。在同一数据集上,vLLM 远优于 FasterTransformer,吞吐量高出 22 倍。
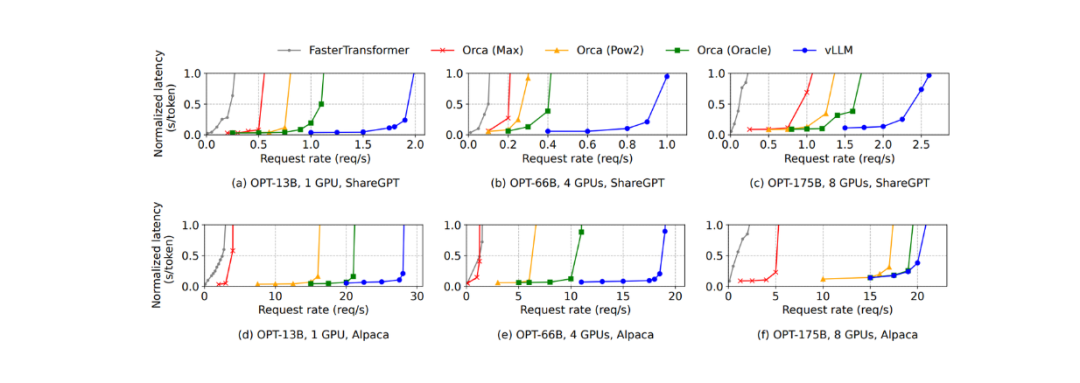
在 Alpaca 数据集上出现了类似的现象。然而,使用 vLLM 在这个数据集上的优势并不像在 ShareGPT 数据集上那么明显。这是因为 OPT 175B 模型需要大量的 GPU 内存来存储 KV 缓存,但这个数据集的平均序列长度远比 ShareGPT 短。
对于并行采样和 beam search,vLLM 提供了更大的性能优势,因为需要更多的序列来进行采样。例如,在 Alpaca 数据集上,使用 vLLM 的性能提升从基础采样的 1.3 倍增加到了进行宽度为 6 的 beam search 时的 2.3 倍。如下所示:
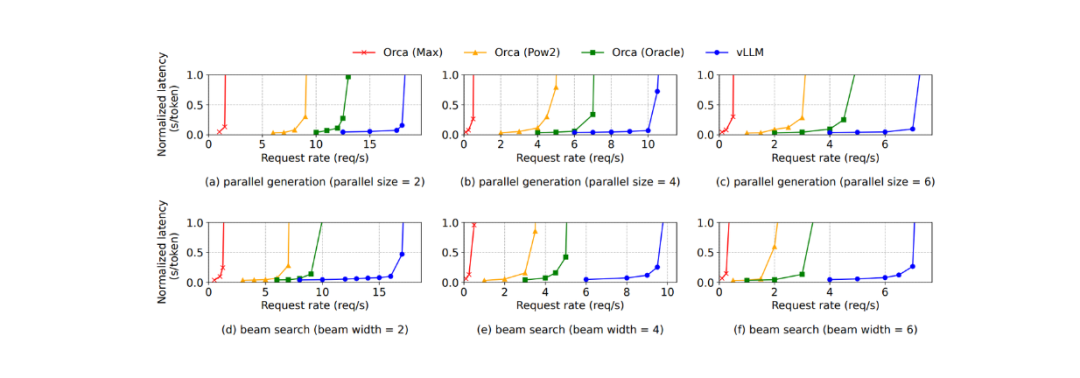
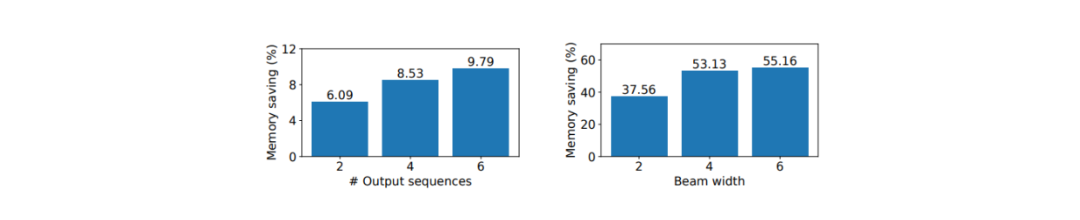
在并行采样和 beam search 过程中,vLLM 在节省 GPU 内存方面比其他方法表现得更好。它在并行采样中节省了 6.1% 至 9.8% 的内存,在 beam search 中节省的内存高达 55.2%。
在使用 vLLM 时,有一个可以调整的参数:块大小,选择合适的块大小非常重要。如果块太小,vLLM 可能无法充分利用 GPU 的并行计算。同时,如果块太大,内部碎片会增加。从 ShareGPT 和 Alpaca 数据集的观察中可以得出结论,块大小= 16 时能够很好地利用 vLLM 的强大性能。因此,vLLM 的默认块大小值为 16。
04.
vLLM 应用
本节将简要介绍一个 vLLM 的具体用例。我们将基于输入 prompt 进行离线推理。最简单的安装 vLLM 方法就是通过 pip install 命令来安装。
pip install vllm现在我们可以安装所需的依赖库并定义输入的 Prompt 列表,如下所示:
from vllm import LLM, SamplingParams
prompts = "Hello, my name is"
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)在上述的 SamplingParams 类中,您可以定义用于生成文本输出的采样参数,比如 LLM 的温度(temperature)、top p、top k、输出序列的数量等。您可以通过这份文档查看这个类中您可以修改的完整参数列表(https://docs.vllm.ai/en/latest/dev/sampling_params.html#vllm.SamplingParams)。
接下来,我们初始化 LLM,然后使用给定的 prompt 生成输出。我们将使用拥有 15 亿参数的微软 Phi 模型。你可以在这份文档中查看 vLLM 支持的模型列表(https://docs.vllm.ai/en/latest/models/supported_models.html#supported-models)。
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
# Print the output
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")05.
集成 vLLM 与 Milvus
在已经了解了 vLLM 的基本实现后,让我们使用 vLLM 和 Milvus 构建一个简单的检索增强生成(RAG)系统。Milvus 是一款开源向量数据库,可以存储数百万的向量,并进行向量搜索。
最简单的 Milvus 使用方式就是安装 Milvus Lite,你可以通过 pip 命令来安装它,如下所示:
!pip install -U pymilvus
!pip install pymilvus[model]现在我们来创建一个 Collection,然后向其中插入数据。在下面的示例中,我们首先将文本数据转换为 Embedding 向量,然后将三个文本数据插入到 Milvus 数据库中。接下来,将向量以及元数据(如主题和原始文本)一起存储到 Milvus 中。
from pymilvus import MilvusClient
from pymilvus import model
client = MilvusClient("milvus_demo.db")
# Create collection
if client.has_collection(collection_name="rag_vllm"):
client.drop_collection(collection_name="rag_vllm")
client.create_collection(
collection_name="rag_vllm",
dimension=768, # The vectors we will use in this demo has 768 dimensions
)
# Define embedding model
embedding_fn = model.DefaultEmbeddingFunction()
# Text data to search from.
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
# Transform text data into embeddings
vectors = embedding_fn.encode_documents(docs)
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
# Insert embeddings into Milvus
res = client.insert(collection_name="rag_vllm", data=data)在此阶段,我们的数据已经存储在 Milvus 中。接下来,我们可以根据查询从 Milvus 数据库中检索最相关的数据。
假设我们的问题是“What's Alan Turing achievement?”。通过执行向量搜索可以获取最相关的文本。但在那之前,需要使用相同的 Embedding 模型将我们的查询转换为 Embedding 向量。
SAMPLE_QUESTION = "What's Alan Turing achievement?"
query_vectors = embedding_fn.encode_queries([SAMPLE_QUESTION])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=1,
output_fields=["text"],
)
context = res[0][0]["entity"]["text"]现在我们已经根据查询得到了最相关的数据。在 RAG 系统中,我们使用这些最相关的数据作为上下文 传入LLM,用来生成具有上下文的回答。通过向 LLM 提供相关的上下文,可以降低 LLM 产生幻觉(hallucination)的风险。
让我们来创建一个完整的 prompt,并发送给 LLM。在RAG应用中,prompt 由高级任务或指令、原始查询以及通过向量搜索获取的上下文组成。
SYSTEM_PROMPT = f"""Answer the question using the provided Context.
Be clear, concise, relevant.
Context: {context}
User's question: {SAMPLE_QUESTION}
"""
prompts = [SYSTEM_PROMPT]最终,我们可以运行使用 Microsoft Phi 1.5B 模型的 RAG 系统。
from vllm import LLM, SamplingParams
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="microsoft/phi-1_5")
outputs = llm.generate(prompts, sampling_params)
# Print the output
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
"""
Output:
Question: "What's Alan Turing achievement?"
Generated text: "Answer: Alan Turing's achievement in AI is his pioneering work in developing the concept"
"""太棒了!现在您已经成功地使用 Milvus、vLLM 和微软的 Phi 模型搭建了一个简单的 RAG 系统。如需了解更多有关 Milvus 与 vLLM 集成的详细信息,可以查看官方文档(https://milvus.io/docs/milvus_rag_with_vllm.md)。
06.
总结
本文详细介绍了 PagedAttention 和 vLLM 相关的一篇论文《Efficient Memory Management for Large Language Model Serving with PagedAttentio》(https://arxiv.org/pdf/2309.06180)。PagedAttention 和 vLLM 解决了 LLM Serving 过程中的重要挑战,特别是在推理时 GPU 内存使用率低但使用成本高的问题。PagedAttention 通过在非连续的内存块中存储 KV 缓存来优化 GPU 内存消耗,而 vLLM 则结合了先进的内存管理技术来降低 GPU 内存使用成本。
性能测试表明,与 FasterTransformer 和 Orca 等方案相比,vLLM 的性能更为优越。随着我们需要生成更多序列(例如在并行采样和 beam search 场景中),使用 vLLM 的好处变得更加明显。通过使用 vLLM,我们可以减少 LLM 产生幻觉的风险,同时提供相关的上下文,这对 RAG 应用来说是非常关键的。
更多资源
2023 vLLM paper on PagedAttention (https://arxiv.org/pdf/2309.06180)
vLLM GitHub Repository (<https://github.com/vllm-project/vllm and model page>)
Building RAG with Milvus, vLLM, and Llama 3.1 (https://zilliz.com/blog/building-rag-milvus-vllm-llama-3-1)
Zilliz Cloud + vLLM: High-Performance RAG Systems (https://zilliz.com/product/integrations/vllm)
Building RAG with Milvus, vLLM, and Llama 3.1 | Milvus Documentation (https://milvus.io/docs/milvus_rag_with_vllm.md)
2023 vLLM presentation at Ray Summit (https://www.youtube.com/watch?v=80bIUggRJf4)
vLLM blog: vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention (https://blog.vllm.ai/2023/06/20/vllm.html)
What is RAG? (https://zilliz.com/learn/Retrieval-Augmented-Generation)
What are Vector Databases and How Do They Work? (https://zilliz.com/learn/what-is-vector-database)
本文作者:Ruben Winastwan
2024年非结构化数据峰会的报名通道现已开启!
作为备受瞩目的年度重磅盛会,本次大会以“数绘万象,智联八方”为主题,邀请广大AI产业伙伴,从生态构建、客户案例、技术前瞻、商业化落地等多个角度共同研讨智能化的新未来。
如果您对AI产业化落地充满热情,渴望加入这场智慧的盛宴,请移步至文章末尾,扫描二维码即刻报名参与!



原文地址:https://blog.csdn.net/weixin_44839084/article/details/143756461
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!