场景文本检测&识别学习 day04(目标检测的基础概念)
经典的目标检测方法
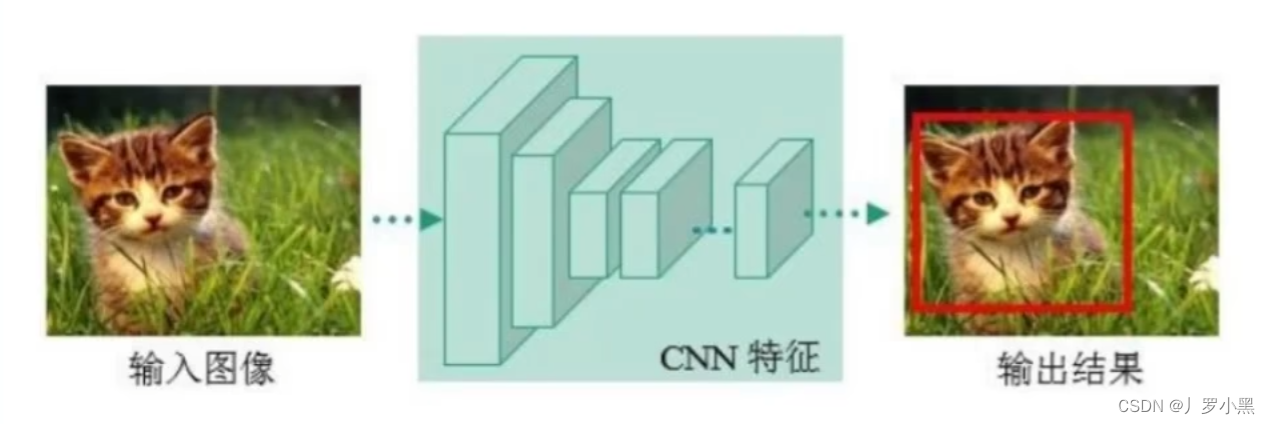
one-stage 单阶段法:YOLO系列、SSD系列
- one-stage方法:仅预测一次,直接在特征图上预测每个物体的类别和边界框
- 输入图像之后,使用CNN网络提取特征图,不加入任何补充(锚点、锚框),直接输出预测框左上右下角的坐标(回归任务)以及物体的类别(分类任务)
- 即该CNN网络在单次前向传播中,不仅提取特征,还要预测每个物体的类别和边界框
- 优点:速度非常快,适合做实时检测任务
- 缺点:效果通常不会太好
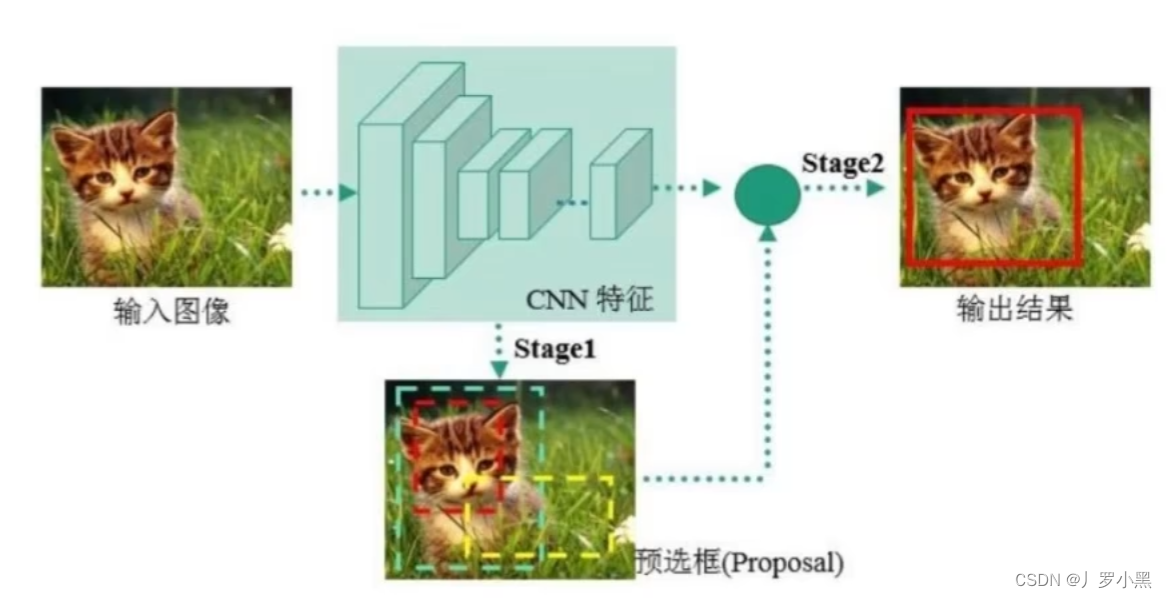
two-stage 两阶段:Faster-RCNN 、 Mask-RCNN系列
- two-stage方法:先进行一个粗糙的目标检测(例如使用RPN网络),之后再根据粗糙的目标检测结果来进行更精确的目标检测。
- 一阶段,区域提议:输入图像之后,会先经过CNN网络,生成特征图。在将特征图送入RPN(区域提议网络)生成一系列区域提议(锚框,大概2万个),RPN根据这些锚框,输出这些锚框包含物体的概率(二分类:前景、背景),以及锚框与真实边界框的偏移量,应用该偏移量后得到候选框(提议区域,大概缩小到2000个)
- 二阶段,检测:对于一阶段得到的提议区域(RoI),我们根据正负样本的比例(通常为1:1)进一步选取一定数量的提议区域(候选框,大概256个),先将其映射回特征图的对应区域,再使用RoI池化、RoI Align,从特征图对应区域中提取固定尺寸大小的特征,并将这些特征送入检测网络(全连接),得到最后选择的候选框中的类别概率(多分类:具体哪一个物体)、从候选框到真实边界框的偏移量。并应用该偏移量后得到最后的预测框。(训练阶段)
- 在测试阶段,由于我们不知道真实框,所以有可能多个预测框检测到同一物体,最后需要使用NMS来过滤这些重复框。最后根据置信度阈值来输出类别、相应置信度得分、以及预测的目标边界框
- 注意,在RPN和测试时的检测阶段中都会使用NMS操作:
- 在RPN中,我们先使用NMS来筛选锚框,选择高质量的锚框来进行损失计算,此时虽然使用了NMS,但是不会唯一确定与真实框对应的锚框,反而会选择一个合理数量(例如256个)的锚框,来进行下一步的损失计算
- 在测试时的检测阶段,我们会在得到预测框后,使用NMS来确定唯一对应的预测框,并进行输出
- 但是在训练时的检测阶段,我们不会用NMS来减少预测框,因为我们需要所有预测框对模型训练的贡献
- 注意,虽然在RPN和检测阶段都会使用真实边界框来计算偏移量:
- 但是在RPN中,通过计算真实边界框和锚框的IoU来判断正负样本,以及通过计算正样本的锚框和真实边界框的偏移量,来训练RPN,使它学会如何调整锚框来更好的覆盖真实物体,并应用偏移量后得到候选框。(较为粗略的候选框)
- 在检测阶段中,仍然计算通过计算真实边界框和候选框的IoU,但是得到具体的物体类别,以及通过计算候选框和真实边界框的偏移量,来训练检测网络,使它学会更精细的调整候选框来更好的覆盖该物体,并应用偏移量后得到最后的预测框。(更精细的预测框)
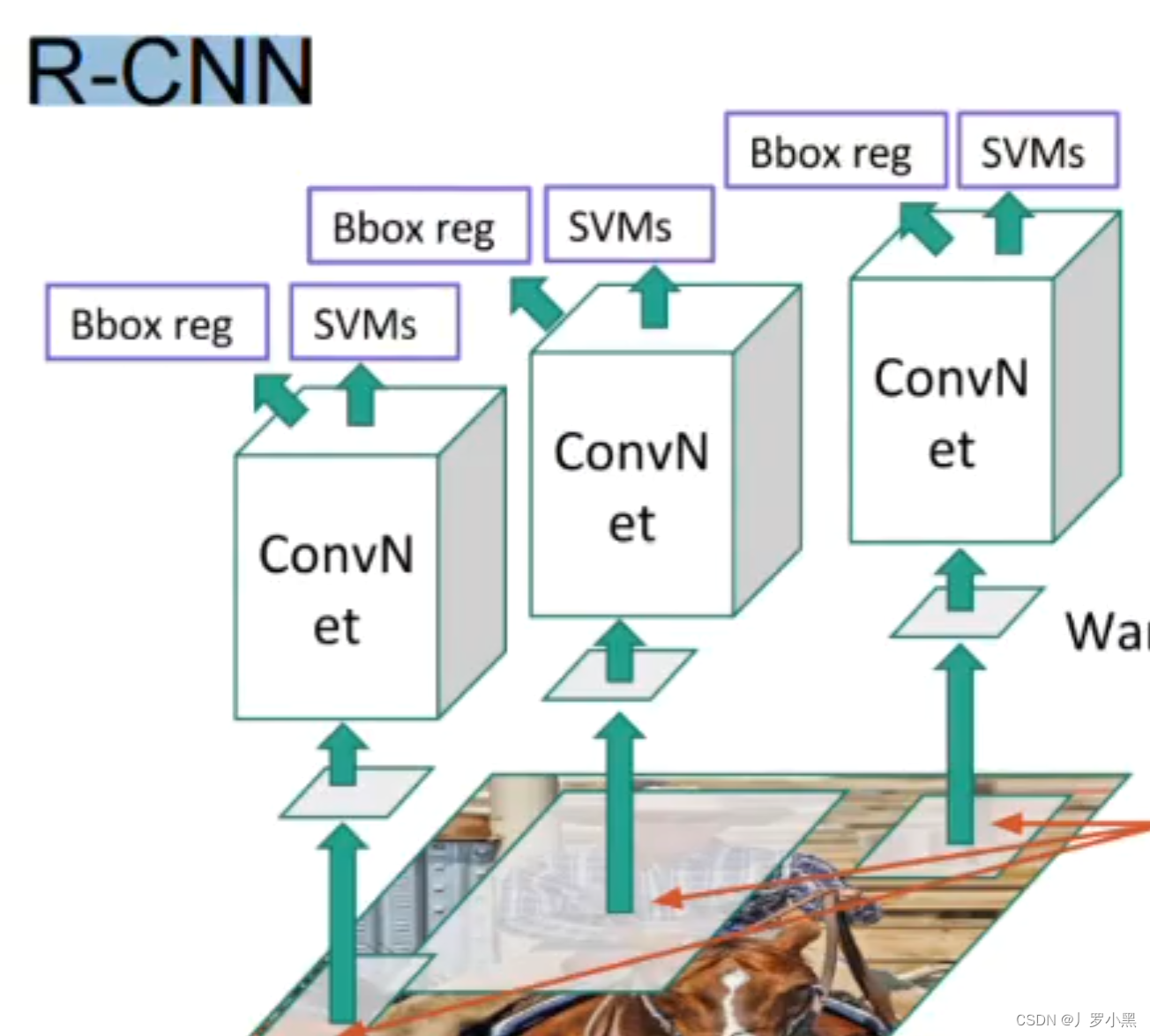
R-CNN、Fast R-CNN、Faster R-CNN 、Mask R-CNN系列解释
-
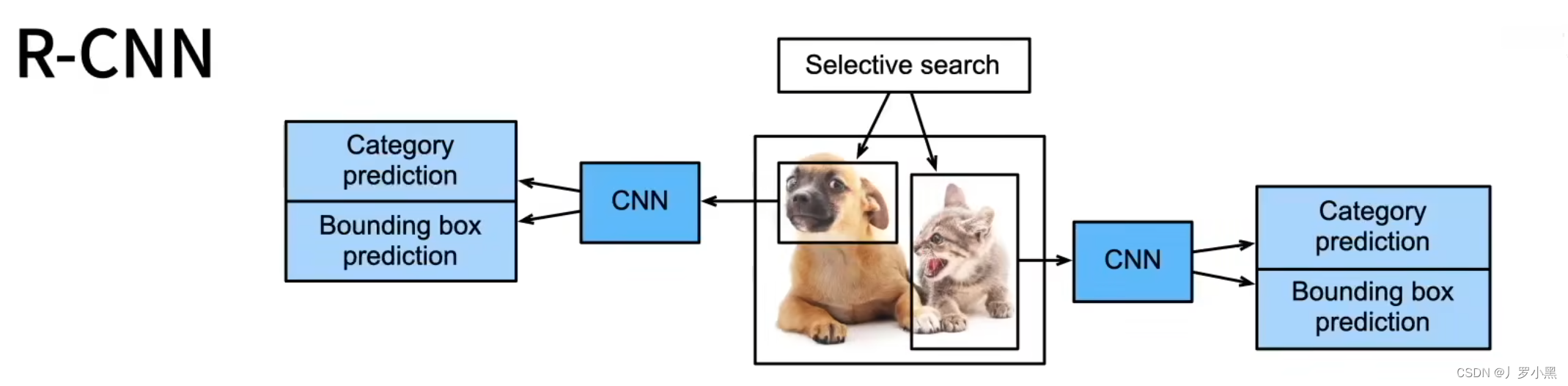
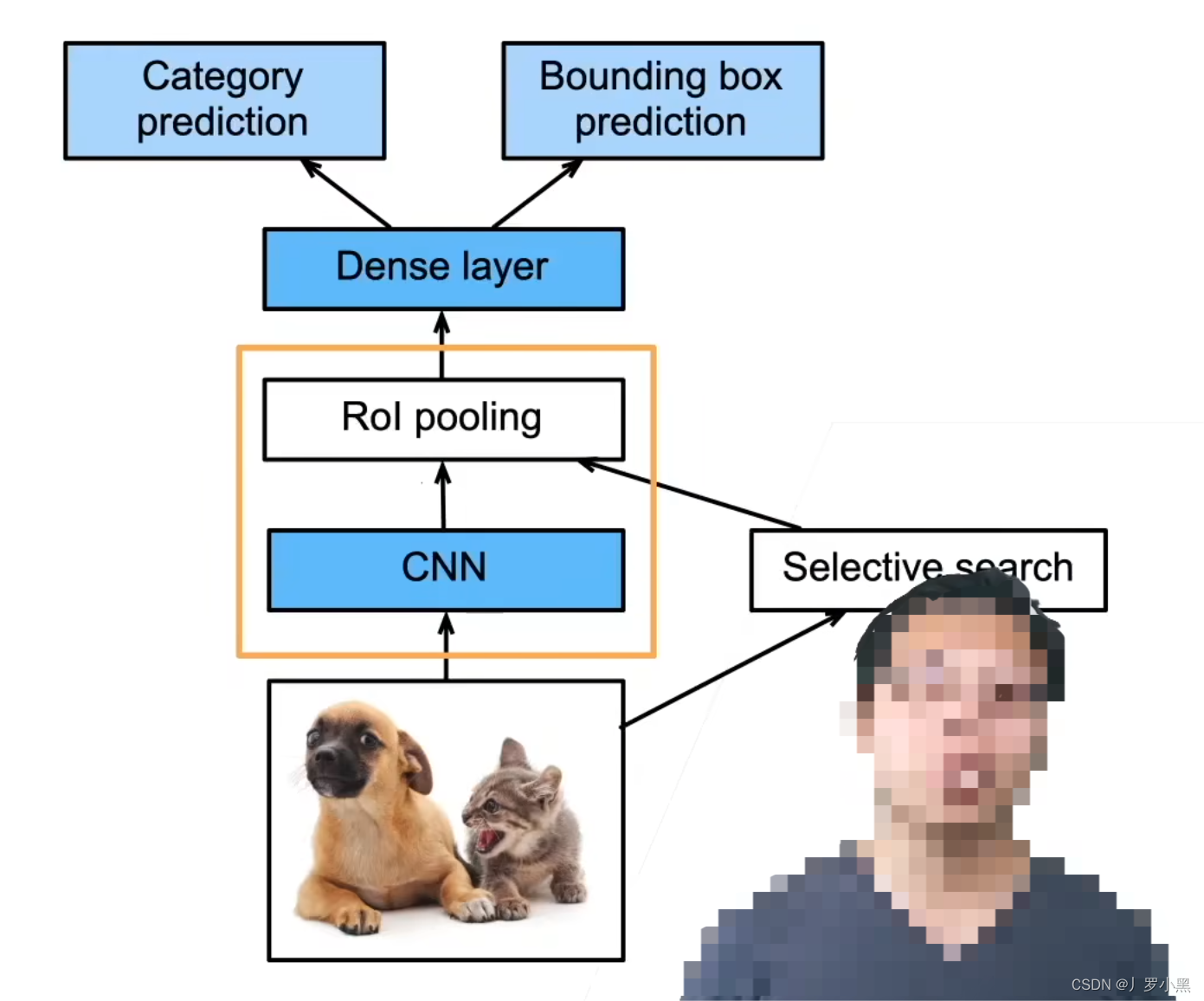
在R-CNN中,我们对于输入图像,先用启发式搜索算法(在神经网络出现之前,用于目标检测的搜索锚框的算法)进行锚框的生成,然后分别将这些锚框覆盖的部分输入图像送入不同的卷积神经网络,提取特征图,再分别将这些特征图送入各自的SVM(支持向量机)做物体分类任务,送入线性回归模型(不包含激活函数)做边界框的回归任务。
- 缺点:由于需要对每一张输入图片中的所有锚框进行特征提取,所以运行速度慢,预测速度慢,同时模型包含多个卷积神经网络,多个线性回归模型,多个SVM,设计复杂。速度在50秒左右检测一张图
- 缺点:由于需要对每一张输入图片中的所有锚框进行特征提取,所以运行速度慢,预测速度慢,同时模型包含多个卷积神经网络,多个线性回归模型,多个SVM,设计复杂。速度在50秒左右检测一张图
-
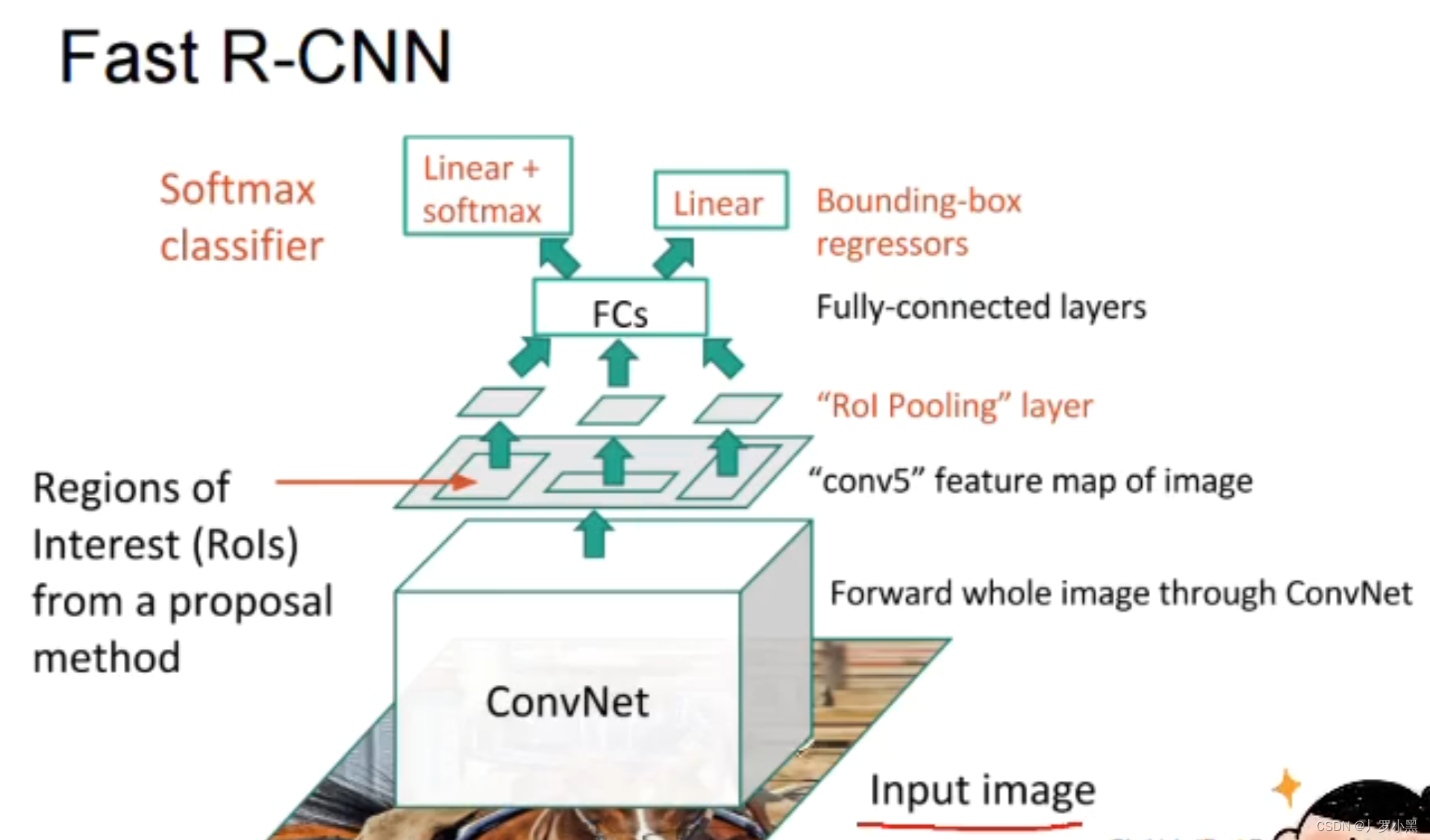
在Fast R-CNN中,我们先将整个输入图像送入一个卷积神经网络,提取特征图。之后用启发式搜索算法在原始图像中进行锚框的生成,并将原始图像的锚框按照比例映射到特征图的对应位置中,再用 RoI池化 将特征图中每个被锚框选中的区域,都生成固定尺寸大小的特征,最后送入全连接层做分类和回归任务。
-
Fast R-CNN只会对输入图像做一个整体的特征提取,而R-CNN由于是对每一个锚框都要进行特征提取,所以会有很多次的重复提取
- 优点:相比于R-CNN,速度会很快很多
- 缺点:由于锚框的生成还是基于启发式搜索算法,所以很难做到实时检测,大概速度在2-3秒左右检测一张图
-
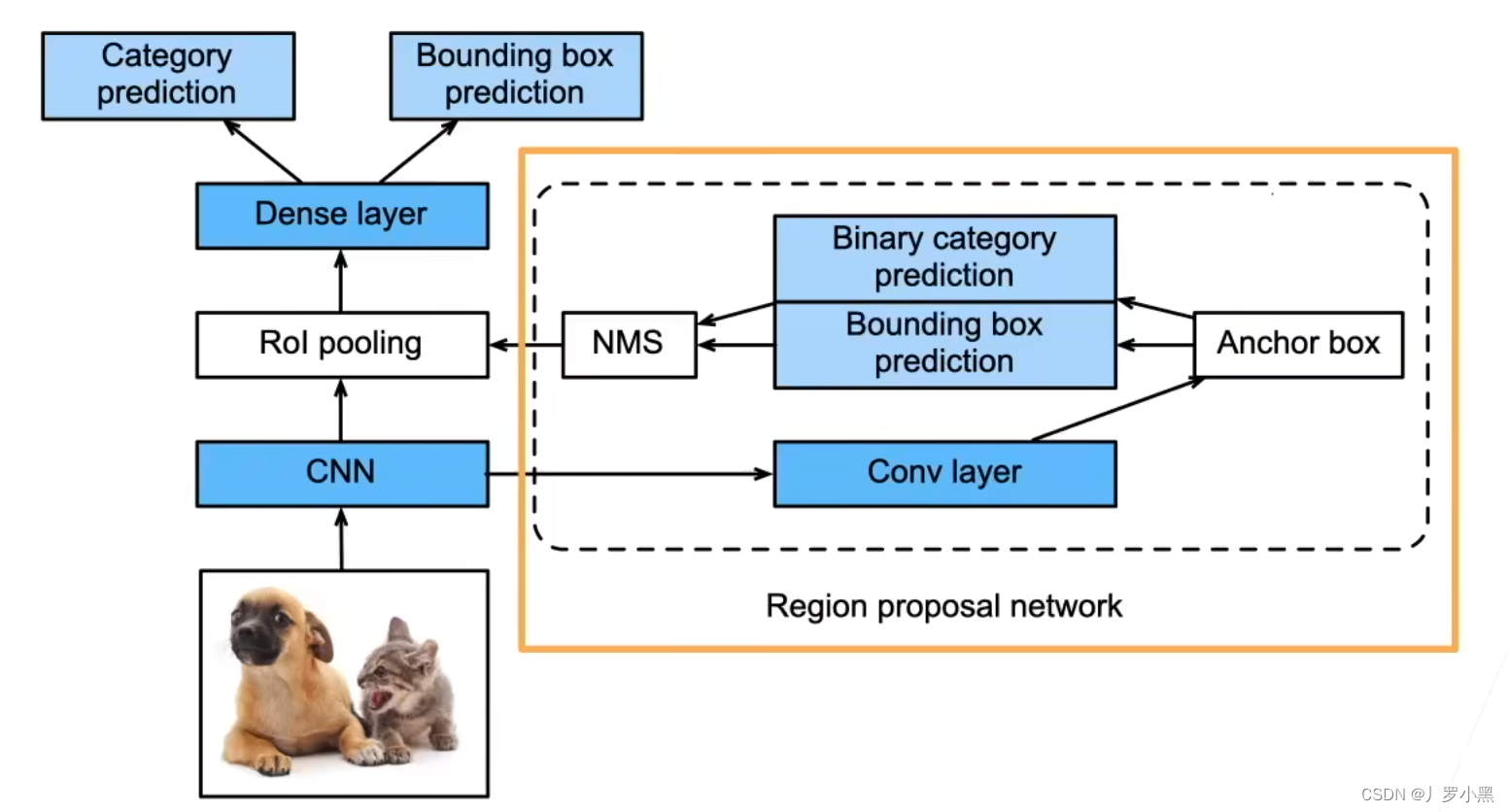
在Faster R-CNN中,我们也是先将整个输入图像送入一个卷积神经网络,提取特征图。之后用RPN(区域提议网络)做一个粗糙的目标检测(二分类,进行锚框的生成),并将RPN生成的锚框按照比例映射到特征图的对应位置中,再用 RoI池化 将特征图中每个被锚框选中的区域,都生成固定尺寸大小的特征,最后送入全连接层做分类和回归任务(更精细的目标检测)。
- 优点:由于使用了神经网络替换掉了启发式搜索算法,相比Fast R-CNN,速度又会快很多,大概在0.2秒左右一张图
- 缺点:速度仍然达不到实时检测的要求
-
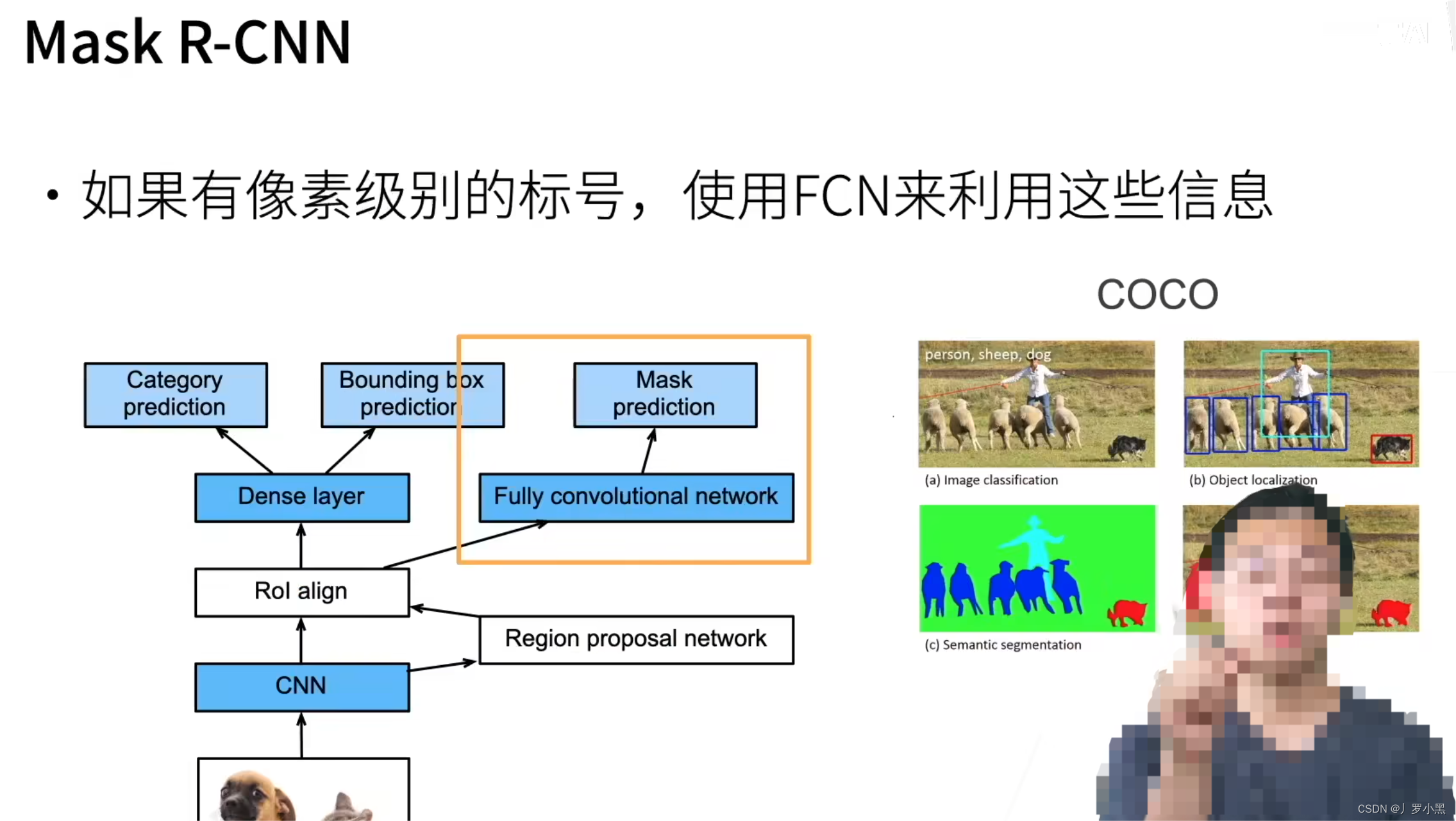
在Mask R-CNN中,主要添加了FCN来针对,具有像素级标号的数据集,从而可以做像素级的预测,即实例分割。使用RoI Align来解决,RoI池化对于候选框还原回原始图像有像素误差的问题。
-
综上:R-CNN是最早基于锚框和CNN的目标检测算法,Faster R-CNN和Mask R-CNN是在要求高精度场景下的常用算法
锚点、锚框、RoI池化、RoI Align
- 锚点、锚框作为额外补充的方法,主要用在two-stage的目标检测方法中,但是YOLOV2开始,也使用锚点、锚框来提升模型对不同尺寸和形状的物体的检测能力,但区别于two-stage的方法,YOLO仍然是在单个网络提过程中完成分类和边界框的回归。
- 在RPN(区域提议网络)中,锚点代表潜在的候选区域的中心,也是锚框的中心。
- 每个锚点可以生成多个锚框,而锚框则是作为候选框,用于覆盖图像中可能出现物体的不同位置和形状
- 在Fast R-CNN的RPN中,锚框就被用来预测物体的位置,而RPN会对每个锚框输出两个结果,一个是物体的存在概率,一个是锚框的调整参数(用来接近真实框)
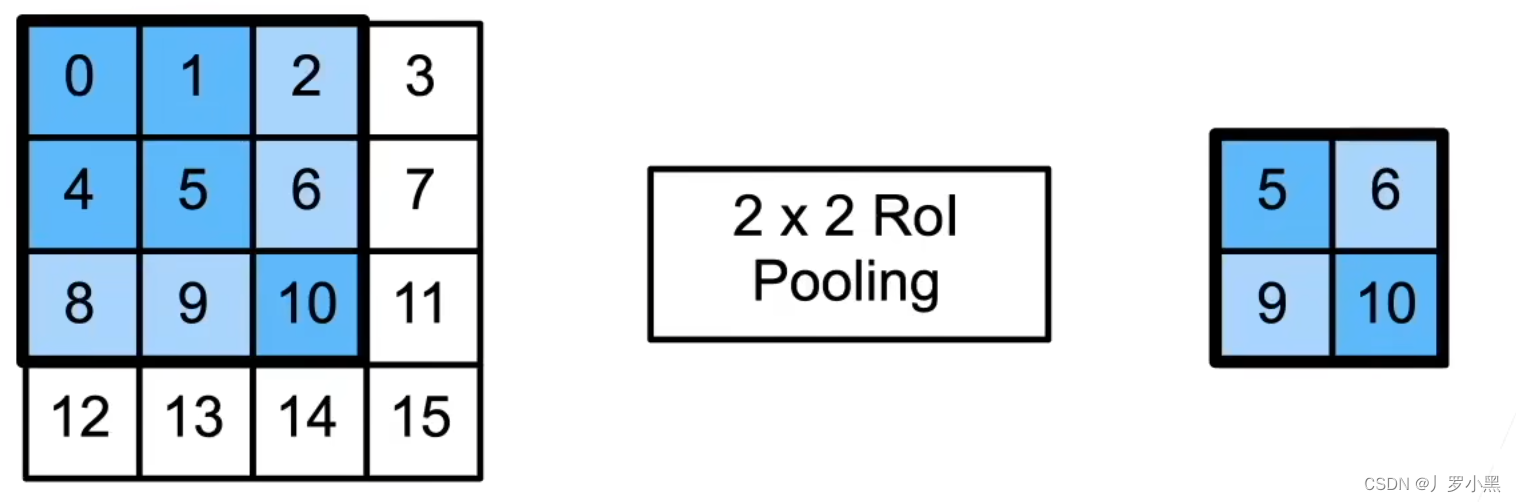
- RoI池化:使用量化操作,将特征图中的RoI区域,均匀分割成n*m块,并输出每块里的最大值
- 缺点:由于RoI池化采用量化操作(取整),所以如上图,对33的锚框变化为22的输出,就会将锚框分为[(2,2), (2,1), (1,2), (1,1)],不均匀等分,这样在最后还原回输入图像时,就会有误差存在。这就导致了在做像素级别的标号(实例分割)时,在边界区域会不准。
- 由于锚框的尺寸大小不统一,而我们最后使用的全连接层(做分类和回归)需要固定大小的输入,而使用RoI池化可以不管锚框多大,总是输出n*m个值,即可以固定输出尺寸的大小
- 注意:RoI的输入为特征图和锚框
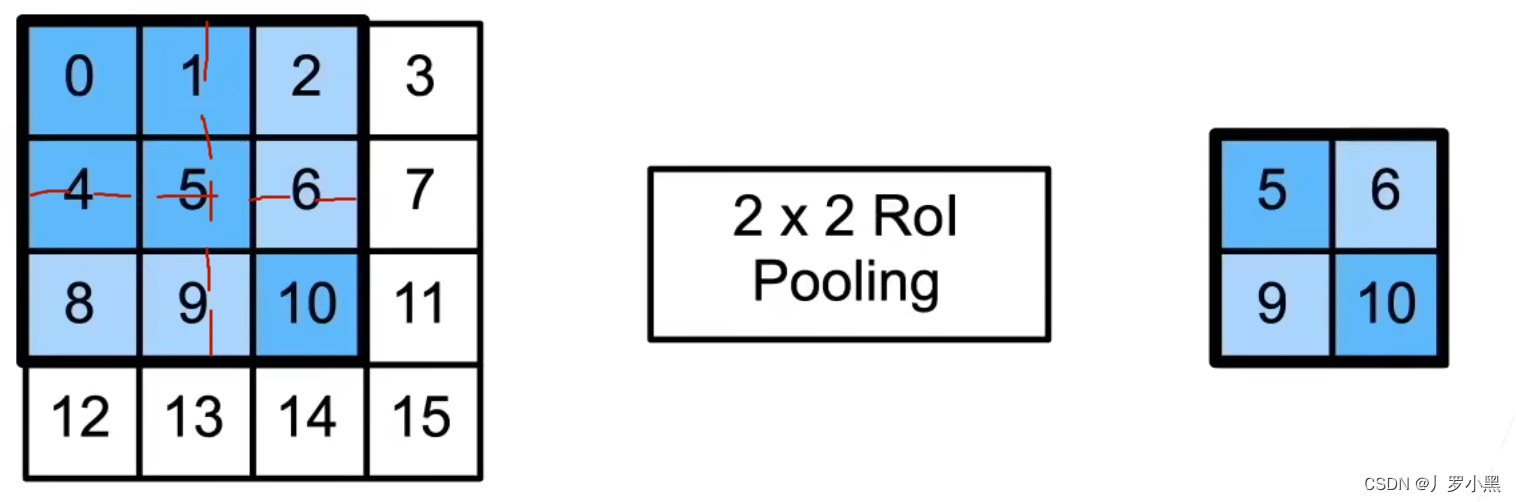
- RoI Align:使用双线性插值,将特征图中的RoI区域,均匀分割成n*m块,并输出每块里的最大值
- 由于使用了双线性插值,所以可以得到像素点之间(四个像素点内部任意采样点)的值,这样防止在最后还原回输入图像时的误差,主要是用在实例分割任务中。
- 这个采样点的值,可以看作是周围四个像素点的加权平均。
特征图、特征向量
- 特征图是CNN中的概念,它表示输入图像经一系列卷积层、池化层处理后的得到的中间输出结果,特征图通常是三维的数据结构,具体为(高度,宽度,通道数),所以特征图保留了输入图片的位置信息。特征图通常出现在网络的中间层,代表输入数据的中间级特征
- 特征向量是一个一维数组,它表示输入数据经过网络最后几层全连接层的输出,用于描述输入数据的高级抽象特征。特征向量通常出现在网络的最后几层,代表输入数据的高级特征。
原文地址:https://blog.csdn.net/u011453680/article/details/137692447
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!