HQL-计算不一样的 MUV
MUV-每月独立访客数(Monthly Unique Visitors),用来衡量在一个月内访问应用的不重复用户总数,这个指标有助于了解应用的用户基础规模和覆盖范围。
一、问题引入
在只考虑这个指标本身计算起来是很简单的,例如用户登录表为user_logins
select
count(distinct user_id) as muv_cnt
from user_logins
where login_dt >= '20240801'
and login_dt <= '20240825';
但是实际的业务需求以及考虑数据的批量回刷和通用性上述的 sql 是不可取的,例如期望通过一个 sql 计算过去若干个月的 MUV 且每天都需要输出一个指标。这个需求看起来是指标提出之始批量补历史数据的过程,下面是表结构设计以及造数据的过程
create table user_login
(
user_id string comment '用户 id',
login_dt string comment '登录时间 yyyy-MM-dd HH:mm:ss'
) comment '用户登陆日志表'
stored as textfile
row format delimited fields terminated by ',';
下面 python 用来生产测试数据
import random
from datetime import datetime, timedelta
################################################
# 配置区 start
################################################
start = '20240701' # 开始时间 yyyyMMdd
end = '20240826' # 结束时间 yyyyMMdd
dt_format = '%Y%m%d' # 时间格式,和上面保持一致
user_prefix = "user-" # 用户标识前缀
max_user = 20 # 生成的用户个数
max_login_num = 1000 # 生成的登录记录
file_name = "user_login.csv"
################################################
# 配置区 end
################################################
start_dt = datetime.strptime(start, dt_format)
end_dt = datetime.strptime(end, dt_format)
# 计算时间间隔
delta_days = (end_dt - start_dt).days
with open(file=file_name, mode="w", encoding="utf-8") as f:
for line in range(max_login_num):
# 随机生成一个用户
user_id = user_prefix + str(random.randint(1, max_user)).rjust(len(str(max_user)), '0')
# 随机生成范围内的登录时间
login_dt = start_dt + timedelta(days=random.randint(0, delta_days))
f.writelines(f"{user_id},{login_dt}\n")
导入数据到 hive 表中
load data local inpath '<your path>/user_login.csv' into table user_login;
二、可视化分析
历史数据每日的 MUV 计算逻辑可以概括如下
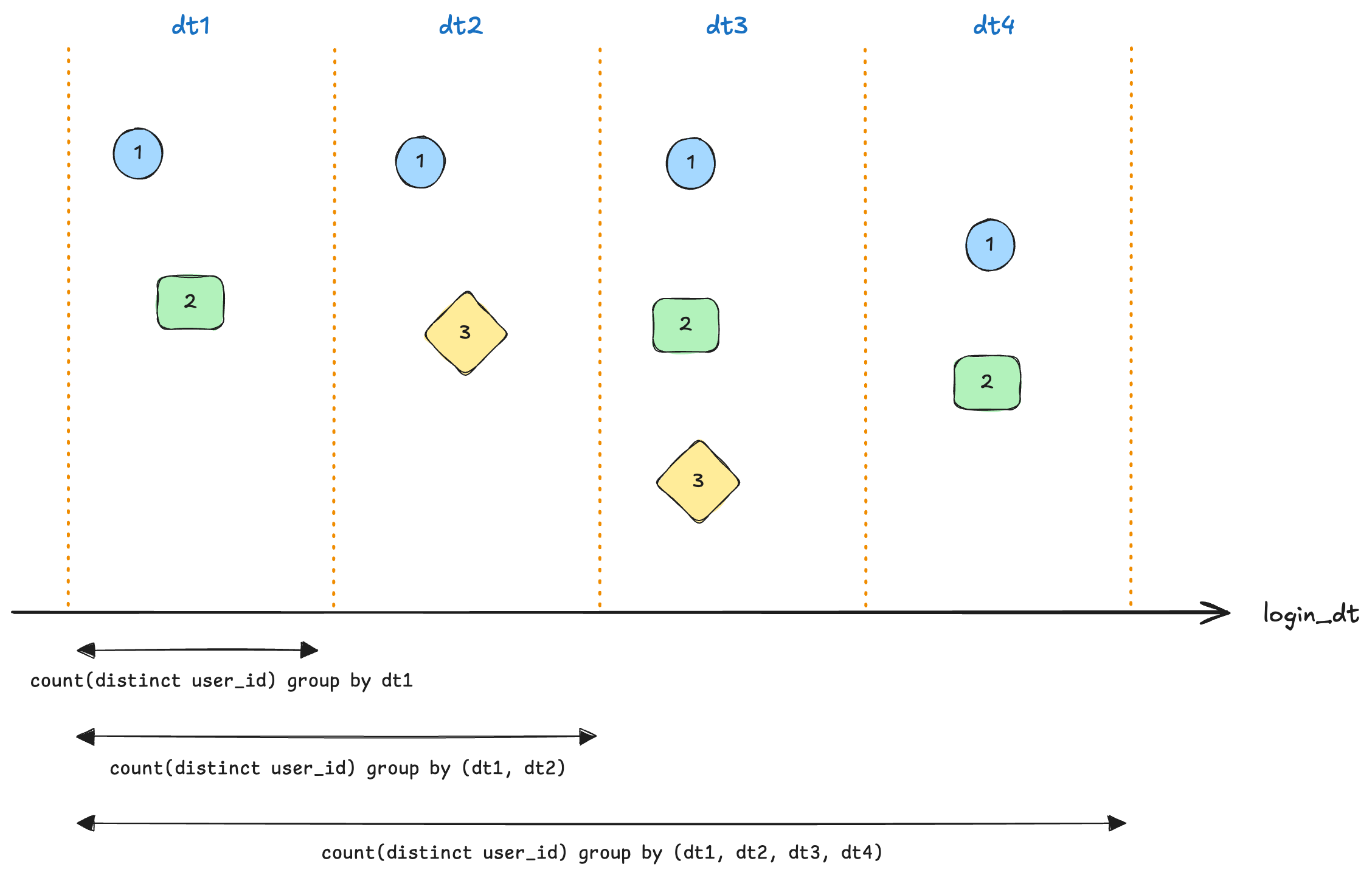
假设 dt1 ~ dt4 同属于一个月,那么:
dt1分区的计算逻辑: 获取 dt1 数据计算 count(distinct user_id)
dt2分区的计算逻辑: 获取 dt1 ~ dt2 数据计算 count(distinct user_id)
dt4分区的计算逻辑: 获取 dt1 ~ dt4 数据计算 count(distinct user_id)
不同分区的唯一区别在于数据桶范围不同,同时范围选取是连续的即从月初到该分区所在日期。用 sql 描述如下
window_function() # 计算逻辑
over(
partition month(dt) # 按月开窗
order by dt # 窗口内按时间升序
rows # 控制窗口计算的数据范围
between
unbounded preceding # 窗口起始行
and
current row# 当前行
)
- unbounded preceding: 无限前导,即为窗口内当前行前面的所有行
- current row: 当前行
三、SQL 实现
第二节的末尾告诉我们可以轻松控制窗口的范围,接下来的问题就是多窗口中的数据如何计算?count(distinct)? 显然是不合适的。因为开窗的结果不会聚合时间且聚合范围直到当前行,产生的现象就是最终的结果会在窗口的最后一条数据
t.user_idt.login_dtmuv_cnt
user-072024-07-01 00:00:001
user-172024-07-01 00:00:002
user-082024-07-01 00:00:003
user-082024-07-01 00:00:003
user-072024-07-01 00:00:003
user-192024-07-01 00:00:004
user-152024-07-01 00:00:005
user-152024-07-01 00:00:005
user-042024-07-01 00:00:006
user-092024-07-01 00:00:007
user-022024-07-01 00:00:008
user-202024-07-01 00:00:009
user-112024-07-01 00:00:0010
user-042024-07-01 00:00:0010
user-052024-07-01 00:00:0011
user-072024-07-02 00:00:0011
user-102024-07-02 00:00:0012
user-142024-07-02 00:00:0013
user-032024-07-02 00:00:0014
user-182024-07-02 00:00:0015
user-072024-07-02 00:00:0015
user-172024-07-02 00:00:0015
user-032024-07-02 00:00:0015
user-082024-07-02 00:00:0015
user-032024-07-02 00:00:0015
user-022024-07-02 00:00:0015
user-022024-07-02 00:00:0015
user-122024-07-02 00:00:0016
user-152024-07-02 00:00:0016
user-012024-07-02 00:00:0017
user-172024-07-02 00:00:0017
聪明的小伙伴就说了,简单后续按照 login_dt 分组求 muv_cnt 最大值!!!恭喜你可行但不合适原因如下:
- hive 低版本和 sparksql 不支持这类语法,博主的生产环境为 hive2.1 和 spark3.0 均不支持
- 最好先对数据做去重处理,原始登录数据量往往是很大的
当不支持此类语法时可以使用下面迂回的方式实现
step-1: 去重,保留每个用户在一个月内第一次登录的记录
select user_id,
date_format(login_dt, 'yyyy-MM') inc_month,
min(date_format(login_dt, 'yyyy-MM-dd')) as first_login_dt
from user_login
group by user_id, date_format(login_dt, 'yyyy-MM');
step-2: 计算每日登录的用户数
select inc_month, first_login_dt, count(1) as cnt
from (select user_id,
date_format(login_dt, 'yyyy-MM') inc_month,
min(date_format(login_dt, 'yyyy-MM-dd')) as first_login_dt
from user_login
group by user_id, date_format(login_dt, 'yyyy-MM')) t
group by inc_month, first_login_dt;
结果如下
+------------+-----------------+------+
| inc_month | first_login_dt | cnt |
+------------+-----------------+------+
| 2024-07 | 2024-07-05 | 1 |
| 2024-08 | 2024-08-04 | 1 |
| 2024-07 | 2024-07-02 | 6 |
| 2024-08 | 2024-08-01 | 12 |
| 2024-08 | 2024-08-02 | 5 |
| 2024-08 | 2024-08-03 | 2 |
| 2024-07 | 2024-07-01 | 11 |
| 2024-07 | 2024-07-03 | 1 |
| 2024-07 | 2024-07-06 | 1 |
+------------+-----------------+------+
step-3: 补齐日期
回看 MUV 的逻辑 2024-07-01 本月第一次登录用户数数为 11,2024-07-02 本月第一次登录用户数为 6,2024-07-03 本月第一次登录用户数为 1,这三天的 MUV 为 11、17(11+6)、18(11+6+1)。这个逻辑可以使用第二节的方式rows between unbounded preceding and current row实现,计算逻辑为sum
select inc_month,
first_login_dt,
sum(cnt)
over (partition by inc_month order by first_login_dt rows between unbounded preceding and current row ) as cnt
from (select inc_month, first_login_dt, count(1) as cnt
from (select user_id,
date_format(login_dt, 'yyyy-MM') inc_month,
min(date_format(login_dt, 'yyyy-MM-dd')) as first_login_dt
from user_login
group by user_id, date_format(login_dt, 'yyyy-MM')) t
group by inc_month, first_login_dt);
结果如下:
+------------+-----------------+------+
| inc_month | first_login_dt | cnt |
+------------+-----------------+------+
| 2024-08 | 2024-08-01 | 12 |
| 2024-08 | 2024-08-02 | 17 |
| 2024-08 | 2024-08-03 | 19 |
| 2024-08 | 2024-08-04 | 20 |
| 2024-07 | 2024-07-01 | 11 |
| 2024-07 | 2024-07-02 | 17 |
| 2024-07 | 2024-07-03 | 18 |
| 2024-07 | 2024-07-05 | 19 |
| 2024-07 | 2024-07-06 | 20 |
+------------+-----------------+------+
因为 2024-07-04 没有本月新用户登录导致结果没有这一天的数据,但是从 MUV 定义来看 2024-07-04 应该是 18(18+0)。所以需要补齐日期让时间连续,这就需要使用时间维表作为主表,关于时间维表可以查看《数仓基建-构建 hive 时间维表》,对于缺失的日期填补 0(这一点很重要)
select t1.inc_month, t1.dt, nvl(cnt, 0) as cnt
from (select dt_format1 as dt, concat(dt_year, '-', dt_month) as inc_month
from dim_dateformat
where dt between '20240701' and '20240825') t1
left join (select inc_month,
first_login_dt,
sum(cnt)
over (partition by inc_month order by first_login_dt rows between unbounded preceding and current row ) as cnt
from (select inc_month, first_login_dt, count(1) as cnt
from (select user_id,
date_format(login_dt, 'yyyy-MM') inc_month,
min(date_format(login_dt, 'yyyy-MM-dd')) as first_login_dt
from user_login
group by user_id, date_format(login_dt, 'yyyy-MM')) t
group by inc_month, first_login_dt) t) t2 on t1.dt = t2.first_login_dt;
step-4: 计算 MUV
每日的 MUV 则再进行一次sum(cnt) over (partition by inc_month order by first_login_dt rows between unbounded preceding and current row )
select inc_month,
dt,
sum(cnt)
over (partition by inc_month order by dt rows between unbounded preceding and current row ) as cnt
from (select t1.inc_month, t1.dt, nvl(cnt, 0) as cnt
from (select dt_format1 as dt, concat(dt_year, '-', dt_month) as inc_month
from dim_dateformat
where dt between '20240701' and '20240825') t1
left join (select inc_month,
first_login_dt,
sum(cnt)
over (partition by inc_month order by first_login_dt rows between unbounded preceding and current row ) as cnt
from (select inc_month, first_login_dt, count(1) as cnt
from (select user_id,
date_format(login_dt, 'yyyy-MM') inc_month,
min(date_format(login_dt, 'yyyy-MM-dd')) as first_login_dt
from user_login
group by user_id, date_format(login_dt, 'yyyy-MM')) t
group by inc_month, first_login_dt) t) t2 on t1.dt = t2.first_login_dt);
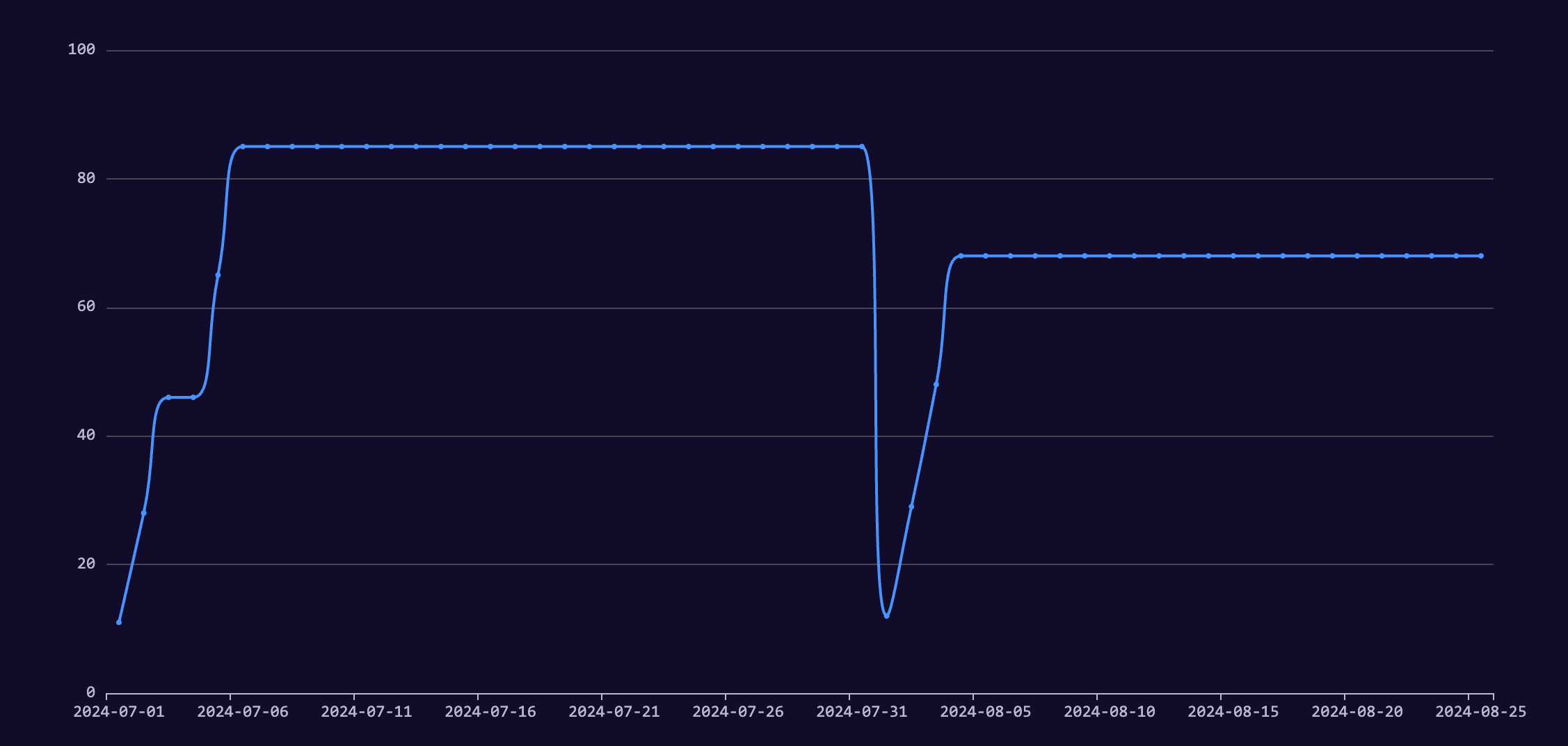
稍微可视化一下
四、浅聊一下
在编写博客的时候博主突然有了一个很巧妙的思路,完全按照第二节的图示思路
按 dt 创建一个数据桶,将当天登录的用户放入桶中,因为是 set 天然具备去重能力
select
login_dt,
collect_set(user_id) user_sets # set 天然具备去重能力
from user_login
group by login_dt
得到每日的登录用户集合
2024-07-01 00:00:00["user-07","user-08","user-15","user-05","user-11","user-04","user-02","user-17","user-09","user-20","user-19"]
2024-07-02 00:00:00["user-17","user-08","user-03","user-15","user-12","user-14","user-07","user-02","user-01","user-18","user-10"]
2024-07-03 00:00:00["user-10","user-20","user-05","user-03","user-07","user-11","user-04","user-18","user-17","user-08","user-19","user-15","user-09","user-16","user-14","user-01"]
2024-07-04 00:00:00["user-03","user-08","user-01","user-05","user-19","user-17","user-15","user-18","user-04","user-10","user-20","user-09","user-02"]
2024-07-05 00:00:00["user-17","user-07","user-03","user-16","user-02","user-13","user-04","user-05","user-14","user-11","user-12","user-18","user-10","user-20","user-09","user-19"]
2024-07-06 00:00:00["user-04","user-19","user-07","user-18","user-15","user-01","user-17","user-09","user-16","user-08","user-20","user-06"]
2024-07-07 00:00:00["user-18","user-01","user-03","user-12","user-15","user-07","user-17","user-19","user-05","user-10","user-16"]
2024-07-08 00:00:00["user-20","user-14","user-10","user-11","user-16","user-01","user-03","user-07","user-17","user-08","user-19","user-15"]
2024-07-09 00:00:00["user-13","user-05","user-15","user-02","user-06","user-03","user-04","user-09","user-08","user-10"]
2024-07-10 00:00:00["user-04","user-01","user-15","user-14","user-06","user-10","user-08","user-17"]
...
collect_set也是一个开窗函数同时可以应用 over 以及 rows 范围,返回的数据类型是 array<array<?>>,如果可以将多个数组进行 flatmap 并去重得到 array<?>,那么每日的 MUV 就是对应日的数组长度。遗憾的是 hive/spark sql 并没有提供这类函数…
原文地址:https://blog.csdn.net/qq_41858402/article/details/142329344
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!