【机器学习】机器学习实验方法与原则(详解)

• 训练集、验证集与测试集
训练集与测试集
•
训练集(
作业
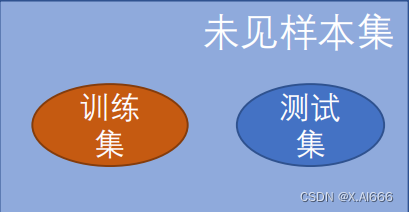
):模型可见样本标签,用于训练模型,样本数有限
• 在训练集上表现好的模型,在其他未见样本上一定表现好吗?小心
过拟合
!
•
未见样本(
所有没做过的题
)往往有指数级别或无穷多个
未见
•
测试集(
考试
):用于评估模型在可能出现的未见样本上的表现
• 尽可能与训练集
互斥
,即测试样本尽量
不在训练集中出现
,为什么?
这是因为测试集的目的是评估模型的泛化能力,即模型在未见过的数据上的表现。如果测试 集中包含了训练集中的样本,那么模型在测试集上的表现可能会被过度乐观地评估,因为模 型已经在训练过程中见过这些样本,从而可能记住了这些数据的特征,而不是真正地学习到 了泛化规律。
• 估计
模型在整个未见样本上的表现
训练集与测试集的划分方式
•
随机
划分
• 按比例,例如
9:1
、
8:2
• 固定数目,例如测试集从全部样本中采样
1w
个,其余为训练集
•
留一
化分(
leave-one-out
)
• 一个样本作测试,其余样本训练:常用于
K
近邻等算法的性能评估
•
特殊
划分
• 按时间划分
,例如
1-5
月气象数据作训练,
6
月气象数据作测试
• 推荐系统中,常把
每个用户交互序列的最后一个样本
作测试,其余作训练
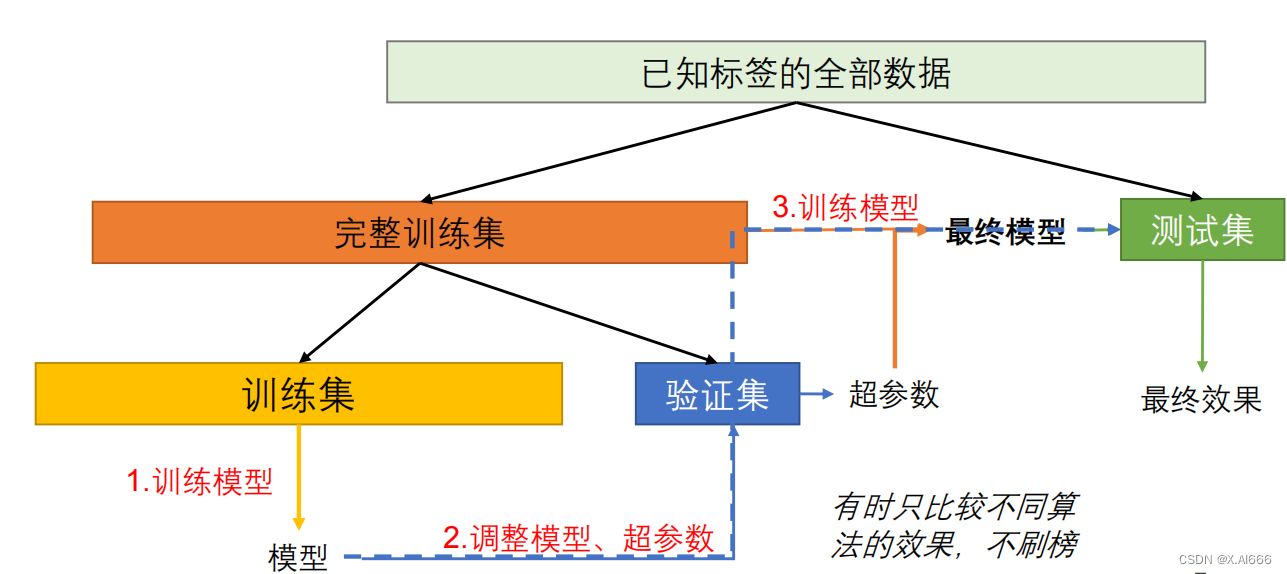
验证集
•
从
训练集
中额外分出的集合,一般用于
超参数
的调整
• 训练轮次、正则化权重、学习率等等
• 为什么不在训练集上调整超参数?过拟合训练集
• 为什么不在测试集上调整超参数?过拟合测试集
• 针对当前测试集调出的参数可能只在当前测试集上较好
• 使得测试集结果偏高,不能反映实际在所有未见样本上的效果
• 类比:针对某场考试的知识点分布作重点复习,不能准确反映学生对所有知识的掌握程度。
• 举例:机器学习竞赛中,针对公开部分的测试数据过度调参,不一定在隐藏的全部测试数 据上表现好。
• 随机重复实验

•
测一次就足够了吗?
• 极端情况:二分类中分类器
随机
输出,
恰好
测试集都对了(效果最好?)
•
数据
随机性
• 由数据集划分带来的评价指标波动
•
模型
随机性
• 由模型或学习算法本身带来的评价指标波动
• 例如:神经网络初始化、训练批次生成
•
数据随机性
• (数据足够多时)增多测试样本
• (数据量有限时)重复多次划分数据集
•
模型随机性
• 更改随机种子重复训练、测试
• 注意
:保持每次得到的评价指标
独立同分布
(iid)
• 报告结果:评价指标的
均值
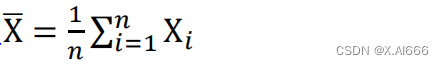
• 样本标准差(个体离散程度,反映了个体对样本均值的代表性)
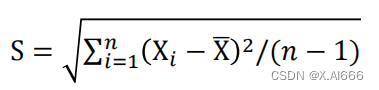
• 标准误差(样本均值的离散程度,反映了样本均值对总体均值的代表性)
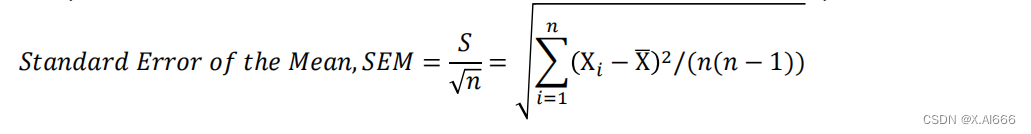
• K折交叉验证
•
随机把数据集分成
K
个相等大小的不相交子集
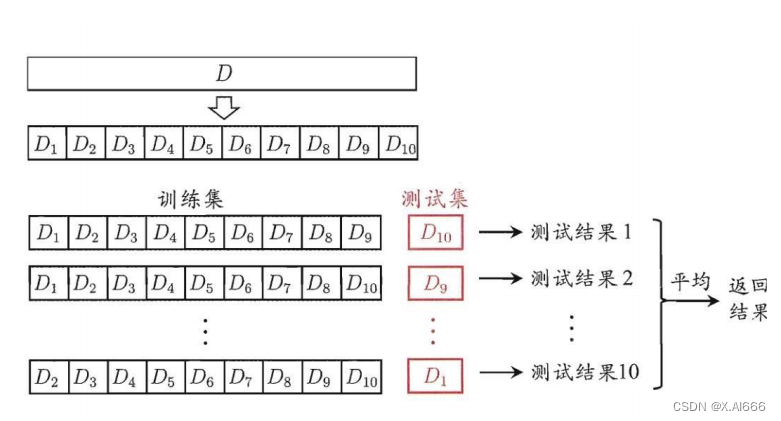
•
优点:
数据利用率高
,适用于数据较少时
•
缺点:训练集互相有交集,
每一轮之间并不满足独立同分布
•
增大
K
,一般情况下:
• 所估计的模型效果
偏差(
bias
)下降
• 所估计的模型效果
方差(
variance
)上升
• 计算代价上升,更多轮次、训练集更大
• K
一般取
5
、
10
原文地址:https://blog.csdn.net/chen695969/article/details/136796982
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!