Redis 特性及应用场景
Redis 是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存,在分布式系统中能够大展拳脚
一.Redis 特性
打开 Redis 的官网我们可以看到 如下:

逐个分析其特性:
- 在内存中存储数据,key 都是 string,value 则可以是上述的这些数据结构;
- MySQL 主要是通过 "表” 的方式来存储组织数据的 “关系型数据库”;Redis主要是通过"键值对”的方式来存储组织数据的 “非关系型数据库”;

针对 Redis 的操作,可以直接通过简单的交互式命令进行操作,也可以通过一些脚本的方式,批量执行一些操作(可以带有一些逻辑)

可以在 Redis 原有的功能基础上再进行扩展,Redis 提供了一组 API。通过上述这几个语言编写 Redis 扩展(本质上就是一个动态链接库)
自己去扩展Redis 的功能,比如,Redis 自身已经提供了很多的数据结构和命令,通过扩展,让 Redis 支持更多的数据结构以及支持更多的命令

持久化:Redis把数据存储在内存上的。
内存的数据是"易失"的,如:进程退出/系统重启
Redis 会把数据存储在硬盘上,内存为主,硬盘为辅。(硬盘相当于对内存的数据备份了一下)如果 Redis 重启了,就会在重启时加载硬盘中的备份数据使 Redis 的内存恢复到重启前的状态。

Redis 作为一个分布式系统中的中间件,能够支持集群是很关键的
Horizontal 这个水平扩展,类似于"分库分表"
一个Redis 能存储的数据是有限的(内存空间有限),引入多个主机,部署多个 Redis 节点,每个 Redis 存储数据的一部分

高可用 => 冗余/备份
Redis 自身也是支持 “主从” 结构的,从节点就相当于主节点的备份了

还有官网没有提及的,但是实际存在的特点就是 快:
为啥快呢?
- Redis 数据在内存中,就比访问硬盘的数据库,要快很多
- Redis 核心功能都是比较简单的逻辑,核心功能都是比较简单的操作内存的数据结构
- 从网络角度上,Redis 使用了IO多路复用的方式(epoll)(IO多路复用:使用一个线程,管理很多个socket)
- Redis 使用的是单线程模型(虽然更高版本的 Redis 引入了多线程),这样的单线程模型,减少了不必要的线程之间的竞争开销(多线程可以提高效率,但是多线程提高效率的前提是,CPU密集型的任务,使用多个线程可以充分的利用 CPU 多核资源。但是Redis 的核心任务,主要就是操作内存的数据结构,不会吃很多 CPU)
- Redis 是使用C语言开发的,所以就快(看个人看法,MySQL 也是 C 语言开发的,也不见得快,但是 C 语言确实比 Python 那些语言要快)
二.Redis 应用场景

在官方文档上有如上三个最主要的用途,但是实际上还有许多应用场景,此处就举例上述三个应用场景:
- 把 redis 当做了数据库
大多数情况下,考虑到数据存储,优先考虑的是 “大”;但是仍然有一些场景,考虑的是 “快”:例如搜索引擎 -> 广告搜索(商业搜索),搜索引擎对性能要求很高,搜索系统中没有用到 MySQL 这样的数据库,把所有需要检索的数据都存储在内存中,就使用的是类似于Redis这样的内存数据库来完成的。当然,使用这样的内存数据库,存储大量的数据,需要不少的硬件资源的
此处 Redis 存的是全量数据,这里的数据是不能随便丢的

使用 MySQL 存数据,大,慢。根据二八原则,把热点数据拎出来,存储在 redis 中的,此处 Redis 存的是部分数据,全量数据都是以 mysql 为主的,哪怕 Redis 的数据没了,还可以从 mysql 这边再加载回来。
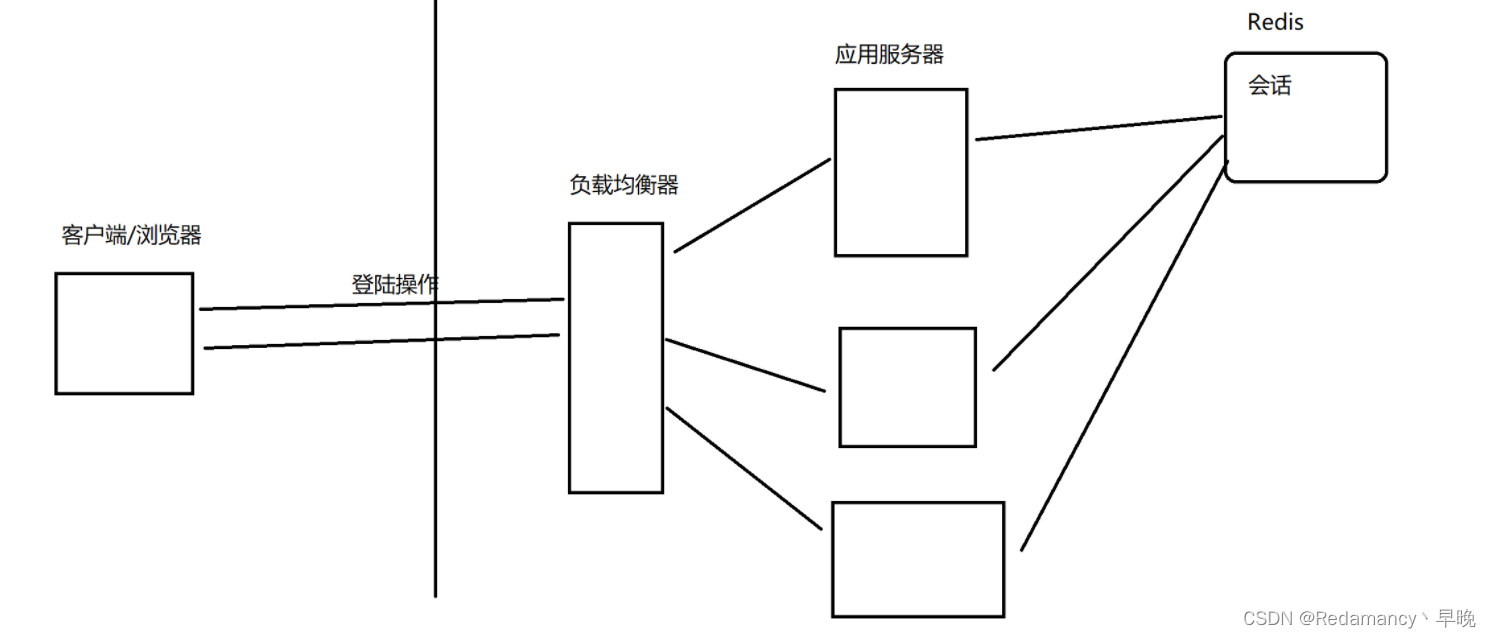
关于 session 持久化:我们可以知道 cookie(只是在浏览器这边存储了一个用户的身份标识 sessionld ) => 实现用户身份信息的保存,需要 session 配合的,服务器这里真正的存储了用户数据,之前 session 是存储在应用服务器上的。
例如上面:我们的客户端发送了一个登录操作,经过负载均衡分配给我们的应用服务器,为了保证信息的可靠性,那么如何确保客户端的登录操作每次都会被负载均衡器分配到同一个应用服务器上呢?有两种操作:
- 想办法让负载均衡器,把同一个用户的请求始终打到同一个机器上 (不能轮询了,而是要通过 userld 之类的方式来分配机器)
- 把会话数据单独拎出来,放到一组独立的机器上存储(Redis) (应用程序重启了,会话不丢失)

- 消息队列(服务器)
基于这个可以实现一个网络版本的生产者消费者模型。对于分布式系统来说,服务器和服务器之间,有时候也需要使用到生产者消费者模型的。
优势:
- 解耦合
- 削峰填谷
业界也有很多知名的消息队列:RabbitMQ,Kafka,RocketMQ …
Redis 也是提供了消息队列的功能的
如果当前场景中,对于消息队列的功能依赖的不是很多,并且又不想引入额外的依赖了,Redis 可以作为一个选择

原文地址:https://blog.csdn.net/m0_67660672/article/details/136992955
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!