JAVA学习笔记
day01
代码的结构
- 主类名,包含main方法的类名
类{
方法{
语句;
}
}
- 编译
javac 要编辑的文件名.java(包含扩展名),生成字节码.class文件- cmd需要在HelloWorld.jav文件夹目录下
javac ./HelloWorld.java
public class HelloWorld {
public static void main(String[] args){
System.out.println("helloWorld");
}
}
//String[] args 不要漏掉了
- 运行
java 编辑后的文件
java 主类名 (也就是 java HelloWorld)
java HelloWorld 正确的
java HelloWorld.class 错误的
java ./HelloWorld.class 错误的
java ./HelloWorld 错误的
- 更改编码格式
javac -encoding UTF-8 HelloWorld.java
否者容易出现编码 GBK 的不可映射字符

大小写问题
1.java的代码是严格区分大小写的
2.java的文件名是否区分大小写
window操作系统来说
2.1 文件名大小写都可以(即javac 命名后面,文件名大小写都可以)
2.2 比如有一个文件名Problem2.java 可以javac problem2.java 也可以javac Problem2.java
3.编译后的xxx.class文件的文件名是否区分大小写? 区分
因为xxx.class文件的文件名代表的是类目
比如,编译后生成字节码文件 Problem2.class,并且主类名称也为Problem2
运行的命令,就必须是 java Problem2
建议都区分
-
特别注意的是,class的类名需要和文件夹名称一致,否则会报下面的错误

java注释
- 单行注释
// - 多行注释
/* 注释内容 */ - 文档注释
/** 内容 */
类型
-
基本数据类型
- 整数:
byte , short ,int ,long - 小数:
float , double - 单字符:
char - 布尔型:
boolean
- 整数:
-
引用数据类型
- 类:
class - 接口:
interface - 枚举:
enum - 注解:
@interface - 数组:
[]
- 类:
-
java的常量是用
final来表示的,常量名通常所有字母都大写
final int FULL_MARK = 100;
基本数据类型的转换之自动转换
- 自动转换之隐式转换
- 当把存储范围小的值(常量值,变量值,表达式的结果值)赋值给存储范围大的变量的时候,就会发生自动类型转换
- 存储范围从小到大排序如下
byte -> short -> int -> long -> float -> doublechart与short同级boolean不参与
double d = 1;
System.out.println(d);//输出1.0
- 当多种数据类型的数据混合运算时,会自动提升为他们之中最大的
double d = 1;
System.out.println(d);//输出1.0
int a = 1;
byte b = 12;
char c = 'a';
//int ff = a + b + c + d;//错误: 不兼容的类型: 从double转换到int可能会有损失
double dd = a + b + c + d;//正确的
- 当
byte与byte,short与short,char与char进行运算或者他们三个混合运算,会自动提升为int类型- 顺带一提:字节(byte)数据类型是8位有符号Java原始整数数据类型。其范围是
-128至127(-27至27-1)。
- 顺带一提:字节(byte)数据类型是8位有符号Java原始整数数据类型。其范围是
byte a = 1;
byte b = 2;
int c = a + b;//正确
- 当小类型和大类型运算的时候,小类型会优先转化为大类型后参与运算(除开字符串)
- 可能有误,这一条个人总结!
char和double之间相加,char型会转换为double类型
char one = 'a'; //97
double two = 12.15;
System.out.println(one + two);//输出109.15
基本数据类型的转换之强制转换
- 当把存储范围大的值(常量值,变量值,表达式的结果值)赋值给存储范围小的变量的时候,就需要强制类型转换
- 格式
(存储范围小的值)值
- 格式
byte a = 1;
byte b = 2;
byte c = (byte)(a + b);//本来是int的,强制转换为byte
- 注意的是,可能会导致溢出或损失精度
String类型与基本数据类型转换的问题
- 任何数据与String进行
+拼接,结果都是String - 其他数据类型进行
+是求和
char c1 = 'a';
char c2 = 'b';
//求和,所以输出int类型
System.out.println(c1 + c2);//197 (类型为整形)
//
System.out.println("C1 + C2 = " + c1 + c2);//C1 + C2 = ab (类型为字符串)
System.out.println(c1 + c2 + "");// 197 (类型为字符串)
System.out.println(c1 + "" + c2);// ab (类型为字符串)
特别注意
float f = 1.2;//错误的
要么
double f = 1.2;
或者
float f = 1.2F;
long j = 120;//自动类型提升
double d = 34;//自动类型提升
赋值运算符
=左边必须是变量,不能是常量值,不能是表达式
int a = 1;
int b = 1;
b = a + b;//正确
b + 1 = a;//错误
-
=右边的值(常量,变量,表达式)的类型必须要<=左边变量的类型- 存储范围从小到大排序如下
byte -> short -> int -> long -> float -> doublechart与short同级
-
=永远是最后算的 -
扩展的赋值运算符,当最后的赋值结果类型大于左边的变量类型时,会发生自动类型转换
byte b1 = 10;
byte b2 = 2;
b1 = b1 + b2;//错误的
b1 += b2;//相对于b1 = (int)(b1 + b2);
System.out.println(b1);
day02
-
编码,同一个模块下,所有文件保持同一个编码,否则文件可以不同编码,使用System.out.println输出中文会出现乱码问题
-
自动导包
Alt + Enter

- 表达式有返回值,语句没有返回值~
几种输出语句
System.out.println(输出内容);//输出内容之后,紧接着换行,如果()中什么都没写,表示空号
System.out.println();//输出空行
System.out.print(内容);//如果()中什么都没写,编译报错
//()中也只能写一个值,如果有多个值,必须用"+"拼接起来
格式化输出
- 使用
System.out.printf(内容,变量列表) - 内容需要使用占位符,占位符如下
%d整形%f小数%.nf小数点留n位(四舍五入)%c单个字符%s字符串%bboolean
int a = 10;
double b = 12.5885;
char c = 'd';
boolean f = true;
System.out.printf("a=%d,b=%f,b=%.2f,c=%c,f=%b",a,b,b,c,f);
//输出结果如下
a=10,b=12.588500,b=12.59,c=d,f=true
输入
next
- 遇到空白或者其他空白字符的时候,就会认为输入结束,后面的数据就不会接收了
- 比如输入
张 空格 三,那么只会接收张
//全名称使用法
java.util.Scanner input = new java.util.Scanner(System.in);
//简写用法
import java.util.Scanner;
Scanner input = new Scanner(System.in);
System.out.print("请输入一个整数");
int num = input.nextInt();//接收键盘输入
System.out.println("num = " + num);
//最后最好关闭
input.close()
-
注意,如果要接收数据的变量类型和用户输入数据的数据类型不符合,会报错
-
input.nextDouble()输入小数 -
input.nextBoolean()输入布尔值 -
input.nextLong();输入大整形 -
input.next();输入字符串 -
input.next().chartAt(0):输入单个字符(从多个字符串截取第一个字符) -
注意,最后最好关闭
input.close() -
示例
import java.util.Scanner;
public class input {
public static void main(String[] args) {
//用户输入
Scanner input = new Scanner(System.in);
//输入字符串
System.out.printf("请输入字符串:");
String a = input.next();
System.out.println("a = " + a);
//输出小数
System.out.printf("请输入小数:");
double b = input.nextDouble();
System.out.println("b = " + b);
//输入布尔值
System.out.printf("请输布尔值:");
boolean c = input.nextBoolean();
System.out.println("c = " + c);
//输入大整形
System.out.printf("请输入大整形:");
long d = input.nextLong();
System.out.println("d = " + d);
//输入单个字符
System.out.printf("请输入单个字符:");
char e = input.next().charAt(0);
System.out.println("e = " + e);
input.close();
}
}
nextLine
- 在读取用户输入的数据时,遇到回车换行符合才会认为输入结束
需要注意
- 当二者结合使用的时候,需要注意下面这种情况
import java.util.Scanner;
public class input_attention {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.printf("请输入姓名");
String name = input.next();//next是以空格为结束
System.out.println("name = " + name);
String other = input.nextLine();//nextLine是以回车结束
System.out.printf("请输入其他信息");
System.out.println("other = " + other);
}
}
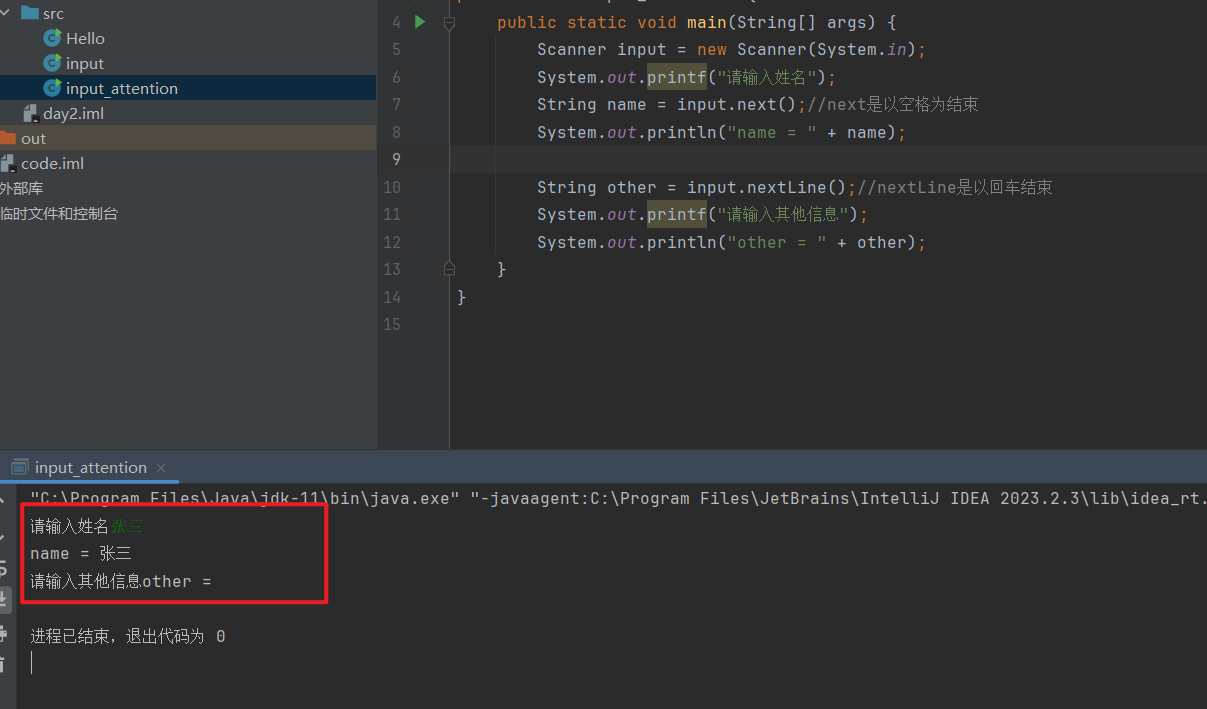
-
其实就是输入流当中的信息被
next和nextLine进行补货,然后特定符号结束捕获,就会发生这种情况 -
建议
- 如果字符串中不需要包含空格,请使用
next()更简单 - 如果字符串中需要包含空格,那么
nextLine()前面有其他的非nextLine()的输入语句,请在前面加一句xx.nextLine()解决(也就是提前捕获下然后不接收)
- 如果字符串中不需要包含空格,请使用
day03
数组
- 命名如下
//推荐的
元素的数据类型[] 数组的名称
//比如
char[] temp;
//不推荐
元素的数据类型 数组的名称[];
int temp[]
初始化
一维数组静态初始化
- 静态初始化一般适用于一组数据的已知的
//支持的格式如下
//如果声明和静态初始化是一起的,支持写法如下
元素数据类型[] 变量名 = { 数据A,数据B,数据C };
元素数据类型[] 变量名 = new 元素数据类型[]{ 数据A,数据B,数据C };
//如果声明和静态初始化是分开的
元素数据类型[] 变量名;
变量名 = new 元素数据类型[]{ 数据A,数据B,数据C }
//如果声明和静态初始化是一起的,支持写法如下
int[] achievement1 = {1,2,3};
int[] achievement2 = new int[]{1,2,3,};
//如果声明和静态初始化是分开的
int [] achievement3;
achievement3 = new int[]{1,2,3};
一维数组动态初始化
- 适用于一组数据是未知的,或需要通过计算得到,或者通过键盘输入得到
元素数据类型[] 变量名 = new 元素数据类型[长度]
//动态初始化
int[] achievement4 = new int[10];
二维数组动态初始化
-
静态初始化不多说,参考一维数组初始化
-
动态初始化
- 规则的矩阵,每一行的列数是相同的
- 不规则的二维表(每一行的列数不相同,也就是一行有长有短)
int[][] arr = new int[5][];//二维数组一共有5行,但是每一行的元素个数不确定 //把二维数组看成一维数组的话,元素类型是int[]类型,int[]数组是引用数据类型,默认值就是null System.out.println(arr[0]);//输出null
初始化的值
整数类型数组: 里面填充为0
小数类型数组: 里面填充为0.0
boolean类型数组: 里面填充false
char类型数组: 里面填充\u000
return new int[0]; 的意义
- 这个
return new int[0];就是防止编译器报错,返回一个垃圾值
/*
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数, 并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
你可以按任意顺序返回答案。
*/
class Solution {
public int[] twoSum(int[] nums, int target) {
//用数组中的一个元素值,加上其它的元素值,看看是否等于target,已经使用过的组合就不再使用了
for(int i = 0;i < nums.length;i++){
for(int j = i + 1;j < nums.length;j++){
//用一个元素值和它后面的所有元素值相加,以此类推
if(target == (nums[i] + nums[j])){
return new int[]{i,j};
}
}
}
return new int[0];
}
}
面向对象
- 以类和对象为核心
- 代码的结构以类为单位,程序是由一个一个的类组成的
- 数据是在类里面的,数据分为在类中方法(函数)外,类中方法(函数)内
- 数据在类中的方法外,称为 成员变量/成员数据.要么属于某个类共享,要么是每一个对象独立的.
public class class_study {
int a = 100;//成员变量
public static void main(String[] args) {
int b = 100;//不是成员变量,为局部变量
}
}
- 数据在类中的方法内,称为局部变量/局部数据.局部变量无法共享,每一个方法独立
类的定义
- 类的定义/声明格式
- 类的名称尽量见名知意,每一个单词的首字母大写
[修饰符] class 类名{
}
[修饰符] 可以缺省
public和缺省public有什么区别?
(1)
如果class前面有public,要求.java文件名称必须要和class后面的类名相同(包括单词和大小写)
一个.java文件只能有一个public的类
如果class前面没有public,则不要求类名与.java文件名相同
建议大家一个.java只写一个类,类名和.java文件名相同,方便维护
(2)如果class是public,可以跨包使用,
如果class没有public,那么不能跨包使用
对象的创建
new 类名();
new 类名(实参列表)
匿名对象,如果没有把对象赋值给一个变量,那么这样子的对象称为匿名对象,
如果希望这个对象反复使用,那么最好把这个对象给一个变量,就像下面这样子
类名 变量名 = new 类名();
类的成员
- 1223
类的成员有:
成员变量
成员方法
构造器
代码块
成员内部类
成员变量
1.成员变量声明的位置,必须要在类中方法外
2.成员变量声明的格式
[修饰符] class 类名{
//下面就是成员变量
[修饰符] 数据类型 变量名
}
成员变量修饰符:public,protected,private,static,final,transient,volatile等
数据类型:可以是8种基本数据类型,也可以是引用数据类型
包
- 必须在源文件的代码首行
- 一个包名对应的是一个目录
- 一个源文件只能有一个声明包的package语句
- 关键字为
package - package语句只要不是一模一样的,就不是同一个包
package 包名
- 包的命名规范和习惯:
- 所有的单词都小写,每一个单词之间使用
.分割 - 习惯用公司的域名倒置开头和具体功能模块进行命名,比如
com.atguigu.xxx;- 因为尚硅谷官网是
atguigui.com,倒过来就是com.atguigu
- 因为尚硅谷官网是
- 所有的单词都小写,每一个单词之间使用
建议大家取包名时不要使用java.xx包
包的作用域
- 位于同一个包的类,可以访问作用域的字段和方法
- 不用
public,protected,private修饰的字段和方法就是包的作用域
不用public,protected,private修饰的字段和方法就是包的作用域,具有代码目录结构如下
均在默认包下(也就是缺省包)
Student.java
TestStudent.java
//Student.java文件内容
public class Student {
String name;
}
//TestStudent.java文件内容
public class TestStudent {
public static void main(String[] args) {
//可以正常使用,没有问题
Student stu1 = new Student();
stu1.name = "李白";
System.out.println("stu1 = " + stu1.name);
}
}
- 如果文件目录更改,也就是将
Student.java移动到top.dreamlove包下- Student的成员变量添加了
Public,才可以被其他类所访问,否者只是在top.dreamlove包下才可以使用,也就是包的作用域下
- Student的成员变量添加了
//文件目录结构
-top.dreamlove
--Student.java
-TestStudent.java
//Student.java文件内容
public class Student {
//添加Public修饰词
Public String name;
}
//TestStudent.java文件内容
import top.dreamlove.Student;
public class TestStudent {
public static void main(String[] args) {
Student stu1 = new Student();
stu1.name = "李白";
System.out.println("stu1 = " + stu1.name);
}
}
- 可以参考这个文章
- https://blog.csdn.net/qq_37189082/article/details/124348206
如何跨包使用类
-
第一种方法是直接使用类型的全名称
例如:
java.util.Scanner input = new java.util.Scanner(System.in); -
第二种方法是通过
import关键字来引入包- import语句告诉编译器到哪里去寻找类。
- import语句的语法格式
- import语句需要编写到package语句之下,class语句之上
//引入部分包 import 包名.类名 //一次性引入指定包名下的所有类 import 包名.* //这里*代表的是省略的类名,不能省略子包名
注意:
使用java.lang包下的类,不需要import语句,就直接可以使用简名称
import语句必须在package下面,class的上面
当使用两个不同包的同名类时,例如:java.util.Date和java.sql.Date。一个使用全名称,一个使用简名称
- 只有public的类才能被跨包使用
方法
- 方法必须要先声明后使用,不调用不执行,调用一次执行一次。
- 声明的正确示范如下
//正确示范
类{
方法1(){
}
方法2(){
}
}
- 错误示范
//错误示范
类{
方法1(){
方法2(){ //位置错误
}
}
}
- 格式
- 修饰符也很多,
public,protected,private,static,final,native,如果需要跨包使用,需要使用public修饰符
- 修饰符也很多,
【修饰符】 返回值类型 方法名(【形参列表 】)【throws 异常列表】{
方法体的功能代码
}
- 如果类中的方法没有使用
public修饰符,那么这个方法只能在本包的其他类使用,不能跨包使用(同理,属性也是一样的)
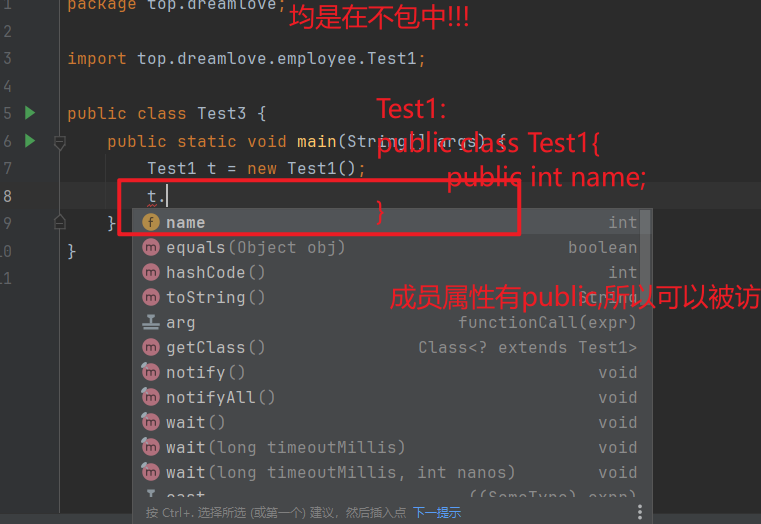
实例变量与局部变量的区别
1、声明位置和方式
(1)实例变量:在类中方法外
(2)局部变量:在方法体{}中或方法的形参列表、代码块中
2、在内存中存储的位置不同
(1)实例变量:堆
(2)局部变量:栈
3、生命周期
(1)实例变量:和对象的生命周期一样,随着对象的创建而存在,随着对象被GC回收而消亡,
而且每一个对象的实例变量是独立的。
(2)局部变量:和方法调用的生命周期一样,每一次方法被调用而在存在,随着方法执行的结束而消亡,
而且每一次方法调用都是独立。
4、作用域
(1)实例变量:通过对象就可以使用,本类中“this.,没有歧义还可以省略this.”,其他类中“对象.”
(2)局部变量:出了作用域就不能使用
5、修饰符(后面来讲)
(1)实例变量:public,protected,private,final,volatile,transient等
(2)局部变量:final
6、默认值
(1)实例变量:有默认值
(2)局部变量:没有,必须手动初始化。其中的形参比较特殊,靠实参给它初始化。
参数
形参和实参
- 形参:在声明方法时,
()中声明的变量,每调用这个方法之前,它的值是不确定的
//int a , int b是形参,它就是一个占位符,形式上存在的
public int max(int a,int b){
return a > b ? a : b;
}
- 实参,在"调用"方法时,
()中传入的数据,这个数据可能是常量值,也可能是变量,还可以是表达式
可变参数
- 当定义一个方法时,形参的类型可以确定,但是形参的个数不确定,那么可以考虑使用可变参数。可变参数的格式:
【修饰符】 返回值类型 方法名(【非可变参数部分的形参列表,】参数类型... 形参名){ }
//貌似这样子也可以
【修饰符】 返回值类型 方法名(【非可变参数部分的形参列表,】参数类型 ...形参名){ }
- 示例,自定义Sum类,有一个计算总值方法
package top.dreamlove.param;
public class Sum {
public double getAll(int... all){
int sum = 0;
for (int i = 0; i < all.length; i++) {
int i1 = all[i];
sum+=i1;
}
return sum;
}
}
//调用
package top.dreamlove.param;
public class Test1 {
public static void main(String[] args) {
Sum s1 = new Sum();
//可以这样子
double temp1 = s1.getAll(new int[]{1, 2, 3, 4, 5});
//也可以这样子
double temp2 = s1.getAll(1,2,3,4,5);
System.out.println("temp1 = " + temp1);//输出15
System.out.println("temp2 = " + temp2);//输出15
}
}
方法的重载(Overload)
- 一个类中出现了方法名相同,形参列表不同的二个或多个方法,称为方法的重载
- 方法名必须要相同
- 形参列表必须不同
- 返回值类型:无关紧要(可相同,可不同)
对象数组
- 数组是用来存储一组数据的容器,一组基本数据类型的数据可以用数组装,那么一组对象也可以使用数组来装。即数组的元素可以是基本数据类型,也可以是引用数据类型。当元素是引用数据类型是,我们称为对象数组。
注意:对象数组,首先要创建数组对象本身,即确定数组的长度,然后再创建每一个元素对象,如果不创建,数组的元素的默认值就是null,所以很容易出现空指针异常NullPointerException。
- 示例
public class Rectangle {
double length;
double width;
double area(){//面积
return length * width;
}
double perimeter(){//周长
return 2 * (length + width);
}
String getInfo(){
return "长:" + length +
",宽:" + width +
",面积:" + area() +
",周长:" + perimeter();
}
}
public class ObjectArrayTest {
public static void main(String[] args) {
//声明并创建一个长度为3的矩形对象数组
Rectangle[] array = new Rectangle[3];
//创建3个矩形对象,并为对象的实例变量赋值,
//3个矩形对象的长分别是10,20,30
//3个矩形对象的宽分别是5,15,25
//调用矩形对象的getInfo()返回对象信息后输出
for (int i = 0; i < array.length; i++) {
//创建矩形对象
array[i] = new Rectangle();
//为矩形对象的成员变量赋值
array[i].length = (i+1) * 10;
array[i].width = (2*i+1) * 5;
//获取并输出对象对象的信息
System.out.println(array[i].getInfo());
}
}
}
面向对象的基本特征
- 面向对象这个编程思想,有三个基本特征
- 封装
- 继承
- 多态
封装
- 隐藏对象内部的复杂性,只对外公开简单和可控的访问方式,从而提高系统的可扩展性、可维护性。通俗的讲,把该隐藏的隐藏起来,该暴露的暴露出来。这就是封装性的设计思想。(只关心使用,不关心如何实现,就和手机一个道理,你不会去关心手机如何实现的,只会在意手机卡不卡)
实现封装
- 依赖于权限修饰符,或者又称为访问控制符,修饰符如下,可用与成员方法或者成员属性
| 修饰符 | 本类 | 本包 | 其他包子类 | 其他包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √ | × | × |
| protected | √ | √ | √ | × |
| public | √ | √ | √ | √ |
private只能被本类访问
public 子类和其他包非子类都可以访问
protected 子类才可以访问,其他包非子类不可以访问
缺省 本包和本类才可以访问
- 成员变量选择哪种权限修饰符?
- 实际上,习惯上,先声明为
private,如果这个成员变量需要扩大它的可见性访问,那么可以把private修改为其他合适的修饰符 - 扩大到本包,可以使用缺省
- 扩大到其他包的子类,可以使用
protected - 扩大到任意位置,可以使用
public
- 实际上,习惯上,先声明为
- 为什么?
- 对象的数据要可控,不应全部暴露
- 其他包子类
package test1;
public class Person {
protected String name;
}
package test1.son;
import test1.Person;
public class Test2 extends Person {
public void method(){
//成功访问
System.out.println(name);
}
}
- 其他包非子类
package test1;
public class Person {
protected String name;
}
//其他包非子类
package test1.noson;
import test1.Person;
public class Test3 {
public static void main(String[] args) {
Person s1 = new Person();
//无法访问
System.out.println(s1.name);
}
}
如何使用私有化的属性?
-
如果这个属性确实要被外部使用,需要提供
get或者set方法get方法:供调用者获取属性值的方法set方法:供调用者修改属性值的方法
-
生成的
get/set的方法名,通常都是get+ 属性名,并且属性名的首字母大写set+ 属性名,并且属性名的首字母大写
-
但是如果实例变量是
boolean类型- 那么它对应的
get方法,就会把get单词替换为is,而set命名不变
public class Test{ private marry; public boolean isMarry(){ } public boolean setMarry(){ } } - 那么它对应的
继承
- 为什么要继承
- 提高代码的复用性。
- 提高代码的扩展性。
- 继承要满足
is - a的关系
Student is a Person
Teacher is a Person
//注意,下面的就不是is - a的关系
Car is not a Person
- 关键词
extends
[修饰符] class 子类名 extends 父类名{
}
- 子类表示的事物范围大还是父类表示事物的范围大?
- Person类是父类
- Student类是子类
- 子类的事物范围 < 父类的事物范围
- 子类更具体,里面的成员描述更多了
- 父类更抽象,笼统的描述信息更少
继承有什么特点
- 子类会继承父类的实例变量和实现方法
- 当子类对象被创建时,在堆中给对象申请内存时,就要看子类和父类都声明了什么实例变量,这些实例变量都要分配内存(不管能不能访问的到)。
- Java只支持单继承,不支持多重继承
public class A{}
class B extends A{}
//一个类只能有一个父类,不可以有多个直接父类。
class C extends B{} //ok
class C extends A,B...//error
- Java支持多层继承(继承体系)
class A{}
class B extends A{}
class C extends B{}
- 一个父类可以同时拥有多个子类
class A{}
class B extends A{}
class D extends A{}
class E extends A{}
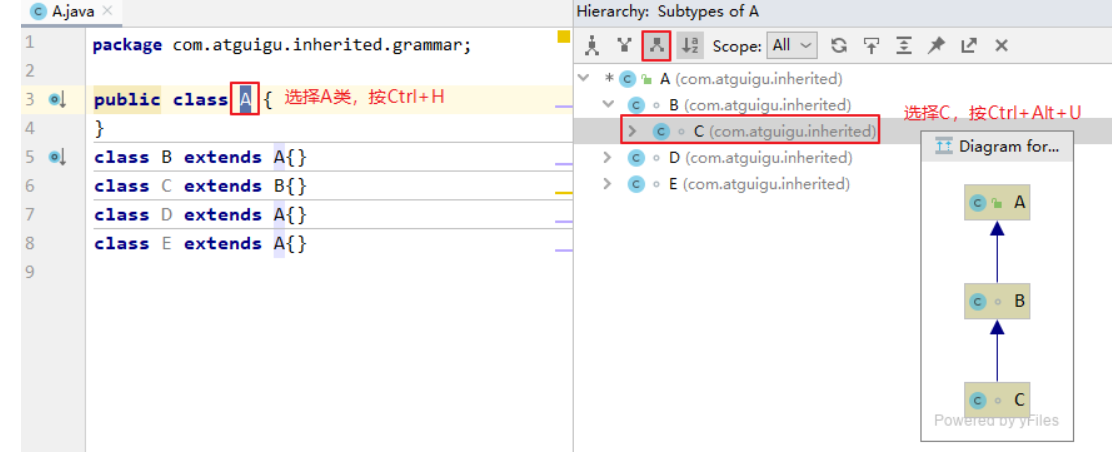
- 查看继承关系快捷键
例如:选择A类名,按Ctrl + H就会显示A类的继承树。
 :A类的父类和子类
:A类的父类和子类
 :A类的父类
:A类的父类
 :A类的所有子类
:A类的所有子类
例如:在类继承目录树中选中某个类,比如C类,按Ctrl+ Alt+U就会用图形化方式显示C类的继承祖宗
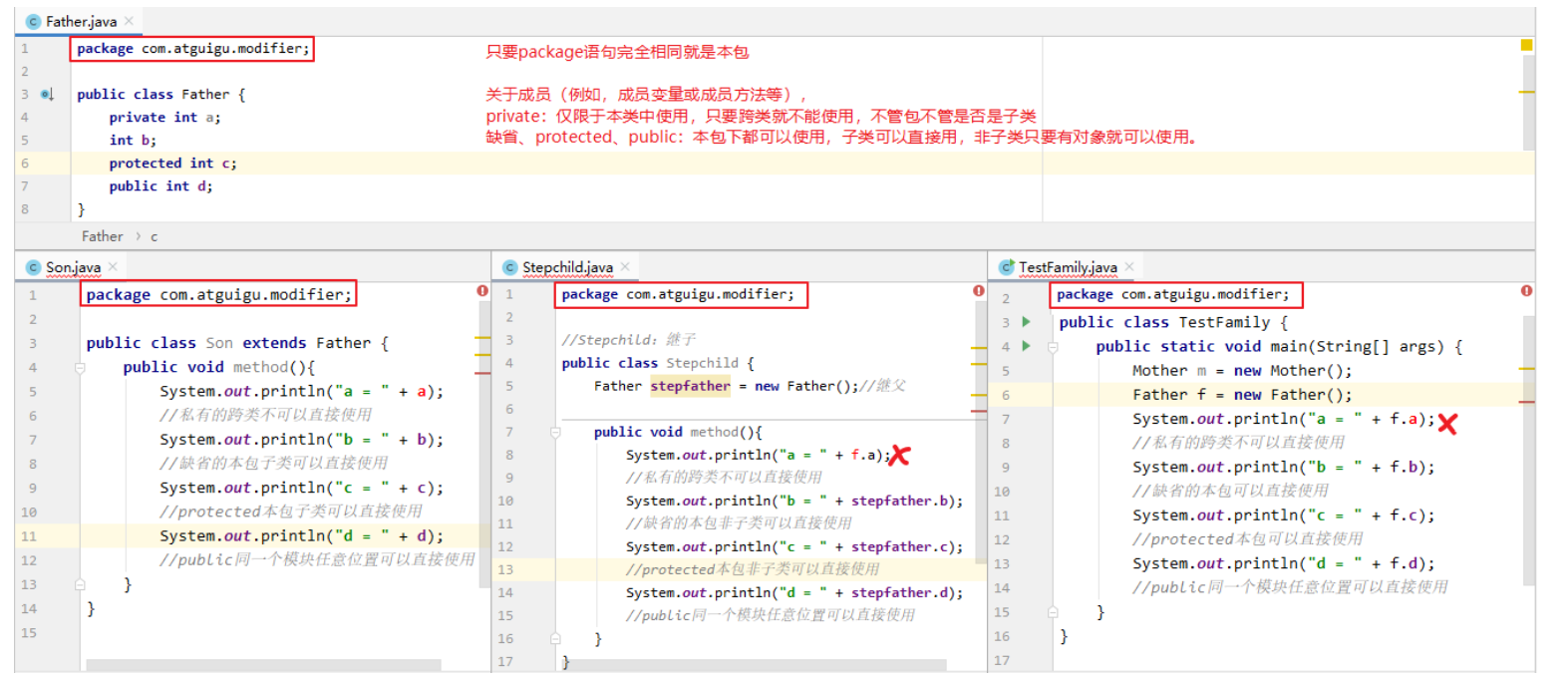
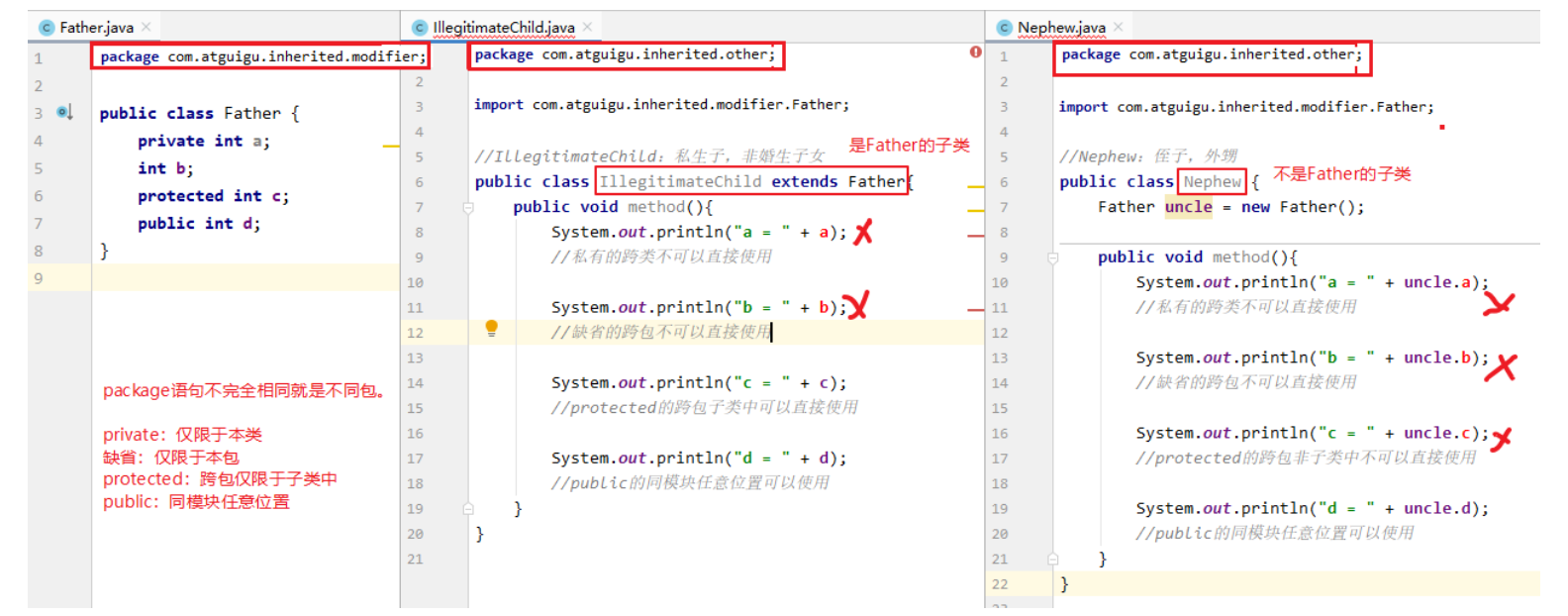
权限修饰符问题
权限修饰符:public,protected,缺省,private
| 修饰符 | 本类 | 本包 | 其他包子类 | 其他包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √(本包子类非子类都可见) | × | × |
| protected | √ | √(本包子类非子类都可见) | √(其他包仅限于子类中可见) | × |
| public | √ | √ | √ | √ |
外部类:public和缺省
成员变量、成员方法等:public,protected,缺省,private
1.外部类要跨包使用必须是public,否则仅限于本包使用
(1)外部类的权限修饰符如果缺省,本包使用没问题
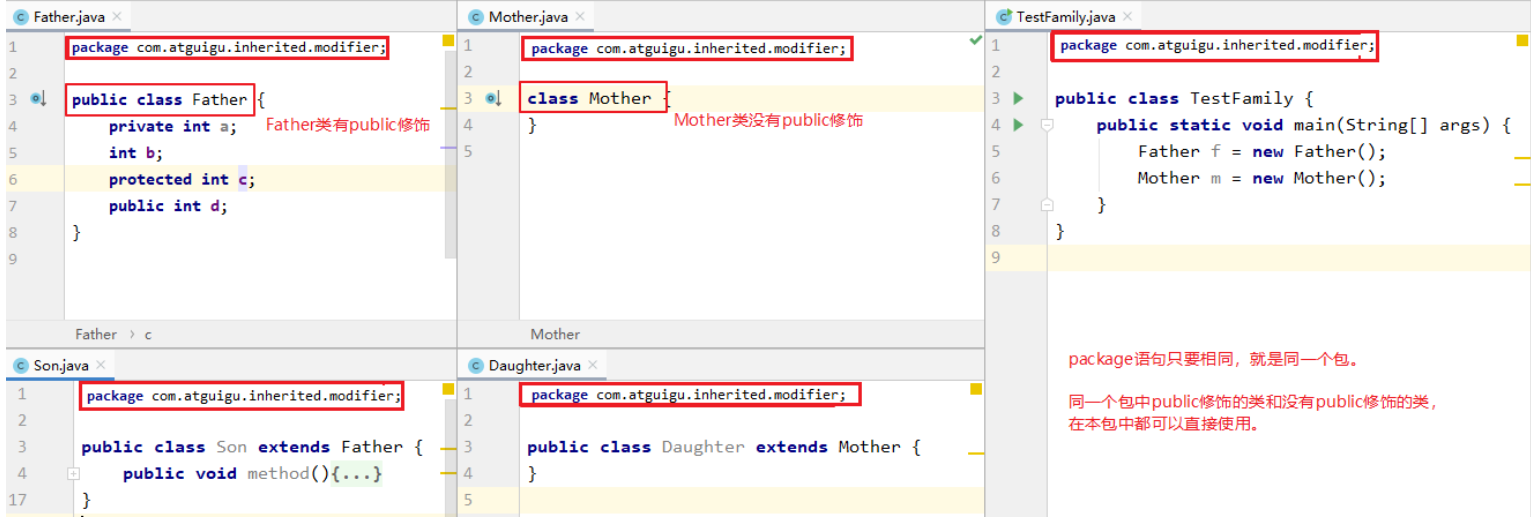
(2)外部类的权限修饰符如果缺省,跨包使用有问题
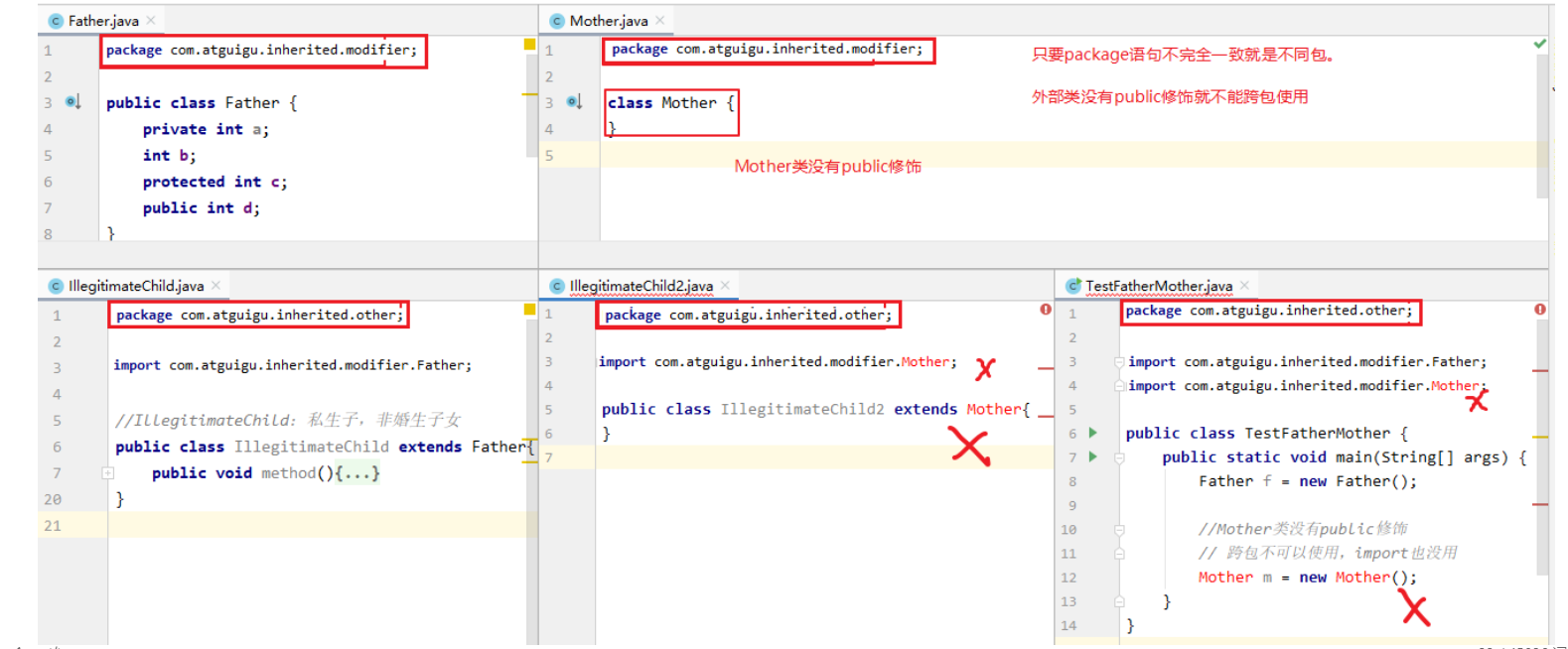
2.成员的权限修饰符问题
(1)本包下使用:成员的权限修饰符可以是public、protected、缺省
(2)跨包下使用:要求严格
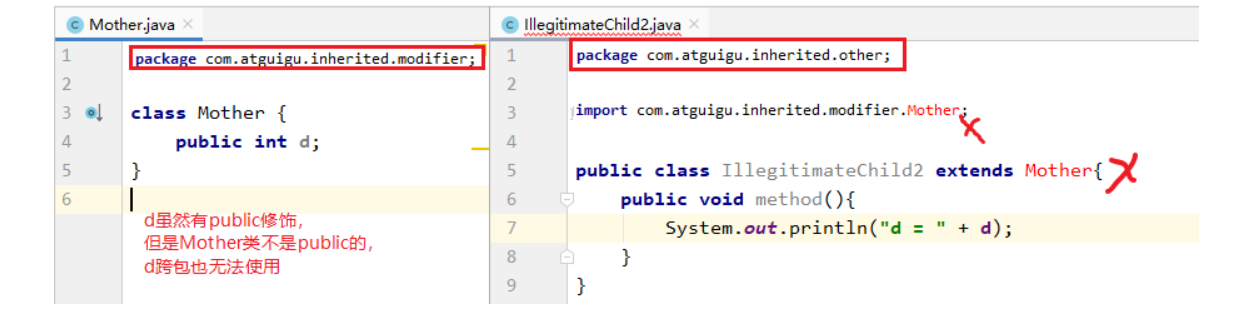
(3)跨包使用时,如果类的权限修饰符缺省,成员权限修饰符>类的权限修饰符也没有意义
3.父类成员变量私有化(private)
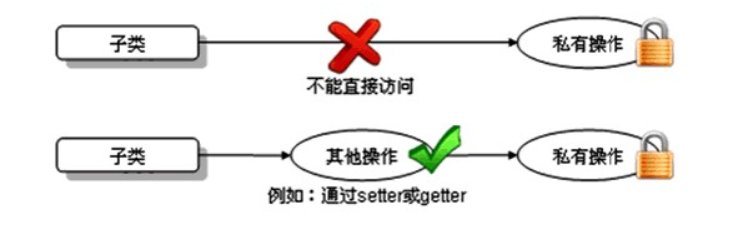
- 子类虽会继承父类私有(private)的成员变量,但子类不能对继承的私有成员变量直接进行访问,可通过继承的get/set方法进行访问。如图所示:
父类代码:
package com.atguigu.inherited.modifier;
public class Person {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getInfo(){
return "姓名:" + name + ",年龄:" + age;
}
}
子类代码
package com.atguigu.inherited.modifier;
public class Student extends Person {
private int score;
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public String getInfo(){
// return "姓名:" + name + ",年龄:" + age;
//在子类中不能直接使用父类私有的name和age
return "姓名:" + getName() + ",年龄:" + getAge();
}
}
测试类代码:
package com.atguigu.inherited.modifier;
public class TestStudent {
public static void main(String[] args) {
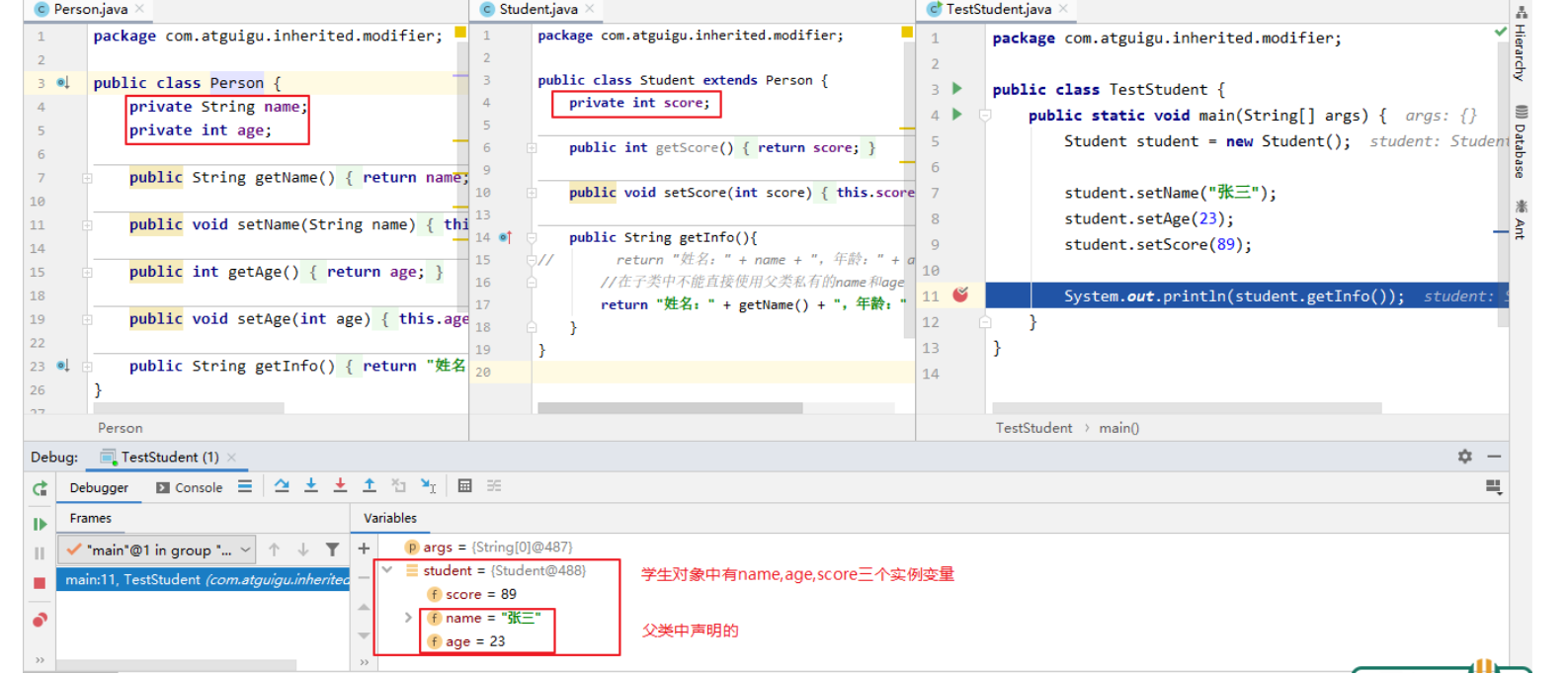
Student student = new Student();
student.setName("张三");
student.setAge(23);
student.setScore(89);
System.out.println(student.getInfo());
}
}
IDEA在Debug模式下查看学生对象信息:
重写(Override)
-
我们说父类的所有方法子类都会继承,但是当某个方法被继承到子类之后,子类觉得父类原来的实现不适合于子类,该怎么办呢?我们可以进行方法重写 (Override)
-
重写过程中,如果需要调用父类的方法,需要使用
super关键字
//父类
package com.atguigu.inherited.method;
public class Phone {
public void sendMessage(){
System.out.println("发短信");
}
public void call(){
System.out.println("打电话");
}
public void showNum(){
System.out.println("来电显示号码");
}
}
package com.atguigu.inherited.method;
//smartphone:智能手机
public class Smartphone extends Phone{
//重写父类的来电显示功能的方法
public void showNum(){
//来电显示姓名和图片功能
System.out.println("显示来电姓名");
System.out.println("显示头像");
//保留父类来电显示号码的功能
super.showNum();//此处必须加super.,否则就是无限递归,那么就会栈内存溢出
}
@Override
public void call() {
super.call();
System.out.println("视频通话");
}
}
重写的要求
-
父类和子类之间,重写方法的名称相同
-
父类和子类之间,参数列表也要完全相同
-
返回值类型
- 如果是
void和基本数据类型,返回值必须要相同 - 如果是引用数据类型
- 子类重写方法的返回值类型必须要小于等于父类方法的返回值类型
- 父类的菜,你子类重写就应该小于等于菜,不能说重写返回值返回一个人类
- 子类重写方法的返回值类型必须要小于等于父类方法的返回值类型
- 子类方法的权限必须【大于等于】父类方法的权限修饰符。
注意:public > protected > 缺省 > private
父类私有方法不能重写
跨包的父类缺省的方法也不能重写
- 如果是
EMS项目结构
- 一般的java项目目录结构如下
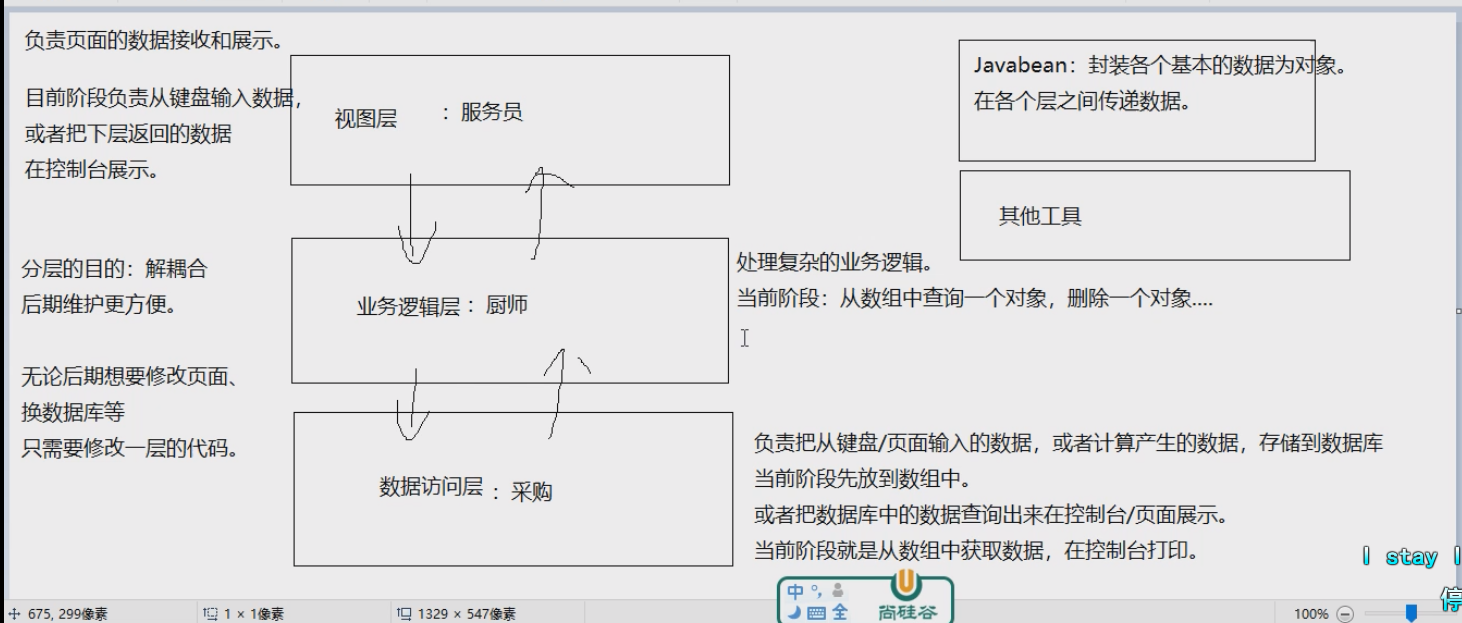
- 也就是
- 视图层(view)包
- 业务逻辑层(service)包
- 数据访问层(dao)包
- bean包或者domain包
多态
父类类型 变量名 = 子类对象;
且在调用的时候只能调用父类声明的方法,不能调用子类扩展的方法
- 编译类型取决于定义对象时 =号的左边,运行类型取决于 =号的右边
向上转型
-
自动类型转换
-
当把子类对象赋值给父类的变量时,在"编译时"会自动类型提升为父类的类型
- 也就是从小的范围自动转化为了大的范围
-
怎么才能成功?
只要满足对象是这个要赋值变量的子类型即可
Person p1 = new Man();
//Man继承了Person类
向下转型
- 如果需要调用子类扩展的方法的时候,必须要向下转型,通过强制类型转换完成,这样才能通过编译,对象的本质类型从头到尾都没有变化,只是骗编译器的
父类类型 变量名 = 子类对象;
且在调用的时候只能调用父类声明的方法,不能调用子类扩展的方法,但是在堆当中已经有对应的方法了,只是编译器不让你调用
- 怎么才能成功向下转型?
- 运行类型类型怎么看?就是new单词后面的类型
- 大小可以理解为范围的大小,比如人类的范围肯定比男人要大,所以男人<人类
对象的运行类型必须要 <= ()中向下转的类型
// Class Man extends Person
//p1对象的运行时类型为Man,会等于要转换为Man的类型,所以可以向下转型
Person p1 = new Man();
Man temp1 = (Man) p1;
// Class Man extends Person
// Class ChineseMan extends Man
// p2运行时候的类型为ChineseMan,和Man相比,小于Man,所以可以向下转型
Person p2 = new ChineseMan();
Man temp2 = (Man)p2;
// Class Man extends Person
// Class Woman extends Person
// p3对象运行时候的类型为Man,和Woman相比,没啥子关系,所以不能比较,所以不可以向下转型
// 向下转型失败,报ClassCastException(类强制转换异常)
Person p3 = new Man();
Man temp3 = (Woman)p3;
// Class Man extends Person
// p4运行时的类型为Person,和Man相比,比Man更大,不满足<=关系,所以不可以向下转型
// 向下转型失败,报ClassCastException(类强制转换异常)
Person p4 = new Person();
Man temp4 = (Man)p4;
如何避免向下转型编译通过,运行发生ClassCastException?
- 添加
instanceof判断
语法格式
变量/对象 instanceof 类型
instanceof的作用是判断某个变量/对象的运行类型是否<=instanceof后面写的类型
(前端作用是:instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。)
注意
- 在成员变量:没有多态的概念,变量的寻找只看编译时类型,没有编译时类型和运行时类型不一致这个说法
- 在成员方法:有多态的概念,编译时看父类,运行时看子类,如果子类重写了,一定是执行子类重写的方法体;
构造器
-
构造器的修饰符只能是
public,protected,缺省,private,不能有static,final -
构造器的名称不能随意乱写,只能也一定要和类名完全一致,包括大小写
-
如果没有创建任何构造器,那么编译器会添加一个和class类前面的权限修饰符一致的默认构造器(如果手动写了任意一个构造器,则不会添加默认构造器)
同一个类中构造器相互调用
this()调用本类的无参构造器this(实参列表)调用本类的有参构造器- this()和this(实参列表)只能出现在构造器首行
- 不能出现递归调用

构造器在继承时的要求
-
父类构造器不会继承到子类中
-
父类的构造器和子类有没有关系?
- 子类在继承父类的时,默认会在子类的构造器首行加一句代码
super(),表示调用父类的无参构造器
- 子类在继承父类的时,默认会在子类的构造器首行加一句代码
-
父类中只有无参构造或者没有写构造函数(默认构造函数)
- 子类首行可以添加
super(),也可以省略
- 子类首行可以添加
-
父类中只有有参构造
- 子类首行必须要添加
super(父类所有实参列表),否则会调用(也就是要调用父类的构造函数)
- 子类首行必须要添加
-
父类中既有无参构造函数,又有有参构造函数
- 写了
super(),就表示调用父类的无参构造 - 写了
super(实参列表),就表示调用父类的有参构造
- 写了
-
为什么子类的构造器一定要调用父类的构造器呢?
- 因为子类会继承父类所有的成员变量,那么在new子类对象的时候,必须要为这些继承成员变量"初始化"
-
super()表示调用父类的无参构造,可以省略
-
super(实参列表),表示调用父类的有参构造,不能省略
-
如果要写他们,都必须要在构造器的首行,而且不能与this(),this(实参列表)在同一个构造器中出现
非静态代码块
-
作用:用来给实例变量初始化的
-
意义:把多个构造器的代码抽离出来,写到代码块中,减少代码冗余
-
特点:
- 代码块中的代码会自动执行
- 当new对象时,会自动执行,不new对象不会执行
- 每new一个对象,执行一次
- 无论它写在哪里,都是比构造器先执行
-
比如需要n个构造器都执行一段代码,怎么办?难不成n个构造器都写入代码吗?太不方便了,所以可以这样子
public class Student{
//非静态代码块
{
System.out.println("新用户注册");
this.currentTime = System.currentTimeMillis();
}
public Student(){
}
public Student(String name){
}
}
- 格式
【修饰符】 class 类{
{
非静态代码块
}
【修饰符】 构造器名(){
// 实例初始化代码
}
【修饰符】 构造器名(参数列表){
// 实例初始化代码
}
}
实例初始化过程
- new调用构造器,本质上是执行它对应的
<init>方法 - 每一个构造器都会有自己对应的
<init>方法,它由下面这些代码组成:- A:
super()或者super(实参列表)(已经不仅仅代表父类的构造器,而且还代码父类构造器对应的init方法) - B:当前类的 实例变量声明后的显式赋值表达式语句和非静态代码块 (这二个按照代码块编写的顺序依次组装)
- C:构造器剩下的代码(除了super()或者super(实参列表)的代码)
- A:
final
- 在类前,代表这个类都不能被继承
- 在方法名前,代表方法只能被继承,不能被重写
- 在变量名前,代表这个变量不能被修改,也就是常量
class MyDate {
//没有set方法(你生成的时候也不显示)
private final int year;
}
Object根父类
- 既然Object是所有类的父类,那么Object类型的变量,可以和任意类型的对象构成"多态引用"
Object obj1 = "hello";//正确
Object obj2 = new Student();//正确
Object obj3 = new Scanner(System.in);//正确
- java规定,Object[]数组,可以接收任意类型的对象数组
- java规定,int[],char[]等,它们之间是不能互相转换,它们和Object[]之间也不能互相转换
Object[] arr1 = new String[5];//正确
Object[] arr2 = new int[10];//错误
Object[] arr3 = new char[10];//错误
Object arr4 = new int[5];//正确
- 所有类都可以调用Object当中的方法
Object类中方法
public String toString();
-
用法
-
通过对象.toString()进行调用
-
在打印对象时自动调用(System.out.print)
-
在对象与字符串进行"+"拼接时自动调用
-
-
说明
- 如果子类没有重写,继承的Object类的toString默认返回的是
- 对象的运行时类型@对象的hashCode值的十六进制值
-
重写toString方法
- 这样子我们就不用去创建
getInfo这种方法了
- 这样子我们就不用去创建
public final Class<?> getClass()
- 返回此对象的运行时类
//编译时类型是Object,运行时类型是Student
Object o1 = new Student("李白","男");
System.out.println(o1.getClass());//class constructor.Student
//编译时类型是Student,运行时类型是Student
Student temp1 = new Student("李黑","男");
System.out.println(temp1.getClass());//class constructor.Student
public boolean equals(Object obj);
- 用于判断当前对象this和指定对象obj是否"相等"
- 默认情况下,equals方法的实现等价于与“==”,比较的是对象的地址值
- 我们可以选择重写,重写有些要求:
- 自反性
- 自己和自己比较一定返回true
- x.equals(x)一定返回true
- 对程序
- x.equals(y)如果返回true,那么y.equals(x)也要返回true
- 传递性
- a等于b,b等于c,那么a肯定会等于c
- 一致性:
- x.equals(y)如果在前面调用时返回true,这2个对象参与equals比较的属性没有修改的话,那么在后面调用结果也要返回true
- 非空对象与null比较,永远是false
- x.equals(null)一定是false
- null.equals(x)错误,会报空指针异常
- 自反性
public native int hashCode()
public native int hashCode():返回该对象的哈希码值。支持此方法是为了提高哈希表(例如 java.util.Hashtable 提供的哈希表)的性能。
哈希表示一个数组+链表或数组+链表/红黑树的结构。
数组的优点:
根据[下标]可以快速的定位到某个元素。
哈希表是一个容器,用来装对象。当哈希表中的对象有很多的时候,要查询到某个对象是否存在,工作会很大。
如何提高查询的效率?希望能够充分利用数组的优点。
但是,对于任意一个对象来说,它在查找之前,并不知道它的[下标]。
问题就转换为,如何找到快速的计算下标的方式。
[下标】 = 对象的hashCode值 & (数组的长度 - 1)。
哈希表存储对象就是这个公式来定位存储位置。
hashCode值 & (数组的长度 - 1) 计算的结果范围[0, 数组的长度-1]
因为Java中hashCode值是通过某个“算法”计算出来的一个int值,那么这个算法,可能是某个散列函数,可能是某个JVM地址值等。
本类Java希望,不同的对象,它的hashCode值是不同的,但是现实中,可能出现,两个不同的Java对象,它的hashCode相等了。
(1)如果两个对象equals返回true,那么这两个的hashCode一定要相同。
(2)如果两个对象hashCode值不相同,那么这两个对象equals也一定要不相等。
(3)如果两个对象的hashCode相同的,那么这个两个对象equals不一定相同
在重写equals方法时,一定要一起重写hashCode方法,保持它俩的上述规定。
- public int hashCode():返回每个对象的hash值。
如果重写equals,那么通常会一起重写hashCode()方法,hashCode()方法主要是为了当对象存储到哈希表(后面集合章节学习)等容器中时提高存储和查询性能用的,这是因为关于hashCode有两个常规协定:
- ①如果两个对象的hash值是不同的,那么这两个对象一定不相等;
- ②如果两个对象的hash值是相同的,那么这两个对象不一定相等。
重写equals和hashCode方法时,要保证满足如下要求:
-
①如果两个对象调用equals返回true,那么要求这两个对象的hashCode值一定是相等的;
-
②如果两个对象的hashCode值不同的,那么要求这个两个对象调用equals方法一定是false;
-
③如果两个对象的hashCode值相同的,那么这个两个对象调用equals可能是true,也可能是false
public static void main(String[] args) {
System.out.println("Aa".hashCode());//2112
System.out.println("BB".hashCode());//2112
}
finalize
protected void finalize():用于最终清理内存的方法


演示finalize()方法被调用:
package com.atguigu.api;
public class TestFinalize {
public static void main(String[] args) throws Throwable{
for (int i=1; i <=10; i++){
MyDemo my = new MyDemo(i);
//每一次循环my就会指向新的对象,那么上次的对象就没有变量引用它了,就成垃圾对象
}
//为了看到垃圾回收器工作,我要加下面的代码,让main方法不那么快结束,因为main结束就会导致JVM退出,GC也会跟着结束。
System.gc();//如果不调用这句代码,GC可能不工作,因为当前内存很充足,GC就觉得不着急回收垃圾对象。
//调用这句代码,会让GC尽快来工作。
Thread.sleep(5000);//单位是毫秒,让当前程序休眠5秒再结束
}
}
class MyDemo{
private int value;
public MyDemo(int value) {
this.value = value;
}
@Override
public String toString() {
return "MyDemo{" + "value=" + value + '}';
}
//重写finalize方法,让大家看一下它的调用效果
@Override
protected void finalize() throws Throwable {
// 正常重写,这里是编写清理系统内存的代码
// 这里写输出语句是为了看到finalize()方法被调用的效果
System.out.println(this+ "轻轻的走了,不带走一段代码....");
}
}
每一个对象的finalize()只会被调用一次,哪怕它多次被标记为垃圾对象。当一个对象没有有效的引用/变量指向它,那么这个对象就是垃圾对象。GC(垃圾回收器)通常会在第一次回收某个垃圾对象之前,先调用一下它的finalize()方法,然后再彻底回收它。但是如果在finalize()方法,这个垃圾对象“复活”了(即在finalize()方法中意外的又有某个引用指向了当前对象,这是要避免的),被“复活”的对象如果再次称为垃圾对象,GC就不再调用它的finalize方法了,避免这个对象称为“僵尸”。
package com.atguigu.api;
public class TestFinalize {
private static MyDemo[] arr = new MyDemo[10];
private static int total;
public static void add(MyDemo demo){
arr[total++] = demo;
}
public static void main(String[] args) throws Throwable{
for (int i=1; i <=10; i++){
MyDemo my = new MyDemo(i);
//每一次循环my就会指向新的对象,那么上次的对象就没有变量引用它了,就成垃圾对象
}
//为了看到垃圾回收器工作,我要加下面的代码,让main方法不那么快结束,因为main结束就会导致JVM退出,GC也会跟着结束。
System.gc();//如果不调用这句代码,GC可能不工作,因为当前内存很充足,GC就觉得不着急回收垃圾对象。
//调用这句代码,会让GC尽快来工作。
Thread.sleep(5000);//单位是毫秒,让当前程序休眠5秒再结束
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);//MyDemo的对象还在,没有被回收掉,因为在回收过程中被复活了
}
for (int i = 0; i < arr.length; i++) {
arr[i] = null;//让这些元素不引用MyDemo的对象,这些对象再次称为垃圾对象
System.out.println(arr[i]);
}
arr = null;
System.gc();//再次让GC工作,使得MyDemo的对象再次被回收
Thread.sleep(5000);//单位是毫秒,让当前程序休眠5秒再结束
}
}
class MyDemo{
private int value;
public MyDemo(int value) {
this.value = value;
}
@Override
public String toString() {
return "MyDemo{" + "value=" + value + '}';
}
//重写finalize方法,让大家看一下它的调用效果
@Override
protected void finalize() throws Throwable {
// 正常重写,这里是编写清理系统内存的代码
// 这里写输出语句是为了看到finalize()方法被调用的效果
System.out.println("我轻轻的走了,不带走一段代码....");
TestFinalize.add(this);
//把当前对象this放到一个数组中,这样就有变量引用它,当前对象就不能被回收了
//当下次this对象再次称为垃圾对象之后,GC就不会调用它的finalize()方法了
}
}
面试题:对finalize()的理解?
-
当对象被GC确定为要被回收的垃圾,在回收之前由GC帮你调用这个方法,不是由程序员手动调用。
-
这个方法与C语言的析构函数不同,C语言的析构函数被调用,那么对象一定被销毁,内存被回收,而finalize方法的调用不一定会销毁当前对象,因为可能在finalize()中出现了让当前对象“复活”的代码
-
每一个对象的finalize方法只会被调用一次,就算对象在finalize方法中被复活了,下次GC就不调用它的finalize方法了。
-
子类可以选择重写,一般用于彻底释放一些资源对象,而且这些资源对象往往时通过C/C++等代码申请的资源内存
静态
- 静态变量存储在方法区
7.1.1 静态关键字(static)
在类中声明的实例变量,其值是每一个对象独立的。但是有些成员变量的值不需要或不能每一个对象单独存储一份,即有些成员变量和当前类的对象无关。
在类中声明的实例方法,在类的外面必须要先创建对象,才能调用。但是有些方法的调用和当前类的对象无关,那么创建对象就有点麻烦了。
此时,就需要将和当前类的对象无关的成员变量、成员方法声明为静态的(static)。
7.1.2 静态变量
1、语法格式
有static修饰的成员变量就是静态变量。
【修饰符】 class 类{
【其他修饰符】 static 数据类型 静态变量名;
}
2、静态变量的特点
-
静态变量的默认值规则和实例变量一样。
-
静态变量值是所有对象共享。
-
静态变量的值存储在方法区。
-
静态变量在本类中,可以在任意方法、代码块、构造器中直接使用。
-
如果权限修饰符允许,在其他类中可以通过“类名.静态变量”直接访问,也可以通过“对象.静态变量”的方式访问(但是更推荐使用类名.静态变量的方式)。
-
静态变量的get/set方法也静态的,当局部变量与静态变量重名时,使用“类名.静态变量”进行区分。
| 分类 | 数据类型 | 默认值 |
|---|---|---|
| 基本类型 | 整数(byte,short,int,long) | 0 |
| 浮点数(float,double) | 0.0 | |
| 字符(char) | ‘\u0000’ | |
| 布尔(boolean) | false | |
| 数据类型 | 默认值 | |
| 引用类型 | 数组,类,接口 | null |
演示:
package com.atguigu.keyword;
public class Employee {
private static int total;//这里私有化,在类的外面必须使用get/set方法的方式来访问静态变量
static String company; //这里缺省权限修饰符,是为了演示在类外面演示“类名.静态变量”的方式访问
private int id;
private String name;
{
//两个构造器的公共代码可以提前到非静态代码块
total++;
id = total; //这里使用total静态变量的值为id属性赋值
}
public Employee() {
}
public Employee(String name) {
this.name = name;
}
public void setId(int id) {
this.id = id;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static int getTotal() {
return total;
}
public static void setTotal(int total) {
Employee.total = total;
}
@Override
public String toString() {
return "Employee{company = " + company + ",id = " + id + " ,name=" + name +"}";
}
}
package com.atguigu.keyword;
public class TestStaticVariable {
public static void main(String[] args) {
//静态变量total的默认值是0
System.out.println("Employee.total = " + Employee.getTotal());
Employee c1 = new Employee("张三");
Employee c2 = new Employee();
System.out.println(c1);//静态变量company的默认值是null
System.out.println(c2);//静态变量company的默认值是null
System.out.println("Employee.total = " + Employee.getTotal());//静态变量total值是2
Employee.company = "尚硅谷";
System.out.println(c1);//静态变量company的值是尚硅谷
System.out.println(c2);//静态变量company的值是尚硅谷
//只要权限修饰符允许,虽然不推荐,但是也可以通过“对象.静态变量”的形式来访问
c1.company = "超级尚硅谷";
System.out.println(c1);//静态变量company的值是超级尚硅谷
System.out.println(c2);//静态变量company的值是超级尚硅谷
}
}
3、静态变量内存分析
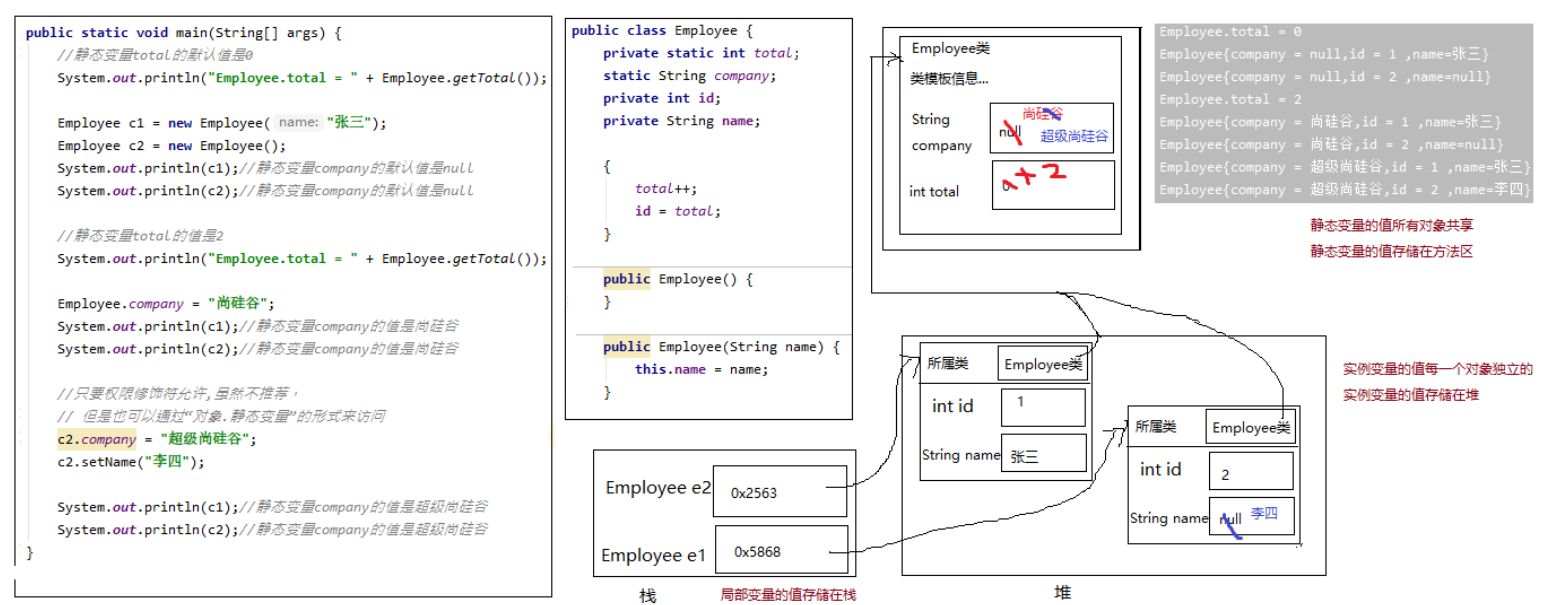
4、静态类变量和非静态实例变量、局部变量
- 静态类变量(简称静态变量):存储在方法区,有默认值,所有对象共享,生命周期和类相同,还可以有权限修饰符、final等其他修饰符
- 非静态实例变量(简称实例变量):存储在堆中,有默认值,每一个对象独立,生命周期每一个对象也独立,还可以有权限修饰符、final等其他修饰符
- 局部变量:存储在栈中,没有默认值,每一次方法调用都是独立的,有作用域,只能有final修饰,没有其他修饰符
- 注意下,局部变量是在
{}中的,形参,代码块{}中,而成员变量是类中方法外
7.1.3 静态方法
1、语法格式
有static修饰的成员方法就是静态方法。
【修饰符】 class 类{
【其他修饰符】 static 返回值类型 方法名(形参列表){
方法体
}
}
2、静态方法的特点
- 静态方法在本类的任意方法、代码块、构造器中都可以直接被调用。
- 只要权限修饰符允许,静态方法在其他类中可以通过“类名.静态方法“的方式调用。也可以通过”对象.静态方法“的方式调用(但是更推荐使用类名.静态方法的方式)。
- 静态方法可以被子类继承,但不能被子类重写。
- 静态方法的调用都只看编译时类型。
package com.atguigu.keyword;
public class Father {
public static void method(){
System.out.println("Father.method");
}
public static void fun(){
System.out.println("Father.fun");
}
}
package com.atguigu.keyword;
public class Son extends Father{
// @Override //尝试重写静态方法,加上@Override编译报错,去掉Override不报错,但是也不是重写
public static void fun(){
System.out.println("Son.fun");
}
}
package com.atguigu.keyword;
public class TestStaticMethod {
public static void main(String[] args) {
Father.method();
Son.method();//继承静态方法
Father f = new Son();
f.method();//执行Father类中的method
}
}
7.1.4 静态代码块
如果想要为静态变量初始化,可以直接在静态变量的声明后面直接赋值,也可以使用静态代码块。
1、语法格式
在代码块的前面加static,就是静态代码块。
【修饰符】 class 类{
static{
静态代码块
}
}
2、静态代码块的特点
每一个类的静态代码块只会执行一次。(注意区分普通的代码块)
静态代码块的执行优先于非静态代码块和构造器。
package com.atguigu.keyword;
public class Chinese {
// private static String country = "中国";
private static String country;
private String name;
{
System.out.println("非静态代码块,country = " + country);
}
static {
country = "中国";
System.out.println("静态代码块");
}
public Chinese(String name) {
this.name = name;
}
}
package com.atguigu.keyword;
public class TestStaticBlock {
public static void main(String[] args) {
Chinese c1 = new Chinese("张三");
Chinese c2 = new Chinese("李四");
}
}
3、静态代码块和非静态代码块
静态代码块在类初始化时执行,只执行一次
非静态代码块在实例初始化时执行,每次new对象都会执行
7.1.5 类初始化
(1)类的初始化就是为静态变量初始化。实际上,类初始化的过程时在调用一个()方法,而这个方法是编译器自动生成的。编译器会将如下两部分的所有代码,按顺序合并到类初始化()方法体中。
-
静态类成员变量的显式赋值语句
-
静态代码块中的语句
(2)每个类初始化只会进行一次,如果子类初始化时,发现父类没有初始化,那么会先初始化父类。
(3)类的初始化一定优先于实例初始化。
1、类初始化代码只执行一次
package com.atguigu.keyword;
public class Fu{
static{
System.out.println("Fu静态代码块1,a = " + Fu.a);
}
private static int a = 1;
static{
System.out.println("Fu静态代码块2,a = " + a);
}
public static void method(){
System.out.println("Fu.method");
}
}
package com.atguigu.keyword;
public class TestClassInit {
public static void main(String[] args) {
Fu.method();
}
}
2、父类优先于子类初始化
package com.atguigu.keyword;
public class Zi extends Fu{
static{
System.out.println("Zi静态代码块");
}
}
package com.atguigu.keyword;
public class TestZiInit {
public static void main(String[] args) {
Zi z = new Zi();
}
}
3、类初始化优先于实例初始化
package com.atguigu.keyword;
public class Fu{
static{
System.out.println("Fu静态代码块1,a = " + Fu.a);
}
private static int a = 1;
static{
System.out.println("Fu静态代码块2,a = " + a);
}
{
System.out.println("Fu非静态代码块");
}
public Fu(){
System.out.println("Fu构造器");
}
public static void method(){
System.out.println("Fu.method");
}
}
package com.atguigu.keyword;
public class Zi extends Fu{
static{
System.out.println("Zi静态代码块");
}
{
System.out.println("Zi非静态代码块");
}
public Zi(){
System.out.println("Zi构造器");
}
}
package com.atguigu.keyword;
public class TestZiInit {
public static void main(String[] args) {
Zi z1 = new Zi();
Zi z2 = new Zi();
}
}
7.1.6 静态和非静态的区别
1、本类中的访问限制区别
静态的类变量和静态的方法可以在本类的任意方法、代码块、构造器中直接访问。
非静态的实例变量和非静态的方法只能在本类的非静态的方法、非静态代码块、构造器中直接访问。
即:
- 静态直接访问静态,可以
- 非静态直接访问非静态,可以
- 非静态直接访问静态,可以
- 静态直接访问非静态,不可以
- 比如在main方法无法调用非静态的方法,只能调用实例身上的方法或者是静态方法
2、在其他类的访问方式区别
静态的类变量和静态的方法可以通过“类名.”的方式直接访问;也可以通过“对象.“的方式访问。(但是更推荐使用==”类名.”==的方式)
非静态的实例变量和非静态的方法只能通过“对象."方式访问。
3、this和super的使用
静态的方法和静态的代码块中,不允许出现this和super关键字,如果有重名问题,使用“类名.”进行区别。
非静态的方法和非静态的代码块中,可以使用this和super关键字。
7.1.7 静态导入
如果大量使用另一个类的静态成员,可以使用静态导入,简化代码。
import static 包.类名.静态成员名;
import static 包.类名.*;
演示:
package com.atguigu.keyword;
import static java.lang.Math.*;
public class TestStaticImport {
public static void main(String[] args) {
//使用Math类的静态成员
System.out.println(Math.PI);
System.out.println(Math.sqrt(9));
System.out.println(Math.random());
System.out.println("----------------------------");
System.out.println(PI);
System.out.println(sqrt(9));
System.out.println(random());
}
}
枚举
7.2.1 概述
某些类型的对象是有限的几个,这样的例子举不胜举:
- 星期:Monday(星期一)…Sunday(星期天)
- 性别:Man(男)、Woman(女)
- 月份:January(1月)…December(12月)
- 季节:Spring(春节)…Winter(冬天)
- 支付方式:Cash(现金)、WeChatPay(微信)、Alipay(支付宝)、BankCard(银行卡)、CreditCard(信用卡)
- 员工工作状态:Busy(忙)、Free(闲)、Vocation(休假)
- 订单状态:Nonpayment(未付款)、Paid(已付款)、Fulfilled(已配货)、Delivered(已发货)、Checked(已确认收货)、Return(退货)、Exchange(换货)、Cancel(取消)
枚举类型本质上也是一种类,只不过是这个类的对象是固定的几个,而不能随意让用户创建。
在JDK1.5之前,需要程序员自己通过特殊的方式来定义枚举类型。
在JDK1.5之后,Java支持enum关键字来快速的定义枚举类型。
7.2.2 JDK1.5之前
在JDK1.5之前如何声明枚举类呢?
- 构造器加private私有化
- 本类内部创建一组常量对象,并添加public static修饰符,对外暴露这些常量对象
示例代码:
public class Season{
public static final Season SPRING = new Season();
public static final Season SUMMER = new Season();
public static final Season AUTUMN = new Season();
public static final Season WINTER = new Season();
private Season(){
}
public String toString(){
if(this == SPRING){
return "春";
}else if(this == SUMMER){
return "夏";
}else if(this == AUTUMN){
return "秋";
}else{
return "冬";
}
}
}
public class TestSeason {
public static void main(String[] args) {
Season spring = Season.SPRING;
System.out.println(spring);
}
}
7.2.3 JDK1.5之后
1、enum关键字声明枚举
【修饰符】 enum 枚举类名{
常量对象列表
}
【修饰符】 enum 枚举类名{
常量对象列表;
其他成员列表;
}
示例代码:
package com.atguigu.enumeration;
public enum Week {
MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY,SATURDAY,SUNDAY
}
public class TestEnum {
public static void main(String[] args) {
Season spring = Season.SPRING;
System.out.println(spring);
}
}
2、枚举类的要求和特点
枚举类的要求和特点:
- 枚举类的常量对象列表必须在枚举类的首行,因为是常量,所以建议大写。
- 如果常量对象列表后面没有其他代码,那么“;”可以省略,否则不可以省略“;”。
- 编译器给枚举类默认提供的是private的无参构造,如果枚举类需要的是无参构造,就不需要声明,写常量对象列表时也不用加参数,
- 如果枚举类需要的是有参构造,需要手动定义,有参构造的private可以省略,调用有参构造的方法就是在常量对象名后面加(实参列表)就可以。
- 枚举类默认继承的是java.lang.Enum类,因此不能再继承其他的类型。
- JDK1.5之后switch,提供支持枚举类型,case后面可以写枚举常量名。
- 枚举类型如有其它属性,建议(不是必须)这些属性也声明为final的,因为常量对象在逻辑意义上应该不可变。
示例代码:
package com.atguigu.enumeration;
public enum Week {
MONDAY("星期一"),
TUESDAY("星期二"),
WEDNESDAY("星期三"),
THURSDAY("星期四"),
FRIDAY("星期五"),
SATURDAY("星期六"),
SUNDAY("星期日");
private final String description;
private Week(String description){
this.description = description;
}
@Override
public String toString() {
return super.toString() +":"+ description;
}
}
package com.atguigu.enumeration;
public class TestWeek {
public static void main(String[] args) {
Week week = Week.MONDAY;
System.out.println(week);
switch (week){
case MONDAY:
System.out.println("怀念周末,困意很浓");break;
case TUESDAY:
System.out.println("进入学习状态");break;
case WEDNESDAY:
System.out.println("死撑");break;
case THURSDAY:
System.out.println("小放松");break;
case FRIDAY:
System.out.println("又信心满满");break;
case SATURDAY:
System.out.println("开始盼周末,无心学习");break;
case SUNDAY:
System.out.println("一觉到下午");break;
}
}
}
3、枚举类型常用方法
1.String toString(): 默认返回的是常量名(对象名),可以继续手动重写该方法!
2.String name():返回的是常量名(对象名)
3.int ordinal():返回常量的次序号,默认从0开始
4.枚举类型[] values():返回该枚举类的所有的常量对象,返回类型是当前枚举的数组类型,是一个静态方法
5.枚举类型 valueOf(String name):根据枚举常量对象名称获取枚举对象
示例代码:
package com.atguigu.enumeration;
import java.util.Scanner;
public class TestEnumMethod {
public static void main(String[] args) {
Week[] values = Week.values();
for (int i = 0; i < values.length; i++) {
System.out.println((values[i].ordinal()+1) + "->" + values[i].name());
}
System.out.println("------------------------");
Scanner input = new Scanner(System.in);
System.out.print("请输入星期值:");
int weekValue = input.nextInt();
Week week = values[weekValue-1];
System.out.println(week);
System.out.print("请输入星期名:");
String weekName = input.next();
week = Week.valueOf(weekName);
System.out.println(week);
input.close();
}
}
技巧
- 快速输出println
sout
- 快速输出printf
souf
- 上一个值打印输出
String a = input.next();
soutv //后回车
//之后生成
System.out.println("a = " + a);
-
遍历数组
itar
for (int i = 0; i < nums.length; i++) { int num = nums[i]; } -
迭代可迭代的对象或数组
iter
for (int num : nums) { } -
for循环当中可以定义多个变量~
public int[] getAllPrimeNumber(){
if(value <=0) return new int[0];
int[] tempArray = new int[approximateNumberCount()];
for(int i =1,index = 0; i <= value; i++){
if(value % i == 0){
tempArray[index++] = i;
}
}
return tempArray;
}
- 查看调用方法的形参可以输入哪些,快捷键
Ctrl + p

- 让当前程序歇一会
Thread.sleep(5000);传入的为毫秒
- System.gc()通知gc来回收一下垃圾对象
- 如果不用构造器有相同代码,可以使用代码块功能
public abc(){
this.a = 100;
this.b = 10;
}
public abc(String a){
this.a = 100;
this.b = 666
}
//简写为
{
this.a = 100;
}
public abc(){
this.b = 10;
}
public abc(String a){
this.b = 666
}
包装类
- 将基本数据类型转化为包装类,这样子就可以调用对象里面的方法了
抽象类
- 描述对象应具有的行为
接口
- 规定标准
- 接口是具有多态的
注解
- Junit
- 可以帮助我们更好测试目前来的用处
异常
- 可以用try…catch捕捉运行
try{
可能发生xx异常的代码
}catch(异常类型1 e){
处理异常的代码1
}catch(异常类型2 e){
处理异常的代码2
}
....

-
如果一个方法可能会产生异常,但是没有能力或者不愿意去处理这个异常,可以在方法声明处用throws来声明抛出异常
- 如果进行了声明,但调用者没有进行异常处理,是无法编译通过的
-
顺带一提,不是所有的方法抛出的异常都会处理的
- IndexOutOfBoundsException,NullPointerException等都在编译时不会强制要求捕获异常,可以选择捕获处理异常,也可以选择不处理
-
练习
-
从键盘输入两个整数,求它们的商。尽量考虑和避免异常,无法避免的使用try…catch处理。
(1)如果用户输入的非整数,使用try…catch处理,并且让用户重新输入
可以使用
InputMismatchException或者Scanner实例对象的hasNextInt(2)如果用户输入的除数为0,请用户重新输入。
可以使用return或者break;跳出循环
-
多线程
-
并行:同一个时刻,同时处理多项任务
-
并发:同一个时刻,只能处理一个任务,其他任务交替执行
-
如果需要停止运行线程,有下面几种方法
- https://www.jb51.net/article/212591.htm
- interrupted(): 测试当前线程是否已经中断。该方法为静态方法,调用后会返回boolean值。不过调用之后会改变线程的状态,如果是中断状态调用的,调用之后会清除线程的中断状态。
- interrupt(): 标记线程为中断状态,不过不会中断正在运行的线程。
-
wait() 必须搭配 synchronized 来使用,wait()必须写到synchronized代码块里面(notify 方法也必须在synchronized代码块中使用)。脱离 synchronized 使用 wait() 会直接抛出异常
-
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能进入这个方法,其他线程在外面等着。
public synchronized void method(){
可能会产生线程安全问题的代码
}
- 同步代码块:synchronized 关键字可以用于某个区块前面,表示只对这个区块的资源实行互斥访问。
格式:
synchronized(同步锁){
需要同步操作的代码
}
- wait和notify
- wait释放占用的资源,并进入阻塞等待阶段
- notify通知阻塞等待阶段的线程,可以过来竞争资源
流
OutputStream out = socket.getOutputStream();
PrintStream ps = new PrintStream(out);
为什么有了OutputStream还需要new一个PrintStream ?
回答:
在给服务器发送数据时,确实可以直接使用 OutputStream 来进行写操作。但是,在这个例子中使用了 PrintStream 的主要原因可能是为了方便输出字符串。
PrintStream 是 OutputStream 的子类,它提供了一些方便的方法来处理字符数据。使用 PrintStream,你可以使用 println() 方法直接输出字符串,并且它会自动添加换行符。这在处理文本数据时比较方便,特别是在网络通信中。
注意
-
如果类中有引用数据类型,记得
new一下,否则会报java.lang.NullPointerException -
访问本类方法(非main)
package top.dreamlove.circle;
public class Circle {
double r;//圆半径
//求圆的面积
public double area(){
return r * r * Math.PI;
}
//周长
public double perimeter(){
return 2 * r * Math.PI;
}
//返回圆对象信息
public String getInfo(){
return "半径:" + r + "周长:" + perimeter() + "面积:" + area();
}
}
- main方法中的
String [] args其实写成String... args也是一样的,因为可变参数是jdk1.5才有的,而main方法jdk1.0就有了 - main方法当中可以获取系统编码
JDBC
- 引入包
MySQL5.7:mysql-connector-java-5.1.36-bin.jar
MySQL8.0:mysql-connector-java-8.0.19.jar
实现增删改查
增
package top.dreamlove.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TestJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
//把驱动类加载到内存中
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");//网络编程的Socket
String sql = "insert into t_department values(null,'测试部门数据','测试数据部门简介')";
PreparedStatement PreparedStatement = connection.prepareStatement(sql);//准备发送
int len = PreparedStatement.executeUpdate();//发送数据
System.out.println("影响的条数" + len);
PreparedStatement.close();
connection.close();//关闭连接
}
}
删
package top.dreamlove.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TESTJDBCDelete {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
String sql = "delete from t_department where did = 7";
PreparedStatement pst = connection.prepareStatement(sql);
int len = pst.executeUpdate();
System.out.println("执行成功" + len);
pst.close();
connection.close();
}
}
改
package top.dreamlove.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TestJDBCUpdate {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
String sql = "update t_department set description = '我是修改后的' where did = 7";
PreparedStatement pst = connection.prepareStatement(sql);
int len = pst.executeUpdate();
System.out.println("执行成功" + len);
pst.close();
connection.close();
}
}
查
- 结果值有一个元数据,对数据进行描述的信息,比如数据列有多少列,数据的列名称等
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();//获取结果集有几列
package top.dreamlove.jdbc;
import java.sql.*;
public class TestJDBCQuery {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
String sql = "select * from t_department";
PreparedStatement pst = connection.prepareStatement(sql);
ResultSet rst = pst.executeQuery();
//遍历
while (rst.next()){
int did = rst.getInt("did");
String dname = rst.getString("dname");
String desc = rst.getString("description");
System.out.println(did + dname + " 描述:" + desc);
//或者
Object did1 = rst.getInt(1);
Object dname1 = rst.getString(2);
Object desc1 = rst.getString(3);
System.out.println("did1 = " + did1);
System.out.println("dname1 = " + dname1);
System.out.println("desc1 = " + desc1);
}
rst.close();
connection.close();
}
}
sql拼接-使用?代替值
- 如果不适用?代替值,如果出现了很多个参数,很不方便
package top.dreamlove.problem;
import java.sql.*;
import java.util.Date;
import java.util.Scanner;
public class Demo1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Scanner input = new Scanner(System.in);
System.out.print("请输入姓名:");
String ename = input.next();//李四
System.out.print("请输入薪资:");
double salary = input.nextDouble();//15000
System.out.print("请输入出生日期:");
String birthday = input.next();//1990-1-1
System.out.print("请输入性别:");
char gender = input.next().charAt(0);//男
System.out.print("请输入手机号码:");
String tel = input.next();//13578595685
System.out.print("请输入邮箱:");
String email = input.next();//zhangsan@atguigu.com
input.close();
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
String sql = "INSERT INTO t_employee(ename,salary,birthday,gender,tel,email,hiredate)VALUES(?,?,?,?,?,?,?);";
PreparedStatement pst = connection.prepareStatement(sql);
//如果知道确切的类型可以指定set类型
// pst.setString(1,ename);//这里的1代表是第一个问号
//如果不知道可以通过setObject
pst.setObject(1,ename);//这里的1代表是第一个问号
pst.setObject(2,salary);
pst.setObject(3,birthday);
pst.setObject(4,gender + "");//Mysql中的char类型实际上是数据库
pst.setObject(5,tel);
pst.setObject(6,email);
pst.setObject(7, new Date());
int len = pst.executeUpdate();
System.out.println("执行成功" + len);
pst.close();
connection.close();
}
}
sql注入-防sql注入
- 如果我们采用拼接的写法,很容易sql注入,比如我们使用
SELECT * FROMt_employeeWHERE eid = + 用户输入的用户id,如果用户输入1 or 1=1,那么就会返回所有的数据
-- 将会返回所有的数据
SELECT * FROM `t_employee` WHERE eid = 1 or 1=1;
- 所以解决办法就是采用
?代替
package top.dreamlove.jdbc;
import java.sql.*;
import java.util.Scanner;
public class TestJDBCQuery1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
Scanner input = new Scanner(System.in);
System.out.print("请输入你要查询的员工的编号:");
String id = input.nextLine();
input.close();
String sql = "select * from t_employee where eid=?";
PreparedStatement pst = connection.prepareStatement(sql);
//通过?设置
pst.setString(1,id);
ResultSet rst = pst.executeQuery();
ResultSetMetaData metaData = rst.getMetaData();
int columnLength = metaData.getColumnCount();//获取数据有多少列
//遍历
while (rst.next()){
for(int i = 1;i<=columnLength;i++){
//输出所有数据
System.out.print(rst.getObject(i) + "\t");
}
System.out.println();
}
rst.close();
connection.close();
}
}
- 不适用?代替就会出现sql注入
package top.dreamlove.jdbc;
import java.sql.*;
import java.util.Scanner;
public class TestJDBCQuery1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");
Scanner input = new Scanner(System.in);
System.out.print("请输入你要查询的员工的编号:");
String id = input.nextLine();
input.close();
String sql = "select * from t_employee where eid = " + id;
PreparedStatement pst = connection.prepareStatement(sql);
ResultSet rst = pst.executeQuery();
ResultSetMetaData metaData = rst.getMetaData();
int columnLength = metaData.getColumnCount();//获取数据有多少列
//遍历
while (rst.next()){
for(int i = 1;i<=columnLength;i++){
//输出所有数据
System.out.print(rst.getObject(i) + "\t");
}
System.out.println();
}
rst.close();
connection.close();
}
}
图片上传
- 如果图片过大,限制了,需要到Mysql配置文件修改
max_allowed_packet变量的值
package top.dreamlove.problem;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Scanner;
public class Demo2 {
public static void main(String[] args) throws ClassNotFoundException, SQLException, FileNotFoundException {
Scanner input = new Scanner(System.in);
System.out.print("请输入用户名:");
String username = input.next();
System.out.print("请选择照片:");
String path = input.next();//这里没有图形化界面,只能输入路径,通过IO流读取图片的内容
System.out.print("请输入密码:");
String password = input.next();
//把驱动类加载到内存中
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");//网络编程的Socket
String sql = "insert into t_user values(null,?,?,?)";
PreparedStatement pst = connection.prepareStatement(sql);//准备发送
pst.setObject(1,username);
pst.setObject(2,new FileInputStream(path));//字节IO流表示二进制
pst.setObject(3,password);
int len = pst.executeUpdate();//发送数据
System.out.println("影响的条数" + len);
pst.close();
connection.close();//关闭连接
}
}
获取自增键值
- 传入一个枚举值为
Statement.RETURN_GENERATED_KEYS
import java.sql.*;
PreparedStatement pst = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);//准备发送
package top.dreamlove.problem;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.sql.*;
import java.util.Date;
import java.util.Scanner;
public class Demo3 {
public static void main(String[] args) throws ClassNotFoundException, SQLException, FileNotFoundException {
Scanner input = new Scanner(System.in);
System.out.print("请输入姓名:");
String ename = input.next();//李四
System.out.print("请输入薪资:");
double salary = input.nextDouble();//15000
System.out.print("请输入出生日期:");
String birthday = input.next();//1990-1-1
System.out.print("请输入性别:");
String gender = input.next();//男 mysql的gender是枚举类型,这里用String处理
System.out.print("请输入手机号码:");
String tel = input.next();//13578595685
System.out.print("请输入邮箱:");
String email = input.next();//zhangsan@atguigu.com
input.close();
//把驱动类加载到内存中
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");//网络编程的Socket
String sql = "INSERT INTO t_employee(ename,salary,birthday,gender,tel,email,hiredate)VALUES(?,?,?,?,?,?,?)";
PreparedStatement pst = connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);//准备发送
pst.setObject(1,ename); //这里的1,表示第1个?
pst.setObject(2,salary); //这里的2,表示第2个?
pst.setObject(3,birthday); //这里的3,表示第3个?
pst.setObject(4,gender); //这里的4,表示第4个?
pst.setObject(5,tel); //这里的5,表示第5个?
pst.setObject(6,email); //这里的6,表示第6个?
pst.setObject(7, new Date()); //这里的7,表示第7个?
int len = pst.executeUpdate();//发送数据
ResultSet generatedKeys = pst.getGeneratedKeys();
if(generatedKeys.next()){
//输出自增第一个的结果
System.out.println(generatedKeys.getObject(1));
}
System.out.println("影响的条数" + len);
pst.close();
connection.close();//关闭连接
}
}
批处理
- 注意不要把values写成了value
- 如何实现批处理?
- url中加
rewriteBatchedStatements=true
jdbc:mysql://localhost:3306/atguigu?serverTimezone=UTC&rewriteBatchedStatements=true - PreparedStatement对象调用
addBatch()先赞着这些数据,设置后后sql会重新编译下,生成一条完整的sqlexecuteBatch()设置一次,执行一次
package top.dreamlove.problem;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class Demo4 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
long start = System.currentTimeMillis();
//把驱动类加载到内存中
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC&rewriteBatchedStatements=true";
Connection connection = DriverManager.getConnection(url,"root","root");//网络编程的Socket
String sql = "insert into t_department values(null,?,?)";
PreparedStatement pst = connection.prepareStatement(sql);//准备发送
//批处理
for(int i = 1 ; i <= 1000;i++){
pst.setObject(1,"测试" + i);
pst.setObject(2,"测试简介" + i);
pst.addBatch();
}
int[] lenList = pst.executeBatch();//发送数据
long end = System.currentTimeMillis();
System.out.println("耗费时间" + (end - start));
System.out.println("影响的条数" + lenList.length);
pst.close();
connection.close();//关闭连接
}
}
事物处理
- JDBC如何管理事务?
- mysql默认是自动提交事务,每执行一条语句成功后,自动提交。需要开启手动提交模式。
Connection连接对象.setAutoCommit(false);//取消自动提交模式,开始手动提交模式- sql执行成功,别忘了提交事务
Connection连接对象.commit(); - sql执行失败,回滚事务
Connection连接对象.rollback();
- sql执行成功,别忘了提交事务
package top.dreamlove.problem;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class Demo5 {
public static void main(String[] args) throws Exception {
//把驱动类加载到内存中
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
String url = "jdbc:mysql://127.0.0.1:3306/atguigu?serverTimezone=UTC";
Connection connection = DriverManager.getConnection(url,"root","root");//网络编程的Socket
connection.setAutoCommit(false);
String sql1 = "update t_department set description = 'xxx' where did = 2";
String sql2 = "update t_department set1 description = 'xxx' where did = 3";
PreparedStatement pst1 = connection.prepareStatement(sql1);//准备发送
PreparedStatement pst2 = connection.prepareStatement(sql2);//准备发送
try{
pst1.executeUpdate();
pst2.executeUpdate();
connection.commit();//没有问题才提交
}catch (Exception e){
//执行失败
connection.rollback();//回滚操作
System.out.println("执行回滚操作");
}
pst1.close();
pst2.close();
//这里习惯上,在cLose之前,,会把连接重新设置为自动提交模式
connection.setAutoCommit(true);
connection.close();//关闭连接
}
}
数据库连接池
-
连接对象的缓冲区。负责申请,分配管理,释放连接的操作。
-
为什么要用
- 如果不使用数据库连接池,每次都通过DriverManager获取新连接,用完直接抛弃断开,连接的利用率太低,太浪费。
- 对于数据库服务器来说,压力太大了。我们数据库服务器和Java程序对连接数也无法控制,很容易导致数据库服务器崩溃。
使用阿里的德鲁伊
-
引入jar
-
编写配置文件
- src下加一个druid.properties文件
- 或者在模块根目录下,再建立一个文件夹叫config,把config文件夹设置为源代码文件夹,再在config文件夹建一个druid.properties文件
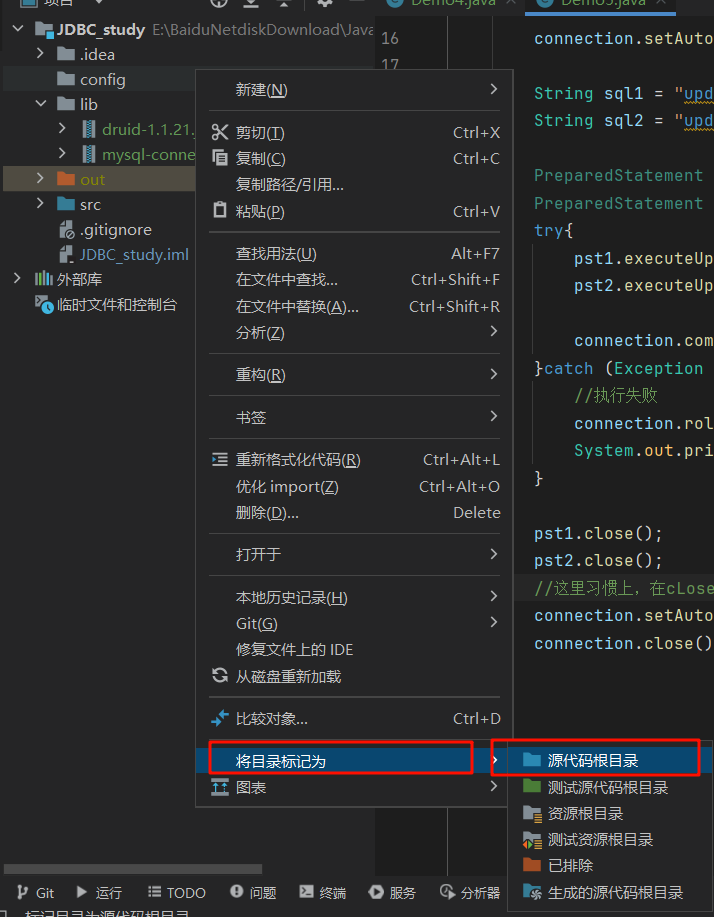
-
填写内容
#key=value
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/atguigu?serverTimezone=UTC&rewriteBatchedStatements=true
username=root
password=123456
initialSize=5
maxActive=10
maxWait=1000
- 从数据库连接池中获取连接
- 通过德鲁伊的数据库连接的工厂类创建数据库连接池,再从池中获取连接
- 加载器加载资源文件
package top.dreamlove.pool;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.util.Properties;
public class TestDruid {
public static void main(String[] args) throws Exception {
//加载配置文件
Properties properties = new Properties();
properties.load(TestDruid.class.getClassLoader().getResourceAsStream("druid.properties"));
DataSource ds = DruidDataSourceFactory.createDataSource(properties);//创建数据库连接池
for(int i = 1 ; i<= 11;i++){
try{
//获取数据库连接池
Connection con = ds.getConnection();
System.out.println(i + "连接池" + con);
}catch (Exception e){
e.printStackTrace();
}
}
}
}
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:”DataSource-” + System.identityHashCode(this) | |
| jdbcUrl | 连接数据库的url,不同数据库不一样。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/使用ConfigFilter | |
| driverClassName | 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义: 1)Destroy线程会检测连接的间隔时间2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
DAO层
- 把访问数据库的代码封装起来,这些类称为DAO,相当与是一个数据访问接口,夹在业务逻辑与数据库资源中间
建立bean包
- 里面的内容是数据库表中的字段,具有构造方法,和getter和setter为的是返回对应的对象(还可以有toString方法,方便输出查看)
建立dao包
-
里面为impl和对应的DAO包
-
DAO包为接口,为应该具有的方法,比如增加,修改,删除
-
impl为实现对应DAO包的方法
- 除了每一个DAO包的实现外,还需要有一个基础的DAO
BaseDAOImpl,用做共同的impl父类,提供基础的方法
- 除了每一个DAO包的实现外,还需要有一个基础的DAO
-
使用Dbutils
commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化jdbc编码的工作量,同时也不会影响程序的性能。
其中QueryRunner类封装了SQL的执行,是线程安全的。
(1)可以实现增、删、改、查、批处理、
(2)考虑了事务处理需要共用Connection。
(3)该类最主要的就是简单化了SQL查询,它与ResultSetHandler组合在一起使用可以完成大部分的数据库操作,能够大大减少编码量。
(4)不需要手动关闭连接,runner会自动关闭连接,释放到连接池中
(1)更新
public int update(Connection conn, String sql, Object… params) throws SQLException:用来执行一个更新(插入、更新或删除)操作。
…
(2)插入
public T insert(Connection conn,String sql,ResultSetHandler rsh, Object… params) throws SQLException:只支持INSERT语句,其中 rsh - The handler used to create the result object from the ResultSet of auto-generated keys. 返回值: An object generated by the handler.即自动生成的键值
…
(3)批处理
public int[] batch(Connection conn,String sql,Object[][] params)throws SQLException: INSERT, UPDATE, or DELETE语句
public T insertBatch(Connection conn,String sql,ResultSetHandler rsh,Object[][] params)throws SQLException:只支持INSERT语句
…
(4)使用QueryRunner类实现查询
public Object query(Connection conn, String sql, ResultSetHandler rsh,Object… params) throws SQLException:执行一个查询操作,在这个查询中,对象数组中的每个元素值被用来作为查询语句的置换参数。该方法会自行处理 PreparedStatement 和 ResultSet 的创建和关闭。
…
ResultSetHandler接口用于处理 java.sql.ResultSet,将数据按要求转换为另一种形式。ResultSetHandler 接口提供了一个单独的方法:Object handle (java.sql.ResultSet rs)该方法的返回值将作为QueryRunner类的query()方法的返回值。
该接口有如下实现类可以使用:
- BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。
- BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。
- ScalarHandler:查询单个值对象
- MapHandler:将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。
- MapListHandler:将结果集中的每一行数据都封装到一个Map里,然后再存放到List
- ColumnListHandler:将结果集中某一列的数据存放到List中。
- KeyedHandler(name):将结果集中的每一行数据都封装到一个Map里,再把这些map再存到一个map里,其key为指定的key。
- ArrayHandler:把结果集中的第一行数据转成对象数组。
- ArrayListHandler:把结果集中的每一行数据都转成一个数组,再存放到List中。
使用Dbutils组件封装BaseDAOImpl
- JDBCTools.java
package top.dreamlove.tools;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class JDBCTools {
private static DataSource ds;
static {
Properties pro = new Properties();
try{
pro.load(JDBCTools.class.getClassLoader().getResourceAsStream("druid.properties"));
ds = DruidDataSourceFactory.createDataSource(pro);
}catch (Exception e){
e.printStackTrace();
}
}
private static ThreadLocal<Connection> threadLocal = new ThreadLocal<>();
//获取连接
public static Connection getConnection() throws SQLException {
Connection connection = threadLocal.get();
//每一个线程调用这句代码,都会到自己的ThreadLocalMap中,以threadLocal对象为key,找到value
//如果value为空,说明当前线程还未获取过Connection对象,那么就从连接池中拿一个数据库连接对象给你
//并且通过threadLocal的set方法把Connection对象放到当前线程ThreadLocalMap中
if(connection == null){
connection = ds.getConnection();
//通过threadLocal的set方法把Connection对象放到当前线程ThreadLocalMap中
threadLocal.set(connection);
}
return connection;
}
public static void freeConnection() throws SQLException {
Connection connection = threadLocal.get();
if(connection != null){
connection.setAutoCommit(false);
threadLocal.remove();
connection.close();
}
}
}
- BaseDAOImpl.java
package top.dreamlove.dao;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import top.dreamlove.tools.JDBCTools;
import java.sql.SQLException;
import java.util.List;
public class BaseDAOImpl {
private QueryRunner queryRunner = new QueryRunner();
/**
* 通用的增删改的方法
* @param sql String 要执行的sql
* @param args Object... 如果sql中有?,就传入对应个数的?要设置值
* @return int 执行的结果
*/
protected int update(String sql,Object... args) {
try {
return queryRunner.update(JDBCTools.getConnection(),sql,args);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
/**
* 查询单个对象的方法
* @param clazz Class 记录对应的类类型
* @param sql String 查询语句
* @param args Object... 如果sql中有?,即根据条件查询,可以设置?的值
* @param <T> 泛型方法声明的泛型类型
* @return T 一个对象
*/
protected <T> T getBean(Class<T> clazz, String sql, Object... args){
return getList(clazz,sql,args).get(0);
}
/**
* 通用查询多个对象的方法
* @param clazz Class 记录对应的类类型
* @param sql String 查询语句
* @param args Object... 如果sql中有?,即根据条件查询,可以设置?的值
* @param <T> 泛型方法声明的泛型类型
* @return List<T> 把多个对象放到了List集合
*/
protected <T> List<T> getList(Class<T> clazz, String sql, Object... args){
try {
return queryRunner.query(JDBCTools.getConnection(),sql,new BeanListHandler<T>(clazz),args);
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
Servlet
- 和服务端进行交互,完成客户的请求沟通
HelloServlet
Servlet(Server Applet)作为服务器端的一个组件,它的本意是“服务器端的小程序”。
- Servlet的实例对象由Servlet容器负责创建;
- Servlet的方法由容器在特定情况下调用;
- Servlet容器会在Web应用卸载时销毁Servlet对象的实例。
-
步骤
-
新建一个普通类
-
实现接口Servlet
<html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>管理员页面</title> </head> <body> <a href="hello">点击我跳转发送请求</a> </body> </html>- 实现接口中的所有抽象方法
- 为HelloServlet设置访问路径
- 注意:web.xml因为有约束文件,所以不可以乱写了,并且还约束了顺序
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <servlet> <servlet-name>abc</servlet-name> <servlet-class>top.dreamlove.servlet.HelloServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>abc</servlet-name> <url-pattern>/hello</url-pattern> </servlet-mapping> </web-app> -
-
注意点
- 网页必须要在web目录下(不可以放在WEB-INF下),暂时也不可以放置在目录下(后面就可以)
- web.xml中的url-pattern的值必须要以/开头
- 请求url中暂时不能以/开头
找不到servlet解决办法

作用
-
接收请求 【解析请求报文中的数据:请求参数】
-
处理请求 【DAO和数据库交互】
-
完成响应 【设置响应报文】

servlet生命周期
-
怎么知道创建了?创建一个构造器可以知道
-
servlet可以设置为服务器启动的时候就创建其对象
- 在当前servlet的设置一个标签
load-on-startup,值越小越先启动(值为非0整数)
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <servlet> <servlet-name>abc</servlet-name> <servlet-class>top.dreamlove.servlet.HelloServlet</servlet-class> <!--设置自启动--> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>abc</servlet-name> <url-pattern>/hello</url-pattern> </servlet-mapping> </web-app> - 在当前servlet的设置一个标签
init
- 只在创建对象时候执行一次,以后再接收到请求,就不会执行了
service
- 接口被调用的时候执行
destroy
- 在web应用被卸载的时候,会被执行改方法
第二种创建servlet的方法-GenericServlet

package top.dreamlove.servlet;
import javax.servlet.GenericServlet;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import java.io.IOException;
public class MyFirstServlet extends GenericServlet {
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
System.out.println("这是我第一个Servlet");
}
}
第三种创建servlet-HttpServlet
- HttpServlet
- 主要功能是实现service方法,然后对请求进行分发的操作(不同的请求方式调用不同的方法)
- 如get请求调用doGet方法
- post请求调用doPost方法
package top.dreamlove.servlet;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.annotation.WebServlet;
import java.io.IOException;
public class LoginServlet extends HttpServlet {
//get请求
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("你好,世界,我是LoginServlet");
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
ServletConfig
- 一个Servlet对象对应唯一的一个ServletConfig配置对象
- ServletConfig对象如何获得?
- 在init方法的形参位置
- ServletConfig是在当前Servlet进行初始化的时候,传递给init方法的
- 功能
- 获取Servlet名称:web.xml中配置servlet-name的值
- 获取全局上下文ServletContext对象
- 获取Servlet初始化参数
- 从web.xml设置的初始化参数
public void init(ServletConfig servletConfig) throws ServletException {
System.out.println("执行了初始化操作");
//获取Servletname
String name = servletConfig.getServletName();
System.out.println("name = " + name);
//获取ServletContext
ServletContext context = servletConfig.getServletContext();
System.out.println("context = " + context);
//获取web.xml的局部配置参数
String path = servletConfig.getInitParameter("path");
System.out.println(path);
}
ServletContext
- 全局上下文对象:一个web项目只有一个ServletContext对象
- 功能
-
获取项目的上下文路径
getContextPath()
-
获取虚拟路径所映射的本地真实路径(根据相对路径获取绝对路径)
getRealPath()
-
获取WEB应用程序的全局初始化参数(基本不用)
- 也就是在web.xml配置文件中的以
<content-param>的标签 getInitParameter(String key)
- 也就是在web.xml配置文件中的以
-
作为域对象共享数据
- 什么是域对象
- 在一定的作用域范围内共享的对象(A对某一个对象设置了数据,在B中也可以获取到)
- 设置:
setAttribute(String key,Object value) - 获取:
getAttribute(key)
- 什么是域对象
-
getContextPath()-获取项目的上下文路径
String contextPath = servletContext.getContextPath();// 获取项目的上下文路径
System.out.println("contextPath = " + contextPath);
getRealPath()-(根据相对路径获取绝对路径)
- 不管有没有这个文件或者文件夹,都会返回路径,只是路径而已
String upload = servletContext.getRealPath("upload");
System.out.println("upload = " + upload);
获取WEB应用程序的全局初始化参数
- 顾名思义,也就是全部Servlet可以访问的初始化参数
web.xml
<web-app>
<!-- Web应用初始化参数 -->
<context-param>
<param-name>ParamName</param-name>
<param-value>ParamValue</param-value>
</context-param>
</web-app>
java代码
String paramKey = servletContext.getInitParameter("ParamKey");
System.out.println("paramKey = " + paramKey);
作为域对象共享数据
servletContext.setAttribute("globalParams","这是全局的参数");
Object globalParams = servletContext.getAttribute("globalParams");
System.out.println("globalParams = " + globalParams);
HttpServletRequest
获取请求头的信息
request.getHeader(String key)- 传入指定的请求头,返回请求头字符串
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获取请求头信息
String header1 = request.getHeader("Referer");
System.out.println("header1 = " + header1);
}
获取URL地址信息
request.getRequestContext()//获取上下文路径request.getServerName()request.getServePort()request.getMethod()
//获取url地址参数
String path = request.getContextPath();//获取上下文路径
System.out.println("path = " + path);
int serverPort = request.getServerPort();//获取请求的端口号
System.out.println("serverPort = " + serverPort);
String serverName = request.getServerName();//获取请求的获取主机名
System.out.println("serverName = " + serverName);
String scheme = request.getScheme();//获取请求的协议
System.out.println("scheme = " + scheme);
获取请求头信息
获取请求的参数
request.getParameter(String key)//根据key值返回一个valuerequest.getParameterValues(String key)//根据key值返回多个value- 原来get请求是支持获取多个传参的~
request.getParameterMap()//将整个表单的所有数据都放在map集合内
String username = request.getParameter("username");
System.out.println("username = " + username);
String password = request.getParameter("password");
System.out.println("password = " + password);
String gender = request.getParameter("gender");
System.out.println("gender = " + gender);
String[] soccerTeams = request.getParameterValues("soccerTeam");
for(String soccerTeam : soccerTeams){
System.out.println("soccerTeam = " + soccerTeam);
}
使用BeanUtils
- 要求Map字段要和bean包的相同
- 需要这几个包
- 代码
Map<String, String[]> parameterMap = request.getParameterMap();
Users users = new Users();
try {
BeanUtils.populate(users,parameterMap);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
}
请求的转发
- 转发
- 交给另外一个Servlet处理
- 重定向
- 网页跳转
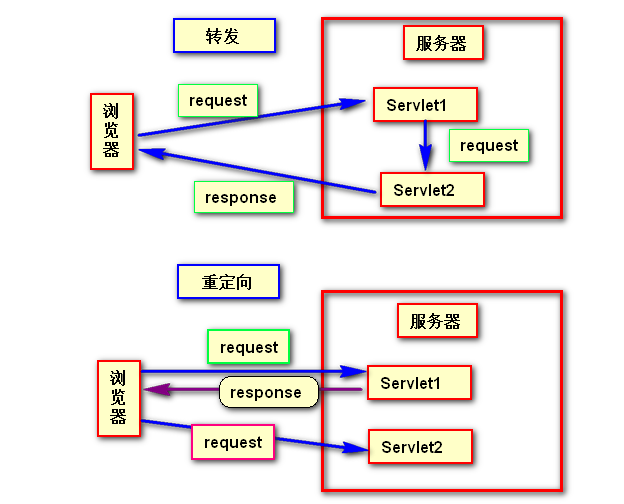
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//读取参数
String name = req.getParameter("name");
System.out.println("第一个name = " + name);
String sex = req.getParameter("sex");
System.out.println("第一个sex = " + sex);
//添加请求域参数
req.setAttribute("hobby","吃饭");
//转发给第二个 需要在web.xml注册
req.getRequestDispatcher("forwardSecond").forward(req,resp);
}
重定向
protected void doGet(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException {
//1.调用HttpServletResponse对象的sendRedirect()方法
//2.传入的参数是目标资源的虚拟路径
response.sendRedirect("index.html");
}
response
//设置HttpServletResponse使用utf-8编码
resp.setCharacterEncoding("utf-8");
//通知浏览器使用utf-8编码
resp.setHeader("Content-Type","text/html;character=utf-8");
web项目的路径问题
-
url(URL)
- 统一资源定位符(从整个网络环境中找一个资源)
- http://localhost:9999/day06_servlet_war_exploded/login.html
http://localhost:9999也是url
-
uri(URI)
- 统一资源标识符(从当前项目下找一个资源)
- http://localhost:9999/day06_servlet_war_exploded/login.html
/day06_servlet_war_exploded/login.html就是URI
-
在web项目中,路径前面用
/,就是采用绝对路径
Thymeleaf
- 添加这些包
- 配置全局变量
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!-- 在上下文参数中配置视图前缀和视图后缀 -->
<context-param>
<param-name>view-prefix</param-name>
<param-value>/pages</param-value>
</context-param>
<context-param>
<param-name>view-suffix</param-name>
<param-value>.html</param-value>
</context-param>
</web-app>
- 编写
ViewBaseServlet
package top.dreamlove;
import org.thymeleaf.TemplateEngine;
import org.thymeleaf.context.WebContext;
import org.thymeleaf.templatemode.TemplateMode;
import org.thymeleaf.templateresolver.ServletContextTemplateResolver;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class ViewBaseServlet extends HttpServlet {
private TemplateEngine templateEngine;
@Override
public void init() throws ServletException {
// 1.获取ServletContext对象
ServletContext servletContext = this.getServletContext();
// 2.创建Thymeleaf解析器对象
ServletContextTemplateResolver templateResolver = new ServletContextTemplateResolver(servletContext);
// 3.给解析器对象设置参数
// ①HTML是默认模式,明确设置是为了代码更容易理解
templateResolver.setTemplateMode(TemplateMode.HTML);
// ②设置前缀
String viewPrefix = servletContext.getInitParameter("view-prefix");
templateResolver.setPrefix(viewPrefix);
// ③设置后缀
String viewSuffix = servletContext.getInitParameter("view-suffix");
templateResolver.setSuffix(viewSuffix);
// ④设置缓存过期时间(毫秒)
templateResolver.setCacheTTLMs(60000L);
// ⑤设置是否缓存
templateResolver.setCacheable(true);
// ⑥设置服务器端编码方式
templateResolver.setCharacterEncoding("utf-8");
// 4.创建模板引擎对象
templateEngine = new TemplateEngine();
// 5.给模板引擎对象设置模板解析器
templateEngine.setTemplateResolver(templateResolver);
}
protected void processTemplate(String templateName, HttpServletRequest req, HttpServletResponse resp) throws IOException {
// 1.设置响应体内容类型和字符集
resp.setContentType("text/html;charset=UTF-8");
// 2.创建WebContext对象
WebContext webContext = new WebContext(req, resp, getServletContext());
// 3.处理模板数据
templateEngine.process(templateName, webContext, resp.getWriter());
}
}
- html设置为如下
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<h2 th:text="${msg}">放服务器传递过来的字段为msg的数据</h2>
</body>
</html>
- 如果出现了
org.apache.catalina.LifecycleException: Failed to start component,看看是不是lib包没有放在WEB-INF目录下的问题

基本语法
- html页面需要首先设置
<html xmlns:th="http://www.thymeleaf.org">
- 拿到URL上下文路径
@{/} - 设置上下文的值
- 默认的从请求域中获取
<p th:属性名="${服务器设置的属性变量}">原始网页内容</p>
- 设置服务端传递过来参数
- 默认的从请求域中获取
<p th:属性名="${服务器设置的属性变量}">原始网页内容</p>
- 设置发送变量
- http://localhost:8080/day03_thymeleaf_war_exploded/hello?id=100&name=李白&age=100
<a th:href="@{/hello(id=100,name='李白',age=100)}">跳转2</a>
操作请求域
Servlet中代码:
String requestAttrName = "helloRequestAttr";
String requestAttrValue = "helloRequestAttr-VALUE";
request.setAttribute(requestAttrName, requestAttrValue);
Thymeleaf表达式:
<p th:text="${helloRequestAttr}">request field value</p>
操作应用域
Servlet中代码:
String requestAttrName = "helloRequestAttr";
String requestAttrValue = "helloRequestAttr-VALUE";
ServletContext application = request.getServletContext();
application.setAttribute(requestAttrName,requestAttrValue)
Thymeleaf表达式:
<p th:text="${application.helloRequestAttr}">request field value</p>
获取请求参数
- 语法
${param.参数名}
-
既可以获取多个,也可以获取单个
-
单个
<h1 th:text="${param.id + param.name + param.age}"></h1>
//访问http://localhost:8080/day03_thymeleaf_war_exploded/params?id=100&name=李白&age=100
//输出100李白100
- 多个
<h1 th:text="${param.hobby}"></h1>
//访问http://localhost:8080/day03_thymeleaf_war_exploded/params?hobby=吃饭&hobby=睡觉
//输出 [吃饭, 睡觉]
如果需要精准获取,就用
<h1 th:text="${params.hobby[0]}"></h1>
内置对象
- 所谓内置对象其实就是在Thymeleaf的表达式中可以直接使用的对象
基本内置对象
#request就是Servlet中的HttpServletRequest对象#response就是Servlet中的HttpServletResponse对象
<h3>表达式的基本内置对象</h3>
<p th:text="${#request.getContextPath()}">调用#request对象的getContextPath()方法</p>
<p th:text="${#request.getAttribute('helloRequestAttr')}">调用#request对象的getAttribute()方法,读取属性域</p>
公共内置对象

ognl-分支
- if
<table>
<tr>
<th>员工编号</th>
<th>员工姓名</th>
<th>员工工资</th>
</tr>
<tr th:if="${#lists.isEmpty(employeeList)}">
<td colspan="3">抱歉!没有查询到你搜索的数据!</td>
</tr>
<tr th:if="${not #lists.isEmpty(employeeList)}">
<td colspan="3">有数据!</td>
</tr>
<tr th:unless="${#lists.isEmpty(employeeList)}">
<td colspan="3">有数据!</td>
</tr>
</table>
- switch
<h3>测试switch</h3>
<div th:switch="${user.memberLevel}">
<p th:case="level-1">银牌会员</p>
<p th:case="level-2">金牌会员</p>
<p th:case="level-3">白金会员</p>
<p th:case="level-4">钻石会员</p>
</div>
- 迭代(遍历)
<!--遍历显示请求域中的teacherList-->
<table border="1" cellspacing="0" width="500">
<tr>
<th>编号</th>
<th>姓名</th>
</tr>
<tbody th:if="${#lists.isEmpty(teacherList)}">
<tr>
<td colspan="2">教师的集合是空的!!!</td>
</tr>
</tbody>
<!--
集合不为空,遍历展示数据
-->
<tbody th:unless="${#lists.isEmpty(teacherList)}">
<!--
使用th:each遍历
用法:
1. th:each写在什么标签上? 每次遍历出来一条数据就要添加一个什么标签,那么th:each就写在这个标签上
2. th:each的语法 th:each="遍历出来的数据,数据的状态 : 要遍历的数据"
3. status表示遍历的状态,它包含如下属性:
index 遍历出来的每一个元素的下标
count 遍历出来的每一个元素的计数
-->
<tr th:each="teacher,status : ${teacherList}">
<td th:text="${status.count}">这里显示编号</td>
<td th:text="${teacher.teacherName}">这里显示老师的名字</td>
</tr>
</tbody>
</table>
小练习
- 反射
Class c = this.getClass();
Method method = c.getDeclaredMethod('要调用的方法',Class参数1,Class参数2,Class参数3,....);
method.setAccessible(true);//暴力访问
method.invoke(由谁调用:this,参数1,参数2)
- 解决乱码问题
request.setCharacterEncoding("uft-8")
Cookie和Session
- Cookie(客户端的会话技术)
- Session(服务端的存储技术)
Cookie
如何将数据保存到Cookie中
- 一旦cookie被保存到客户端,在以后的每次请求中都会带着所有的cookie
- 此时添加cookie被称为瞬时cookie,浏览器关闭cookie就消失
//添加Cookie
Cookie testCooke = new Cookie("adminKey","adminValue");
Cookie testCooke1 = new Cookie("adminKey1","adminValue3");
Cookie testCooke2 = new Cookie("adminKey2","adminValue4");
//设置Cookie
resp.addCookie(testCooke1);
resp.addCookie(testCooke2);
resp.addCookie(testCooke);
如何将数据从Cookie中取出来
//获取Cookie
Cookie[] reqCookies = req.getCookies();
Cookie中的数据的有效时间
- 在添加到响应之前,可以设置有效时间
//添加Cookie
Cookie testCooke = new Cookie("adminKey","adminValue");
//设置Cookie时间
testCooke.setMaxAge(60);//单位为秒
设置Cookie的携带条件
- 比如为user设置了20个Cookie,为book设置了20个Cookie,我们不希望访问任意的时候都携带上,就可以设置携带条件
- 比如只希望
xxxx/user下的URI可以访问,就需要设置下方数据
testCooke.setPath(req.getContextPath() + "/user");
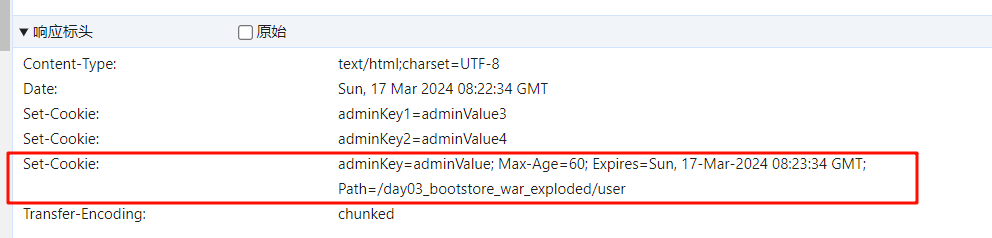
Session
- 数据存储在服务器端
- 服务器端的会话从第一次获得HttpSession对象开始的,直到HttpSession对象销毁结束
- 服务器会为每一个客户端创建对应的Session
- 服务器是如何办到客户端和session对应关系?
- 是通过cookie办到的!session是依赖于cookie
- 当客户端第一次访问服务器,调用
getSession(),新建一个session对象,并且设置一个cookie给浏览器 - 当客户端第二次访问服务器,调用
getSession(),就去获得请求中的jsessionid这个Cookie,通过Cookie判断
- 会话什么时候结束?
- 客户端关闭(jsessionid这个Cookie消息)
- 强制失效
invalidate
- 自动失效(达到最大空闲时间)
- 默认是半小时,可以通过
setMaxInactiveInterval
- 默认是半小时,可以通过
//获取session对象
HttpSession session = req.getSession();
//设置
session.setAttribute("sessionMsg","value");
//获取
Object sessionMsg = session.getAttribute("sessionMsg");
//移除
session.removeAttribute("sessionMsg");
//销毁session对象(强制失效)
session.invalidate()
//设置空闲失效 60秒
session.setMaxInactiveInterval(60);
后台响应JSON
- 使用JSON数据作为响应数据(JSON格式的字符串)
- 可以借助
gson帮助我们将JAVA对象转换为json字符串
Gson gson = new Gson();
Books books = new Books("a","b",20.0,10,30,"f");
String s1 = gson.toJson(books);
System.out.println("s1 = " + s1);// { title:'xxx',author:'xxx' }
//将Map集合作为响应数据
Map<String,Books> map = new HashMap<>();
map.put("one1",new Books("a","b",20.0,10,30,"f"));
map.put("one2",new Books("a","b",20.0,10,30,"f"));
map.put("one3",new Books("a","b",20.0,10,30,"f"));
String s2 = gson.toJson(map);
System.out.println("s2 = " + s2);// { one1:{},one2:{},one3:{}, }
//List集合
List<Books> booksList = new ArrayList<>();
booksList.add(new Books("a","b",20.0,10,30,"f"));
booksList.add(new Books("a","b",20.0,10,30,"f"));
booksList.add(new Books("a","b",20.0,10,30,"f"));
String s3 = gson.toJson(booksList);
System.out.println("s3 = " + s3);//[{ title:'xxx',author:'xxx' },{},{},]
PrintWriter writer = resp.getWriter();
writer.write(s2);
CommonResult
- 设置异步请求响应结果的格式
Maven
Maven之Helloworld
- Maven工程目录结构约束
- 项目名
- src(书写源代码)
- main【书写主程序代码】
- java【书写java源代码】
- resources【书写配置文件代码】
- test(书写测试代码)
- java(书写测试代码)
- main【书写主程序代码】
- pom.xml(书写Maven配置)
- src(书写源代码)
Maven的坐标【重要】
-
作用:使用坐标引入jar包
- 一对多的关系
-
坐标由g-a-v组成
[1]groupId:公司或组织的域名倒序+当前项目名称
[2]artifactId:当前项目的模块名称
[3]version:当前模块的版本
-
注意
- g-a-v:本地仓库jar包位置
- a-v:jar包全名
坐标应用
- 坐标参考网址:http://mvnrepository.com
Maven的依赖管理
-
依赖语法
<scope>compile- 【默认值】:在main、test、Tomcat【服务器】下均有效。
test- 只能在test目录下有效
- 比如junit
- 只能在test目录下有效
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.2</version> <scope>test</scope> </dependency> </dependencies>provided- 在main、test下均有效,Tomcat【服务器】无效。
- servlet-api(因为Tomcat服务器有了,如果再提供就冲突了)
-
依赖传递性
-
路径最短者有先【就近原则】
-
先声明者优先
-
注意:Maven可以自动解决jar包之间的依赖问题
-
-
统一管理版本号
<properties>
<spring-version>5.3.17</spring-version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring-version}</version>
</dependency>
</dependencies>
Maven继承和聚合
继承
-
为什么需要继承?
- 如果子工程大部分都共同使用jar包,可以提取父工程中,使用继承原理在子工程中使用
- 父工程打包方式,必须是pom方式
-
第一种:在父工程中的pom.xml中导入jar包,在子工程中统一使用。【不足:所有子工程强制引入父工程jar包】
<packaging>pom</packaging>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
- 第二种:在父工程中导入jar包【pom.xml】
- 注意标签使用
dependencyManagement
- 注意标签使用
<packaging>pom</packaging>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</dependencyManagement>
- 在子工程引入父工程的相关jar包
<relativePath>../pom.xml</relativePath>- 注意:在子工程中,不能指定版本号
<parent>
<artifactId>maven_demo</artifactId>
<groupId>com.atguigu</groupId>
<version>1.0-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
</dependencies>
聚合
为什么使用Maven的聚合
- 优势:只要将子工程聚合到父工程中,就可以实现效果:安装或清除父工程时,子工程会进行同步操作。
- 注意:Maven会按照依赖顺序自动安装子工程
<modules>
<module>maven_helloworld</module>
<module>HelloFriend</module>
<module>MakeFriend</module>
</modules>
Maven在IDEA创建
- 目录结构如下

- 设置项目结构
- 修改为

- 修改这个
- 设置
- 添加Tomcat
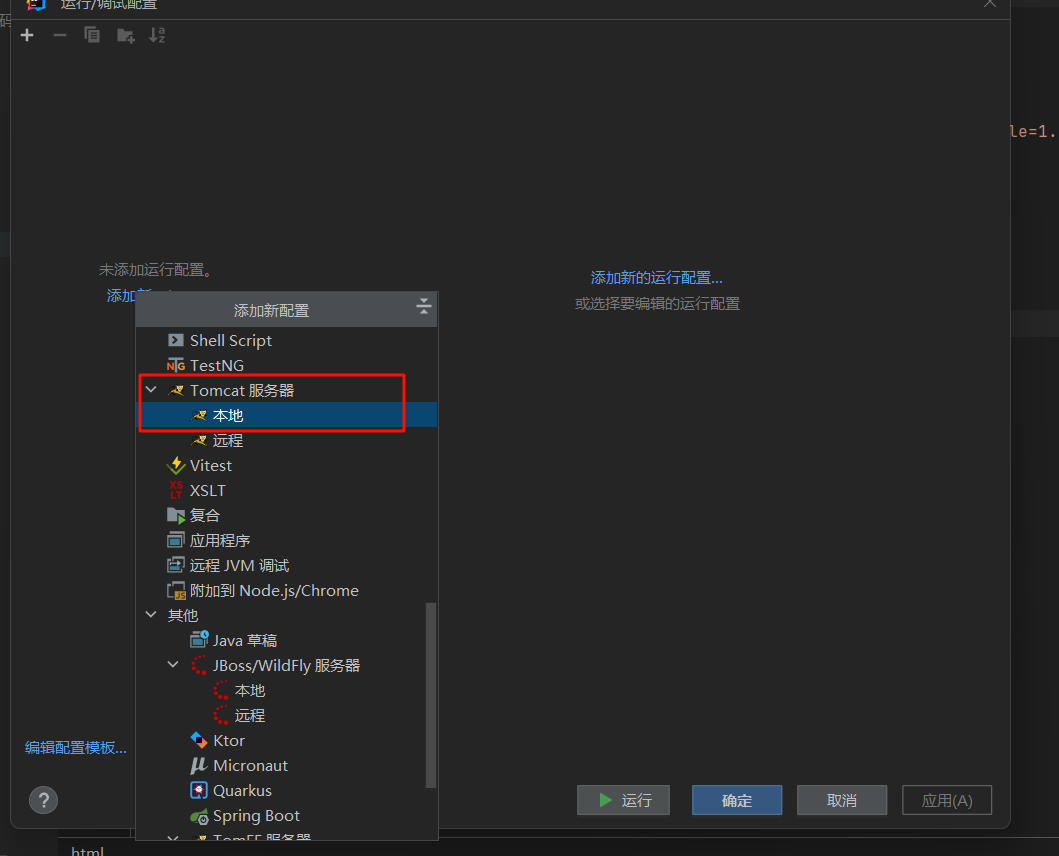

Mybatis
- 文档地址:https://mybatis.org/mybatis-3/
- 源码地址:https://github.com/mybatis/mybatis-3
- Mybatis是一个半自动化持久化层ORM框架
- ORM:
Object Relational Mapping[对象 关系 映射]- 将JAVA中的对象与数据库中的表建立关系
-
Mybatis与Hibernate对比
- Mybatis是一个半自动化【需要手写SQL】
- Hibernate是全自动化【无需手写SQL】
-
Mybatis与JDBC对比
- JDBC中的SQL与Java代码耦合度高
- Mybatis将SQL与Java代码解耦
-
Java POJO(Plain Old Java Objects,普通老式 Java 对象)
- JavaBean 等同于 POJO
搭建Mybatis框架
1.导入jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>top.dreamlove</groupId>
<artifactId>day03_maven</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>qiuye_01_mybatis</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--mysql的驱动包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
<!--Mybatis的jar包-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
2.编写核心配置文件【mybatis-config.xml】
-
位置:resources目标下
-
名称:推荐使用mybatis-config.xml
-
示例代码
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- mysql8版本-->
<!-- <property name="driver" value="com.mysql.cj.jdbc.Driver"/>-->
<!-- <property name="url" value="jdbc:mysql://localhost:3306/db220106?serverTimezone=UTC"/>-->
<!-- mysql5版本-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/db220106"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!-- 设置映射文件路径-->
<mappers>
<mapper resource="mapper/EmployeeMapper.xml"/>
</mappers>
</configuration>
3.书写相关接口及映射文件
-
映射文件位置:resources/mapper
-
映射文件名称:XXXMapper.xml
-
映射文件作用:主要作用为Mapper接口书写Sql语句
- 映射文件名与接口名一致
- 映射文件namespace与接口全类名一致
- 映射文件SQL的Id与接口的方法名一致
- 1.书写pojo(也就是bean层)
- 2.书写mapper层(接口文件)
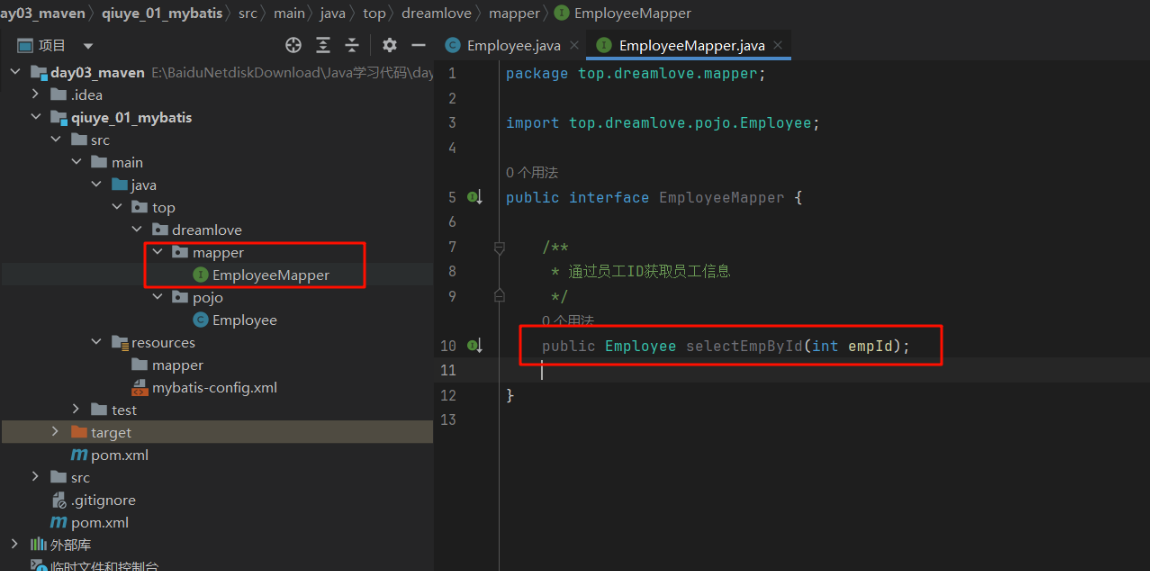
- 3.resources下书写xml映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<select id="selectEmpById" resultType="top.dreamlove.pojo.Employee">
select id,
last_name lastName,
email,
salary
from
tbl_employee
where
id = #{id}
</select>
</mapper>
- 4.测试[sqlSession]
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import org.apache.ibatis.io.Resources;
import top.dreamlove.mapper.EmployeeMapper;
import top.dreamlove.pojo.Employee;
import java.io.IOException;
import java.io.InputStream;
public class TestMybatis {
@Test
public void testMyBatis() {
String resource = "mybatis-config.xml";
try {
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//通过sqlSessionFactory获取sqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取EmployeeMapper的代理对象
EmployeeMapper employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
System.out.println("employeeMapper = " + employeeMapper);
//执行
Employee employee = employeeMapper.selectEmpById(1);
System.out.println("employee = " + employee.toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
4.添加log4j日志jar包
- 添加jar包
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
- 配置文件resources
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="STDOUT" class="org.apache.log4j.ConsoleAppender">
<param name="Encoding" value="UTF-8" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n" />
</layout>
</appender>
<logger name="java.sql">
<level value="debug" />
</logger>
<logger name="org.apache.ibatis">
<level value="info" />
</logger>
<root>
<level value="debug" />
<appender-ref ref="STDOUT" />
</root>
</log4j:configuration>

Mybatis配置
properties
- 可以通过
resources来引入外部文件(基于类路径)

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"></properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${db.driver}"/>
<property name="url" value="${db.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</dataSource>
</environment>
</environments>
<!-- 设置映射文件路径-->
<mappers>
<mapper resource="mapper/EmployeeMapper.xml"/>
</mappers>
</configuration>
- 也可以通过
url来引入(基于系统路径,盘符啥的) - 也可以直接书写
<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
</properties>
使用
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
setting
-
作用:这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。
-
mapUnderscoreToCamelCase属性:是否开启驼峰命名自动映射,默认值false,如设置true会自动将
字段a_col与aCol属性自动映射
- 注意:只能将字母相同的字段与属性自动映射
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!--加载属性文件--> <properties resource="db.properties"></properties> <settings> <!--开启驼峰命名(数据库字段自动映射为驼峰命名)--> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${db.driver}"/> <property name="url" value="${db.url}"/> <property name="username" value="${db.username}"/> <property name="password" value="${db.password}"/> </dataSource> </environment> </environments> <!-- 设置映射文件路径--> <mappers> <mapper resource="mapper/EmployeeMapper.xml"/> </mappers> </configuration>
typeAliases
-
作用:类型别名可为 Java 类型设置一个缩写名字。
-
语法及特点
<typeAliases>
<!-- 为指定类型定义别名-->
<!-- <typeAlias type="com.atguigu.mybatis.pojo.Employee" alias="employee"></typeAlias>-->
<!-- 为指定包下所有的类定义别名
默认将改包下的每一个类名作为别名,不区分大小写【推荐使用小写字母】
-->
<package name="com.atguigu.mybatis.pojo"/>
</typeAliases>
environments
-
作用:设置数据库连接环境
-
示例代码
<!-- 设置数据库连接环境-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!-- mysql8版本-->
<!-- <property name="driver" value="com.mysql.cj.jdbc.Driver"/>-->
<!-- <property name="url" value="jdbc:mysql://localhost:3306/db220106?serverTimezone=UTC"/>-->
<!-- mysql5版本-->
<property name="driver" value="${db.driver}"/>
<property name="url" value="${db.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</dataSource>
</environment>
</environments>
mappers子标签
-
作用:设置映射文件路径
-
示例代码
<!-- 设置映射文件路径-->
<mappers>
<mapper resource="mapper/EmployeeMapper.xml"/>
<!-- 要求:接口的包名与映射文件的包名需要一致-->
<!-- <package name="com.atguigu.mybatis.mapper"/>-->
</mappers>
- 注意:核心配置中的子标签,是有顺序要求的。

Mybatis映射
映射文件概述
- MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。
- 如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。
映射文件根标签
- mapper标签
- mapper中的namespace要求与接口的全类名一致

映射文件子标签
子标签共有9个,注意学习其中8大子标签
- insert标签:定义添加SQL
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<insert id="addEmployee">
insert into tbl_employee(last_name,email,salary) values(#{lastName},#{email},#{salary})
</insert>
</mapper>
- delete标签:定义删除SQL
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<delete id="deleteEmployee">
delete from tbl_employee where id = #{empId}
</delete>
</mapper>
- update标签:定义修改SQL
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<!--更新员工-->
<update id="updateEmployee">
update tbl_employee set last_name=#{lastName},email=#{email},salary=#{salary} where id = #{id};
</update>
</mapper>
- select标签:定义查询SQL
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<!--查询所有员工,当然,你也可以取一个别名在resultType-->
<select id="selectAllEmployee" resultType="top.dreamlove.pojo.Employee">
select id,last_name,email,salary from tbl_employee
</select>
</mapper>
- sql标签:定义可重用的SQL语句块
- cache标签:设置当前命名空间的缓存配置
- cache-ref标签:设置其他命名空间的缓存配置
- **resultMap标签:**描述如何从数据库结果集中加载对象
- resultType解决不了的问题,交个resultMap。
获取主键自增数据
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<!--添加员工-->
<insert id="addEmployee" useGeneratedKeys="true" keyProperty="id" >
insert into tbl_employee(last_name,email,salary) values(#{lastName},#{email},#{salary})
</insert>
</mapper>
Employee employee1 = new Employee(null,"李白","zmqdream@qq.com",1000.0);
employeeMapper.addEmployee(employee1);
//获取返回的自增主键
System.out.println(employee1.getId());
获取数据库受影响行数
直接将接口中方法的返回值设置为int或boolean即可
- int:代表受影响行数
- boolean
- true:表示对数据库有影响
- false:表示对数据库无影响
Mybatis参数传递问题
单个参数 单个普通参数
- 可以任意使用:参数数据类型、参数名称不用考虑
- 当然,不建议这样,接口的参数名称是什么名称,一般映射当中就要什么名称
Employee selectEmpById(int empId);
<!--根据ID查询用户信息-->
<select id="selectEmpById" resultType="top.dreamlove.pojo.Employee">
select id,
last_name,
email,
salary
from
tbl_employee
where
id = #{abcdefff}
</select>
多个普通参数
- Mybatis底层封装Map结构,封装key为param1、param2…【支持:arg0、arg1、…】
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace对应书写的mapper下的JAVA文件-->
<mapper namespace="top.dreamlove.mapper.EmployeeMapper">
<!--
id: 方法名要和接口对应的方法相同
resultType: 返回类型,和pojo相同
-->
<!-- 根据员工名称,邮箱查询员工信息 -->
<select id="selectEmployName" resultType="top.dreamlove.pojo.Employee">
select * from tbl_employee where last_name = #{param1} and email = #{param2}
</select>
</mapper>
package top.dreamlove.mapper;
import top.dreamlove.pojo.Employee;
import java.util.List;
public interface EmployeeMapper {
/**
* 员工名称,邮箱查询员工信息
*/
Employee selectEmployName(String name,String email);
}
POJO参数
- Mybatis支持POJO【JavaBean】入参,参数key是POJO中属性
- 也就是这个对象里面的属性可以直接拿来用(有点类似于前端的自动帮你解构赋值了)
多个普通参数(命名参数)
- 支持param,但是不支持arg0
/**
* 通过员工姓名及薪资查询员工信息【命名参数】
* @return
*/
public List<Employee> selectEmpByNamed(@Param("lName")String lastName,
@Param("salary") double salary);
<select id="selectEmpByNamed" resultType="employee">
SELECT
id,
last_name,
email,
salary
FROM
tbl_employee
WHERE
last_name=#{param1}
AND
salary=#{param2}
</select>
或者不适用param1
<select id="selectEmployName" resultType="top.dreamlove.pojo.Employee">
select * from tbl_employee where last_name = #{lName} and email = #{salary}
</select>
Map参数
- Mybatis支持直接Map入参,map的key=参数key
Employee selectEmployName(Map<String,Object> map);
Map<String,Object> map = new HashMap<>();
map.put("Name","李白");
map.put("Email","zmqdream@qq.com");
<select id="selectEmployName" resultType="top.dreamlove.pojo.Employee">
select * from tbl_employee where last_name = #{Name} and email = #{Email}
</select>
#与$使用场景
-
#使用场景,sql占位符位置均可以使用#
-
KaTeX parse error: Expected 'EOF', got '#' at position 6: 使用场景,#̲解决不了的参数传递问题,均可以…处理【如:form 动态化表名】
/**
* 测试$使用场景
*/
public List<Employee> selectEmpByDynamitTable(@Param("tblName") String tblName);
<select id="selectEmpByDynamitTable" resultType="employee">
SELECT
id,
last_name,
email,
salary
FROM
${tblName}
</select>
select查询返回值情况
- 查询单行数据返回Map集合
-
resultType写一个map就可以,因为底层有别名的存在 -
Map<String key,Object value>
- 字段作为Map的key,查询结果作为Map的Value
-
/**
* 查询单行数据返回Map集合
* @return
*/
public Map<String,Object> selectEmpReturnMap(int empId);
<!-- 查询单行数据返回Map集合-->
<select id="selectEmpReturnMap" resultType="map">
SELECT
id,
last_name,
email,
salary
FROM
tbl_employee
WHERE
id=#{empId}
</select>
- 查询多行数据返回Map集合
-
Map<Integer key,Employee value>
- 对象的id作为key
- 对象作为value
-
@MapKey("id")id为Employee唯一标识
-
/**
* 查询多行数据返回Map
* Map<Integer,Object>
* Map<Integer,Employee>
* 对象Id作为:key
* 对象作为:value
* @return
*/
@MapKey("id")
public Map<Integer,Employee> selectEmpsReturnMap();
<select id="selectEmpsReturnMap" resultType="map">
SELECT
id,
last_name,
email,
salary
FROM
tbl_employee
</select>
Mybatis中自动映射与自定义映射
自动映射【resultType】
自定义映射【resultMap】
8.1 自动映射与自定义映射
- 自动映射【resultType】:指的是自动将表中的字段与类中的属性进行关联映射
- 自动映射解决不了两类问题
- 多表连接查询时,需要返回多张表的结果集
- 单表查询时,不支持驼峰式自动映射【不想为字段定义别名】
- 自动映射解决不了两类问题
- 自定义映射【resultMap】:自动映射解决不了问题,交给自定义映射
- 注意:resultType与resultMap只能同时使用一个
8.2 自定义映射-级联映射
<!-- 自定义映射 【员工与部门关系】-->
<resultMap id="empAndDeptResultMap" type="employee">
<!-- 定义主键字段与属性关联关系 -->
<id column="id" property="id"></id>
<!-- 定义非主键字段与属性关联关系-->
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
<result column="salary" property="salary"></result>
<!-- 为员工中所属部门,自定义关联关系-->
<result column="dept_id" property="dept.deptId"></result>
<result column="dept_name" property="dept.deptName"></result>
</resultMap>
<select id="selectEmpAndDeptByEmpId" resultMap="empAndDeptResultMap">
SELECT
e.`id`,
e.`email`,
e.`last_name`,
e.`salary`,
d.`dept_id`,
d.`dept_name`
FROM
tbl_employee e,
tbl_dept d
WHERE
e.`dept_id` = d.`dept_id`
AND
e.`id` = #{empId}
</select>
8.3 自定义映射-association映射
-
特点:解决一对一映射关系【一对多】
-
示例代码
-
<!-- 自定义映射 【员工与部门关系】--> <resultMap id="empAndDeptResultMapAssociation" type="employee"> <!-- 定义主键字段与属性关联关系 --> <id column="id" property="id"></id> <!-- 定义非主键字段与属性关联关系--> <result column="last_name" property="lastName"></result> <result column="email" property="email"></result> <result column="salary" property="salary"></result> <!-- 为员工中所属部门,自定义关联关系--> <association property="dept" javaType="com.atguigu.mybatis.pojo.Dept"> <id column="dept_id" property="deptId"></id> <result column="dept_name" property="deptName"></result> </association> </resultMap>
-
8.4 自定义映射-collection映射
-
示例代码
/** * 通过部门id获取部门信息,及部门所属员工信息 */ public Dept selectDeptAndEmpByDeptId(int deptId);<resultMap id="deptAndempResultMap" type="dept"> <id property="deptId" column="dept_id"></id> <result property="deptName" column="dept_name"></result> <collection property="empList" ofType="com.atguigu.mybatis.pojo.Employee"> <id column="id" property="id"></id> <result column="last_name" property="lastName"></result> <result column="email" property="email"></result> <result column="salary" property="salary"></result> </collection> </resultMap> <select id="selectDeptAndEmpByDeptId" resultMap="deptAndempResultMap"> SELECT e.`id`, e.`email`, e.`last_name`, e.`salary`, d.`dept_id`, d.`dept_name` FROM tbl_employee e, tbl_dept d WHERE e.`dept_id` = d.`dept_id` AND d.dept_id = #{deptId} </select>
8.5 ResultMap相关标签及属性
-
resultMap标签:自定义映射标签
- id属性:定义唯一标识
- type属性:设置映射类型
-
resultMap子标签
- id标签:定义主键字段与属性关联关系
- result标签:定义非主键字段与属性关联关系
- column属性:定义表中字段名称
- property属性:定义类中属性名称
- association标签:定义一对一的关联关系
- property:定义关联关系属性
- javaType:定义关联关系属性的类型
- select:设置分步查询SQL全路径
- colunm:设置分步查询SQL中需要参数
- collection标签:定义一对多的关联关系
- property:定义一对一关联关系属性
- ofType:定义一对一关联关系属性类型
8.6 Mybatis中分步查询
- 为什么使用分步查询【分步查询优势】?
- 将多表连接查询,改为【分步单表查询】,从而提高程序运行效率
MBG
MyBatisGenerator:简称MBG
是一个专门为MyBatis框架使用者定制的代码生成器
可以快速的根据表生成对应的映射文件,接口,以及bean类。
只可以生成单表CRUD,但是表连接、存储过程等这些复杂sgl的定义需要我们手工编写
- https://mybatis.org/generator/
- https://github.com/mybatis/generator/releases
Mybatis中分页插件
- PageHelper
Spring
-
官网https://spring.io/
-
之前创建是先new,而现在是装配到容器中
public void test1(){
//使用Spring之前
// Student student = new Student();
//使用Spring之后
ApplicationContext iocObj = new ClassPathXmlApplicationContext("applicationContext.xml");
Student student = (Student) iocObj.getBean("qiuyeStu");
System.out.println("student = " + student);
//输出student = Student{id=100, name='libai'}
}
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--对象装配到容器中,之后再用-->
<bean id="qiuyeStu" class="top.dreamlove.pojo.Student">
<property name="id" value="100"/>
<property name="name" value="libai"/>
</bean>
</beans>
Spring中getBean()三种方式
-
getBean(String beanId):通过beanId获取对象
- 不足:需要强制类型转换,不灵活
-
getBean(Class clazz):通过Class方式获取对象
-
不足:容器中有多个相同类型bean的时候,会报如下错误:
expected single matching bean but found 2: stuZhenzhong,stuZhouxu
-
-
getBean(String beanId,Clazz clazz):通过beanId和Class获取对象
- 推荐使用
Spring依赖注入数值问题
- 比如我想取名叫
<西游记>,但是不允许这样写
<bean id="qiuyeStu1" class="top.dreamlove.pojo.Student">
<property name="name" value="<西游记>"/>
</bean>
- 所以就需要写
<![CDATA[]]>
<bean id="qiuyeStu1" class="top.dreamlove.pojo.Student">
<property name="name">
<value> <![CDATA[<红楼梦>]]> </value>
</property>
</bean>

- 语法:<![CDATA[]]>
- 作用:在xml中定义特殊字符时,使用CDATA区
SpringBoot
- 官网https://spring.io/
- 2.x版本文档
- https://docs.spring.io/spring-boot/docs/2.7.18/reference/html/index.html
HelloWorld
- 可以参照文档进行
- https://docs.spring.io/spring-boot/docs/2.7.18/reference/html/getting-started.html#getting-started.first-application.pom
- 配置文件
- https://docs.spring.io/spring-boot/docs/2.7.18/reference/html/application-properties.html#appendix.application-properties
package top.dreamlove.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MainController {
public static void main(String[] args) {
SpringApplication.run(MainController.class,args);
}
}
package top.dreamlove.boot.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String handle01(){
return "hello,wordl";
}
}
- 创建jar包
- https://docs.spring.io/spring-boot/docs/2.7.18/reference/html/getting-started.html#getting-started.first-application.executable-jar
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version>
</parent>
<!-- Additional lines to be added here... -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- 可以修改默认版本号
1、查看spring-boot-dependencies里面规定当前依赖的版本 用的 key。
2、在当前项目里面重写配置
<properties>
<mysql.version>5.1.43</mysql.version>
</properties>
- 默认的包结构
- 主程序所在包及其下面的所有子包里面的组件都会被默认扫描进来
- 无需以前的包扫描配置
@Configuration
@Conditional
- 可以对类使用,当满足条件,则类里面的所有会被注入,
- 也可以对某一个方法使用,当满足,这个方法才会被注入
@ImportResource
- 原生配置文件引入
@PathVariable
- http://localhost:9909/car/3/owner/libai
- 获取路径变量信息
@RestController
public class ParamController {
@GetMapping("/car/{id}/owner/{userName}")
public Map<String,Object> getInfo(@PathVariable("id") String id,
@PathVariable("userName") String username
){
Map<String,Object> map = new HashMap<>();
map.put("id",id);
map.put("userName",username);
return map;
}
}
{
"id": "3",
"userName": "libai"
}
@RequestParam
- http://localhost:9909/car/3/owner/libai?age=18&hobby=吃饭&hobby=睡觉
- 获取请求参数
@RestController
public class ParamController {
@GetMapping("/car/{id}/owner/{userName}")
public Map<String,Object> getInfo(@PathVariable("id") String id,
@PathVariable("userName") String username,
@RequestParam("age") Integer age,
@RequestParam("hobby") List<String> hobby
){
Map<String,Object> map = new HashMap<>();
map.put("id",id);
map.put("userName",username);
map.put("age",age);
map.put("hobby",hobby);
return map;
}
}
{
"id": "3",
"userName": "libai",
"age": 18,
"hobby": [
"吃饭",
"睡觉"
]
}
@RequestHeader
- 获取请求头数据
@RestController
public class ParamController {
@GetMapping("/car/{id}/owner/{userName}")
public Map<String,Object> getInfo(@PathVariable("id") String id,
@PathVariable("userName") String username,
@RequestParam("age") Integer age,
@RequestParam("hobby") List<String> hobby,
@RequestHeader("User-Agent") String agent,
@RequestHeader Map<String,String> header
){
Map<String,Object> map = new HashMap<>();
map.put("id",id);
map.put("userName",username);
map.put("age",age);
map.put("hobby",hobby);
map.put("agent",agent);
map.put("所有请求头",header);
return map;
}
}
{
"agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"所有请求头": {
"host": "localhost:9909",
"connection": "keep-alive",
"cache-control": "max-age=0",
"sec-ch-ua": "\"Google Chrome\";v=\"123\", \"Not:A-Brand\";v=\"8\", \"Chromium\";v=\"123\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"cookie": "Idea-8296f2b3=4f2c3186-368f-495a-91d3-c900f7982eb4"
},
"id": "3",
"userName": "libai",
"age": 18,
"hobby": [
"吃饭",
"睡觉"
]
}
@CookieValue
- 获取Cookie数据
@RestController
public class ParamController {
@GetMapping("/car/{id}/owner/{userName}")
public Map<String,Object> getInfo(@PathVariable("id") String id,
@PathVariable("userName") String username,
@RequestParam("age") Integer age,
@RequestParam("hobby") List<String> hobby,
@RequestHeader("User-Agent") String agent,
@RequestHeader Map<String,String> header,
@CookieValue("Idea-8296f2b3") String Cookie1,
@CookieValue("Idea-8296f2b3") Cookie cookie2
){
Map<String,Object> map = new HashMap<>();
map.put("id",id);
map.put("userName",username);
map.put("age",age);
map.put("hobby",hobby);
map.put("agent",agent);
map.put("所有请求头",header);
map.put("cookie1",Cookie1);
map.put("cookie2",cookie2.getValue());
return map;
}
}
{
"agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"所有请求头": {
"host": "localhost:9909",
"connection": "keep-alive",
"pragma": "no-cache",
"cache-control": "no-cache",
"sec-ch-ua": "\"Google Chrome\";v=\"123\", \"Not:A-Brand\";v=\"8\", \"Chromium\";v=\"123\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8",
"cookie": "Idea-8296f2b3=4f2c3186-368f-495a-91d3-c900f7982eb4"
},
"id": "3",
"userName": "libai",
"cookie1": "4f2c3186-368f-495a-91d3-c900f7982eb4",
"age": 18,
"hobby": [
"吃饭",
"睡觉"
],
"cookie2": "4f2c3186-368f-495a-91d3-c900f7982eb4"
}
@RequestAttribute
- 获取request域属性
- 既可以通过注解获取,也可以通过
request.getAttribute()方法获取
拦截器
package top.dreamlove.admin.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import top.dreamlove.admin.interceptor.LoginInterceptor;
@Configuration
public class AdminWebConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
//使用拦截器
registry.addInterceptor(new LoginInterceptor())
// 所有的页面添加拦截
.addPathPatterns("/**")
// 排除静态资源和登录页面
.excludePathPatterns("/", "/login", "/css/**", "/fonts/**", "/images/**", "/js/**");
}
}
package top.dreamlove.admin.interceptor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
@Slf4j
public class LoginInterceptor implements HandlerInterceptor {
/**
* 请求之前
*
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断是否登录
HttpSession session = request.getSession();
String requestURI = request.getRequestURI();//获取请求地址
if(session.getAttribute("user") == null){
log.info("拦截" + session.getAttribute("user") + "地址:" + requestURI);
request.setAttribute("msg","请登录");
//跳转到登录页面
request.getRequestDispatcher("/").forward(request,response);
return false;//拦截,未登录
}else{
return true;//登录,放行
}
// return HandlerInterceptor.super.preHandle(request, response, handler);
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
HandlerInterceptor.super.afterCompletion(request, response, handler, ex);
}
}
MyBatis-plus
- 默认情况下名称和表名对应,可以通过
@TableName("user_tabl")来指定表名
基本
- window版本的redis
- https://github.com/tporadowski/redis/releases
- redis是区分大小写的
- 如果需要显示中文,登录的时候
redis-cli --raw即可 - 菜鸟笔记记的很好,我这边只是自己看看
- https://www.runoob.com/redis/redis-stream.html
字符串
-
get key
-
set key
-
setnx key value
- 当key不存在的时候才设置value
-
del key
- 成功1,失败0
-
exists key
- 是否存在,存在1,不存在0
-
keys pattern
- 获取所有符合pattern的键
-
flushall
- 清空所有
-
ttl key
- 查看一个键的过期时间,-1表示未设置过期时间
-
expire key second
- 设置key过期时间 second单位为秒
列表(list)-命令l开头
-
元素是可以重复的
-
lpush key value1,value2,value3,…valueN
- 列表头部添加内容
-
rpush key value1,value2,value3,…valueN
- 列表尾部添加内容
-
lrange key start stop
- start为起始位置,stop为结束位置(以0开始)
lrange letter 0 -1从开始获取到最后(获取所有)
-
lpop key count
- 列表头部删除元素
- count为删除元素个数
-
rpop key count
- 列表尾部删除元素
- count为删除元素个数
-
llen key
- 查看列表的元素个数
-
LTRIM key start stop
- 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
集合(set)-命令s开头
-
无序的,且元素不可以重复
-
sadd key member1,member2,…,memberN,
- 添加元素,一个或多个
-
smembers key
-
sismember key member
- 判断member是否在key的集合中
-
srem key member
- 删除key当中的member
-
集合运算
有序集合(sortedset或zset)-命令以z开头
-
有序集合的每个元素,都会关联一个浮点类型的分数,然后按照这个分数,来对集合中的元素进行从小到大的排序,有序集合的成员是唯一的,但是分数是可以重复的,
-
zadd key 分数 成员,分数 成员,分数 成员
- 返回添加的集合数量
- 分数在前,成员在后
-
zrange key start stop
- 技巧:
zrange key 0 -1获取所有元素 - 如果需要输出分数,需要
zrange key 0 -1 withscores
- 技巧:
-
zscore key member
- 查看某个成员分数的
-
zrank key member
- 查看某个成员分数的排名(从小到大的顺序排列的排名),0开始排
-
zrevrank key member
- 查看某个成员分数的排名(从大到小的顺序排列的排名) 0开始排
-
zrem key member
- 删除成员
哈希(hash)-命令以h开头
-
哈希是一个字符类型的字段和值的映射表,简单来说就是一个键值对的集合,特别适合用来存储对象
-
hset key field value [field value…]
-
hgetall key
- 获取所有键值对(以键值对成对出现)
-
hdel key field
- 删除
-
hexist key field
- 判断是否存在
-
hkeys key
- 获取所有field
-
hlens key
发布订阅模式
-
publish命令来将消息发送到指定的频道
-
subscribe来订阅这个频道
-
subscribe channel 订阅
-
publish channel message
- channel频道发布消息
消息队列(Stream)-命令以x开头
-
redis5.0版本引入的一个新的数据结构
-
可以解决发布订阅消息无法持久化,无法记录历史记录等
-
XADD key ID field value [field value …]
- key :队列名称,如果不存在就创建
- ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。
- field value : 记录。
-
XLEN key
- 使用 XLEN 获取流包含的元素数量,即消息长度,语法格式:
-
XRANGE key start end [COUNT count]
- 使用 XRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
- 开始和结束可以分别使用
-和+
-
xdel
- 删除消息
-
xtrim
-
xgroup
技巧
-
GetMapping(“/”),GetMapping( value = “/”),多个值GetMapping( value = {“/”,“/login”} )
-
Controller和RestController的区别
- 举个例子,如果你需要返回一个HTML页面,那么你需要使用@Controller注解;如果你需要返回一个JSON格式的数据,那么你需要使用@RestController注解。
- https://blog.csdn.net/chris3will/article/details/130067995
-
thymeleaf如果是行内,则需要使用
[[${变量}]] -
Arrays.asList() -
slf4j可以用占位符
Log.info("上传的信息:email={},username={},headerImg={},photos={}",email,username,headerImg.getSize(),photos.length); //输出信息 上传的信息:emai1=534096094@qq.c0m,username=admin,headerImg=43535,phot0s=2 -
C:\Users\Administrator\AppData\Local\Temp\tomcat.8080.3393410858019601440\work\Tomcat\localhost\ROOT\upload_52f25625_bd8b_400f_a069_c10bd66bdb8f_00000002.tmp (系统找不到指定的文件。)
- https://www.cnblogs.com/rong-xu-drum/p/16711478.html
- 解决方案:引入commons-io的Maven依赖包
然后import org.apache.commons.io.FileUtils;
-
可以直接使用
MapperScan这样就不需要我们手动为每一个Mapper添加@Mapper注解了 -
Ctrl + f12做什么用的?
技巧
- 重新部署可以按这2个按钮
- 2023创建Servlet的快捷方式
- https://blog.csdn.net/hgnuxc_1993/article/details/134417537
- 跳转值root.html页面
request.getRequestDispatcher(s:"root.html").forward(request,response); - lib包必须要在WEB-INFO下
- 2023添加javaEE项目

req.getRequestDispatcher("/list").forward(req,resp);
//RequestDispatcher把request和response复制并转给“dispatchUrl”,需要注意的是,转发前后地址栏不变(均为转发前的地址
resp.sendRedirect(req.getContextPath() + "/list");
原文地址:https://blog.csdn.net/u014582342/article/details/137753538
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!