【MGR】MySQL Group Replication 管理操作
目录
17.5 Group Replication Operations
17.5.1 Deploying in Multi-Primary or Single-Primary Mode
Enhanced Automatic Donor Switchover(增强数据源节点切换)
Donor Connection Retries(数据源节点连接重试)
17.5.5 Using MySQL Enterprise Backup with Group Replication
17.5 Group Replication Operations
该部分描述了部署Group Replication的不同模式,解释了管理组的常见操作,并提供了有关如何调整组的信息。
17.5.1 Deploying in Multi-Primary or Single-Primary Mode
Group Replication可以在以下不同模式下运行:
- 单主模式(single-primary mode)
- 多主模式(multi-primary mode)
默认模式为单主模式。不能将组的成员部署在不同的模式下,例如一个配置为多主模式,而另一个配置为单主模式。要在模式之间切换,需要重新启动组,而不是服务器,使用不同的操作配置。无论部署的模式如何,Group Replication都不处理客户端故障转移,这必须由应用程序本身、连接器或中间件框架(如代理或MySQL Router 8.0)来处理。
当部署在多主模式下时,会检查语句以确保其与该模式兼容。当Group Replication部署在多主模式下时,会进行以下检查:
- 如果事务在SERIALIZABLE隔离级别下执行,则在与组同步时,其提交将失败。
- 如果事务针对具有级联约束的外键的表执行,则在与组同步时,该事务将无法提交。
可以通过将选项group_replication_enforce_update_everywhere_checks设置为FALSE来取消这些检查。在单主模式下部署时,必须将此选项设置为FALSE。
17.5.1.1 Single-Primary Mode
在此模式下,组具有一个设置为读写模式的单主服务器。组中的所有其他成员都被设置为只读模式(super-read-only=ON)。这是自动完成的。主服务器通常是首个引导组的服务器,所有其他自动加入的服务器都会自动了解主服务器,并被设置为只读模式。
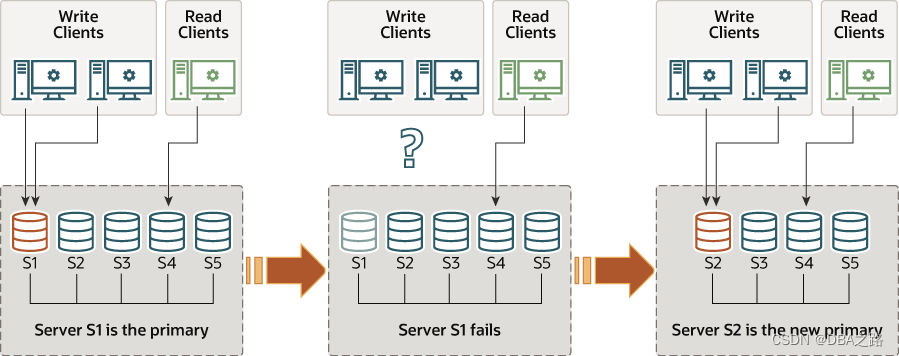
五个服务器实例,S1、S2、S3、S4和S5,被部署为相互连接的组。服务器S1是主服务器。写入客户端正在与服务器S1通信,而读取客户端正在与服务器S4通信。然后,服务器S1失败,导致与写入客户端的通信中断。然后,服务器S2接管并成为新的主服务器,写入客户端现在与服务器S2通信。
在单主模式下,一些在多主模式下部署的检查被禁用,因为系统强制仅允许单个服务器向组写入。例如,允许对具有级联外键的表进行更改,而在多主模式下则不允许。在主要成员故障时,自动主选举机制选择新的主要成员。选举过程通过查看新视图并根据group_replication_member_weight值对潜在的新主进行排序来执行。假设组中的所有成员运行相同的MySQL版本,则具有最高group_replication_member_weight值的成员被选为新的主要成员。如果多个服务器具有相同的group_replication_member_weight,则根据它们的server_uuid按字典顺序对服务器进行优先排序,并选择第一个。一旦选出新的主要成员,它就会自动设置为读写,而其他从属成员保持为从属成员,因此为只读。
当选出新的主要成员时,只有在它处理了来自旧主要成员的所有事务之后,它才能进行写入。这避免了旧主要成员的旧事务与在此成员上执行的新事务之间可能的并发问题。在将客户端应用程序重新路由到新主要成员之前,等待新主要成员应用其与复制相关的中继日志是一种良好的做法。
如果组中的成员运行不同版本的MySQL,则选举过程可能会受到影响。例如,如果任何成员不支持group_replication_member_weight,则基于较低主要版本的成员的server_uuid顺序选择主要成员。或者,如果所有运行不同MySQL版本的成员都支持group_replication_member_weight,则基于较低主要版本的成员的group_replication_member_weight选择主要成员。
17.5.1.2 Multi-Primary Mode
在多主模式下,不存在单一主服务器的概念。不需要进行选举过程,因为没有任何服务器扮演特殊角色的必要。
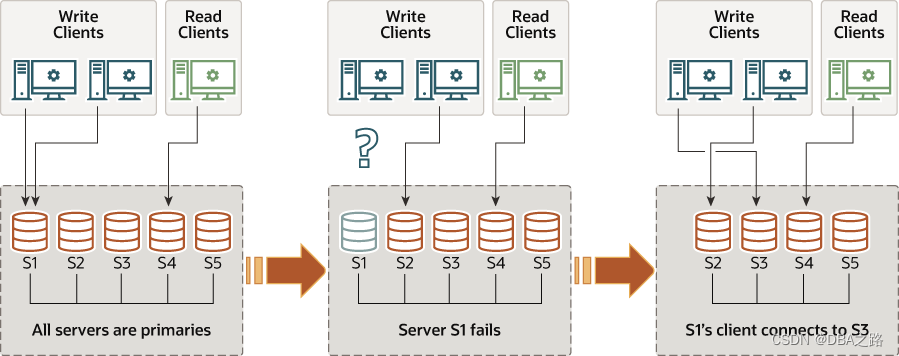
所有服务器在加入组时都被设置为读写模式。
17.5.1.3 Finding the Primary
以下示例显示了在单主模式下部署时如何找出当前是主服务器的方法。
mysql> SHOW STATUS LIKE 'group_replication_primary_member';17.5.2 Tuning Recovery
每当新成员加入复制组时,它会连接到一个合适的数据源节点,并获取自身所错过的数据,直到他的状态为ONLINE。Group Replication中的这个关键组件是容错且可配置的。接下来的部分将解释恢复的工作原理以及如何调整设置。
Donor Selection (数据源选择)
从当前在线成员中随机选择一个数据源。这样,当多个成员进入组时,同一个服务器几乎不会多次选择。
如果与所选数据源的连接失败,则会自动尝试连接到新的候选数据源。一旦达到连接重试限制,恢复过程将以错误终止。
Note
从当前视图的在线成员列表中随机选择一个捐助者。
Enhanced Automatic Donor Switchover(增强数据源节点切换)
恢复过程的另一个主要关注点是确保它能够处理故障。因此,Group Replication 提供了强大的错误检测机制。在 Group Replication 的早期版本中,当联系数据源节点时,恢复只能检测到由于身份验证问题或其他问题导致的连接错误。对于这种问题情景的反应是切换到一个新的数据源节点,因此尝试建立到另一个成员的新连接。
这种行为也被扩展到涵盖其他故障情景:
-
数据被清除情景 - 如果所选数据源节点恢复过程所需的某些数据已被清除,则会发生错误。恢复会检测到此错误并选择一个新的数据源节点。
-
数据重复 - 如果加入组的服务器已经包含与恢复过程中所选数据源节点提供的数据冲突的数据,则会发生错误。这可能是由加入组的服务器上存在的某些错误事务引起的。有人可能会认为,在出现错误时,恢复应该失败而不是切换到另一个捐助者,但在异构组中,存在其他成员共享冲突事务的可能性,而其他成员则不共享。因此,在出现错误时,恢复会从组中选择另一个数据源节点。
- 其他错误 - 如果任何恢复线程失败(接收器或应用程序线程失败),则会发生错误,并且恢复会切换到一个新的捐助者。
Note
在一些持久性故障或甚至短暂故障的情况下,恢复会自动重试连接到相同或新的数据源节点。
Donor Connection Retries(数据源节点连接重试)
恢复数据传输依赖于二进制日志和现有的MySQL复制框架,因此可能会出现一些瞬态错误,导致接收器或应用程序线程出现错误。在这种情况下,数据源节点切换过程具有重试功能,类似于常规复制中的功能。
Number of Attempts(尝试次数)
当服务器尝试从数据源节点池中连接到数据源节点时,加入组的服务器尝试次数为10次。这通过group_replication_recovery_retry_count插件变量进行配置。以下命令将尝试连接到数据源节点的最大次数设置为10。
mysql> SET GLOBAL group_replication_recovery_retry_count= 10;请注意,这考虑了加入组的服务器尝试连接到每个合适的数据源节点的全局尝试次数。
Sleep Routines(睡眠程序)
group_replication_recovery_reconnect_interval插件变量定义了恢复过程在数据源节点连接尝试之间应该休眠多长时间。该变量的默认值设置为60秒,您可以动态更改此值。以下命令将恢复数据源节点连接重试间隔设置为120秒。
mysql> SET GLOBAL group_replication_recovery_reconnect_interval= 120;但请注意,恢复不会在每次数据源节点连接尝试后都休眠。由于加入组的服务器正在连接到不同的服务器而不是一遍又一遍地连接到同一个服务器,它可以假定影响服务器A的问题不会影响服务器B。因此,只有当恢复已经尝试连接到组中的所有可能的数据源节点并且没有剩余时,恢复才会暂停。一旦加入组的服务器尝试连接到组中的所有适当捐赠者并且没有剩余,则恢复过程会休眠,休眠时间由group_replication_recovery_reconnect_interval变量配置的秒数确定。
17.5.3 Network Partitioning
该组在发生需要复制的更改时需要达成共识。这适用于常规交易,但也适用于组成员变更和一些保持组一致性的内部消息。共识要求大多数组成员就给定决定达成一致意见。当失去大多数组成员时,组无法继续前进并阻塞,因为它无法获得多数或法定人数。
当存在多个非自愿故障时,可能会丢失法定人数,导致大多数服务器突然从组中移除。例如,在由5台服务器组成的组中,如果有3台服务器同时变得静默,那么大多数将受到影响,因此无法达成法定人数。事实上,剩下的两台服务器无法确定其他3台服务器是否已崩溃,或者是否网络分区已将这两台服务器孤立,因此组无法自动重新配置。
另一方面,如果服务器自愿退出组,它们会通知组应该重新配置自己。实际上,这意味着即将离开的服务器告诉其他人它即将离开。这意味着其他成员可以正确地重新配置组,维护成员资格的一致性并重新计算大多数。例如,在上述5台服务器的场景中,如果3台服务器同时离开,则如果这3台离开的服务器依次通知组它们正在离开,那么成员资格可以从5个调整到2个,并在此过程中保持法定人数。
Note
丢失法定人数本身就是规划不良的副作用。根据预期的故障数量(无论是连续发生、同时发生还是零星发生),为组大小制定计划。
下面的部分将解释如果系统以一种无法通过组中的服务器自动实现法定人数的方式分区应该怎么办。
Tip
在发生多数损失之后,通过重新配置被排除在组外的主要成员可能包含未包含在新组中的额外交易。如果发生这种情况,则尝试将被排除的成员从组中添加回去会导致错误,错误消息为“This member has more executed transactions than those present in the group.”(该成员的已执行交易数比组中存在的交易数多)。
Detecting Partitions(检测分区)
replication_group_members性能模式表显示了从此服务器的视角看每个服务器的当前视图的状态。大多数情况下,系统不会遇到分区,因此该表显示对于组中的所有服务器来说是一致的信息。换句话说,该表中每个服务器的状态在当前视图中被所有人认可。但是,如果存在网络分区,并且丢失了法定人数,那么该表将显示无法联系到的服务器的状态为UNREACHABLE(无法访问)。此信息由内置于Group Replication的本地故障检测器导出。
Figure 17.7 Losing Quorum
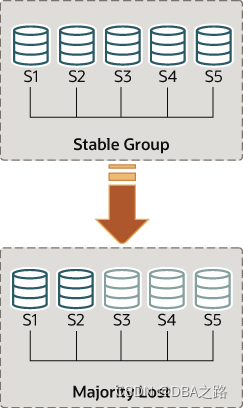
理解这种类型的网络分区,以下部分描述了最初有5台服务器正确地协同工作的情景,以及当只有2台服务器在线时群组发生的变化。情景如下图所示。
因此,让我们假设有一个包含以下5台服务器的群组:
- 服务器s1,成员标识符为199b2df7-4aaf-11e6-bb16-28b2bd168d07
- 服务器s2,成员标识符为199bb88e-4aaf-11e6-babe-28b2bd168d07
- 服务器s3,成员标识符为1999b9fb-4aaf-11e6-bb54-28b2bd168d07
- 服务器s4,成员标识符为19ab72fc-4aaf-11e6-bb51-28b2bd168d07
- 服务器s5,成员标识符为19b33846-4aaf-11e6-ba81-28b2bd168d07
最初,该群组正常运行,服务器之间正常通信。您可以通过登录到s1并查看其 preformance_schema.replication_group_members表来验证这一点。例如:
mysql> SELECT MEMBER_ID,MEMBER_STATE, MEMBER_ROLE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+-------------+
| MEMBER_ID | MEMBER_STATE |-MEMBER_ROLE |
+--------------------------------------+--------------+-------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | ONLINE | SECONDARY |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE | PRIMARY |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE | SECONDARY |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | ONLINE | SECONDARY |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | ONLINE | SECONDARY |
+--------------------------------------+--------------+-------------+然而,片刻之后发生了一次灾难性的故障,服务器 s3、s4 和 s5 意外停止工作。此后几秒钟,再次查看 s1 上的 replication_group_members 表,显示它仍然在线,但其他几个成员却不在。事实上,如下所示,它们被标记为 UNREACHABLE(无法访问)。此外,系统无法重新配置自身以更改成员资格,因为大多数成员已经丢失。
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+该表显示,s1 现在处于一个没有可能在没有外部干预的情况下继续进行的群组中,因为大多数服务器都无法访问。在这种特殊情况下,需要重置群组成员资格列表,以允许系统继续进行,这在本节中有详细说明。或者,您也可以选择停止 s1 和 s2 上的组复制(或完全停止 s1 和 s2),弄清楚 s3、s4 和 s5 发生了什么,然后重新启动组复制(或服务器)。
Unblocking a Partition
组复制使您能够通过强制特定配置来重置群组成员资格列表。例如,在上述情况中,其中只有 s1 和 s2 在线,您可以选择强制一个仅由 s1 和 s2 组成的成员配置。这需要检查有关 s1 和 s2 的一些信息,然后使用 group_replication_force_members 变量。
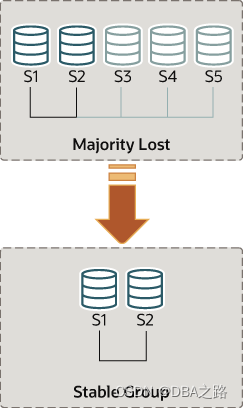
假设您回到了只剩下 s1 和 s2 的服务器的情况。服务器 s3、s4 和 s5 已意外离开了群组。为了让服务器 s1 和 s2 继续运行,您想要强制进行一个只包含 s1 和 s2 的成员配置。
Warning
此过程使用了 group_replication_force_members,并且应被视为最后的应急措施。必须极其小心使用,仅用于覆盖丧失法定人数的情况。如果错误使用,可能会产生人为的脑裂场景或完全阻塞整个系统。
请记住,系统已经被阻塞,当前配置如下(由 s1 上的本地故障检测器感知):
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | UNREACHABLE |
| 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | ONLINE |
| 199bb88e-4aaf-11e6-babe-28b2bd168d07 | ONLINE |
| 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | UNREACHABLE |
| 19b33846-4aaf-11e6-ba81-28b2bd168d07 | UNREACHABLE |
+--------------------------------------+--------------+首先要做的是检查 s1 和 s2 的本地地址(组通信标识符)。登录到 s1 和 s2,并按照以下方式获取该信息。
在 s1 和 s2 上执行以下命令:
mysql> SELECT @@group_replication_local_address;一旦您知道了 s1(127.0.0.1:10000)和 s2(127.0.0.1:10001)的组通信地址,您就可以在其中一个服务器上使用该信息来注入一个新的成员配置,从而覆盖掉已经失去法定人数的现有配置。在 s1 上执行以下操作:
mysql> SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";这将通过强制不同的配置来解除组的阻塞。在此更改后,检查 s1 和 s2 上的 replication_group_members,以验证组成员资格。首先在 s1 上执行:
mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+然后在 s2 上执行:
mysql> SELECT * FROM performance_schema.replication_group_members;
+--------------------------------------+--------------+
| MEMBER_ID | MEMBER_STATE |
+--------------------------------------+--------------+
| b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | ONLINE |
| b60907e7-4ab6-11e6-afb7-28b2bd168d07 | ONLINE |
+--------------------------------------+--------------+在强制使用新的成员配置时,请确保将要被强制退出组的任何服务器确实已停止。在上述场景中,如果 s3、s4 和 s5 实际上并非无法访问,而是在线的,它们可能已经形成了自己的功能分区(它们是 5 个服务器中的 3 个,因此它们拥有多数)。在这种情况下,强制使用包含 s1 和 s2 的组成员列表可能会导致人为的脑分裂情况。因此,在强制使用新的成员配置之前,确保要排除的服务器确实已关闭,并在继续之前关闭它们。
在成功强制新的组成员配置并解除组阻塞后,请确保清除该系统变量。group_replication_force_members 必须为空,才能发出 START GROUP_REPLICATION 语句。
17.5.4 Restarting a Group
Group Replication旨在确保数据库服务始终可用,即使组成该组的某些服务器当前由于计划维护或意外问题而无法参与其中。只要剩余成员是组的大多数,它们就可以选举一个新的主服务器并继续作为一个组运行。然而,如果复制组的每个成员都离开了组,并且每个成员上都通过STOP GROUP_REPLICATION语句或系统关闭停止了Group Replication,那么该组现在只存在于理论上,作为成员上的一个配置。在这种情况下,要重新创建组,必须像第一次启动一样通过引导启动。
第一次引导组和第二次或后续引导组之间的区别在于,在后一种情况下,已关闭组的成员可能具有彼此不同的事务集,这取决于它们停止或失败的顺序。如果成员具有其他组成员上不存在的事务,则不能加入组。对于Group Replication,这包括已提交和已应用的事务,位于gtid_executed GTID集中的事务,以及已认证但尚未应用的事务,位于group_replication_applier通道中。 Group Replication组成员永远不会删除已认证的事务,这是成员打算提交事务的声明。
因此,必须重新启动复制组,从最新的成员开始,即具有执行和认证最多事务的成员。然后,具有较少事务的成员可以加入并通过分布式恢复赶上它们丢失的事务。不能假设组的最后已知的主成员是组的最新成员,因为稍后关闭的成员可能具有更多事务。因此,必须重新启动每个成员以检查事务,比较所有事务集,并确定最新的成员。然后可以使用该成员引导组。
按照以下步骤,在每个成员关闭后安全地重新启动复制组。
1 对于每个组成员,按任意顺序执行以下步骤:
- 连接到该组成员的客户端。如果 Group Replication 尚未停止,请发出 STOP GROUP_REPLICATION 命令,并等待 Group Replication 停止。
- 编辑 MySQL 服务器配置文件(在 Linux 和 Unix 系统上通常命名为 my.cnf,在 Windows 系统上通常命名为 my.ini),并设置系统变量 group_replication_start_on_boot=OFF。该设置阻止了 MySQL 服务器启动时自动启动 Group Replication,这是默认行为。如果您无法更改系统上的该设置,则可以允许服务器尝试启动 Group Replication,这将失败,因为组已完全关闭并且尚未启动引导。如果采用此方法,请不要在此阶段将 group_replication_bootstrap_group=ON 设置为任何服务器。
- 启动 MySQL 服务器实例,并验证 Group Replication 尚未启动(或已启动失败)。在此阶段不要启动 Group Replication。
- 从组成员收集以下信息:
- gtid_executed GTID 集的内容。您可以通过执行以下语句来获取此信息:
mysql> SELECT @@GLOBAL.GTID_EXECUTED;- group_replication_applier 通道上的已认证事务集。您可以通过执行以下语句来获取此信息:
mysql> SELECT received_transaction_set FROM \
performance_schema.replication_connection_status WHERE \
channel_name="group_replication_applier";接下来的步骤将依据这些信息进行。
2. 当您收集了所有组成员的事务集后,比较它们以找出哪个成员具有最大的事务集,包括已执行的事务(gtid_executed)和已认证的事务(在 group_replication_applier 通道上)。您可以通过查看 GTID 来手动执行此操作,或者使用存储函数比较 GTID 集,如第 16.1.3.7 节中所述的“用于操作 GTID 的存储函数示例”。
3. 使用具有最大事务集的成员来引导组,方法是连接到该组成员的客户端,然后执行以下语句:
mysql> SET GLOBAL group_replication_bootstrap_group=ON;
mysql> START GROUP_REPLICATION;
mysql> SET GLOBAL group_replication_bootstrap_group=OFF;重要提示:不要将设置 group_replication_bootstrap_group=ON 存储在配置文件中,否则当服务器再次启动时,会设置一个具有相同名称的第二个组。
4. 要验证该组现在是否存在,并且有这个创建者成员在其中,请在引导它的成员上执行以下语句:
mysql> SELECT * FROM performance_schema.replication_group_members;5. 以任意顺序将其他成员添加回组中,通过在每个成员上执行 START GROUP_REPLICATION 语句:
mysql> START GROUP_REPLICATION;6. 要验证每个成员是否已加入组,请在任意成员上执行以下语句:
mysql> SELECT * FROM performance_schema.replication_group_members;7. 当成员重新加入组时,如果您编辑了它们的配置文件以将 group_replication_start_on_boot=OFF 设置为关闭状态,则可以再次编辑它们以将其设置为开启状态(或删除该系统变量,因为 ON 是默认值)。
17.5.5 Using MySQL Enterprise Backup with Group Replication
原文地址:https://blog.csdn.net/weixin_48154829/article/details/136462037
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!