Linux多线程服务端编程:使用muduo C++网络库 学习笔记 附录A 谈一谈网络编程学习经验
本文谈一谈作者在学习网络编程方面的一些个人经验。“网络编程”这个术语的范围很广,本文指用Sockets API开发基于TCP/IP的网络应用程序,具体定义见A.1.5 “网络编程的各种任务角色”。
受限于作者的经历和经验,本附录的适应范围是:
1.x86-64 Linux服务端网络编程,直接或间接使用Sockets API。
2.公司内网。不一定是局域网,但总体位于公司防火墙之内,环境可控。
文本可能不适合:
1.PC客户端网络编程,程序运行在客户的PC上,环境多变且不可控。
2.Windows网络编程。
3.面向公网的服务程序。
4.高性能网络服务器。
本文分为两个部分:
1.网络编程的一些“胡思乱想”,以自问自答的形式谈谈作者对这一领域的认识。
2.几本必看的书,基本上还是W.Richard Stevents的那几本。
另外,本文没有特别说明时均暗指TCP协议,“连接”是“TCP连接”,“服务端”是“TCP服务端”。
A.1 网络编程的一些“胡思乱想”
以下大致列出作者对网络编程的一些想法,前后无关联。
A.1.1 网络编程是什么
网络编程是什么?是熟练使用Sockets API吗?说实话,在实际项目里作者只用过两次Sockets API,其他时候都是使用封装好的网络库。
第一次是2005年在学校做一个羽毛球赛场计分系统:作者用C#编写运行在PC上的软件,负责比分的显示;再用C#写了运行在PDA(个人数字助理,一种便携式电子设备,随着智能手机的普及,PDA已逐渐被手机取代)上的计分界面,记分员拿着PDA记录比分;这两部分程序通过TCP协议相互通信。这其实是个简单的分布式系统,体育馆有几片场地,每个场地都有一名拿PDA的记分员,每个场地都有两台显示比分的PC(显示器是42寸平板电视,放在场地的对角,这样两边的观众都能看到比分)。这两台PC的功能不完全一样,一台只负责显示当前比分,另一台还要负责与PDA通信,并更新数据库里的比分信息。此外,还有一台PC负责周期性地从数据库读出全部7片场地的比分,显示在体育馆墙上的大屏幕上。这台PC上还运行着一个程序,负责生成比分数据的静态页面,通过FTP上传发布到某门户网站的体育频道。系统中还有一个录入赛程(参赛队、运动员、出场顺序等)数据库的程序,运行在数据库服务器上。算下来整个系统有十来个程序,运行在二十多台设备(PC和PDA)上,还要考虑可靠性,避免single point of failure。
这是作者第一次写实际项目中的网络程序,当时写下来的感觉是像写命令行与用户交互的程序:程序在命令行输出一句提示语,等待客户输入一句话,然后处理客户输入,再输出下一句提示语,如此循环。只不过这里的“客户”不是人,而是另一个程序。在建立好TCP连接之后,双方的程序都是read/write循环(为求简单,作者用的blocking读写),直到有一方断开连接。
第二次是2010年编写muduo网络库,作者再次拿起了Sockets API,写了一个基于Reactor模式的C++网络库。写这个库的目的之一就是想让日常的网络编程从Sockets API的琐碎细节中解脱出来,让程序员专注于业务逻辑,把时间用在刀刃上。muduo网络库的示例代码包含了几十个网络程序,这些示例程序都没有直接使用Sockets API。
在此之外,无论是实习还是工作,虽然作者写的程序都会通过TCP协议与其他程序打交道,但作者没有直接使用过Sockets API。对于TCP网络编程,作者认为核心是处理“三个半事件”,见第六章。程序员的主要工作是在事件处理函数中实现业务逻辑,而不是和Sockets API“较劲”。
这里还是没有说清楚“网络编程”是什么,请继续阅读后文A.1.5 “网络编程的各种任务角色”。
A.1.2 学习网络编程有用吗
以上说的是比较底层的网络编程,程序代码直接面对从TCP或UDP收到的数据以及构造数据包发出去。在实际工作中,另一种常见的情况是通过各种client library来与服务端打交道,或者在现成的框架中填空来实现server,或者采用更上层的通信方式。比如用libmemcached与memcached打交道,使用libpq来与PostgreSQL打交道,编写Servlet来响应HTTP请求,使用某种RPC与其他进程通信,等等。这些情况都会发生网络通信,但不一定算作“网络编程”。如果你的工作是前面列举的这些,学习TCP/IP网络编程还有用吗?
作者认为还是有必要学一学,至少在troubleshooting的时候有用。无论如何,这些library或framework都会调用底层Socket API来实现网络功能。当你的程序遇到一个线上问题时,如果你熟悉Sockets API,那么从strace不难发现程序卡在哪里,尽管可能你没有直接调用这些Sockets API。另外,熟悉TCP/IP协议、会用tcpdump也非常有助于分析解决线上网络服务问题。
A.1.3 在什么平台上学习网络编程
对于服务端网络编程,作者建议在Linux上学习。
如果在10年前,这个问题的答案或许是FreeBSD,因为FreeBSD“根正苗红”,在2000年那一次互联网浪潮中扮演了重要角色,是很多公司首选的免费服务器操作系统。2000年那会儿Linux还远未成熟,连epoll都还没有实现(FreeBSD在2001年发布4.1版,加入了kqueue,从此C10k不是问题)。
10年后的今天,事情起了一些变化,Linux成为市场份额最大的服务器操作系统(http://en.wikipedia.org/wiki/Usage_share_of_operating_systems)。在Linux这种大众系统上学习网络编程,遇到什么问题会比较容易解决。因为用的人多,你遇到的问题别人多半也遇到过;同样因为用的人多,如果真的有什么内核bug,很快就会得到修复,至少有work around的办法。如果用别的系统,可能一个问题发到论坛上半个月都不会有人理。从内核源码的风格看,FreeBSD更干净整洁,注释到位,但是无奈它的市场份额远不如Linux,学习Linux是更好的技术投资。
A.1.4 可移植性重要吗
写完过程需要不要考虑移植性?要不要跨平台?这取决于项目需要,如果贵公司做的程序要卖给其他公司,而对方可能使用Windows、Linux、FreeBSD、Solaris、AIX、HP-UX等等操作系统,这时候当然要考虑移植性。如果编写公司内部的服务器上用的网络程序,那么大可只关注一个平台,比如Linux。因为编写和维护可移植的网络程序的代价相当高,平台间的差异可能远比想象中大,即便是POSIX系统之间也有不小的差异(比如Linux没有SO_NOSIGPIPE选项(向一个已关闭的套接字写入数据时,系统会发送SIGPIPE信号给写进程。默认情况下,该信号会导致进程终止,使用SO_NOSIGPIPE选项时,系统将不会发送SIGPIPE信号,而是返回一个错误码),Linux的pipe(2)是单向的,而FreeBSD是双向的),返回的错误码也大不一样。
作者就不打算把muduo往Windows或其他操作系统移植。如果需要编写可移植的网络程序,作者宁愿用libevent、libuv、Java Netty这样现成的库,把“脏活、累活”留给别人。
A.1.5 网络编程的各种任务角色
计算机网络是个big topic,涉及很多人物和角色,既有开发人员,也有运维人员。比方说:公司内部两台机器之间ping不通,通常由网络运维人员解决,看看是布线有问题还是路由器设置不对;两台机器能ping通,但是程序连不上,经检查是本机防火墙设置有问题,通常由系统管理员解决;两台机器能连上,但是丢包很严重,发现是网卡或者交换机的网口故障,由硬件维修人员解决;两台机器的程序能连上,但是偶尔发过去的请求得不到响应,通常是程序bug,应该由开发人员解决。
本文主要关心开发人员这一角色。下面简单列出一些作者能想到的跟网络打交道的编程任务,其中前三项是面向网络本身,后面几项是在计算机网络之上构建信息系统。
1.开发网络设备,编写防火墙、交换机、路由器的固件(firmware)。
2.开发或移植网卡的驱动。
3.移植或维护TCP/IP协议栈(特别是在嵌入式系统上)。
4.开发或维护标准的网络协议程序,HTTP、FTP、DNS、SMTP、POP3、NFS。
5.开发标准网络协议的“附加品”,比如HAProxy(High Availability Proxy,一种免费、快速、可靠的开源负载均衡和代理软件,它可以将传入的流量分发到多个后端服务器,以实现高可用性、可扩展性和性能优化)、squid(一个开源的代理服务器和网页缓存软件)、varnish(一个开源的高性能HTTP加速器,原理是利用内存中的缓存来存储经常请求的内容,也是一个反向HTTP代理服务器)等Web load balancer。
上面提到的反向HTTP代理服务器指在internet和服务端之间的代理,而正向(前向)HTTP代理服务器指客户到internet之间的代理。正向HTTP代理服务器一般用于隐藏客户的真实IP地址,或限制该客户对特定网站或内容的访问;反向HTTP代理服务器一般用于负载均衡,将请求分发到多个后端服务器上,以提高性能和可用性,或缓存经常请求的内容,减少对后端服务器的请求,提高响应速度,或作为安全屏障,隐藏真实的服务器IP地址,并过滤和检查传入的请求。一般正向HTTP代理部署在企业内部网络等地方,而反向HTTP代理部署在数据中心或云服务提供商的服务器上。
6.开发标准或非标准网络服务的客户端库,比如ZooKeeper客户端库、memcached客户端库。
7.开发与公司业务直接相关的网络服务程序,比如即时聊天软件的后台服务器、网游服务器、金融交易系统、互联网企业用的分布式海量存储、微博发帖的内部广播通知等等。
8.客户端程序中涉及网络的部分,比如邮件客户端中与POP3(Post Office Protocol version 3,一种用于从邮件服务器接收电子邮件的标准协议)、SMTP通信的部分,以及网游的客户端程序中与服务器通信的部分。
本文所指的“网络编程”专指第7项,即在TCP/IP协议之上开发业务软件。换句话说,不是用Sockets API开发muduo这样的网络库,而是用libevent、muduo、Netty、gevent(一个Python的第三方库,提供了一个简单易用的高性能异步 I/O 框架)这样现成的库开发业务软件,muduo自带的十几个示例程序是业务软件的代表。
A.1.6 面向业务的网络编程的特点
与通用的网络服务器不同,面向公司业务的专用网络程序有其自身的特点。
业务逻辑比较复杂,而且时常变化
如果写一个HTTP服务器,在大致实现HTTP 1.1标准之后,程序的主体功能一般不会有太大的变化,程序员会把时间放在性能调优和bug修复上。而开发针对公司业务的专用程序时,功能说明书(spec)很可能不如HTTP 1.1标准那么细致明确。更重要的是,程序是快速演化的。以即时聊天工具的后台服务器为例,可能第一版只支持在线聊天;几个月之后发布第二版,支持离线消息;又过了几个月,第三版支持隐身聊天;随后,第四版支持上传头像;如此等等。这要求程序员能快速响应新的业务需求,公司才能保持竞争力。由于业务时常变化(假设每月一次版本升级),也会降低服务程序连续运行时间的要求。相反,我们要设计一套流程,通过轮流重启服务器来完成平滑升级(9.2.2)。
不一定需要遵循公认的通信协议标准
比方说网游服务器就没什么协议标准,反正客户端和服务端都是本公司开发的,如果发现目前的协议设计有问题,两边一起改就行了。由于可以自己设计协议,因此我们可以绕开一些性能难点,简化程序结构。比方说,对于多线程的服务程序,如果用短连接TCP协议,为了优化性能通常要精心设计accept新连接的机制(必要时甚至要修改Linux内核),避免惊群并减少上下文切换。但是如果改用长连接,用最简单的单线程accept就行了。
程序结构没有定论
对于高并发大吞吐的标准网络服务,一般采用单线程事件驱动的方式开发,比如HAProxy、lighttpd等都是这个模式。但是对于专用的业务系统,其业务逻辑比较复杂,占用较多的CPU资源,这种单线程事件驱动方式不见得能发挥现在多核处理器的优势。这留给程序员比较大的自由发挥空间,做好了“横扫千军”,做烂了一败涂地。作者认为目前one loop per thread是通用性较高的一种程序结构,能发挥多核的优势,见第三章和第六章。
性能评判的标准不同
如果开发httpd这样的通用服务,必然会和开源的Nginx、lighttpd等高性能服务器比较,程序员要投入相当的精力去优化程序,才能在市场上占有一席之地。而面向业务的专用网络程序不一定是IO bound(计算任务的执行受限于IO),也不一定有开源的实现以供对比性能,优化方向也可能不同。程序员通常更加注重功能的稳定性与开发的便捷性。性能只要一代比一代强即可。
网络编程起到支撑作用,但不处于主导地位
程序员的主要工作是实现业务逻辑,而不只是实现网络通信协议。这要求程序员深入理解业务。程序的性能瓶颈不一定在网络上,瓶颈有可能是CPU、Disk IO、数据库等,这时优化网络方面的代码并不能提高整体性能。只有对所在的领域有深入的了解,明白各种因素的权衡(trade-off),才能做出一些有针对性的优化。现在的机器上,简单的并发长连接echo服务程序不用特别优化就能做到十多万qps,但是如果每个业务请求需要1ms密集计算,在8核机器上充其量能达到8000qps,优化IO不如去优化业务计算(如果投入产出合算的话)。
A.1.7 几个术语
互联网上的很多“口水战”是由对同一术语的不同理解引起的,比如作者写的《多线程服务器的适用场合》(http://blog.csdn.net/solstice/article/details/5334243,收入本书第3章),就曾被人说是“挂羊头卖狗肉”,因为这篇文章中举的master例子“根本就算不上是个网络服务器。因为它的瓶颈根本就跟网络无关”。
网络服务器
“网络服务器”这个术语确实含义模糊,到底指硬件还是软件?到底是服务于网络本身的机器(交换机、路由器、防火墙、NAT),还是利用网络为其他人或程序提供服务的机器(打印服务器、文件服务器、邮件服务器)?每个人根据自己熟悉的领域,可能会有不同的解读。比方说,或许有人认为只有支持高并发、高吞吐量的才算是网络服务器。
为了避免无谓的争执,作者只用“网络服务程序”或者“网络应用程序”这种含义明确的术语。“开发网络服务程序”通常不会造成误解。
客户端?服务端?
在TCP网络编程中,客户端和服务端很容易区分,主动发起连接的是客户端,被动接受连接的是服务端。当然,这个“客户端”本身也可能是个后台服务程序,HTTP proxy对HTTP server来说就是个客户端。
客户端编程?服务端编程?
但是“服务端编程”和“客户端编程”就不那么好区分了。比如Web crawler(网络爬虫),它会主动发起大量连接,扮演的是HTTP客户端的角色,但似乎应该归入“服务端编程”。又比如写一个HTTP proxy,它既会扮演服务端——被动接受Web browser发起的连接,也会扮演客户端——主动向HTTP server发起连接,它究竟算服务端还是客户端?作者猜大多数人会把它归入服务端编程。
那么究竟如何定义“服务端编程”?
服务端编程需要处理大量并发连接?也许是,也许不是。比如云风在一篇介绍网游服务器的博客(http://blog.codingnow.com/2006/04/iocp_kqueue_epoll.html)中就谈到,网游中用到的“连接服务器”需要处理大量连接,而“逻辑服务器”只有一个外部连接。那么开发这种网游“逻辑服务器”算服务端变成还是客户端编程呢?又比如机房的服务进程监控软件,并发数跟机器数成正比,至多也就是两三千的并发连接(再大规模就超出本书的范围了)。
作者认为,“服务端网络编程”指的是编写没有用户界面的长期运行的网络程序,程序默默地运行在一台服务器上,通过网络与其他程序打交道,而不必和人打交道。与之对应的是客户端网络程序,要么是短时间运行,比如wget;要么是有用户界面(无论是字符界面还是图形界面)。本文主要谈服务端网络编程。
A.1.8 7×24重要吗,内存碎片可怕吗
一谈到服务端网络编程,有人立刻会提出7×24运行的要求。对于某些网络设备而言,这是合理的需求,比如交换机、路由器。对于开发商业系统,作者认为要求程序7×24运行通常是系统设计上考虑不周。具体见本书第九章。重要的不是7×24,而是程序不必做到7×24的情况下也能达到足够高的可用性。一个考虑周到的系统应该允许每个进程都能随时重启,这样才能在廉价的服务器硬件上做到高可用性。
既然不要求7×24,那么也不必害怕内存碎片(http://stackoverflow.com/questions/3770457/what-is-memory-fragment)(http://stackoverflow.com/questions/60871/how-to-solve-memory-fragment),理由如下:
1.64-bit系统的地址空间足够大,不会出现没有足够的连续空间这种情况。有没有谁能够故意制造内存碎片(不是内存泄漏)使得服务程序失去响应?
2.现在的内存分配器(malloc及其第三方实现)今非昔比,除了memcached这种纯以内存为卖点的程序需要自己设计分配器之外,其他网络程序大可使用系统自带的malloc或者某个第三方实现。重新发明memory pool似乎已经不流行了(12.2.8)。
3.Linux Kernel也大量用到了动态内存分配。既然操作系统内核都不怕动态分配内存造成碎片,应用程序为什么要害怕?应用程序的可靠性只要不低于硬件和操作系统的可靠性就行。普通PC服务器的年故障率为3%~5%,算一算你的服务程序一年要被意外重启多少次。
4.内存碎片如何度量?有没有什么工具能为当前进程的内存碎片状况评个分?如何不能比较两种方案的内存碎片程序,谈何优化?
有人为了避免内存碎片,不使用STL容器,也不敢new/delete,这算是premature optimization(编程过程中过早地尝试优化代码,而不是首先专注于正确性、可读性和可维护性,这种行为通常是不明智的,因为在优化之前,我们往往没有足够的信息来确定哪些部分是性能瓶颈,因此很容易陷入过度优化的陷阱)还是因噎废食呢?
A.1.9 协议设计是网络编程的核心
对于专用的业务系统,协议设计是核心任务,决定了系统的开发难度与可靠性,但是这个领域还没有形成大家公认的设计流程。
系统中哪个程序发起连接,哪个程序接受连接?如果写标准的网络服务,那么这不是问题,按RFC来就行了。自己设计业务系统,有没有章法可循?以网游为例,到底是连接服务器主动连接逻辑服务器,还是逻辑服务器主动连接“连接服务器”?似乎没有定论,两种做法都行。一般可以按照“依赖->被依赖”的关系来设计发起连接的方向。
比新建连接难的是关闭连接。在传统的网络服务中(特别是短连接服务),不少是服务端主动关闭连接,比如daytime、HTTP 1.0。也有少部分是客户端主动关闭连接,通常是些长连接服务,比如echo、chargen等。我们自己的业务系统该如何设计连接关闭协议呢?
服务端主动关闭连接的缺点之一是会多占用服务器资源。服务端主动关闭连接之后会进入TIME_WAIT状态,在一段时间之内持有(hold)一些内核资源。如果并发访问量很高,就会影响服务端的处理能力。这似乎暗示我们应该把协议设计为客户端主动关闭,让TIME_WAIT状态分散到多台客户机器上,化整为零。
这又有另外的问题:客户端赖着不走怎么办?会不会造成拒绝服务攻击?或许有一个二者结合的方案:客户端在收到相应之后就应该主动关闭,这样把TIME_WAIT留在客户端(s)。服务端有一个定时器,如果客户端若干秒之内没有主动断开,就踢掉它。这样善意的客户端会把TIME_WAIT留给自己,buggy的客户端会把TIME_WAIT留给服务端。或者干脆使用长连接协议,这样可以避免频繁创建、销毁连接。
比连接的建立与断开更重要的是设计消息协议。消息格式很好办,XML、JSON、Protobuf都是很好的选择;难的是消息内容。一个消息应该包含哪些内容?多个程序相互通信如何避免race condition(第九章)?外部事件发生时,网络消息应该发snapshot还是delta?新增功能时,各个组件如何平滑升级?
可惜这方面可供参考的例子不多,也没有太多通用的指导原则,作者知道的只有30年前提出的end-to-end principle(网络中的中间节点应该尽可能简单,只提供最基本的传输服务,而复杂的处理应该由端系统来完成)和happens-before relationship(并发编程中的一个重要概念,用于描述事件之间的顺序关系,它指示一个事件发生在另一个事件之前)。只能从实践中慢慢积累了。
A.1.10 网络编程的三个层次
侯捷先生在《漫谈程序员与编程》中讲到STL运用的三个档次:“会用STL,是一种档次。对STL原理有所了解,又是一个档次。追踪过STL源码,又是一个档次。第三种档次的人用起STL来,虎虎生风之势绝非第一档次的人能够望其项背。”
作者认为网络编程也可以分为三个层次:
1.读过教程和文档,做过练习;
2.熟悉本系统TCP/IP协议栈的脾气;
3.自己写过一个简单的TCP/IP stack。
第一个层次是基本要求,读过《UNIX网络编程》这样的编程教材,读过《TCP/IP详解》并基本理解TCP/IP协议,读过本系统的manpage。在这个层次,可以编写一些基本的网络程序,完成常见的任务。但网络编程不是照猫画虎这么简单,若是按照manpage的功能描述就能编写产品级的网络程序,那人生就太幸福了。
第二个层次,熟悉本系统的TCP/IP协议栈参数设置与优化是开发高性能网络程序的必备条件。摸透协议栈的脾气,还能解决工作中遇到的比较复杂的网络问题。拿Linux的TCP/IP协议栈来说:
1.有可能出现TCP自连接(self-connection)(见第八章和《学之者生,用之者死——ACE历史与简评》举的三个硬伤,http://blog.csdn.net/solstice/article/details/5364096),程序应该有所准备。
2.Linux的内核会有bug,比如某种TCP拥塞控制算法曾经出现TCP window clamping(窗口箝位)bug(窗口大小被限制在一个较小的值,而不是根据网络状况进行调整),导致吞吐量暴跌,可以选用其他拥塞控制算法来绕开(work around)这个问题。
这些“阴暗角落”在manpage里没有描述,要通过其他渠道了解。
编写可靠的网络程序的关键是熟悉各种场景下的error code(文件描述符用完了如何?本地ephemeral port暂时用完,不能发起新链接怎么办?服务端新建并发连接太快,backlog用完了,客户端connect会返回什么错误?),有的在manpage里有描述,有的要通过实践或阅读源码获得。
第三个层次,通过自己写一个简单的TCP/IP协议栈,能大大加深对TCP/IP的理解,更能明白TCP为什么要这么设计,有哪些因素制约,每一步操作的代价是什么,写起网络程序来更是成竹在胸。
其实实现TCP/IP只需要操作系统提供三个接口函数:一个函数,两个回调函数。分别是:send_packet()、on_receive_packet()、on_timer()。多年前有一篇文章《使用libnet与libpcap构造TCP/IP协议软件》介绍了在用户态实现TCP/IP的方法。lwIP(lightweight IP,一个用C语言编写的开源的嵌入式TCP/IP协议栈,专为嵌入式系统设计,具有轻量级、高性能和可移植性等特点)也是很好的借鉴对象。
如果有时间,作者打算自己写一个Mini/Tiny/Toy/Trivial/Yet-Another TCP/IP。作者准备换一个思路,用TUN/TAP(一种虚拟网络设备,用于在用户空间程序和内核之间创建网络数据包的交换通道,TUN代表“网络隧道(network TUNnel)”,而TAP代表“网络附加(network TAP)”;TUN设备工作在网络层(第三层),因此它传输的是IP数据包,可用于建立点对点的虚拟网络连接;TAP设备工作在数据链路层(第二层),因此它传输的是以太网帧,可以模拟一个网络交换机,允许多个虚拟机或用户空间程序通过TAP设备连接到同一个虚拟以太网)设备在用户态实现一个能与本机点对点通信的TCP/IP协议栈(见本书附录D),这样那三个接口函数就表现为作者最熟悉的文件读写。在用户态实现的好处是便于调试,协议栈做成静态库,与应用程序链接到一起(库的接口不必是标准的Sockets API)。写完这一版协议栈,还可以继续发挥,用FTDI(Future Technology Devices International,一家总部位于英国格拉斯哥的公司)的USB-SPI接口芯片(一种集成了USB和SPI(Serial Peripheral Interface)功能的芯片,它允许将USB接口与SPI总线连接起来,从而实现USB主机与SPI设备之间的通信)连接ENC28J60适配器(是一种基于Microchip公司的ENC28J60芯片的网络适配器,用于将嵌入式系统连接到局域网(LAN)或因特网(Internet)),做一个真正独立于操作系统的TCP/IP stack。如果只实现最基本的IP、ICMP Echo、TCP,代码应能控制在3000行以内;也可以实现UDP,如果应用程序需要用到DNS的话。
A.1.11 最主要的三个例子
作者认为TCP网络编程有三个例子最值得学习研究,分别是echo、chat、proxy,都是长连接协议。
echo的作用:熟悉服务端被动接受新连接、收发数据、被动处理连接断开。每个连接是独立服务的,连接之间没有关联。在消息内容方面echo有一些变种:比如做成一问一答的方式,收到的请求和发送响应的内容不一样,这时候要考虑打包与拆包格式的设计,进一步还可以写简单的HTTP服务。
chat的作用:连接之间的数据有交流,从a收到的数据要发给b。这样对连接管理提出了更高的要求:如何用一个程序同时处理多个连接?fork()-per-connection似乎是不行的。如何防止串话?b有可能随时断开连接,而新建立的连接c可能恰好复用了b的文件描述符,那么a会不会错误地把消息发给c?
proxy的作用:连接的管理更加复杂:既要被动接受连接,也要主动发起连接;既要主动关闭连接,也要被动关闭连接。还要考虑两边速度不匹配(第七章)。
这三个例子功能简单,突出了TCP网络编程中的重点问题,挨着做一遍基本就能达到层次一的要求。
A.1.12 学习Sockets API的利器:IPython
作者在编写muduo网络库的时候,写了一个命令行交互式的调试工具(http://blog.csdn.net/solstice/article/details/5497814),方便试验各个Sockets API的返回时机和返回值。后来发现其实可以用IPython达到相同的效果,不必自己编程。用交互式工具很快就能摸清各种IO事件的发生条件,比反复编译C代码高效得多。比方说想简单试验一下TCP服务器和epoll,可以这么写:

同时在令一个命令行窗口用nc发送数据:

在编写muduo的时候,作者一般会开四个命令行窗口,其一看log,其二看strace,其三用netcat/tempest/ipython充作通信对方,其四看tcpdump。各个工具的输出相互验证,很快就摸清了门道。muduo是一个基于Reactor模式的Linux C++网络库,采用非阻塞IO,支持高并发和多线程,核心代码量不大(4000多行),示例丰富,可供网络编程的学习者参考。
A.1.13 TCP的可靠性有多高
TCP是“面向连接的、可靠的、字节流传输协议”,这里的“可靠”究竟是什么意思?《Effective TCP/IP Programming》第9条说:“Realize That TCP Is a Reliable Protocol, Not an Infallible Protocol”,那么TCP在哪种情况下会出错?这里说的“出错”指的是收到的数据与发送的数据不一致,而不是数据不可达。
作者在第七章“一种自动反射消息类型的Google Protobuf网络传输方案”中设计了带check sum的消息格式,很多人表示不理解,认为是多余的。IP header中有check sum,TCP header也有check sum,链路层以太网还有CRC32校验,那么为什么还需要在应用层做校验?什么情况下TCP传送的数据会出错?
IP header和TCP header的checksum是一种非常弱的16-bit check sum算法,其把数据当成反码表示的16-bit integers,再加到一起。这种checksum算法能检出一些简单的错误,而对某些错误无能为力。由于是简单的假发,遇到“和(sum)”不变的情况就无法检查出错误(比如交换两个16-bit整数,加法满足交换律,checksum不变)。以太网的CRC32只能保证同一个网段上的通信不会出错(两台机器的网线插到同一个交换机上,这时候以太网的CTC是有用的)。但是,如果两台机器之间经过了多级路由器呢?
图A-1中client向server发了一个TCP segment,这个segment先被封装成一个IP packet,再被封装成ethernet frame,发送到路由器(图A-1中的消息a)。router收到ethernet frame b,转发到另一个网段(消息c),最后server收到d,通知应用程序。以太网CRC能保证a和b相同,c和d相同;TCP header checksum的强度不足以保证收发payload的内容一样。另外,如果把router换成NAT,那么NAT自己会构造消息c(替换掉源地址),这时候a和d的payload不能用TCP header checksum校验。
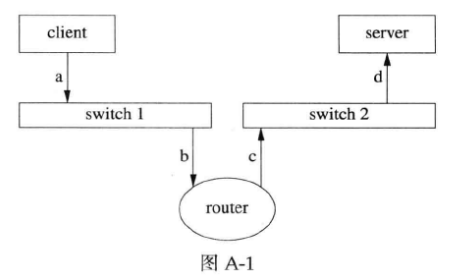
路由器可能出现硬件故障,比方说它的内存故障(或偶然错误)导致收发IP报文出现多bit的反转或双字节交换,这个反转如果发生在payload区,那么无法用链路层、网络层、传输层的check sum查出来,只能通过应用层的check sum来检测。这个现象在开发的时候不会遇到,因为开发用的几台机器很可能都连到同一个交换机,ethernet CRC能防止错误。开发和测试的时候数据量不大,错误很难发生。之后大规模部署到生产环境,网络环境复杂,这个时候出个错就让人措手不及。有一篇论文《When the CRC and TCP checksum disagree》分析了这个问题。另外《The Limitaions of the Ethernet CRC and TCP/IP checksums for error detection》(http://noahdavids.org/self_published/CRC_and_checksum.html)也值得一读。
这个情况真的会发生吗?会的,Amazon S3在2008年7月就遇到过,单bit反转导致了一次严重线上事故,所以他们吸取教训加了check sum)。
另外一个例证:下载大文件的时候一般都会附上MD5,这除了有安全方面的考虑(防止篡改),也说明应用层应该自己设法校验数据的正确性。这是end-to-end principle的一个例证。
A.2 三本必看的书
谈到Unix编程和网络编程,W.Richard Stevens是个绕不开的人物,他生前写了6本书,即[APUE]、两卷《UNIX网络编程》、三卷《TCP/IP详解》。其中四本与网络编程直接相关。[UNPv2]其实跟网络编程关系不大,是[APUE]在多线程和进程间通信(IPC)方面的补充。很多人把《TCP/IP详解》一二三卷作为整体推荐,其实这三本书的用处不同,应该区别对待。
这里谈到的几本书都没有超出孟岩在《TCP/IP网络编程之四书五经》中的推荐,说明网络编程这一领域已经相对成熟稳定。
第一本:《TCP/IP Illustrated, Vol. 1:The Protocols》(中文名《TCP/IP详解》),以下简称TCPv1。
TCPv1是一本奇书。这本书迄今至少被三百多篇学术论文引用过(http://portal.acm.org/citation.cfm?id=161724)。一本学术专著被论文引用算不上出奇,难得的是一本写给程序员看的技术书能被学术论文引用几百次,不知道还有哪本书能做到这一点。
TCPv1堪称TCP/IP领域的圣经。作者W. Richard Stevens不是TCP/IP协议的发明人,他从使用者(程序员)的角度,以tcpdump为工具,对TCP协议抽丝剥茧、娓娓道来(第17~24章),让人叹服。恐怕TCP协议的设计者也难以讲解得如此出色,至少不会像他这么耐心细致地画几百幅收发package的时序图。
TCP作为一个可靠的传输层协议,其核心有三点:
1.Positive acknowledgement with retransmission;
2.Flow control using sliding window(包括Nagle算法等);
3.Congestion control(包括slow start、congestion avoidance、fast retransmit等)。
第一点已经足以满足“可靠性”要求(为什么?);第二点是为了提高吞吐量,充分利用链路层带宽;第三点是防止过载造成丢包。换言之,第二点是避免发得太慢,第三点是避免发得太快,二者相互制约。从反馈控制的角度看,TCP像是一个自适应的节流阀,根据管道的拥堵情况自动调整阀门的流量。
TCP的flow control有一个问题,每个TCP connection是彼此独立的,保存着自己的状态变量;一个程序如果同时开启多个连接,或者操作系统中运行多个网络程序,这些连接似乎不知道他人的存在,缺少对网卡贷款的统筹安排(或许现代的操作系统已经解决了这个问题?)。
TCPv1唯一的不足是它出版得太早了,1993年至今网络技术发展了几代。链路层方面,当面主流的10Mbit网卡和集线器早已经被淘汰;100Mbit以太网也没什么企业在用了,交换机(switch)也已经全面取代了集线器(hub);服务器机房以1Gbit网络为主,有些场合甚至用上了10Gbit以太网。另外,无线网的普及也让TCP flow control面临新挑战;原来设计TCP的时候,人们认为丢包通常是拥塞造成的,这是应该放慢发送速度,减轻拥塞;而在无线网中,丢包可能是信号太弱造成的,这时反而应该快速重试,以保证性能。网络层方面变化不大,IPv6“雷声大、雨点小”。传输层方面,由于链路层带宽大增,TCP window scale option被普遍使用,另外TCP timestamps option和TCP selective ack option也很常用。由于这些因素,在现在的Linux机器上运行tcpdump观察TCP协议,程序输出会与原书有些不同。
一个好消息:TCPv1已于2011年10月推出第2版,经典能否重现?
第二本《Unix Network Programming, Vol. 1:Networking API》第2版或第3版(这两版的副标题稍有不同,第3版去掉了XTI(X/Open Transport Interface,UNIX系统上用于网络编程的一种标准接口)),以下统称UNP。W. Richard Stevens在UNP第2版出版之后就不幸去世了,UNP第3版是由他人续写的。
UNP是Sockets API的权威指南,但是网络编程远不是使用那十几个Sockets API那么简单,作者W. Richard Stevens深刻地认识到了这一点,他在UNP第2版的前言中写道:
I have found when teacing network programming the about 80% of all network programming problems have nothing to do with network programming, per se. That is, the problems are not with the API functions such as accept and select, but the problems arise from a lack of understanding of underlying network protocols. For example, I have found that once a student understands TCP’s three-way handshake and four-packet connection termination, many network programming problem are immediately understood.
搞网络编程,一定要熟悉TCP/IP协议及其外在表现(比如打开和关闭Nagle算法对收发包延时的影响),不然出现意料之外的情况就摸不着头脑了。不知道为什么UNP第3版在前言中去掉了这段至关重要的话。
另外值得一提的是,UNP中文版《UNIX网络编程》翻译得相当好,译者杨继张先生是真懂网络编程的。
UNP很详细,面面俱到,UDP、TCP、IPv4、IPv6都讲到了。要说有什么缺点的话,就是太详细了,重点不够突出。作者十分赞同孟岩说的(http://blog.csdn.net/myan/archive/2010/09/11/5877305.aspx):
(孟岩)我主张,在具备基础之后,学习任何新东西,都要抓住主线,突出重点。对于关键理论的学习,要集中精力,速战速决。而旁枝末节和非本质性的知识内容,完全可以留给实践去零敲碎打。
原因是这样的,任何一个高级的知识内容,其中都只有一小部分是有思想创新、有重大影响的,而其他很多东西都是琐碎的、非本质的。因此,集中学习时必须把握住真正重要的那部分,把其他东西留给实践。对于重点知识,只有集中学习其理论,才能确保体系性、连贯性、正确性;而对于那些旁枝末节,只有边干边学才能够让你了解它们的真实价值是大是小,才能让你留下更生动的印象。如果你把精力用错了地方,比如用集中大块的时间来学习哪些本来只需要查查手册就可以明白的小技巧,而对于真正重要的、思想性的东西放在平时零碎敲打,那么肯定是事倍功半,甚至适得其反。
因此我对于市面上绝大部分开发类图书都不满——它们基本上都是面向知识体系本身的,而不是面向读者的。总是把相关的所有知识细节都放在一堆,然后一堆一堆攒起来变成一本书。反映在内容上,就是毫无重点地平铺直叙,不分轻重地陈述细节,往往在第三章以前就用无聊的细节“谋杀”了读者的热情。为什么当年侯捷先生的《深入浅出MFC》和Scott Meyers的《Effective C++》能够成为经典?就在于这两本书抓住了各自领域中的主干,提纲挈领,纲举目张,一下子打通了读者的“任督二脉”。可惜这样的书太少了,就算是已故的W. Richard Stevens和当今Jeffrey Richter的书,也只是在体系性和深入性上高人一头,并不是面向读者的书。
什么是旁枝末节呢?拿以太网来说,CRC32如何计算就是“旁枝末节”。网络程序员要明白check sum的作用,直到为什么需要check sum,至于具体怎么算CRC就不需要程序员操心了。这部分通常是由网卡硬件完成的,在发包的时候由硬件填充CRC,在收包的时候网卡自动丢弃CRC不合格的包。如果代码中确实要用到CRC计算,调用通用的zlib就行,也不用自己实现。
UNP就像给了你一堆做菜的原料(各种Sockets函数的用法),常用和不常用的都给了(Out-of-Band Data、Single-Driven IO(SDIO,一种接口标准,使单个设备同时支持多种不同类型的输入/输出(I/O)功能)等等),要靠读者自己设法取舍组合,做出一盘大菜来。在读第一遍的时候,作者建议只读那些基本且重要的章节;另外那些次要的内容可略作了解,即便跳过不读也无妨。UNP是一本操作性很强的书,读这本书一定要上机练习。
另外,UNP举的两个例子(菜谱)太简单,daytime和echo一个是短连接协议,一个是长连接无格式协议,不足以覆盖基本的网络开发场景(比如TCP封包与拆包、多连接之间交换数据)。作者估计W. Richard Stevens原打算在UNP第三卷中讲解一些实际的例子,只可惜他英年早逝,我等无福阅读。
UNP是一本偏重Unix传统的书,这本书写作的时候服务端还不需要处理成千上万的连接,也没有现在这么多网络攻击。书中重点介绍的以accept()+fork()来处理并发连接的方式在现在看来已经有点吃力,这本书的代码也没有特别防范恶意攻击。如果工作涉及这些方面,需要再进一步学习专门的知识(C10k问题,安全编程)。
TCPv1和UNP应该先看哪本?见仁见智吧。作者自己是先看的TCPv1,花了大约两个月时间,然后再读UNP和APUE。
第三本:《Effective TCP/IP Programming》
关于第三本书,作者犹豫了很久,不知道该推荐哪本。还有哪本书能与W. Richard Stevens的这两本比肩吗?W. Richard Stevens为技术书籍的写作树立了难以逾越的标杆,他是一位伟大的技术作家。没能看到他写完UNP第三卷实在是人生的遗憾。
《Effective TCP/IP Programming》这本书属于专家经验总结类,初看时觉得收获很大,工作一段时间再看也能有新的发现。比如第6条“TCP是一个字节流协议”,看过这一条就不会去研究所谓的“TCP粘包问题”。作者手头这本中国电力出版社2001年的中文版翻译尚可,但是却把参考文献去掉了,正文中引用的文章资料根本查不到名字。人民邮电出版社2011年重新出版的版本有参考文献。
其他值得一看的书
以下两本都不易读,需要相当的基础。
1.《TCP/IP Illustated, Vol. 2:The Implementation》,以下简称TCPv2。
1200页的大部头,详细讲解了4.4 BSD的完整TCP/IP协议栈,注释了15000行C源码。这本书啃下来不容易,如果时间不充裕,作者认为没必要啃完,应用层的网络程序员选其中与工作相关的部分来阅读即可。
这本书的第一作者是Gary Wright,从叙述风格和内容组织上是典型的“面向知识体系本身”,先将mbuf(计算机网络中用于管理数据包的数据结构),再从链路层一路往上,以太网、IP网络层、ICMP、IP多播、IGMP、IP路由、多播路由、Sockets系统调用、ARP等等。到了正文内容3/4的地方才开始讲TCP。面面俱到、主次不明。
对于主要使用TCP的程序员,作者认为TCPv2的一大半内容可以跳过不看,比如路由表、IGMP等等(开发网络设备的人可能更关心这些内容)。在工作中大可以把IP视为host-to-host的协议,把“IP packet如何送达对方机器”的细节视为黑盒子,这不会影响对TCP的理解和运用,因为网络协议是分层的。这样精简下来,需要看的只有三四百页,四五千行代码,大大减轻了阅读的负担。
这本书直接呈现高质量的工业级操作系统源码,读起来有难度,读懂它甚至要有“不求甚解的能力”。其一,代码只能看,不能上机运行,也不能改动试验。其二,与操作系统的其他部分紧密关联。比如TCP/IP stack下接网卡驱动、软中断;上承inode转发来的系统调用操作;中间还要与平级的进程文件描述符管理子系统打交道。如果要把每一部分都弄清楚,把持不住就会迷失主题。其三,一些历史包袱让代码变得复杂晦涩。比如BSD在20世纪80年代初需要在只有4MiB内存的VAX小型机上实现TCP/IP,内存方面捉襟见肘,这才发明了mbuf结构,代码也增加了不少偶发复杂度(指计算机软件开发过程中所引入不必要的复杂度)(buffer不连续的处理)。
读这套TCP/IP书切忌胶柱鼓瑟,这套书以4.4 BSD为讲解对象,其描述的行为(特别是与timer相关的行为)与现在的Linux TCP/IP有不小的出入,用书本上的知识直接套用到生产环境的Linux系统可能会造成不小的误解和困扰。(《TCP/IP详解(第3卷)》不重要,可以成套买来收藏,不读亦可)
2.《Pattern-Oriented Software Architecture Volume 2: Patterns for Concurrent and Networked Objects》,以下简称POSA2。
这本书总结了开发并发网络服务程序的模式,是对UNP很好的补充。UNP中的代码往往把业务逻辑和Sockets API调用混在一起,代码固然短小精悍,但是这种编码风格恐怕不适合开发大型的网络程序。POSA2强调模块化,网络通信交给library/framework去做,程序员写代码只关注业务逻辑(这是非常重要的思想)。阅读这本书对于理解常用的event-driven网络库(libevent、Java Netty、Java Mina(Multipurpose Infrastructure for Network Applications,一个用于构建高性能网络应用程序的开源框架)、Perl POE(Portable Object Environment,一个开源的事件驱动的框架,用于构建可扩展的并发和分布式系统)、 Python Twisted(一个基于事件驱动的网络编程框架,用于构建高性能的异步网络应用程序)等等)也很有帮助,因为这些库都是依照这本书的思想编写的。
POSA2的代码是示意性的,思想很好,细节不佳。其C++代码没有充分考虑资源的自动化管理(RAII),如果直接按照书中介绍的方式去实现网络库,那么会给使用者造成不小的负担与陷阱。换言之,照他说的做,而不是照他做的学。
原文地址:https://blog.csdn.net/tus00000/article/details/136256330
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!