DNF Decouple and Feedback Network for Seeing in the Dark
DNF: Decouple and Feedback Network for Seeing in the Dark
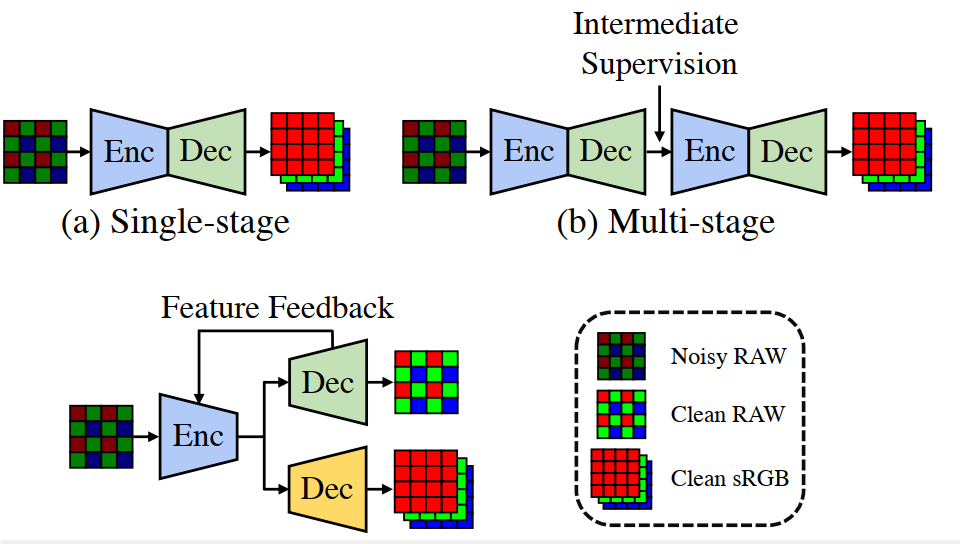
在深度学习领域,尤其是在低光照图像增强的应用中,RAW数据的独特属性展现出了巨大的潜力。然而,现有架构在单阶段和多阶段方法中都存在性能瓶颈。单阶段方法由于域歧义,即在噪声到干净和RAW到sRGB之间的混合映射,导致性能受限。多阶段方法则仅仅通过每个阶段产生的图像传递信息,忽略了损失图像级数据流中的丰富特征。
为了解决这些限制,提出了一种名为Decouple aNd Feedback(DNF)的框架。DNF框架通过解耦特定域的子任务并充分利用RAW和sRGB域中的独特属性来减轻域歧义。此外,通过在阶段之间使用带有反馈机制的特征传播,避免了由图像级数据流造成信息丢失的问题。这种方法的两个关键见解有效地解决了基于RAW数据的低光照图像增强的固有限制,使得DNF方法在参数量只有19%的情况下,性能大幅度超越了先前的最佳方法,在SID数据集的Sony和Fuji子集上分别取得了0.97dB和1.30dB的峰值信噪比(PSNR)提升。
DNF框架的主要贡献包括:
- 特定域任务解耦:通过在RAW和sRGB域中充分利用独特属性,避免了域歧义问题。
- 特征级数据流:通过去噪先验反馈减少了错误累积,并在各个阶段聚合了互补特征。
这些贡献使得DNF框架在低光照图像增强任务中表现出色,特别是在处理RAW数据时,能够有效地提升图像质量。通过实验和分析,DNF在多个数据集上的性能都得到了验证,证明了其在低光照图像增强领域的潜力和有效性。
背景:开创性工作 SID [2] 为基于 RAW 的 LLIE 提出了一个大尺度配对数据集,重新点燃了人们对数据驱动方法的兴趣。如图 1 所示,一种工作[2, 5, 12, 13, 22, 42]侧重于设计单级网络架构,另一种工作[4,7,35,47]则利用多级网络进行渐进增强。
-
首先,当前的单级方法迫使神经网络学习从噪声 RAW 域到清洁 RGB 域的直接映射。噪声到清洁和 RAW 到 RGB 这两个不同域的混合映射会误导整体增强过程,从而导致域模糊问题。例如,在色彩空间转换过程中,RAW 图像中的可控噪声会被映射为其次,现有的多级方法通过级联子网络组成流水线,每个子网络负责根据上一级的输出图像进行逐步增强。在他们采用图像级数据流的设计中,只有图像会在多个阶段中向前传播,后一阶段只能从前一阶段的结果中获取信息。同时,每个阶段中的每个子网络都可能因为下采样操作或单独的目标函数而造成信息丢失 [41]。因此,有损图像级数据流会带来次优性能。错误会随着阶段的增加而传播、累积和放大,最终无法重建纹理细节。不可预测的分布。因此,图像中不可避免地会出现色彩偏移和未经处理的噪点。
-
其次,现有的多级方法通过级联子网络组成流水线,每个子网络负责根据上一级的输出图像进行逐步增强==。在他们采用图像级数据流的设计中,只有图像会在多个阶段中向前传播,后一阶段只能从前一阶段的结果中获取信息。同时,每个阶段中的每个子网络都可能因为下采样操作或单独的目标函数而造成信息丢失 [41]==。因此,有损图像级数据流会带来次优性能。错误会随着阶段的增加而传播、累积和放大,最终无法重建纹理细节。
为了挖掘 RAW 图像在 LLIE 方面的潜力,我们需要一个超越上述两个限制的通用管道。具体来说,神经网络应该在不同的领域利用上述优点[7],而不是被领域的模糊性所迷惑。根据 RAW 和 sRGB 域的独特属性,必须将增强工作分解为特定域的子任务。在探索了 RAW 域的线性度和可处理噪声之后,就可以有意识地进行从 RAW 域到 sRGB 域的色彩空间转换,而不会受到噪声的干扰。此外,整个框架不会阻碍跨阶段通信,而不是像图像级数据流那样只允许小部分有损信息通过。由于子任务的多样性,每个级别的中间特征往往是互补的[20, 46]。同时,多尺度特征保留了纹理和上下文信息,为后面的阶段提供额外的指导[41]。因此,不同阶段的特征需要在数据流中传播,聚合丰富的特征并保持完整的信息。特定领域的解耦与特征级数据流一起,促进了可学习性,从而获得更好的增强性能,并保持了该方法的可解释性
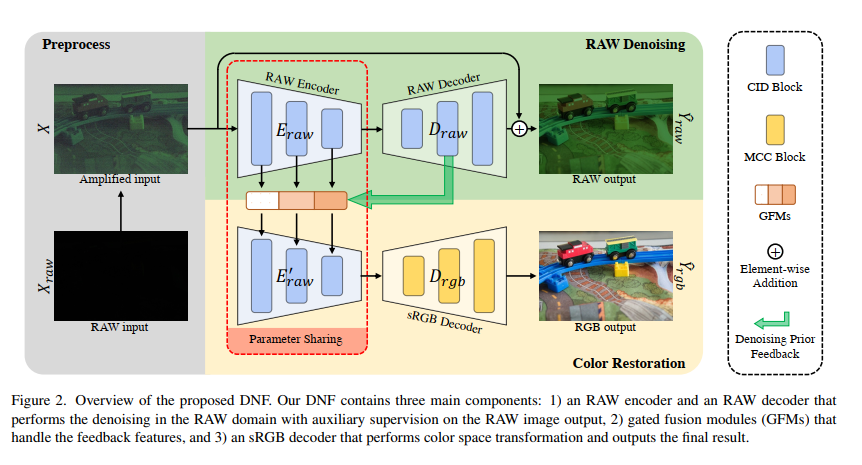
基于这些原则,我们提出了解耦反馈(DNF)框架,并针对基于 RAW 的 LLIE 进行了如下设计。如图 1©所示,增强过程被解耦为两个特定域的子任务:RAW 域的去噪[30, 33, 45, 48]和 sRGB 域的色彩还原[8, 28, 39]。 在前人常用的编码器-解码器架构下[27],子网络中的每个模块都来自于每个域的专属属性:信道独立去噪(CID)模块用于 RAW 去噪,矩阵色彩校正(MCC)模块用于色彩渲染。此外,我们不使用误差消除的 RAW 图像,而是使用 RAW 解码器的多尺度特征作为去噪先验。然后,通过提出的门控融合模块(GFM)将这些特征导入共享的 RAW 编码器,自适应地区分 RAW 图像的多尺度特征。
2.2. Decouple Mechanism
解耦机制旨在将原始任务划分为几个更简单的子任务,然后明确地征服它们。通过适当的解耦,神经网络可以更容易地进行收敛,从而获得更好的性能。Li 等人[18]将外推法任务解耦为边界框布局生成、分割布局生成和图像生成。合理的解耦减少了文本和图像之间的差距,即边界框和分割布局这两个立足点。最近关于内绘的研究[16, 25, 26]旨在将内绘任务解耦为结构和纹理重建,以获得更好的效果。在高层次任务中 [11],将领域适应任务与特征分布对齐和分割解耦可以提高性能。我们通过特定领域的任务解耦来实现这一机制,将 LLIE 任务解耦为 RAW 去噪和色彩还原。
反馈机制
反馈机制使网络能够从先前的状态中获取掌握的信息。这一想法已被应用于许多任务中,例如分类 [37]、超分辨率 [17,19] 和点云补全 [36]。由于涉及到反馈机制,Li 等人[19] 采用了课程学习策略来逐步还原。Yan 等人[36]则打算利用反馈机制,用高分辨率特征来丰富低分辨率特征。所有现有方法都采用了反馈机制来逐步完成唯一的任务,这与我们的方法不同。我们的反馈机制使我们的网络能够在两个不同的子任务之间进行交流,同样也适用于不同的领域。
具体来说,共享编码器 Eraw 和两个解码器(Draw 和 Drgb)是专门为特定域任务解耦与特定任务块(第 3.1 节)所解耦的子任务而设计的。引入独立通道去噪(CID)模块是为了学习 RAW 域中不同颜色通道的可控独立噪声分布。根据色彩空间的定义,矩阵色彩校正(MCC)块利用全局矩阵变换将剩余的增强效果转换到 sRGB 域。此外,我们还加入了去噪先验反馈机制,以避免误差跨阶段累积。利用从 RAW 解码器中提取的去噪特征 Fdn,RAW 编码器用高频信息丰富浅层特征。此外,还提出了具有门控机制[17]的门控融合模块(GFM),用于自适应地探索埋藏在噪声中的细节(第 3.2 节)。
RAW 域去噪。如图 2 所示,我们堆叠多个信道不相干的去噪(CID)块来实现 RAW 编码器 Eraw 和 RAW 解码器 Draw。CID 块的设计基于以下两个先验知识:1)RAW 格式的低照度图像存在与信号无关的噪声,该噪声服从零均值分布[9, 33];2)由于不同信道的信号在 RAW 域中的相关性较低,噪声分布趋向于独立于不同信道[24, 34]。因此,我们需要对几乎相同的信号(相邻像素)进行突发观测,以消除零均值噪声的干扰。此外,要处理与信道无关的噪声分布,就必须在去噪过程中防止信道信息交换。根据上述讨论,我们在 CID 块中引入了带有大核的深度卷积进行去噪。CID 块的具体结构如图 3 (a) 所示。具体来说,对于输入特征 Fin,经过独立于信道的去噪块后的输出特征 Fout 可以表示为
RAW 到 sRGB 的色彩校正。矩阵变换通常用于典型的 ISPipelines [23]。由于环境光照和色彩空间规格等设置是全局共享的,因此图像的色彩主要是通过通道矩阵变换来增强或转换为另一种色彩空间。根据这一原理,我们引入了矩阵色彩校正(MCC)模块,以进行全局色彩增强和局部细化,如图 3 (b)所示。对于 sRGB 解码器 Drgb,我们堆叠了多个用于色彩校正的 MCC 块。这一区块的设计得益于最近在转置自注意方面取得的进展[38]。给定输入源特征 Fsource ∈ RC×H×W,查询向量 Q ∈ RC×HW、关键向量 K ∈ RC×HW、值向量 V ∈ RC×HW,首先用 1 × 1 卷积层进行投影,然后用 3 × 3 深度卷积层和扁平化操作生成。然后,通过矩阵乘法得到变换矩阵 M∈RC×C。这一过程可表述为
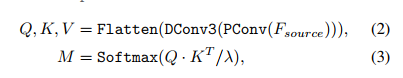
其中应用了缩放系数λ以提高数值稳定性。然后,通过矩阵M变换颜色向量V,执行特征级别的颜色空间转换。通过Ftarget = M · V可以得到颜色转换后的目标特征。作为全局矩阵变换的补充,我们使用深度卷积和点卷积来进一步细化局部细节。
3.2. Denoising Prior Feedback
在先前基于RAW的方法[4, 7, 35, 47]中,一部分高频内容在增强过程中被错误地识别为噪声,严重恶化了最终结果,导致细节丢失,并造成了数据流的损失。为==了避免现有多阶段方法的损失图像级数据流,我们提出了一种去噪先验反馈机制,通过特征级信息传播。==我们将Fdn = {Fdn 1, Fdn 2, …, Fdn L} 表示为从RAW解码器Draw提取的一组去噪特征,其中L表示阶段数。Fdn中的每个元素主要包含RAW域中不同尺度的最终噪声估计信息。具体来说,这些特征使噪声更加明显,并作为进一步去噪的指导。通过将去噪特征集Fdn重新路由到具有多个反馈连接[1, 19, 29]的RAW编码器的相应阶段,编码器逐渐生成更好的去噪特征,以进行进一步的增强。因此,sRGB解码器Drgb可以更专注于颜色校正。反馈管道如图2所示,可以表述为:
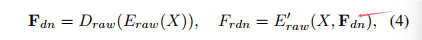
在这里,Frdn表示经过精炼的去噪特征,它将被传递给sRGB解码器。E’raw表示RAW编码器,它不仅包含了Eraw的权重,而且配备了L个门控融合模块(GFMs)。每个GFM负责处理来自Fdn的一个反馈特征。
Gated Fusion Modules. GFM(Gated Fusion Module)被设计为通过门控机制自适应地融合反馈噪声估计和初始去噪特征。在特征门控过程中,我们期望有益的信息能够自适应地在空间和通道维度上被选择和合并。为了提高效率,我们使用点卷积和深度卷积分别聚合通道和局部内容信息。然后,我们将混合特征沿通道维度分割成两个部分,即Fgate l和Fcon l。通过GELU非线性激活函数激活后,Fgate l通过点乘的方式对Fcon l进行门控。我们通过这种门控机制实现了空间和通道的适应性。GFM的详细结构如图3(c)所示。第l阶(l ∈ {1, 2, …, L})的操作可以表述为:。

DConv3 和 PConv 分别代表具有 3×3 核的深度卷积和点卷积。⊙ 表示哈达玛积(Hadamard 乘积)。Fraw l 是原始 RAW 编码器中第 l l l 个上采样层后获得的特征。 F f l F^l_f Ffl 是相应的融合特征。
Residual Switch Mechanism.
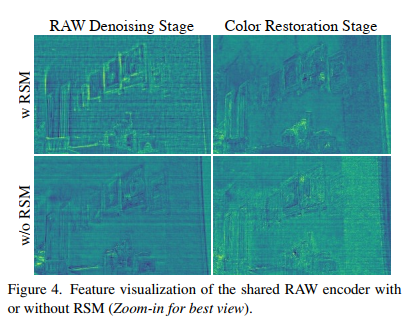
我们只在 RAW 域的去噪阶段保留全局shortcut方式,以获得更好的去噪效果[22, 43],而在色彩还原阶段则将其移除,以避免有噪声的 RAW 域和干净的 sRGB 域之间的模糊联系,如图 2 所示。因此,编码器在去噪时需要执行噪声估计,而在色彩还原时则需要重建信号。为了在一个编码器中实现这两种相互矛盾的功能,我们提出了一种简单而有效的残差切换机制(Residual Switch Mechanism,RSM),如图 3 (a)所示,它赋予共享 RAW 编码器中的 CID 块以权力,使其产生两种相互矛盾的特征:噪声和信号。在全局残差连接的去噪阶段,局部残差捷径被关闭,以估计噪声;相反,在增强阶段,局部残差被触发,以捷径上的原始特征抵消噪声,最终重建信号。如图 4 所示,使用 RSM 时,共享 RAW 编码器的 CID 块能够在不同阶段产生两种不同的特征。然而,在没有 RSM 的情况下,权重共享 CID 块在色彩还原阶段无法区分噪声和信号,导致特征模糊。
3.3. Training Objectives
为了依次完成由特定领域任务解耦的 RAW 去噪和色彩修复子任务,我们在不同领域引入了两种不同的监督,即干净的 RAW 和干净的 sRGB。地面实况是清晰的 RAW 图像 Yraw。我们将去噪解码器输出的 RAW 图像称为 Yˆraw。我们网络的损失函数为
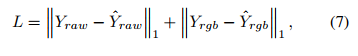
这里的 Yrgb 是地面真实 sRGB 图像。值得注意的是,在我们的方法中,RAW 监督和 sRGB 监督都只使用了 L1 损失,而不是像以前的方法[7, 30, 32, 42, 47]那样混合使用复杂的损失函数。训练细节和详细的网络架构见补充材料
方法[7, 30, 32, 42, 47]那样混合使用复杂的损失函数。训练细节和详细的网络架构见补充材料
原文地址:https://blog.csdn.net/qq_46401672/article/details/142445501
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!