MySQL中char和varchar的区别
1.从字符和字节的区别开始
字节(Byte)是计量单位,表示数据量多少,是计算机信息技术用于计量存储容量的一种计量单位。
字符(Character)计算机中使用的字母、数字、字和符号等,比如'A'、'B'、'$'、'&','中'等。
那么比如: 'A'是占多少个字节的呢?在不同编码中,结果是不一样的。
GBK编码,一个英文字符占一个字节,中文2字节,单字符最大可占用2个字节。UTF-8编码,一个英文字符占一个字节,中文3字节,单字符最大可占用3个字节。utf8mb4编码,一个英文字符占一个字节,中文3字节,单字符最大占4个字节(如emoji表情4字节)。
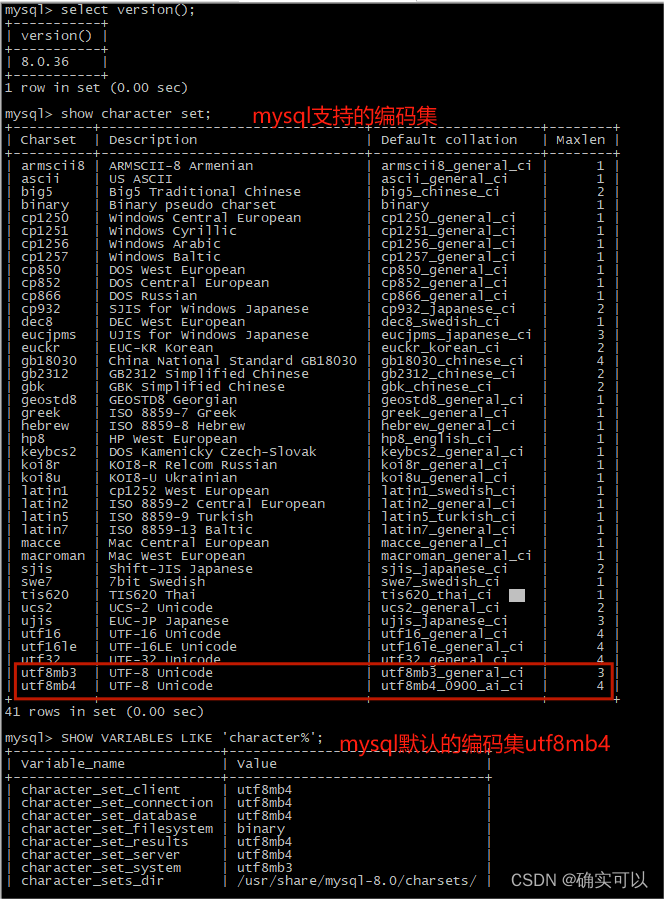
mysql支持的编码集和默认的编码
常用的是utf8,而MySQL的“utf8”实际上不是真正的UTF-8。
mysql的“utf8”只支持每个字符最多三个字节,而真正的UTF-8是每个字符最多四个字节。
以前版本mysql使用的是utf8,现在官方把以前最多3字节的utf8改成了utf8mb3。而utf8mb4才是完整的utf8(一个字符最多可以占4个字节)。
MySQL在5.5.3之后增加了utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。
所以所有在使用“utf8”的MySQL和MariaDB用户都应该改用“utf8mb4”。
说明:后面进行测试的mysql都是上图的版本8.0.36。
2.char和varchar类型对比
这两种都是字符串,char是定长,varchar是变长的。
char(N),varchar(N)中的N表示什么?N个字节还是N个字符?
在version4中长度单位是字节,而在version5及以后版本中是字符。
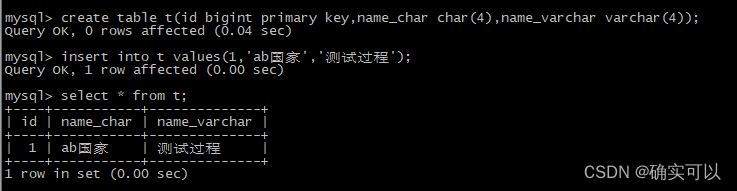
一个中文字占3个字符,表明char(4)中的4表示的是最长是4个字符。
char(N),varchar(N)中的N最大可以是多少?
char
char(N)中的N值最大是255。
对于char类型来说,最多只能存放的字符个数为255,和编码无关,任何编码最大容量都是255。
varchar
而varchar(N)中,很多文章写最大是65536,这是错误的。
MySQL行默认最大65535字节,是所有列共享(相加)的,所以varchar的最大值受此限制。
表中只有单列字段情况下,varchar一般最多能存放(65535 - 3)个字节,varchar的最大有效长度通过最大行数据长度和使用的字符集来确定,通常的最大长度是65532个字符(当字符串中的字符都只占1个字节时,能达到65532个字符);
为什么是65532个字符?算法如下(有余数时向下取整):
最大长度(字符数) = (行存储最大字节数 - null标识列占用字节数 - 长度标识字节数) / 字符集单字符最大字节数
该列允许是null的时候,null占用字节数为1
长度标识字节数是因为varchar的头部需要存储该列该字符串的长度。长度大于255的时候就需要2字节。
char,varchar中尾随空格的情况
char类型插入的时候,末尾有空格的话,会去除空格;若插入的字符长度不足默认用空格填满,
检索和获取时会自动去除。
varchar类型插入的时候,末尾有空格的话,不会去除空格。
用concat函数来测试,char类型的进行concat的话,是没有空格,而varchar是有空格的。
也通过select....where...来进行查找。
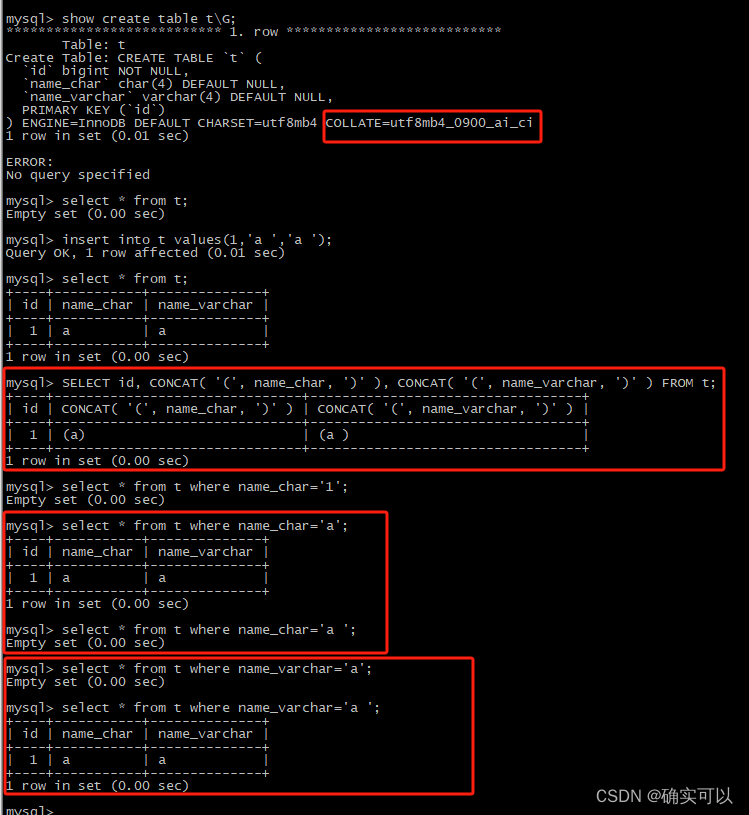
排序规则collate对char,varchar中尾随空格的影响
上述情况都是发生在我们默认的collate(排序规则)。
排序规则是由使用的编码集来确定的,而我们使用的编码集是utf8mb4,而其默认的collate是utf8mb4_0900_ai_ci。
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。
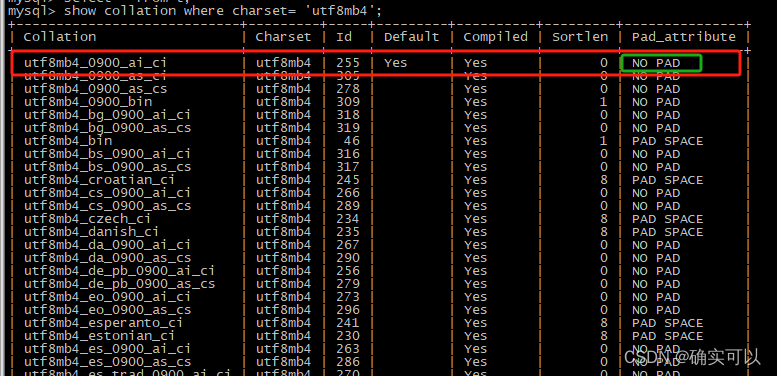
我们先来看看PAD SPACE与NO PAD的具体意义:
-
PAD SPACE:在排序和比较运算中,忽略字符串尾部空格。
-
NO PAD:在排序和比较运算中,字符串尾部空格当成普通字符,不能忽略。
我们把callate修改成PAD SPACE模式测试下:
name字段的callate修改成utf8mb4_bin,其Pad_attribute是PAD SPACE。
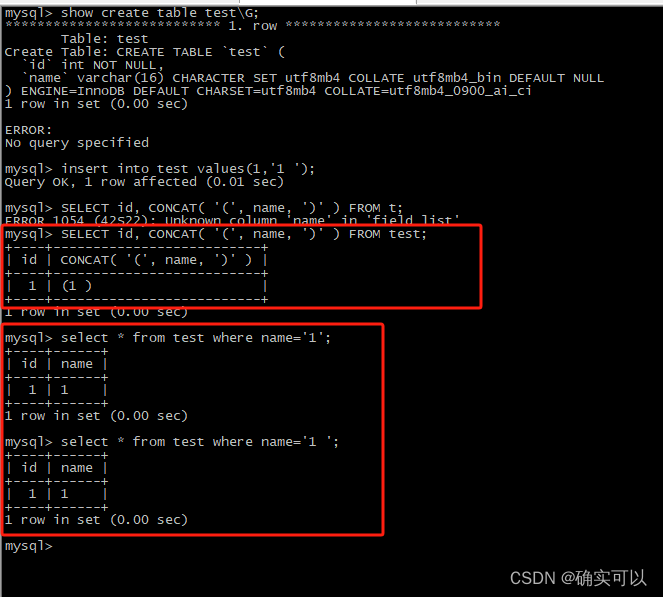
没有特别情况,我们一般是使用默认情况,就记住这个排序规则。
3.char和varchar在innodb引擎层的存储
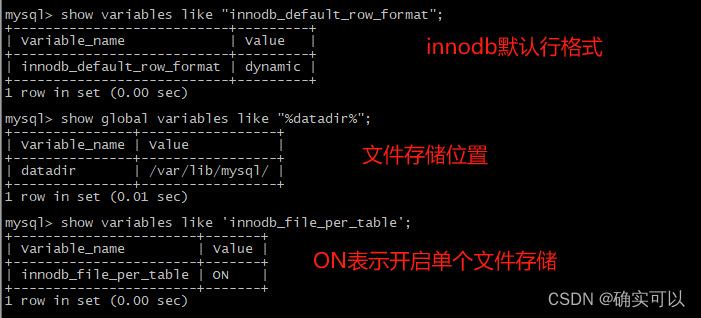
Innodb存储引擎支持多种行格式(REDUNDANT、COMPACT、DYNAMIC、COMPRESSED),不同行格式存储方式存在差异。这里是基于默认行格式DYNAMIC。
varchar
在表test_varchar插入以下数据(单字节的字母和多字节的中文)。
mysql> show create table test_varchar\G;
*************************** 1. row ***************************
Table: test_varchar
Create Table: CREATE TABLE `test_varchar` (
`id` int NOT NULL,
`code` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
mysql> insert into test_varcahr values(1,'aaaaa'),(2,'hellohello'),(3,'我我我我我我');然后到/var/lib/mysql目录位置,之后找到使用的该数据库,然后在该数据库找到使用的表test_varchar。
之后使用命令 hexdump -C test_varchar.ibd
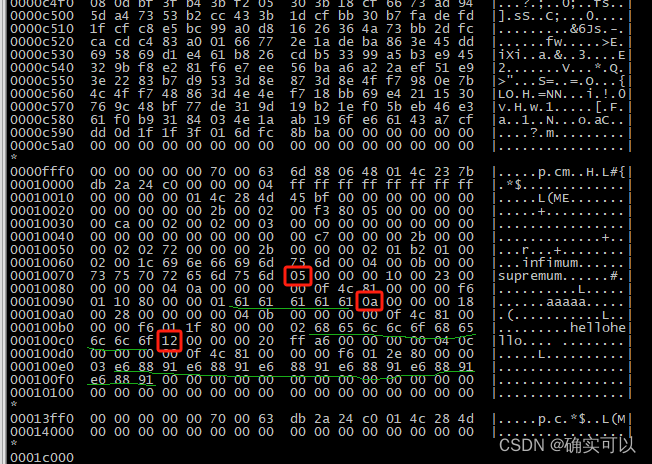
红框内的05和0a和12(十进制就是18)分别表示的是对应字符串的长度(字节数)5,10,18。绿色下划线部分为实际存储的数据aaaaa和hello,'我'的十六进制是E68891。(可以在mysql中 select hex('我');查看)。
说明varchar类型对于单字节编码、多字节编码,都是存储了字符长度+实际的字符。
char
在表test_char插入以下数据(6字节,30字节,10字节)
mysql> show create table test_char\G;
*************************** 1. row ***************************
Table: test_char
Create Table: CREATE TABLE `test_char` (
`id` int NOT NULL,
`code` char(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> insert into test_char values(1,'我aaa'),(2,'我我我我我我我我我我'),(3,'bbbbbbbbbb');code字段是char(20),表明该字段最多可以存储20*4=80字节大小的数据。

可以看到,红色的是数据大小,14,1e,14。表明char类型的,innodb也是保存了字符长度的。而长度不够80字节的,末尾是用0x20(即是空格)来插入。
而这也有个情况,不是每次都是开辟80字节的空间来存储的。从这个实验来看,是这样:要是插入的大小不足设置的数值20(这里char(N)的N是20),就只开辟20字节的空间存储,超过20字节了,就开辟实际大小的空间来存储(1e就是十进制30)。
char和varchar的存储总结
- 都是存储长度大小和实际数据。
- 对于
CHAR(N)字段,如果实际存储数据小于N字节,会填充空格到N个字节。
网上说的对于innodb引擎,建议使用varchar就是这个原因吧。
4.用char还是varchar
经过上面的分析,我们可知,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储!
所以建议大部分可以使用varchar。
但是要是就确定是这么多字节的,那当然是使用char的。
还有种情况:知道该字段的最大长度,并且该字段需要频繁修改的。比如使用char(50),则插入记录后就分配了50个字节,后续修改不会造成页分裂、页空隙等情况;而varchar(50)由于没有提前分配存储空间,后续修改时可能出现页分裂,进而导致性能下降。
原文地址:https://blog.csdn.net/m0_57408211/article/details/136251681
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!