数字人解决方案— SadTalker语音驱动图像生成视频原理与源码部署
简介
随着数字人物概念的兴起和生成技术的不断发展,将照片中的人物与音频输入进行同步变得越来越容易。然而,目前仍存在一些问题,比如头部运动不自然、面部表情扭曲以及图片和视频中人物面部的差异等。为了解决这些问题,来自西安交通大学等机构的研究人员提出了 SadTalker 模型。
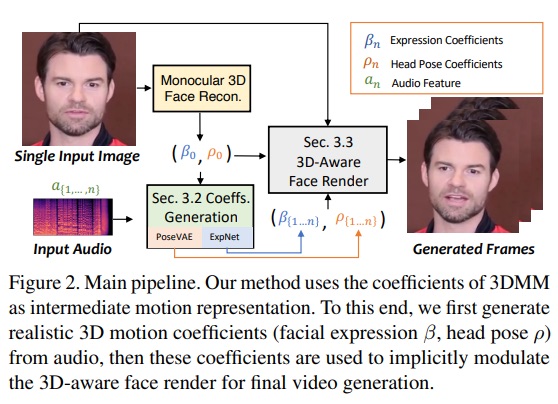
SadTalker 模型在三维运动场中学习如何从音频中生成3DMM的3D运动系数,包括头部姿势和表情,并利用全新的3D面部渲染器来生成自然的头部运动。
为了学习真实的运动系数,研究人员将音频和不同类型的运动系数之间的联系进行了显式建模。他们设计了蒸馏系数和3D渲染的脸部,从音频中学习准确的面部表情。同时,他们还设计了条件VAE,即 PoseVAE,用于合成不同风格的头部运动。最后,他们将生成的三维运动系数映射到人脸渲染的无监督三维关键点空间,并合成最终的视频。
在实验中,研究人员证明了 SadTalker 模型在运动同步和视频质量方面实现了最先进的性能,为通过人脸图像和语音音频生成会说话的人物头像视频提供了一种有效的方法。
SadTalker语音驱动图像生成视频
企鹅交流群:787501969,整合包下载地址可以加交流群
获者从csdn下载:https://download.csdn.net/download/matt45m/88984818
算法架构
在数字人创作、视频会议等多个领域中,将静态照片动态化,即通过语音音频让照片中的人物动起来,是一项具有挑战性的任务。过去的研究主要集中在生成唇部运动,因为唇部动作与语音之间的关联最为紧密。虽然一些工作也尝试生成其他相关的人脸运动,比如头部姿势,但生成视频的质量仍然存在着许多不自然的问题,例如偏好的姿势、模糊、身份修改和面部扭曲等限制。
另一种流行的方法是基于潜在空间的人脸动画,该方法主要关注于在对话式人脸动画中特定类别的运动。然而,生成高质量的视频仍然是一项具有挑战性的任务。尽管三维面部模型中包含高度解耦的表征,可以用于单独学习面部不同位置的运动轨迹,但仍然会产生不准确的表情和不自然的运动序列。
基于以上观察结果,研究人员提出了SadTalker(Stylized Audio-Driven Talking-head)系统。该系统通过隐式三维系数调制来实现风格化音频驱动的视频生成。
3面部
现实中的视频通常是在三维环境中拍摄的,因此三维信息对于生成逼真的视频至关重要。然而,以往的研究很少考虑到三维空间,因为仅仅通过一张平面图像很难获取原始的三维稀疏信息,而且设计高质量的面部渲染器也非常困难。
受到最近单图像深度三维重建方法的启发,研究人员开始将预测的三维形变模型(3DMMs)作为中间表征。在3DMM中,三维脸部形状S可以被解耦为:
S
=
S
‾
+
α
U
i
d
+
β
U
e
x
p
,
(
1
)
{\bf S}={\overline S}+\alpha{\bf U}_{i d}+\beta{\bf U}_{e x p},\qquad(1)
S=S+αUid+βUexp,(1)
在这个算法中,通过LSFM morphable模型,三维形变模型(3DMMs)的各个参数有以下含义和作用:
- S:代表三维人脸的平均形状。
- Uid 和 Uexp:LSFM morphable模型的参数,分别用于描述人物的身份和表情的正则。
- α 和 β:分别是身份和表情的系数,分别具有80维和64维,用于描述人物的身份和表情。
- r 和 t:分别表示头部旋转和平移,用于保持头部姿势的差异性。
- {β, r, t}:仅将运动的参数建模为表情系数β、头部旋转r和平移t。
在该算法中,从驱动的音频中单独学习头部姿势ρ=[r, t]和表情系数β。然后,利用这些学习到的运动系数来隐式地调制面部渲染,用于最终的视频合成。这种方法可以保持生成的面部动画与音频的相关性,从而使合成的视频更加真实和生动。
通过音频生成运动稀疏
SadTalker使用了两个模型,PoseVAE和ExpNet,来分别生成头部姿势和表情的运动。这是因为三维运动系数包含了头部姿势和表情,而这两者具有不同的特性。头部姿势是全局运动,对应整个面部区域的变化,而表情通常是相对局部的,局限于特定的面部区域。由于头部姿势与音频的关系相对较弱,而表情与音频高度相关,如果尝试在一个模型中完全学习所有的系数,会导致网络面临巨大的不确定性。因此,通过分别使用PoseVAE和ExpNet来生成头部姿势和表情的运动,网络可以更有效地处理头部姿势和表情之间的关系,从而提高生成的面部动画的真实性和准确性。
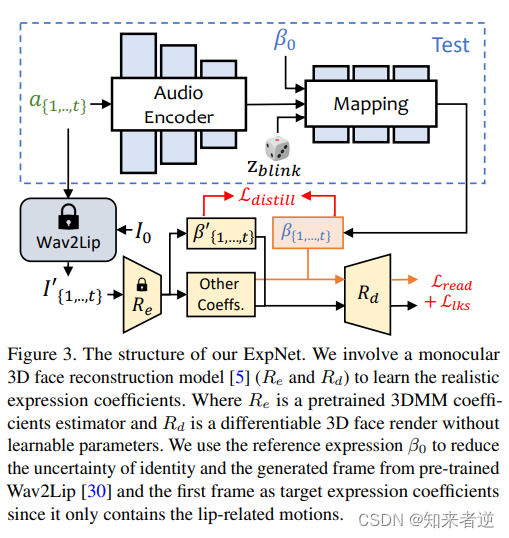
ExpNet
学习一个能够从音频中准确生成表情系数的通用模型是非常困难的,原因主要有两点:
-
音频到表情不是对不同人物的一对一的映射任务:不同个体对相同的语音输入可能会产生不同的面部表情反应。这是由于个体之间的生理特征、情感状态、习惯性表现等因素的差异导致了相同音频信号引发不同表情的情况。
-
表情系数中存在与音频相关的动作,这会影响到预测的准确性:音频信号中的语调、情感内容以及说话速度等因素都可能影响到面部表情的生成。因此,从音频中预测表情时,需要考虑如何有效地捕捉和建模这些与音频相关的动作,以提高预测的准确性和鲁棒性。
为了应对这些挑战,ExpNet 的设计目标是减少这些不确定性。针对个体身份问题,研究人员通过使用第一帧的表情系数将表情运动与特定的人物联系起来。
为了减少自然对话中其他面部成分的运动权重,研究人员通过预训练网络,如 Wav2Lip 和深度三维重建,只使用嘴唇运动系数作为系数目标。这种方法有助于减少由于音频中其他动作导致的表情系数的不确定性。
对于其他细微的面部运动,比如眼睛眨动等,可以在渲染图像上的额外landmark损失中引入,以进一步提高模型的准确性和鲁棒性。
PoseVAE
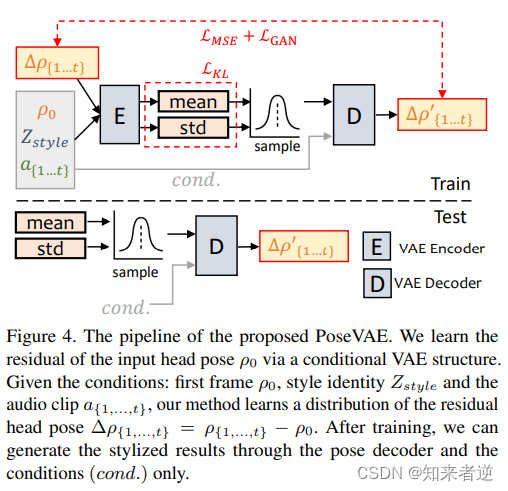
研究人员设计了一个基于变分自动编码器(VAE)的模型,旨在学习谈话视频中真实的、身份相关的风格化头部运动。在训练中,他们采用了基于编码器-解码器结构的方法对固定的n个帧进行姿势VAE训练。编码器和解码器都是由两层多层感知器(MLP)组成,输入是一个连续的t帧头部姿势,将其嵌入到高斯分布中。在解码器中,网络从采样分布中学习生成t帧姿势。
需要注意的是,PoseVAE并不直接生成姿势,而是学习第一帧的条件姿势的残差。这使得该方法在测试中能够在第一帧的条件下生成更长、更稳定、更连续的头部运动。根据条件变分自动编码器(CVAE),PoseVAE还增加了相应的音频特征和风格标识作为节奏感知(rhythm awareness)和身份风格的条件。
模型使用KL散度来衡量生成运动的分布,并使用均方损失和对抗性损失来确保生成的质量。这样的设计使得模型能够从谈话视频中学习到真实且与身份相关的头部运动,并能够在测试阶段生成更长、更连续的运动序列。
3D-aware面部渲染
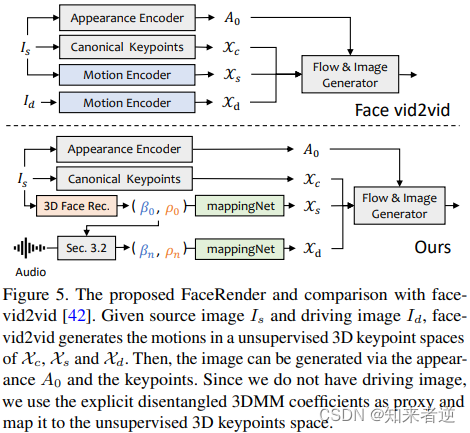
在生成真实的三维运动系数后,研究人员使用了一个精心设计的三维图像动画器来渲染最终的视频。最近提出的图像动画方法,称为 face-vid2vid,可以隐含地从单一图像中学习3D信息。然而,该方法需要一个真实的视频作为动作驱动信号。与此不同的是,这篇论文中提出的脸部渲染可以通过3DMM系数来驱动。
为了建立显式3DMM运动系数(头部姿势和表情)与隐式无监督3D关键点之间的关系,研究人员提出了 mappingNet。mappingNet 使用了几个一维卷积层,类似于 PIRenderer,使用时间窗口的时间系数进行平滑处理。不同之处在于,研究人员发现 PIRenderer 中的人脸对齐运动系数会极大地影响音频驱动的视频生成的运动自然度,因此 mappingNet 只使用表情和头部姿势的系数。
训练阶段包含两个步骤:首先,按照原论文的方法,使用自监督方式训练 face-vid2vid。然后,在冻结外观编码器、canonical关键点估计器和图像生成器的所有参数后,通过在ground truth视频的3DMM系数上进行重建,对 mappingNet 进行微调。
在无监督关键点的域中,使用 L1 损失进行监督训练,并按照其原始实现方式生成最终的视频。这种方法允许通过3DMM系数来驱动脸部渲染,从而生成具有更高真实度和自然度的视频。
实验对比
在实验结果中,研究人员使用了多个指标来评估他们提出的方法相对于其他方法的性能:
-
图像质量评估:使用 Frechet Inception Distance(FID)和 Cumulative Probability Blur Detection(CPBD)来评估生成图像的真实性和清晰度。
-
身份保留程度评估:使用 ArcFace 提取图像的身份嵌入,并计算源图像与生成帧之间身份嵌入的余弦相似度(CSIM)来评估身份的保留程度。
-
唇部同步和口型评估:评估了来自 Wav2Lip 的口型的感知差异,包括距离评分(LSE-D)和置信评分(LSE-C)。
-
头部运动评估:使用 Hopenet 提取的头部运动特征嵌入的标准偏差来评估生成头部运动的多样性,并计算 Beat Align Score 来评估音频和生成头部运动的一致性。
通过与其他最先进的谈话头像生成方法进行对比,包括 MakeItTalk、Audio2Head 和音频转表情生成方法(Wav2Lip、PC-AVS),研究人员使用公开的 checkpoint 权重进行评估。
实验结果显示,提出的方法在整体视频质量和头部姿势的多样性方面表现出更好的性能。同时,在唇部同步方面也与其他完全说话的头部生成方法相当。虽然研究人员发现唇语同步指标对音频过于敏感,可能导致不自然的唇部运动获得更好的分数,但该方法取得了与真实视频相似的分数,表明了其优势。
与其他方法相比,实验结果显示了提出的方法与原始目标视频的视觉质量非常相似,并且能够生成与预期的不同头部姿势非常相似的视频。相比之下,其他方法如 Wav2Lip 生成了模糊的半脸,PC-AVS 和 Audio2Head 难以保留源图像的身份,Audio2Head 只能生成正面说话的脸,而 MakeItTalk 和 Audio2Head 则由于二维扭曲而生成了扭曲的人脸视频。

项目安装
项目安装分三种方式,有从源码安装的,这个可以参考官方给的安装文档,在SD-webui里面当插件安装,还有一键整合包这三种模式:
1.源码安装方式
源码安装最好依赖在conda虚拟环境:
安装环境:
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
下载模型:
bash scripts/download_models.sh
头像合成:
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--enhancer gfpgan
全身合成:
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--result_dir <a file to store results> \
--still \
--preprocess full \
--enhancer gfpgan
2.插件安装方式
启动SD-webui,这里使用的是秋叶大佬的一键整合包,找到插件,点安装,等待安装完成之后,重启webui:
安装完成了之后,在ui界面就有SadTalker这个插件菜单:
在sd插件路径下创建模型两个目录:
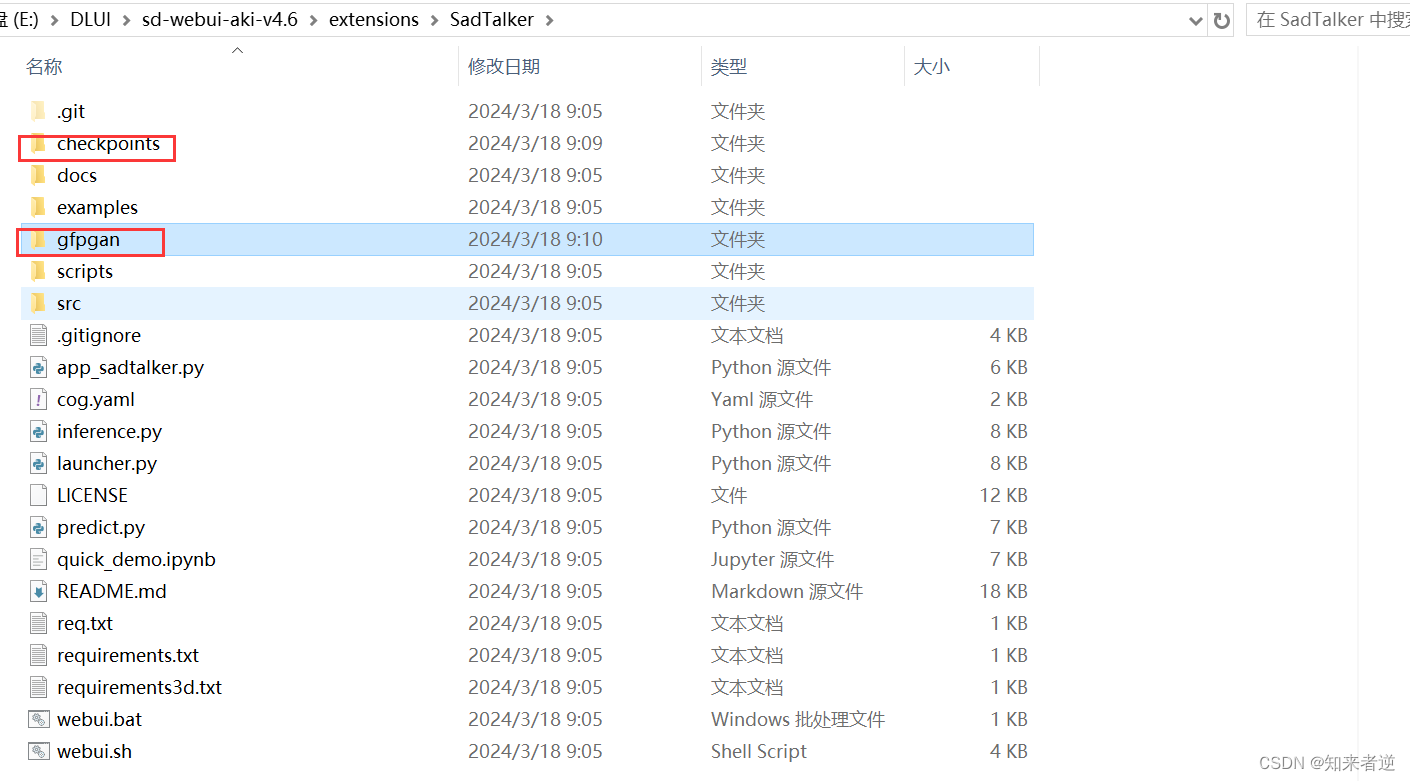
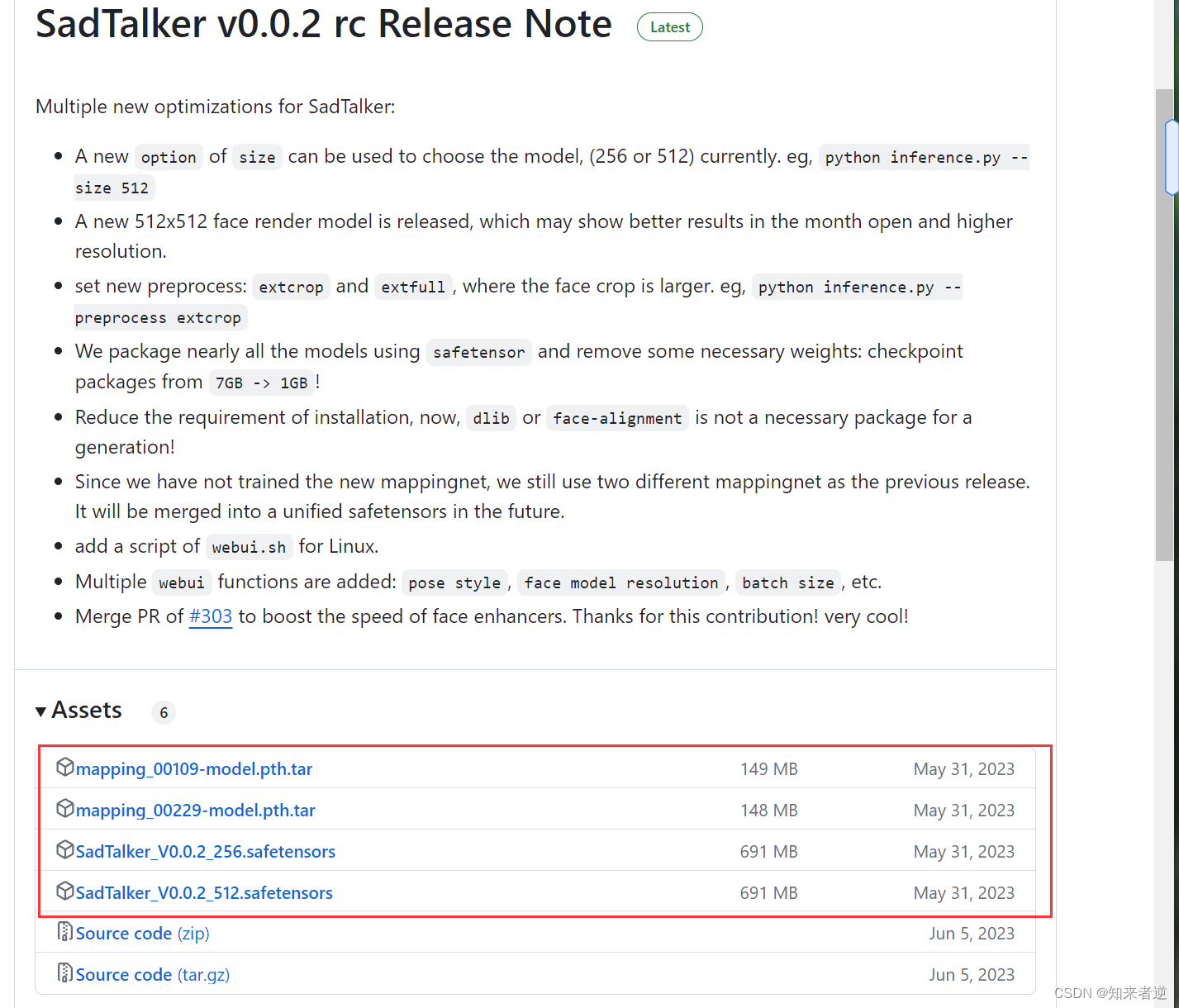
将下面4个模型文件下载到checkpoints文件夹下,再将下载的gfpgan 文件夹里面的文件放到SadTalker的gfpgan目录下:
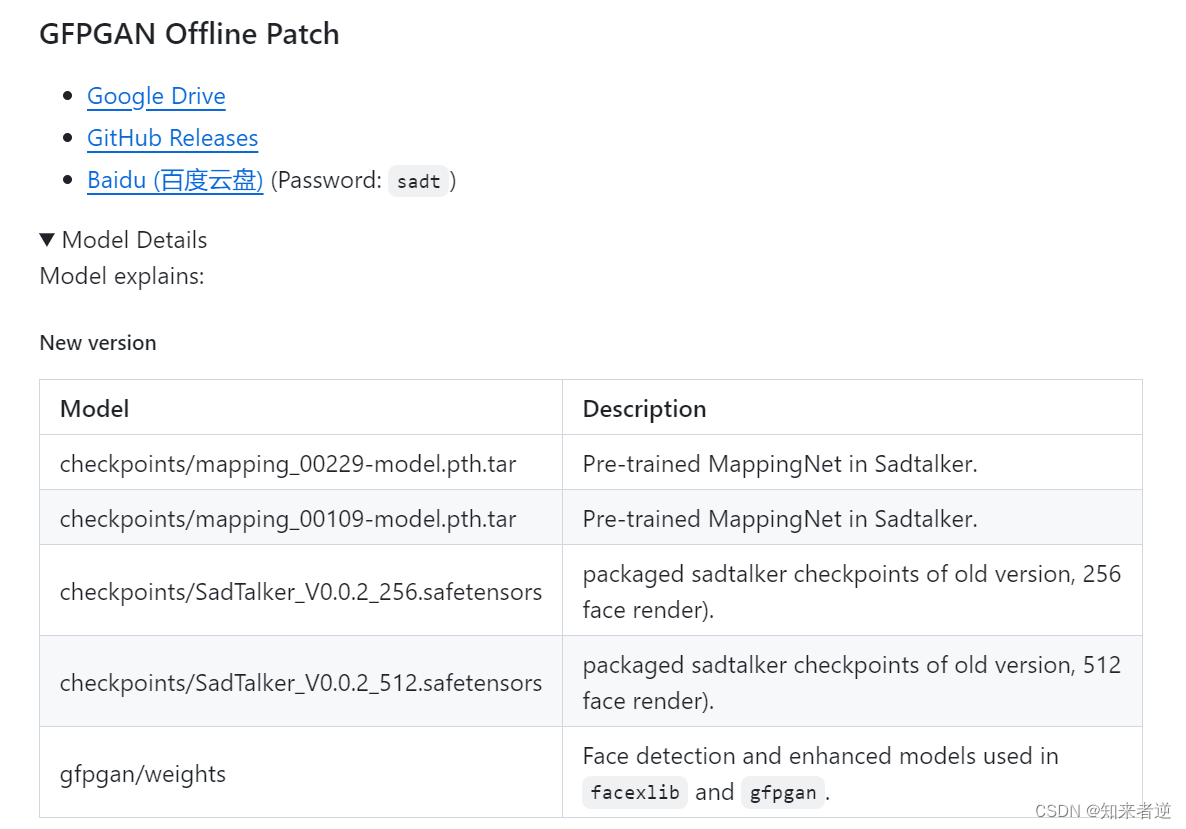
3.一键整合包安装
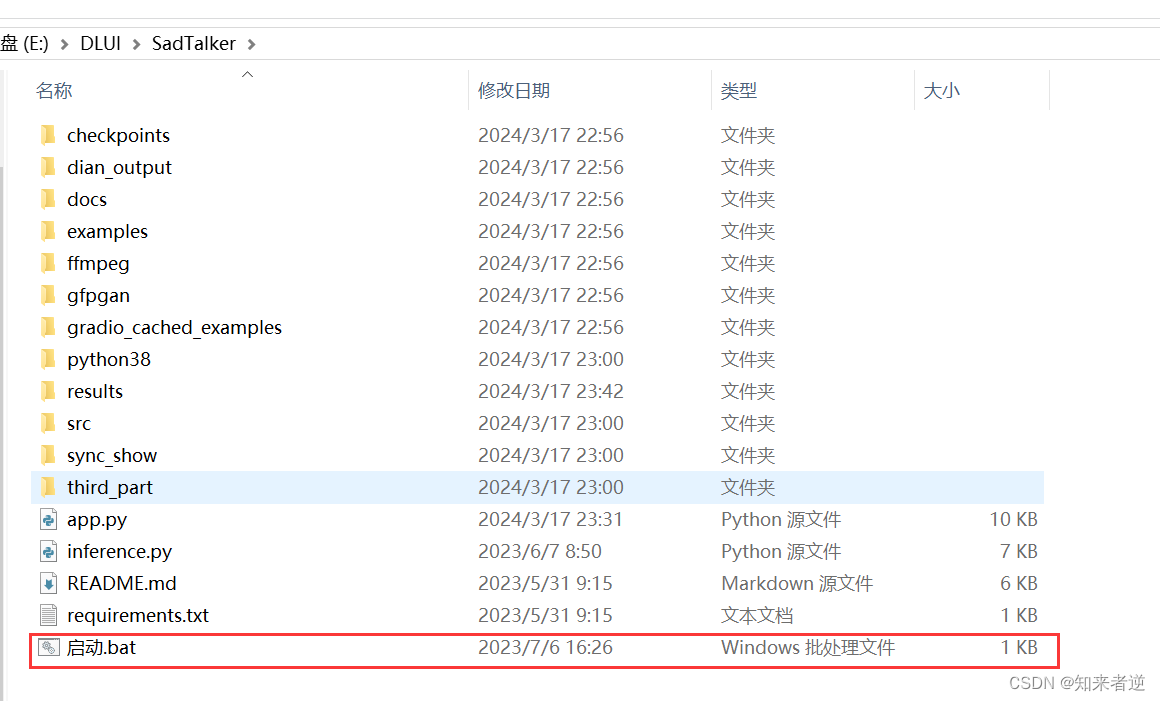
下载整合包,点击启动:
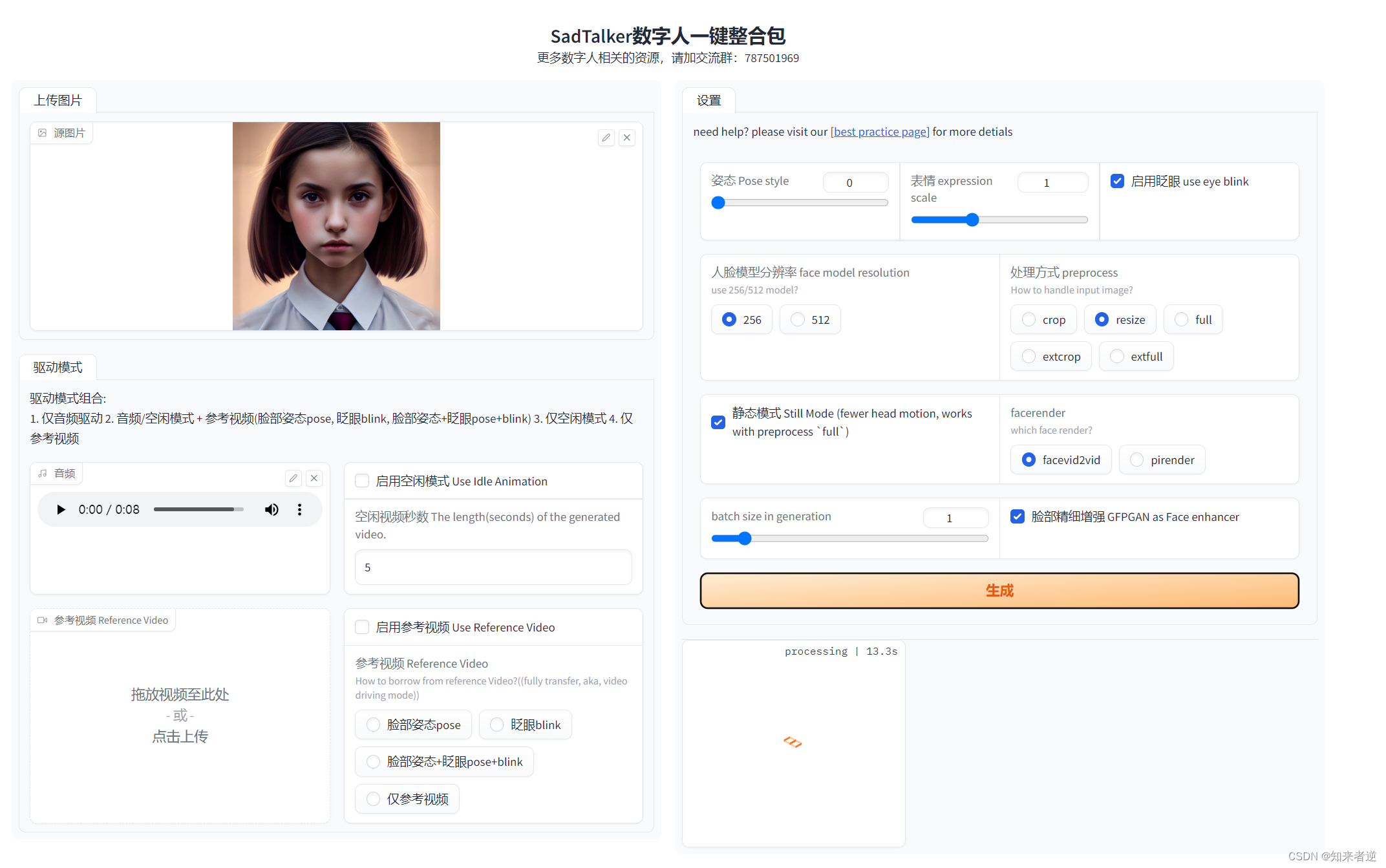
之后在浏览器打开:http://127.0.0.1:7860/

错误解决:
Windows系统下报错: LLVM ERROR: Symbol not found: __svml_sqrtf8_ha
vml_dispmd.dll引起的错误,是由于numba库在windows系统下会根据系统变量路径自动调用svml_dispmd.dll可执行程序。解决方案是把系统路径下的该文件删除或重新命名,并添加一个新的系统变量NUMBA_DISABLE_INTEL_SVML=1
原文地址:https://blog.csdn.net/matt45m/article/details/136764663
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!