Object discovery from motion-guided tokens
Abstract
这项工作引入了一种新颖的自动编码器架构 MoTok,用于无监督视频对象发现。通过利用运动引导标记化,该模型增强了 Transformer 架构中注意力机制的核心矢量量化过程。我们的方法允许出现可解释的中级特征,从而简化对象发现任务。对合成数据集和真实世界数据集的综合评估表明,如果解码器具有足够的容量,运动引导可以减轻对标签、光流或深度解码的需求,从而实现最先进的结果。所提出的方法有效地解决了对象背景模糊性的挑战,并提高了现实视频场景中的性能 [T4]、[T5]。
网络架构图

图2。提议的运动引导令牌(MoTok)框架的模型架构。MoTok是一个统一的视频对象发现框架,可以灵活地选择不同的解码器和重构空间。我们的框架有效地利用了运动和标记化之间的协同作用,并允许出现可解释的特定对象的中级功能。
methods
论文中提出的方法称为运动引导标记(MoTok)。它旨在通过利用运动提示和标记化来增强对象发现。以下是 MoTok 框架的关键组件:
- 运动引导标记化:该方法利用运动信号创建标记表示,简化基于颜色、纹理和位置等属性将像素分组到中级区域的过程。这有助于更有效地区分对象和背景。
- 联合训练:MoTok 使用运动提示和矢量量化联合训练槽表示。这种方法允许模型学习更多可解释的中级特征,从而有助于对象发现过程。
- 端到端框架:该架构旨在以端到端的方式运行,允许同时发现对象并表示其特征。这与以前通常单独训练组件的方法形成鲜明对比。
- 对复杂场景的鲁棒性:该模型在现实和复杂场景中表现出更好的性能,而传统方法在这些场景中表现不佳,尤其是在背景杂乱和有多个移动物体的情况下。
- 在多个数据集上的评估:通过对合成数据集(如 TRI-PD)和真实世界数据集(如 KITTI)的全面评估,验证了 MoTok 的有效性,并在对象发现任务中展示了最先进的结果。
results
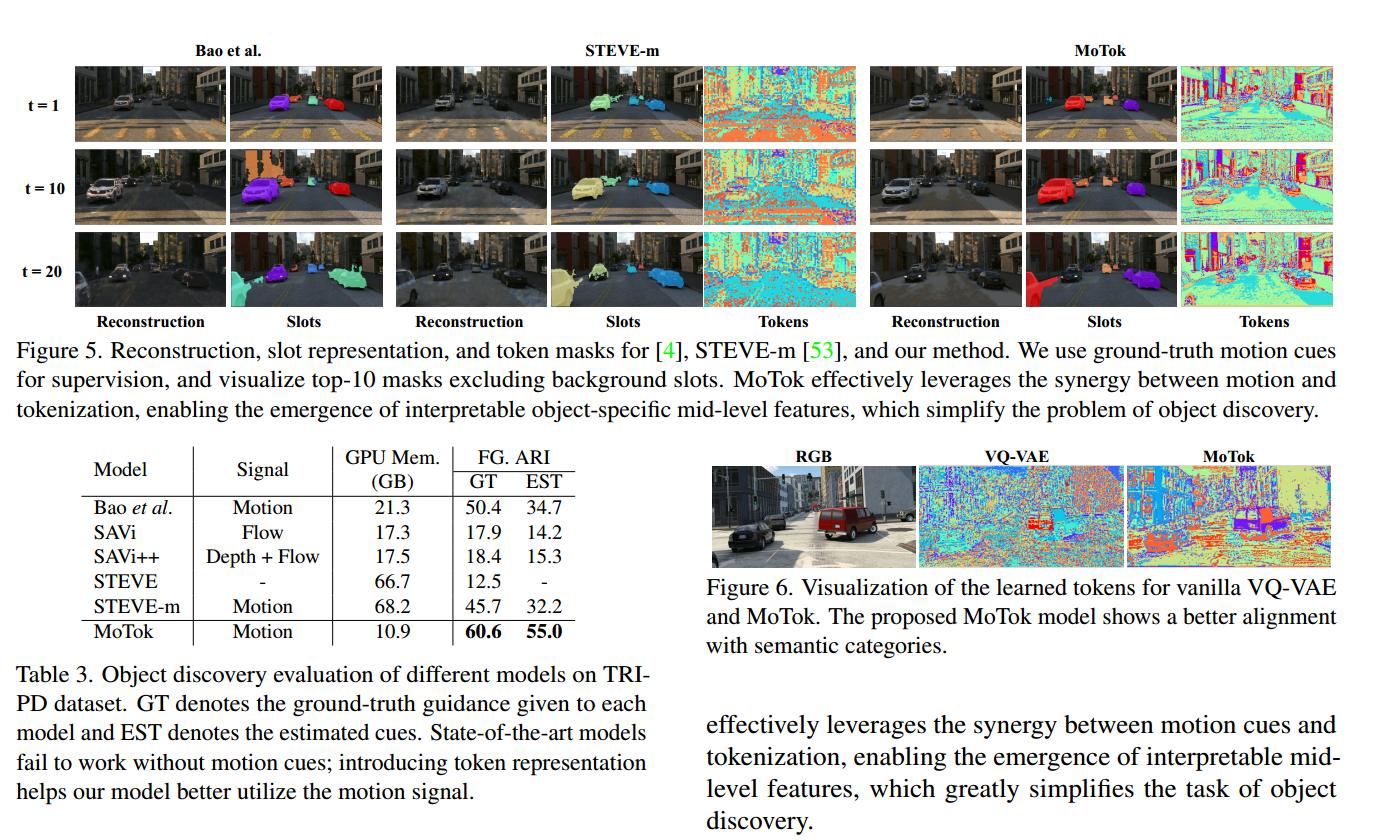
表3。TRIPD数据集上不同模型的对象发现评估。GT表示给出每个模型的真值指导,EST表示估计的线索。没有动作提示,最先进的模型无法工作;引入令牌表示有助于我们的模型更好地利用运动信号。
图5。[4], STEVE-m[53]的重构,槽表示和令牌掩码,以及我们的方法。我们使用真实运动线索进行监督,并可视化前10个面具,不包括背景插槽。MoTok有效地利用了运动和标记化之间的协同作用,使可解释对象特定的中级功能得以出现,从而简化了对象发现问题
图6。香草VQ-VAE和MoTok学习符号的可视化。提出的MoTok模型显示出与语义类别更好的一致性
conclusion
论文的结论强调了运动引导标记 (MoTok) 框架在无监督对象发现领域带来的有效性和进步。结论中的要点如下:
- 性能改进:MoTok 在各种数据集上的表现优于现有的最先进方法,展示了其无需手动标记或额外监督即可有效将对象与背景分离的能力。
- 可解释的特征:该框架能够产生可解释的中级特征,这些特征超越了典型的低级特征集群。这种可解释性对于理解模型的决策和提高其在现实场景中的适用性至关重要。
- 对现实场景的鲁棒性:该方法在处理复杂而逼真的视频场景方面表现出显着的改进,解决了诸如对象/背景模糊性和多个移动物体的存在等挑战。
- 未来方向:作者承认存在局限性,例如在无监督设置下物体/背景分离的持续挑战。他们建议未来的工作可以探索时间对比学习和无监督聚类等技术,以进一步增强模型的功能。
- 对该领域的贡献:总体而言,MoTok 框架代表了一种有效结合运动引导和标记化的新方法,为无监督物体发现的进一步研究和开发铺平了道路 [T1]、[T4]、[T6]。
原文地址:https://blog.csdn.net/okimaru/article/details/140733321
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!