昇思25天学习打卡营第07天 | 函数式自动微分
昇思25天学习打卡营第07天 | 函数式自动微分
神经网络的训练主要使用反向传播算法,首先计算模型预测值(logits)与正确标签(label)之间的loss,然后进行反向传播,通过梯度来更新模型参数从而完成网路的训练。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。
函数与计算图
计算图是图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。
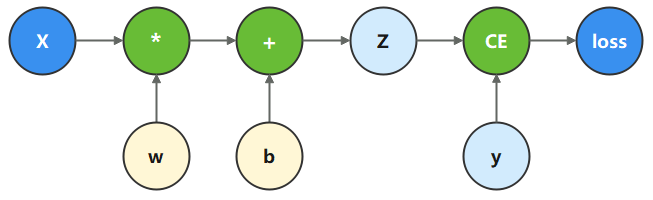
在这个模型中,
x
x
x为输入,
z
z
z为输出,
y
y
y为正确值,
w
w
w和
b
b
b是需要优化的参数。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias
def function(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss
通过执行function获得loss值:
loss = function(x,y,w,b)
微分函数与梯度
为了优化参数 w w w和 b b b,需要求参数对loss的导数 ∂ l o s s ∂ w \frac{\partial loss}{\partial w} ∂w∂loss和 ∂ l o s s ∂ b \frac{\partial loss}{\partial b} ∂b∂loss。
可以通过mindspore.grad函数来获得function的微分函数:
grad_fn = mindspore.grad(function, (2, 3))
grads = grad_fn(x, y, w, b)
此处使用了grad的两个入参:
fn:待求导的函数;grad_position:指定求导输入位置的索引。
Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数只输出loss一项。
如果函数输出多项时,微分函数会求所有输出对参数的导数。
def function_with_logits(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
此处
function_with_logits输出的z会影响梯度。
如果想要实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
def function_stop_gradient(x, y, w, b):
z = ops.matmul(x, w) + b
loss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))
return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)
Auxiliary data
Auxiliary data为辅助数据,是函数除第一个输出项外的其他输出。通常loss值为函数的第一个输出,而其它输出即为辅助数据。
grad和value_and_grad提供has_aux参数,设置为True时,可以自动实现前文中stop_gradient的功能。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)
神经网络梯度计算
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.w = w
self.b = b
def construct(self, x):
z = ops.matmul(x, self.w) + self.b
return z
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()
实例化网络和损失函数后,将其封装为一个前向计算函数,用于自动微分:
# Define forward function
def forward_fn(x, y):
z = model(x)
loss = loss_fn(z, y)
return loss
由于使用nn.Cell封装网络模型,其参数为Cell的内部属性,因此不需要指定grad_position参数,直接设置为None。
对模型参数求导时,使用weights参数,指定为通过model.trainable_params()方法从Cell中取出的可以求导的参数:
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)
总结
这一节从一个简单的线性函数
w
x
+
b
wx+b
wx+b出发,介绍了网络模型中数学函数的统一表示方法(即计算图),与loss的计算过程。使用grad和value_and_grad方法可以通过自动微分获取目标函数的微分函数,从而得到参数对loss的梯度,进而优化参数。对于需要输出辅助数据的函数来说,可以通过ops.stop_gradient进行梯度截断,或设置has_aux=True来自动完成。
在通过Cell封装的网络模型中,需要将模型和loss的调用封装为一个前向计算函数,从而进行自动微分。
打卡

原文地址:https://blog.csdn.net/qq_31254435/article/details/140212305
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!