面向演化计算的群智协同研究综述
源自:电子与信息学报
作者:公茂果, 罗天实, 李豪, 何亚静
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
摘 要
演化计算为代表的群体智能的迅速发展引发了人工智能领域新一轮技术变革。为满足多样化复杂系统应用需求,人工智能越来越趋向于跨级别的智能化、协同化研究。该文提出面向演化计算的群智协同的概念,根据群智协同层级将人工智能跨级别的智能化、协同化研究分为微观协同、中观协同与宏观协同,以群智协同视角对近年来上述分支领域相关研究做出了总结。首先,通过分析决策变量级协同、全局与局部级协同对微观协同进行了阐述。其次,从目标级协同和任务级协同两个维度对中观协同进行了总结。再次,以智能协同系统中存在的空天地海协同、车路云协同和端边云协同对宏观协同展开分析。最后,该文指出了面向演化计算的群智协同领域的研究挑战,并对相关领域发展方向进行了展望。
关键词
协同优化 / 群体智能 / 演化计算
1. 引言
演化算法(Evolutionary Algorithms, EAs)以达尔文主义自然选择、适者生存的原则为核心思想依据,是一类受到生物界进化思想启发的随机优化方法[1]。这类算法的优势在于其对于复杂、多模态和高维度的优化问题具有很好的适应性。在演化计算中,种群中的个体代表潜在解空间中的候选解,每个个体都有一个适应度值来评估其在解空间中的优劣。通过选择、交叉和变异等操作,演化计算算法能够在解空间中搜索并优化个体,逐步逼近最优解。具体而言,个体的编码方式类似于基因,通过交叉和变异操作来产生新的个体,从而探索解空间。选择操作根据个体的适应度值来确定哪些个体会被保留下来,以构建下一代种群。因此,演化计算旨在基于一个随机初始化的种群,通过个体进行多代的遗传、变异、自然选择等操作,保留更加适应环境的优良个体、淘汰相对不适应的个体,实现遗传物质的不断优化更新。除此之外,在演化优化过程中引入相关进化策略,关注个体的变异操作,通过随机性的变异来探索解空间。演化算法的一大特征就是基于上述种群搜索策略产生的隐式并行性,能够自动并行地在多个区域进行优化搜索,指导整个种群进入更有潜力的搜索区域。总体而言,演化计算算法具有较强的全局搜索能力,能够避免陷入局部最优解。对比传统优化方法,演化算法具有杰出的优化能力,由于其适应性和并行性,被广泛应用在科学理论研究、工程项目优化等各个方面,取得了令人欣喜的效果。因此,演化算法被广泛应用于群智协同的研究当中,其中具有代表性的相关算法包括非支配排序遗传算法(Nondominated Sorting Genetic Algorithm II, NSGA-II)[2]、多因子进化算法(Multi-Factorial Evolutionary Algorithm, MFEA)[3]、基于分解的多目标进化算法(Multi-objective Optimization Evolutionary Algorithm based on Decomposition, MOEA/D)[4]等。世界进化计算领域的年度盛会(Congress on Evolutionary Conference, CEC) IEEE上,每年都有学者就演化算法为核心的相关理论研究作报告,同时举办了多场此方向相关的比赛,引起了与会者的热烈讨论和持续关注[5–7]。这些现象表明,以多目标优化、多任务优化等为代表的基于演化算法的研究内容,已经开始逐步成为智能计算领域的一个备受瞩目的热门方向。
由此可见,作为近年来智能计算研究领域的研究热点的核心,演化算法的相关研究从不同的维度展开了计算智能的多重可能性与创新性。演化算法所依托的种群,本质上是群体智能的一个缩影,种群中个体的交流,知识信息的传递与迁移是协同的基石。决策变量通过不同的分组策略、评估优化以及完整解整合等过程进行变量之间的协同交互;全局与局部协同通过在种群搜索不同阶段引入局部处理,提升问题求解效率;目标协同、任务协同是充分利用目标、任务之间的正向知识迁移,促进问题的高效优化。各层级协同优化的关系如图1所示,其中Ti,i∈[1,N] 表示N 个不同的任务;min/maxFi(X) 表示对应上述N 个任务的优化方向;fi(X) 表示任务中待优化的多个目标,其中X 表示优化目标中的决策空间,由若干决策变量xi 构成。因此,本文所提基于演化计算的群智协同是以演化算法为核心,以协同策略主导解决高复杂度优化问题的多个研究方向的集合。
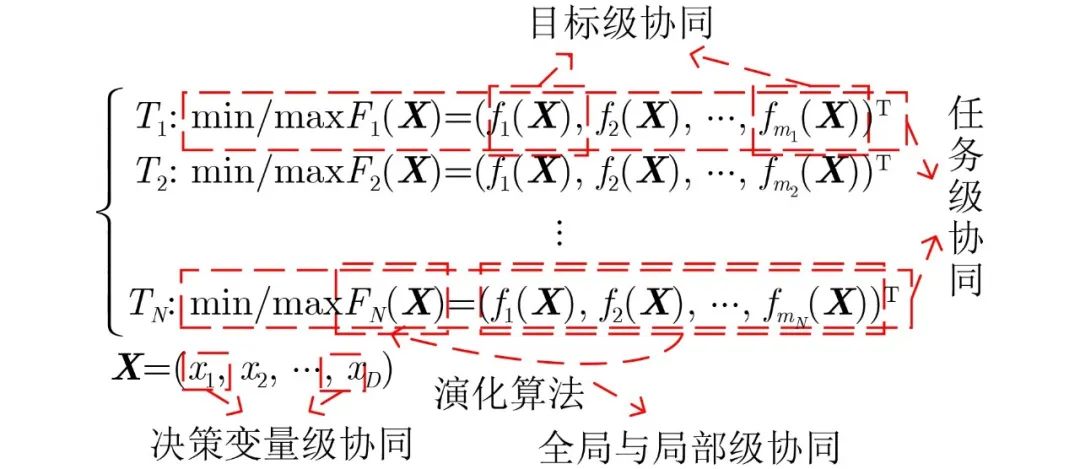
图 1 各层级协同优化关系示意图
据本文所知,目前已有的相关研究综述[8–19],分别对多目标优化、演化多任务优化等方向进行了总结与概括,但鲜有文献将这些研究方向进行系统整合综述。本文以全新的视角将决策变量协同、全局与局部协同、目标协同、任务协同4个方向进行整合为基于演化学习与优化的群智协同决策。本文面向演化计算的群智协同研究概念的提出,是以演化算法为出发点,以群智协同为核心,将现有的研究成果,根据其所处演化算法的不同层级(决策变量、全局与局部、目标、任务),对相应层级“群体”中“个体”之间所进行的智能协同交互进行提炼与剖析,并将其归类总结,最终形成面向演化计算的群智协同研究综述。
本文针对面向演化计算的群智协同研究从决策变量协同级、全局与局部协同级、目标协同级、任务协同级4个维度进行了综述。第2节,以决策变量分组方式对决策变量协同进行划分与归类;第3节,以是否处于种群搜索阶段对全局与局部协同过程进行展开;第4节,从目标数量的维度将目标协同分类为多目标协同与众目标协同;第5节,根据任务的优化顺序与逻辑,将任务协同划分为并行任务协同与串行任务协同;第6节,对智能协同系统中存在的空天地海协同、车路云协同和端边云协同展开分析。最后,本文讨论了面向演化计算的群智协同研究领域目前存在的挑战以及未来的研究方向。
2. 决策变量级协同
基于演化算法的决策变量级群智协同,聚焦于决策变量之间的耦合作用,并以此为基础通过不同路径提升演化算法的优化效率。具体而言,决策变量级群智协同体现在3个方面:(1)决策变量分组过程中的协同[20–24];(2)演化算法优化评估过程中的协同;(3)演化算法优化完整解整合过程中的协同。
2.1 决策变量分组过程中的群智协同
决策变量分组过程中,其耦合作用会从根本上影响演化算法优化的效率。针对现实世界中大部分问题为不可分问题的情况,决策变量分组过程中的群智协同显得尤为重要。当具有耦合关系的决策变量被分至不同的子组份时,不仅会形成伪局部最优解干扰演化算法优化过程和效率,甚至会导致原始问题无法被求解。面向决策向量分解的决策变量级群智协同研究可分为基于随机分组的决策变量级别群智协同、基于耦合作用学习分组的决策变量级群智协同。
基于随机分组的决策变量级群智协同,通过采用动态策略对子组份大小 𝑠进行优化[25]。Yang等人[26]在合作协同与差分进化(Cooperative Co-evolution with Differential Evolution, DECC-II)算法中设计了一种动态的决策向量分解策略,在预定义范围内随机调整s𝑠;以此为基础,他们进一步在多级协同进化(MultiLevel Cooperative Co-evolution, MLCC)[27]中引入了一种自适应策略来设置s 以获得更好的决策变量群智协同效果。最优解向量b 是一个n 维向量,其中n𝑛表示问题的维度,每个维度对应问题的一个决策变量。例如,在一个简单的优化问题中,如果要最小化一个函数f(x) ,其中 𝑥=(𝑥1,𝑥2,⋯,𝑥𝑛)是一个n 维向量,那么最优解向量 𝑏可以定义为使得f(b) 取得最小值的向量。合作协同进化萤火虫算法(Cooperative Coevolutionary Firefly Algorithm, CCFA)[28]和合作协同进化算法(Cooperative Coevolutionary AlgorithmS, CCAS)[29]根据它们在提升整体问题的最优解向量b 方面的性能,同时调整子组份大小和相应的子种群大小。
基于随机分组的群智协同存在的问题是对于子组份大小s𝑠的离散化预定义以及机械化平均分配决策变量,即一旦确定子组份大小,则直接将决策变量平均分配至大小相同的若干子组份当中。理想情况下,子组份的大小和数量应由决策向量分解策略自适应确定,子组份应该基于决策变量的耦合作用形成从而获取更高效的决策变量级群智协同[30]。
基于耦合作用学习分组的决策变量级群智协同中,对于决策变量耦合作用的分析重点关注原始问题的结构,对于不同程度的决策变量耦合作用,学者们通过采取不同类型机器学习算法针对性优化原始问题的分解策略,实现对问题结构的有效剖析,降低了求解原始问题的难度。以决策变量耦合作用形成的不可分关系程度为量度标准,提出了相应的基于分布模型思想、重叠分层思想的问题分解可行方案。基于上述思想,为实现决策变量级群智协同高效化,提升问题优化效率,需要解决以下两个问题。第一,设计一个有效的决策向量分解策略使子组份之间决策变量带来的耦合作用最小化[31];第二,当两个子组份共享同一个决策变量时[32],确定子组份之间可以协同分享的信息,如图2所示,其中xi 表示决策空间中的决策变量。
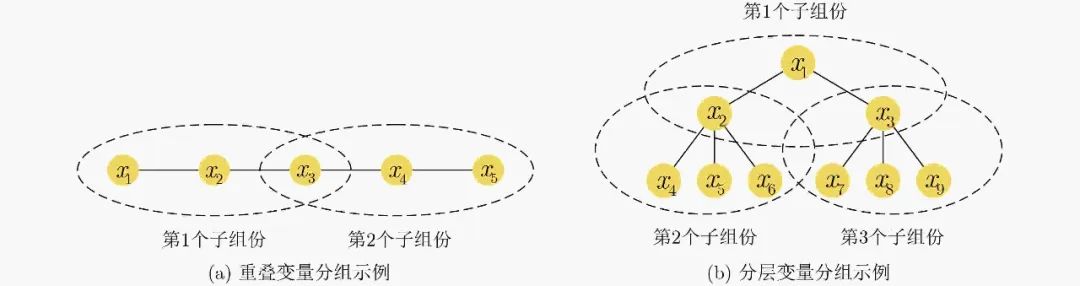
图 2 基于耦合作用学习分组示例
面向不可分问题,将其分为𝑘-不可分问题和完全不可分问题。作为𝑘-不可分问题的一种,问题结构简单的加性可分问题中,因子分布算法(Factorized Distribution Algorithm, FDA)[33]表现良好,其利用基于问题分解的条件分布方法来处理高阶决策变量耦合作用。对于问题结构相对复杂的𝑘-不可分问题,学者提出的方法主要基于对偶相互作用,如2元边际分布算法(Bivariate Marginal Distribution Algorithm, BMDA)[34],基于简单链式分布的种群的模拟算法(population-based MIMIC algorithm based on simple chain distributions)[35]。面向完全不可分问题,Strasser等人[31]在因子进化算法(factored evolutionary algorithm)引入了一系列重叠分组策略,包括随机重叠分组(random overlap grouping)、近邻重叠分组(neighbor overlap grouping)、中心重叠分组(centered overlap grouping)等。具有分层结构的决策变量之间的耦合作用更加复杂,如图2(b)所示,为解决这类问题,提出了一些分层决策向量分解方法。Yu等人[36]提出在每个层级对问题进行适当的分解,使EA可以有效地将下层的决策变量分解表示为上层的输入变量。上层子问题部分地调整了其下层子问题的演化过程,以此实现决策变量之间的群智协同。
2.2 演化算法优化评估过程中的群智协同
经过决策变量分组过程,决策向量被以各种方式进行合理化、高效化分解,进而实现了对于原始问题的分解。而在将决策变量分组,形成若干子组份之后,对于子组份中解的评估,体现了演化算法优化过程中另一层级的群智协同。
演化算法优化评估过程中的群智协同存在多种思想驱动的适应度评估方法。Potter和Jong[37]提出的经典方法合作型协同进化遗传算法(Cooperative Coevolutionary Genetic Algorithm, CCGA)中,对于某个子组份中决策变量适应度评估,保持其余子组份中决策变量取值不变(为目前最优值),只将待测子组份中决策变量值进行替换以达到评估的目的。Bergh和Engelbrecht[38]针对CCGA的改进方法、Yang 等人[26]提出的DECC-II方法都采取了类似的评估方式。Sun等人[32]提出的基于统计变量相互依赖学习的协同粒子群优化算法(Cooperative Particle Swarm Optimizer with Statistical variable interdependence Learning, CPSO-SL)中,子组份被设计为包含决策变量xi 以及与xi 耦合程度不低于给定阈值的其他变量,针对子问题的重叠困境,为每个子问题定义一个核心决策变量。在适应度评估过程中,未出现在子组份中的决策变量取值保持不变(为从原始解中提取的常数),也与上述适应度评估过程中的群智协同有着异曲同工之妙。
另一类适应度评估过程中的群智协同则是通过衡量子组份中解的贡献度来实现。在Zheng和Chen[39]提出的基于粒子群优化分层协同优化算法(Hierarchical Cooperative optiMization algorithm based on Particle Swarm Optimization, HCMPSO)中,经过对原始问题的分解,形成若干低维子组份。以尽可能提高由决策变量形成的子组份解对整个问题完整解的贡献为目标,在适应度评估过程中,引入增益函数 𝑔(𝑥𝑖)来衡量子组份解对于决策变量级群智协同的贡献度,并结合 𝑔(𝑥𝑖)对子组份解的进行评估
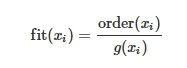
(1)
相似地,Yu等人[36]提出在每个层级对问题进行适当的分解,面向决策变量耦合形成的分层和重叠困境,分别进行决策变量级群智协同。在适应度评估层面,由于在演化算法进入到更高层级之前难以作出正确决策,因而需要选取由决策变量构成的子组份中的优质解并将其保留。
除此之外,学者们倾向于关注适应度评估过程中由子组份间的信息交换驱动的群智协同。Strasser等人[31]针对因子进化算法(Factored Evolutionary Algorithms, FEA)的研究中,适应度评估层面,由于每个子种群只针对决策向量X 分解之后组成的一个子组份Si 进行优化,因此为Si 定义的子种群需要知道决策变量的Ri(Ri=X/Si) 以进行局部适应度评估。已知Si 与R𝑖,子组份解的适应度评估可以表达为
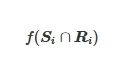
(2)
其中,Ri 的值来源于其他子种群,将每个子种群的Ri 值设置为完整解G 中的值,以便每个子群种群Ri 可以在f 上评估其部分解,因此Si 可以和其他子种群中的决策变量进行群智协同。Sayed等人[40]则采用基于模因算法的依赖关系识别(Dependency Identification with Memetic Algorithm, DIMA)模型将大规模连续优化问题的适应度评估转化为更简单的部分可分问题的评估。并将信息交换机制(information exchange mechanism)引入到DIMA当中,这种信息交流机制保证了在大规模优化问题中的每个决策变量在优化过程中只有一个实例值,在优化过程中,子问题的V 个最优决策变量将被更新至现有完整解中,当优化另一子问题,而其需要属于本子组份的V 个决策变量之外的N−V 个决策变量中的某些来完成适应度评估时,信息交流机制保证的决策变量唯一且最新的最优值将被采用。
2.3 演化算法完整解整合过程中的群智协同
为了提高优化效率,研究者们在演化算法优化的初始阶段通过对原始问题进行分解,利用机器学习算法对问题结构进行合理分析,实现了决策变量分组过程中的群体智能协同。然而,原始问题的分解导致了一个相关过程,即在适应度评估之后对原始问题完整解的整合。这种完整解的整合机制涉及到不同于前述两个过程的层面,展现了决策变量层面的群体智能协同。
完整解整合过程中的群智协同,通过衡量子组份对完整解的价值等维度对分解后的决策变量进行整合。Bergh和Engelbrecht[38]提出的协同粒子群优化算法(Cooperative Particle Swarm Optimizer, CPSO)中,每个特定子组份中的决策变量只具有完整解的一部分特定相关信息,在此基础上,经过分析计算赋予每个子组份对完整解的价值权重,并依据权重比例组合所有子组份构成最终的完整解。基于此机制,每个决策变量均对于整体问题的最优解向量b𝑏作出贡献,实现了决策变量级群智协同。Yu等人[36]应用依赖结构矩阵遗传算法(Dependency Structure Matrix Genetic Algorithm, DSMGA)为原始问题完整解的重组整合自动创建定制化重组算子,以重组子组份中的决策变量。Sun等人[32]的研究中,基于为每个子问题定义的核心决策变量。在完整解整合过程中,获取并连接优化后子问题的核心决策变量组成新的完整解,即完整解由第i𝑖个子种群的最优解xi𝑥𝑖组成,以此实现决策变量级群智协同。Strasser 等人[31]针对FEA的研究中,在FEA中设计了协同信息分享机制,面向重叠问题结构,选择种群中产生最佳适应度的个体整合至完整解G𝐺中。Sayed等人[40]采用DIMA模型则,通过有效的信息交流机制,从完整解的实时更新与准确性的角度实现了决策变量级群智协同。
本节介绍的决策变量级协同方法的总结如表1所示。
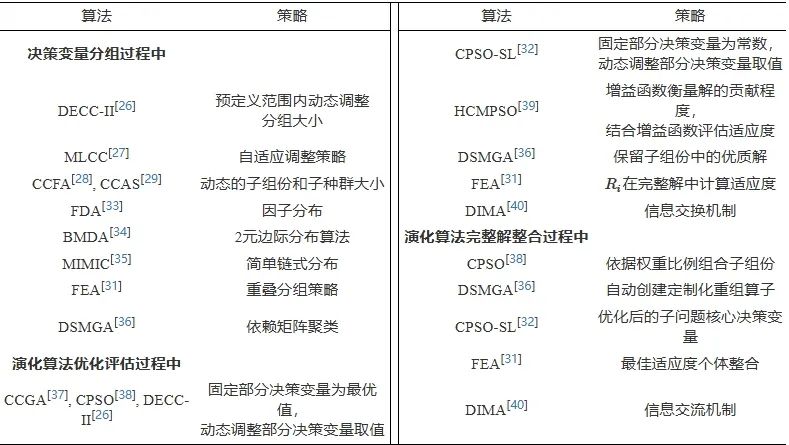
表 1 决策变量级协同方法的研究总结
3. 全局与局部级协同
基于种群的搜索方法能够实现对全局最优值的估计;局部搜索策略通过搜索邻域,对目前找到的所有最优解进行搜索,以得到更优解。基于种群的搜索方法与局部搜索策略的以协同方式结合在一起时,利用两者的互补优势,可提高混合算法解决问题的能力[41]。局部搜索策略在基于种群的搜索方法中的引入时机,可分为非种群搜索进行过程中和种群搜索进行过程中两个阶段。
3.1 非种群搜索过程中
在种群搜索前以种群初始化的形式进行局部搜索可以有效地提高整体算法的搜索效率。Rahnamayan等人[42]提出了一种新的基于反向学习(opposition learning)的种群初始化方法,来加速EAs的收敛速度。基于反向学习的主要思想是同时考虑估计和反向估计,通过这种方式以实现对当前候选解更好地近似。所提出的基于反向学习的种群初始化方法被嵌入到差分进化算法(Differential Evolution algorithm, DE) 中,通过种群初始化过程中的局部搜索与种群全局演化协同,提高收敛速度。均匀随机种群初始化被基于反向学习的种群初始化所取代。通过这种方式,尝试从更好(更合适)的候选解开始,而不是从纯粹的随机猜测开始。计算时间与初始化种群距离最优解的距离直接相关。根据概率论相关理论,在50%的情况下,解比相反的解离最优解更远。基于反向学习的种群初始化方法通过同时检查相反的解,可以提高种群搜索从距离更近的解开始的机会,选择与最优解距离较近的解作为初始解,从而有利于加快种群搜索的收敛速度。基于反向学习的种群初始化流程如图3所示,其中n𝑛代表进化种群的规模。针对旅行商问题(Traveling Salesman Problem, TSP)最初的种群初始化,Kang等人[43]提出了一种随机初始化(random initialization)和诱导初始化(induced initialization)结合的混合初始化方法。通过随机生成器选择一个起始城市,参考已知的城市之间的距离信息,从距离最近的城市到距离最远的城市依次排列。在此基础上,在每一代选择算子运行之前,他们还提出了一种顺序变换方法(sequential transformation method),将上一代生成的种群的解按顺序改变,然后应用选择算子。通过顺序变换方法进行局部混合初始化种群与全局种群演化的协同。由于种群是按照由前一代的解产生最优解构成的种群的顺序重新排列的,当产生下一代所使用的种群时,选择较优解的概率变大。

图 3 基于反向学习的种群初始化方法示意图
在种群搜索前使用领域特定知识对问题进行预处理也可以使搜索更加集中,提高整体算法搜索的收敛速度。针对广义TSP(Generalized TSP, GTSP)每个顶点和边不应该都被访问的特征,Gutin等人[44]提出了一种删除冗余顶点和边,保留最优解的问题约简算法。GTSP缩减技术,以局部预处理的方式,通过以非常低的成本显著降低问题复杂度,与全局演化求解协同,使得GTSP求解器的求解时间有效缩短。针对传统高分辨合成孔径雷达稀疏自聚焦成像算法难以有效平衡稀疏与聚焦特征的问题,Yang等人[45]通过引入熵范数表征SAR成像结果聚焦特征,在交替方向多乘子方法优化框架下,利用近端算法求解聚焦特征解析解。对于高维模式分类问题。Ishibuchi等人[46]提出了一种多目标遗传局部搜索算法(Multi-Objective Genetic Local Search, MOGLS),将数据挖掘中的两种规则评价指标(信任度和支持度)作为预筛选标准的思想,对模糊规则选择的候选规则进行预筛选。通过将这种候选规则的预筛选方法作为局部搜索过程与多目标遗传算法(Multi-Objective Genetic Algorithm, MOGA)相结合,形成局部搜索与全局演化协同,显著提高了模糊规则选择方法的效率。
3.2 种群搜索过程中
在种群搜索的迭代过程中引入局部搜索策略对部分个体进行局部改良,可以实现全局搜索与局部搜索的结合,提高找到最优解的概率。一种情况下局部搜索策略以确定性形式出现。Blum等人[47]提出了一种分支定界衍生方法(branch and bound derivatives)如束搜索(Beam Search, BS),和元启发式算法(metaheuristics)的混合形式,分支定界技术以交错的方式与元启发式算法协作,形成局部与全局的协同。首先,使用分支定界技术来识别搜索空间中可以找到最优解的区域。然后使用元启发式方法来利用这些知识,以改进分支定界技术所使用的边界,以强制进一步修剪分支。束搜索可以通过向种群中注入搜索空间中更有前景区域的信息来指导种群搜索。元启发式可以在合理的时间内找到好的解决方案,通过在分支定界内使用元启发式算法,以减少分支定界的空间和时间消耗。对于带时间窗的车辆路径问题(Vehicle Routing Problems with Time Windows, VRPTW),为了满足时间和容量的约束,Alvarenga等人[48]在遗传算法中引入了一个更复杂的交叉算子来有效交换两个客户之间的部分路线,并且不会在任何特定方向上引入偏差。通过引入专门化的交叉算子,从而避免产生在不可行域内的解,能够避免对不可行解搜索所付出的努力。交叉算子部分基于个体适应度的好坏,通过交叉产生的具有良好适应度的个体能够诱导向该方向的种群搜索。以交叉算子为媒介,进行局部个体优化与全局种群演化的协同。
还有一种情况下局部搜索策略以随机性形式出现。为了应对问题复杂性的提升,例如高模态、多模态,研究人员采用随机性形式出现的局部搜索策略以增强搜索多样性。由于纯进化方法无法应对低自相关2元序列的构造问题(Low Autocorrelation Binary Sequences, LABS)的复杂性,它们需要局部寻优算子的辅助才能提供最优或近似最优的结果。为此,Gallardo等人[49]引入了一种局部搜索策略——禁忌搜索(tabu search),这种策略作为独立的技术嵌入在模因算法(Memetic Algorithm, MA)中。使用禁忌搜索作为局部搜索策略,可以从一个初始解出发,持续在邻域内进行搜索,直至当前运行的局部搜索中不能找到更优解决方案忽略禁忌移动。在最速下降局部搜索过程后使用禁忌搜索技术,形成局部搜索与全局演化的协同,达到逃离局部最优的效果。Neri等人[50]提出了一种基于神经网络的方法来解决对等网络(Peer to Peer, P2P)中的资源发现问题,并提出了一种自适应全局局部模因算法(Adaptive Global Local Memetic Algorithm, AGLMA)来训练神经网络。采用模拟退火(Simulate Anneal, SA)作为局部搜索算法,局部搜索策略具有支持进化框架、提供新的搜索方向和开发可用基因型的作用。之所以选择SA元启发式方法,是因为它在决策空间中提供了一个探索性的视角,可以选择一个搜索方向,导致与起点不同的吸引域。在AGLMA中使用SA的主要原因是进化框架应该被协助找到更好的解决方案,从而改善可用的基因型,同时探索尚未探索的决策空间域。Lara等人[51]提出了一种新的逐点迭代搜索过程称为具有侧步功能的攀爬器(Hill Climber with Sidestep, HCS),通过将HCS集成到给定的进化策略中,处理多目标优化问题。根据当前迭代点的位置,HCS可以同时向Pareto点集移动和沿Pareto点集移动。HCS从单个解开始探索Pareto解集中的部分,并能在一定程度上处理模型的约束。通过上述方法,将HCS集成到给定的多目标进化算法(Multi-objective Optimization Evolutionary Algorithm, MOEA)中,形成局部与全局的协同,获得了一种新的模因策略。
另外一种情况下局部搜索策略以自适应形式出现。由于人们对问题的结构只有有限的认识,使得难以设计特定的混合算法,局部搜索策略以自适应的形式能够适应给定的问题。Caponio等人[52]提出了超适应模因差分进化算法(Super-Fit Memetic Differential Evolution, SFMDE)。该算法采用DE框架与3个元启发式算法进行混合,每个元启发式算法具有不同的角色和特征。SFMDE的一般算法理念是自适应地平衡超适应个体与其他种群的改进。为了实现这一目标,局部搜索算子在进化的各个阶段协助进化框架,并适用于超适应个体和其他个体。在优化过程的开始通过粒子群优化算法生成超适应个体来协助DE。另外两个元启发式算法是通过一个指标来衡量超适应个体相对于其他种群的质量,自适应地协调局部搜索算子,形成局部搜索算子与全局算法的协同。Krasnogor等人[53]关注一类特殊的全局-局部搜索混合MAs,描述了“自生成”机制的实现,以产生MAs使用的局部搜索。文章中使用的自生成元启发式的具体实现是基于MAs的。与MAs和混合全局-局部搜索策略的普遍观点不同,在不使用人为设计的局部搜索策略,而是允许自生成模因算法(Self-Generating Memetic Algorithm, SGMA)动态地发现和生成最适合特定情况的局部搜索策略。MAs自生成局部搜索策略能够适应每个问题、一类问题中的每个实例以及搜索的每个阶段,具有明显的优势。图4是这种MAs 的示意图。

图 4 全局-局部搜索混合模因算法示意图
本节介绍的全局与局部级协同方法的总结如表2所示。
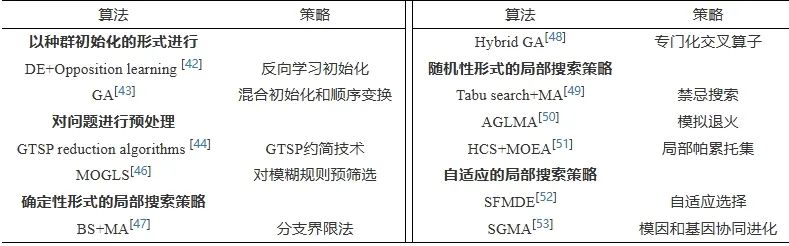
表 2 全局与局部级协同方法的研究总结
4. 目标级协同
多目标优化问题(Multi-objective Optimization Problem, MOP)是指需要同时处理多个相互冲突的目标的最优化问题。对于多目标优化问题,不存在一个解能够同时优化每一个目标函数。具体来说,一个解对一个目标函数的优化将会导致另一个目标函数的恶化。因此,多目标优化问题的解是一组解的集合。对于多目标优化问题,目标级协同通过使用遗传算法同时优化多个目标得到Pareto最优解集。为高效地选择和繁殖,常见的方法主要包括基于种群的Pareto方法和种群多样性维持方法。
4.1 多目标协同
多目标协同[54–56]从方法角度可以被分为两大类,即最优求解过程中的协同方法和种群多样性维持过程中的协同方法。最优求解过程中的协同方法中,基于Pareto最优的概念,衍生出的利用Pareto支配属性选择下一代的策略可以被分为,排序策略、竞争策略和保留策略;而种群多样性维持过程中的协同方法则是源于对随机基因漂变问题的解决,所提出的基于适应度共享的方法。
4.1.1 最优解求解过程中的协同
Pareto方法不仅根据目标函数值,还根据个体的支配属性来对它们进行选择和繁殖。具体可分为基于Pareto最优的排序策略和基于Pareto最优的保留策略。对于基于Pareto最优的排序策略,Goldberg[57]提出的基于Pareto的排序方法中,将等级为1的个体分配给种群中的非支配个体并将其移除,然后将等级为2的个体分配给修改后的种群中的非支配个体,以此类推。图5是上述两种排序方法的实例。Zhang等人[58]提出的MOEA/D将多目标优化问题被转化为一系列单目标优化子问题,采用进化算法对这些子问题同时进行协同优化。因为Pareto前沿面上的一个解对应于每一个单目标优化子问题的最优解,最终可以求得一组Pareto最优解[59]。但上述方法的本质是将多目标问题转化为单目标问题,无法从根本上实现多目标的有效平衡[60–63]。对于基于Pareto最优的保留策略,在采用选择算子之前,应用交叉算子和变异算子产生相当多的个体,然后选择所有非支配个体,如图6所示。
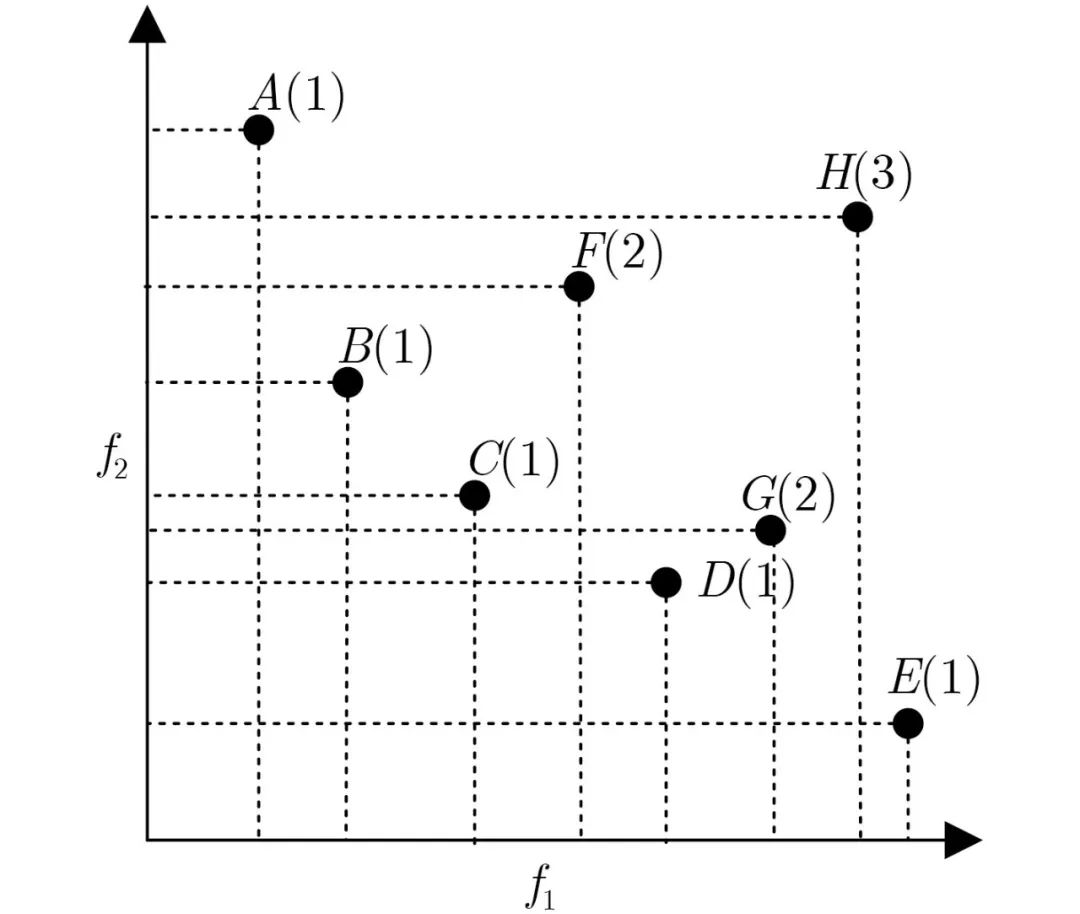
图 5 基于Pareto的排序示意图
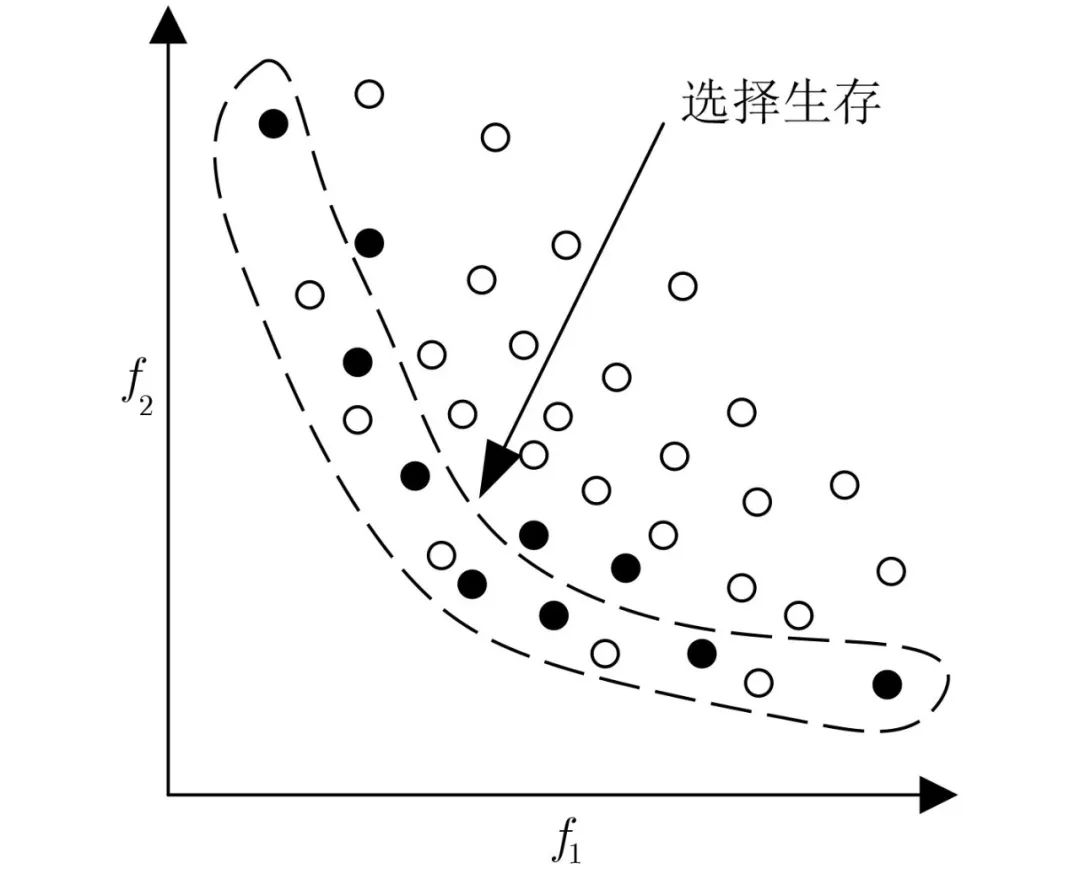
图 6 Pareto最优解集示意图
4.1.2 种群多样性维持过程中的协同
MOP的解需要满足两个条件,首先是Pareto最优解,其次是从Pareto最优解集中均匀采样得到的。Pareto方法求解MOP得到的解仅满足了第1个条件,而无法满足第2个条件。Pareto方法中的随机选择过程会导致种群的遗传多样性丢失,产生随机基因漂变(random genetic drift)[57]。为避免这种现象的发生,学者们又提出了一些其他方法来维持种群多样性[64]。
为了在多目标优化中维持种群多样性,主要可采用一种适应度共享方法[57,65,66]。通过适应度共享方法实现种群多样性维持过程中的协同。适应度共享方法是指当一个个体的邻域内存在其他个体时,每个个体的适合度值都降低。适应度共享方法使越拥挤区域的个体所能留下的后代越少[57],最终得到均匀分布在Pareto最优集上的种群。Horn等人[65]提出的仿帕累托遗传算法(Niched Pareto Genetic Algorithm, NPGA)在目标域(即函数空间)中,Srinivas等人[66]在决策变量域(即解空间)中,对个体之间的相似性(即距离)度量进行适应度共享。
4.2 众目标协同
面向众目标协同[67–70]问题,相关方法聚焦于对下述3类问题的解决:(1)EMO算法的搜索能力因目标(函数)数量的增加而下降;(2)逼近Pareto前沿所需的非支配解的数量指数级增长。针对上述问题的解决方法,构成了众目标协同的主要方法体系。
4.2.1 EMO算法的搜索能力因目标数量的增加而下降
大多数EMO算法使用Pareto支配来达到寻找Pareto最优解集的良好近似解集的目的。目标数量的增加会导致随机生成的种群的很大一部分变成非支配的,一个主要由非支配解组成的种群并不能为每一代创造新的解提供空间,导致搜索效率低。Pareto支配的使用使得搜索能力随目标数量的增加而下降是EMO领域面临的一个主要问题。目前为解决这一问题,可主要采用增加Pareto前沿选择压力和采用不同适应度评估机制的研究方法。为增加Pareto前沿选择压力,可通过基于修改Pareto支配的协同和基于偏好关系的协同两种方式来实现。
基于修改Pareto支配的协同方面,Sato等人[71]经实验研究得到了修正Pareto支配与修正目标函数对多目标进化的影响相似的结果。这表明修正Pareto支配可以增加Pareto前沿的选择压力,导致解的多样性降低。在EMO算法中,修正Pareto支配的基本思想是保证一个目标的小幅度提升不能导致一个目标的大幅度恶化,以此为协同的目标进行方法优化改进。Sato等人[71]在NSGA-II[72]中提出了一种改良的Pareto部分支配方法,使用目标的子集计算解的支配,这些目标子集在固定数量的代数后进行切换。这种方法通过对Pareto支配进行修正,增加了Pareto前沿的选择压力,如图7所示。图中的阴影区域表示每个解的支配区域。如图7(a)所示,当使用标准Pareto支配时,3个解都是互相非支配的。如图7(b)所示,当使用修改后的Pareto部分支配时,解F𝐹被解E𝐸支配。这表明通过修正Pareto支配减少了非支配解的数量,从而增加了Pareto前沿的选择压力,提高了NSGA-II处理多目标问题的能力。
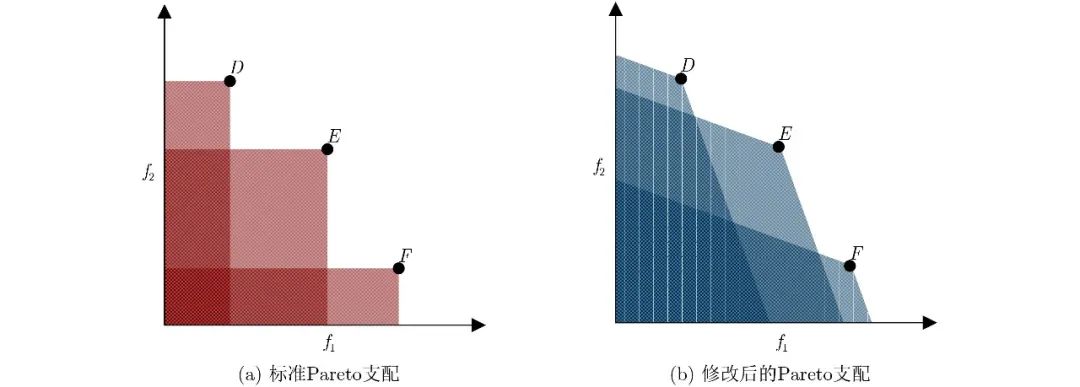
图 7 修正Pareto示例
基于偏好关系的协同方面,在修改Pareto支配的前提下,对非支配解引入不同的Pareto等级可以增大Pareto前沿的选择压力。目前已经提出了一些方法,以不同的方式区分非支配解从而得到解的Pareto等级。Drechsler等人[73]提出了一种偏好(favour)关系,在其约束下进行目标层面的协同。这种关系根据一种解优于另一种解的目标数量大小来确定,当解z 在偏好关系下优于解y 时,具体关系可表示为
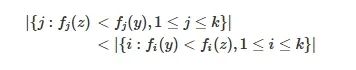
(3)
其中,k 表示k 个支配等级。在此基础上Sülflow等人[74]又对偏好关系进行了修改,不仅考虑了一种解优于另一种解的目标数量,还考虑了两种解的目标值差异。在处理多目标问题时,使用偏好关系对非支配解进行区分是得到它们的Pareto等级的一种简单方法。
4.2.2 逼近Pareto前沿所需的非支配解的数量指数级增长
EMO算法通常被设计用于搜索一组近似Pareto前沿的非支配解集[75,76]。通常情况下,为充分表示高维Pareto前沿,所需要的解的数量也更多。随着目标数量的增加,近似度高的非支配解的数量会呈指数增长,多目标优化算法的计算能力需求也达到指数级别。因此,昂贵的计算代价成为EMO领域面临的另一个主要问题。为了缓解这一问题,到目前已经提出了一些方法,可主要分为基于偏好信息(preference information)的协同和基于目标数量调节的协同。
基于偏好信息的协同方面,利用偏好信息关注Pareto前沿的特定区域,可以节省花费在寻找不感兴趣的解上的不必要的计算时间,是用于降低计算代价的有效方法之一。目前针对现有算法已经提出了一些不同的修改,以纳入用户的偏好信息,以此驱动目标级协同。Fleming等人[77]将偏好表达方法应用于多目标进化过程中焦点区域逐渐变小的MOP。Deb和Sundar[78]在NSGA-II[79]中引入了基于参考点的偏好信息,在Pareto排序后使用到参考点的归一化距离代替拥挤距离对每个解进行评估,在参考点周围搜索得到若干非支配解。污水处理工艺设计涉及多个相互冲突的目标的优化。对于设计人员来说,在工艺条件发生变化或出现新的约束条件时,有效地切换到新的最优操作策略在目标值方面检测至关重要。Ortiz-Martinez等人[80]利用NSGA-II开发了一种多目标优化策略,以获得最优解并处理过程条件或约束的变化。为了优化策略能够自适应地调整以达到最优,Han等人[81]提出了一种基于动态多目标粒子群优化(Dynamic Multi-Objective Particle Swarm Optimization, DMOPSO)算法[82]的最优控制器,用于处理动态多个冲突准则。
基于目标数量调节的协同方面,通过删除不必要的目标同时保留重要目标从而减少目标数量,可以缓解进化多目标优化的计算难题[83]。Deb和Saxena[84]提出了一种基于主成分分析(Principle Component Analysis, PCA)的目标简化方法,在去除不必要的目标的同时保持Pareto前沿的形状。除此之外,Brockhoff和Zitzler[85]提出了另一种基于简单指标的进化算法(Simple Indicator Based Evolutionary Algorithm, SIBEA),当一个目标不改变或只是轻微地改变解之间的Pareto支配关系时,这个目标就被删除,通过调节目标数量实现协同。
本节介绍的目标级协同方法的总结见表3。
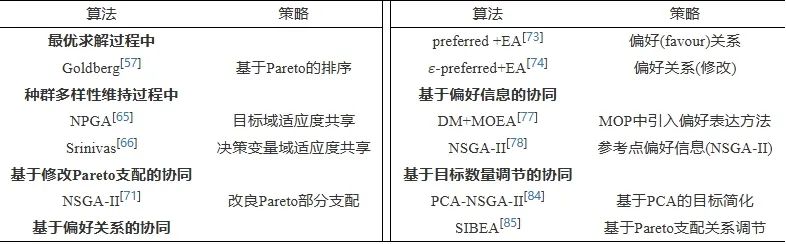
表 3 目标级协同方法的研究总结
5. 任务级协同
多任务优化(Multi-Task Optimization, MTO)算法利用各相似或相关任务之间的有效知识,同时处理多个优化问题。多任务优化问题的求解挖掘并利用任务间潜在的有效信息,基于多因子遗传模型的思想,充分利用种群搜索的隐并行性,使用一个种群表示多个任务的解,充分体现了处理MTO问题时任务间的合作协同性。多任务优化问题又可分为单目标多任务优化问题和多任务多目标优化问题,多目标多任务优化(Multi-Objective MTO, MO-MTO)[86]是一种旨在同时解决多个多目标优化任务的新兴范式。由于进化计算(Evolutionary Computation, EC)的方法在处理具有不同特征和难度的各种复杂优化问题时功能强大且效率高[87–90],在处理MO-MTO问题时通常采用EC算法,因此这一类问题也可称为进化MO-MTO(Evolutionary MO-MTO, EMO-MTO)[91]。广泛使用的EC算法包括遗传算法(Genetic Algorithm, GA)[92]、粒子群优化(Particle Swarm Optimization, PSO)[93]、差分进化(DE)[94–97]、分布估计算法(Estimation of Distribution Algorithm, EDA)[98]、蚁群优化(Ant Colony Optimization, ACO)[99]、进化搜索(Evolution Strategies, ES)[100]。
任务级协同,根据其解决任务的顺序策略,本文将其分为并行多任务协同与串行多任务协同两大类。并行多任务是目前主流的解决多任务优化问题的方案之一,从任务优化顺序的角度,其优化过程可描述为并行优化多个任务,并在其中进行任务间的知识迁移以加速各个任务的优化速度,提升优化效率;不同地,串行多任务则是根据一定的规则,对任务优化进行排序,根据此顺序以序列串行优化单个任务的方式对任务进行优化,每个任务的先验知识来源于上一个被优化完成的任务。
5.1 并行多任务协同
并行多任务协同优化问题,其重点在于种群之间的知识迁移。知识迁移不仅需要保证知识的正向迁移,即有效知识的种群间迁移,也要保证相应的知识迁移效率。因此,本文将其分为3个部分进行具体的方法分类:(1)知识迁移时机,(2)知识迁移内容,(3)知识迁移方式。
5.1.1 知识迁移时机
在多任务优化的过程中,种群间的繁殖可通过跨任务的知识迁移实现[101],这一过程发生的具体时机可以由固定世代间隔和触发式两种方法确定。一种方法是跨任务的知识迁移以固定的世代间隔发生。在MFEA中,每一代都进行跨任务的知识迁移[102]。在进化多任务处理 (Evolutionary MultiTasking, EMT)中世代间隔固定为10代[103],通过跨任务的知识迁移进行种间繁殖产生后代。
另一种方法是跨任务的知识迁移以触发式的形式发生。在多任务协同进化粒子群优化(MultiTasking Coevolutionary Particle Swarm Optimization, MT-CPSO)中,如果一个种群中的粒子的最佳位置在规定的迭代次数后没有得到优化,则触发跨任务的知识迁移来寻找更优的位置[104]。
5.1.2 知识迁移内容
对于多任务优化的知识迁移来说,通常希望用于迁移的解是能够实现正向迁移的优质解。正向迁移是指选择得到的迁移解能够从彼此的进化过程中获益的情况。为了从每个任务中选择得到优质解,目前可采用基于非支配原则、差分向量共享机制、增量朴素贝叶斯分类器、个体梯度(Individual Gradient, IG)、基于多问题代理(Multi-Problem Surrogates, MPS)的自适应方法主要五种方法进行选择[105,106]。
优质解可以基于非支配原则从每个目标任务中进行选择。在显式自编码的进化多任务中,基于高度潜在的任务间的相似性[107],可以从每个任务的非支配解中选择得到优质解进行迁移[103],帮助优化其他任务。在Lin等人[108]提出的方法中,首先将目标任务的非支配解作为正迁移解,然后基于正迁移解的原始搜索空间的欧式距离,选择距离最近的解作为优质解。
5.1.3 知识迁移方式
在多任务优化过程中,为寻找不同任务域之间的最优线性映射,从而实现从源域到目标域的跨任务知识迁移,采用的策略可主要分为隐式和显式两种多任务演化计算(Multi-Task Evolutionary Computing, MTEC)算法。具体来说,一种是采用单一种群统一表示多个优化任务的解的隐式策略,其中采用子种群分别表示不同优化任务的解;另一种是采用多个种群分别表示每个优化任务的解的显式策略。在隐式策略中,种群中的每个解都基于相同的概率被选为迁移解。与隐式策略相比,显式策略通过采用更灵活的迁移解选择方法,在一定程度上抑制了知识的负迁移效应。
在隐式知识迁移策略方面,隐式MTEC算法一般通过分别从两个不同的子种群中选择父代个体进行种群间的交叉变异实现种群间的繁殖,从而实现知识迁移[109]。在MFEA中,通过进行种群间的模拟二进制交叉实现知识迁移[102]。在Song等人[110]提出的多任务多群优化(MultiTasking Multi-Swarm Optimization, MTMSO)算法中,通过对每一代不同任务之间每个粒子的个体最佳位置进行算术交叉,实现跨任务的知识迁移。为了增强不同任务之间的知识迁移程度,Yin等人[111]提出了一种新的跨任务知识迁移方法。在这种方法中,一个任务使用另一个任务的搜索方向进行搜索,利用任务中的精英个体加快种群收敛速度,利用来自其他任务的差分向量增强搜索多样性。在面向大规模优化的进化多任务辅助随机嵌入(Evolutionary MultiTasking assisted Random Embedding method, EMT-RE)框架中,选择两个具有不同技能因子的解,通过对个体进行交叉,隐式地进行跨任务的知识迁移[112]。
在显式知识迁移策略方面,显式MTEC算法的每个优化任务都有一个独立的进化种群,通过采用显式策略进行跨任务的知识迁移。Feng等人[103]提出了一种显式MTEC算法,通过使用去噪自编码器学习不同多目标任务之间的最优线性映射,以映射作为桥梁进行知识迁移。除此之外,为构建不同任务之间搜索空间的映射,Liang等人[113]还提出了一种子空间对齐(Subspace Alignment, SA)策略,通过使用两个迁移矩阵来建立两个任务之间的联系,降低了负迁移的概率,实现了高效、高质量的知识迁移。对于MOP, Chen等人[114]提出了一种具有学习任务关系(Learning Task Relationships, LTR)的进化多任务算法,通过将每个任务的决策空间视为一个流形,将不同任务的所有决策空间联合建模为一个联合流形,然后构造由多个映射函数组成的联合映射矩阵,将不同任务的决策空间映射到潜在空间,最终可以共同学习不同任务之间的关系,从而促进MOP中所有任务的优化。同样,Tang等人[115]也引入了一种任务间知识迁移策略。具体来说,首先通过PCA方法建立任务决策空间的低维子空间,学习并求解两个子空间之间的对齐矩阵,然后将属于不同任务的相应解投影到子空间中,最后,可以在对齐的子空间中设计两种任务间复制策略。受异步优化的启发,Seenivasan等人[116]对一种顺序优化多任务学习模型(Sequential Multi-Task Learning, S-MLT)进行了探索,并将其应用于执行器械分割和器械-组织交互检测的多任务外科手术场景理解。具体来说,首先根据分割损失训练模型的特征编码器和分割模型,将收敛后的特征编码器和分割块的权重冻结,然后进行场景图检测交互的训练直到收敛。针对多任务优化问题废水处理工艺(WasteWater Treatment Process, WWTP)的特点,相关多任务优化方法在近年来被广泛研究[117–119],其中具有代表性的是Han等人[120]提出的一种自适应多任务优化(Adaptive Multi-Task Optimization, AMTO)策略,设计了一种基于自适应知识迁移方法[121]的多任务粒子群优化算法来实现WWTP的最优运算。据我们所知,到目前为止在最小-最大两层问题上能够提供可证明收敛保证的只有Gu等人[122]提出的基于梯度下降上升的单循环双时间尺度随机算法。在非凸强凹(上)强凸(下)设置下,Hu等人[123]提出了两种简单的单循环单时间尺度随机方法,用于求解一般形式的多块最小-最大双层优化问题。
5.2 串行多任务协同
串行多任务协同优化问题,其关键在于寻找并确定一个最优的串行多任务优化序列,这个序列的构成,由任务选择(Task Selection, TS)主导;而任务选择的依据,则来源于对任务相似度的衡量;最终,根据形成的串行多任务优化序列,开展任务间知识的迁移,使优化效率得到提升。
5.2.1 基于任务相似度衡量的协同
到目前为止,现有的MTEC方法主要专注于同时求解两种优化任务,而针对具有两个以上任务的MTO问题的研究工作还很少。在MTO情况下,知识迁移的一个自然而然思想是从所有任务中选择最匹配的个体。当需要优化的任务数多于两个时,为了避免这种耗时的方法,选择最合适的任务(或源任务)与当前任务(或目标任务)配对,进行有效的知识迁移是很重要的[124]。在MTO背景下,分析和测量任务相关性成为一项重要任务。任务相似度衡量的一项开创性工作跨任务适应度距离相关性(Cross Task Fitness Distance Correlation, CTFDC)[125]从最佳解之间的距离、适应度等级相关性和适应度场景分析三个不同的角度衡量了任务之间的相似性。Gupta等人[126]在对不同任务的目标函数场景进行相关性分析的基础上,提出了一种协同度量( 𝜉),用于获取和量化不同优化任务之间一种互补模式。通过任务间相似度衡量驱动任务间协同。对于两个最小化目标函数F1 和F2 ,它们之间的协同度量可以表示F2 对F1 的累计互补效应,具体可表示为
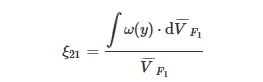
(4)
其中

(5)
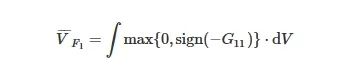
(6)
其中,
![]()
表示统一搜索空间中不可能相交的子空间的总体积,dV 为统一搜索空间Y 的微分体积元素,G11(y) 为F1 对自身的局部互补系数,G21(y) 为F2 对F1 在y 处的局部互补系数,具体表达式为
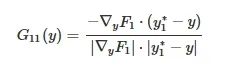
(7)
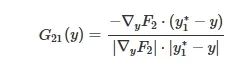
(8)
其中,
![]()
表示目标函数F1 的全局最优值,y∈Y 是统一搜索空间中的点。
5.2.2 任务选择
对于不进行任务选择的MTO方法,采用相同的随机交配参数rmp,对不同任务的个体进行随机分组,实现跨不同域的信息共享。然而,考虑到优化任务属性的多样性,采用统一的方法控制跨任务的信息共享是不合理的,因为并不是所有的任务都能从知识迁移阶段受益。基于相似任务或互补任务应通过信息共享获得更好的优化性能的假设,任务选择策略可以分为两类[127],即基于相似性的策略和基于反馈的策略。
基于相似性的策略根据任务之间的相似度选择源任务。为了量化任务间的相似度,最直接的一类方法是测量两个任务种群分布之间的距离或差异。在自适应知识迁移的代理辅助进化框架(Surrogate-assisted Evolutionary Framework with Adaptive Knowledge Transfer, SaEF-AKT) [128]中采用KL散度,在多源选择迁移优化框架(Multi-Source Selective Transfer Optimization, MSSTO)[129]中采用Wasserstein距离来衡量种群分布之间的相似性。Tang等人[130]提出了一种基于组的MFEA,利用Manhattan距离将相似的任务聚类为一组,在组内进行遗传物质的迁移,消除了负迁移效应。除了上述方法外,还有另外一类方法用于间接衡量任务间相似度。例如在文献[131]中,构建了一个由多个概率模型的加权和组成的混合模型,每个概率模型代表单个任务的高质量种群,通过最大似然估计得到混合模型的参数,该参数可作为任务选择概率,选择与目标任务最相似的源任务。在此基础上,Min等人[132]在基于多问题代理的迁移进化多目标优化(Transfer Evolutionary Multi-objective Optimization base on Multi-Problem Surrogates, TEMO-MPSs)中建立了一个类似的混合模型,其中每个概率模型是一个子问题的代理,是一个高斯过程模型。
基于反馈的策略通过使用进化算法搜索过程的历史信息进行任务选择,从而避免过多计算资源的消耗。目前,大部分方法都是将反馈信息用于动态自适应地控制随机交配参数rmp。在文献[133]中,Liaw等人确定了任务i𝑖的迁移概率
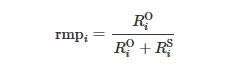
(9)
其中,
![]()
分别是最优解通过相同任务i 和其他任务改进的比率,rmpir 决定是否对任务i𝑖进行跨任务进化。然而,使用这种方法确定的rmp是用一种粗粒度方法控制的,也就是说不同的任务仍然被认为是等价的。为了对任何一对任务的关系进行评估,需要设计一种细粒度控制策略。Shang等人[127]提出了一种基于信用分配的任务选择方法,采用一个K×K 矩阵W 记录不同任务传递的解的效果,当源任务i𝑖给定时,目标任务j 的选择概率为
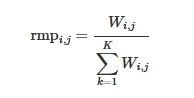
(10)
其中, 𝑊𝑖,𝑗表示从任务𝑗成功迁移到任务𝑖的个体累计数量。在该方法中,根据所设计的矩阵,可以选择合适的任务进行正向知识迁移。
5.2.3 任务间知识迁移
在传统的MTO算法中,通常采用一种在不同任务域中实现遗传物质迁移的统一表示方法进行隐式知识迁移[102]。然而,这种隐式知识迁移策略忽略了知识的负迁移效应。为了更好地识别正迁移和抑制负迁移,设计了一系列显式策略,通过将个体从源域迁移到目标域进行知识迁移。显式知识迁移策略具体可分为3类,包括基于分布的策略、基于匹配的策略以及两种策略的协同。这3类策略可用于克服由不同原因造成的负迁移,包括不同的最优位置,不同的场景相似性,不同的种群分布,或者不同的进化路径。
基于分布的策略旨在克服由不同的最优位置和不同种群分布造成的负迁移。为考虑不同的最优位置,Ding等人[134]提出了广义MFEA(Generalized MFEA, GMFEA),旨在将当前最优个体迁移到均匀搜索空间的中心。在GMFEA中,通过利用某一任务的最优个体的均匀中心与样本均值的差值,来进行迁移操作。为了更好地包含分布信息,Liang等人[135]通过在源域减去样本均值在目标域加上样本均值,将高质量个体从一个域迁移到另一个域,直接重新获得了种群分布的差异。
基于匹配的策略旨在克服由不同任务场景引起的负迁移。线性域自适应MFEA(Linearized Domain Adaptation-MFEA, LDA-MFEA) [136]是最先提出的方法,这种方法首先根据个体的适应度函数对源域和目标域的个体进行排序,然后用最小二乘法构造一个一一映射矩阵。在基于匹配的策略的框架下,Lim等人[137]利用两层神经网络对源域和目标域中排序后的个体进行非线性匹配,以获取两个域之间更复杂的关联。
策略间协同通过将分布信息引入基于匹配的策略中,旨在克服各种优化场景下的负迁移,以混合方法实现协同。Xue等人[138]提出直接将排序后的个体从源域匹配到目标域可能会导致混沌匹配问题。为克服这一问题,他们提出了一种新的秩损失函数,用于获得源-目标实例之间的高级任务间映射,然后构建了一个基于进化路径的概率表示模型来表示优化实例,有效地避免了源-目标域之间的混沌匹配,最后利用渐进式高斯表示模型,根据所提出的秩损失函数,用数学方法推导出了一个用来弥补源-目标实例之间的差距的仿射变换的闭合型解。
本节介绍的任务级协同方法的总结见表4。
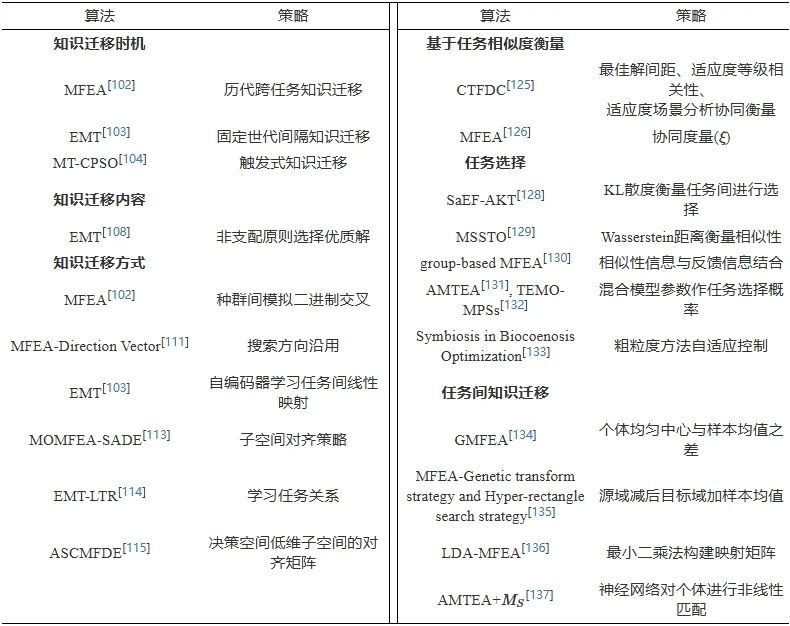
表 4 任务级协同方法的研究总结
6. 智能协同系统
智能协同系统是一种整合多类资源、多个系统和多个实体,通过协同工作实现更高效、更智能的系统,包括空天地海协同、车路云协同、端边云协同等领域。进化计算和协同优化方法在这些智能协同系统中具有关键意义。对于空天地海协同系统,其涉及到多个领域的协同工作,如航空航天、地面交通、海洋监测等。进化计算可用于优化空中飞行路径规划、资源分配、航线设计等问题。通过相关算法,系统可以自动优化飞行计划,提高飞行效率和安全性。协同优化方法则可以赋能不同部门或系统之间的信息共享、资源协调,从而实现空天地海协同系统的高效运行。对于车路云协同系统,其涉及到车辆、道路基础设施和云端服务器之间的协同工作。进化计算在车辆路径规划、交通流优化、车辆调度等方面具有广阔的发展空间。通过相关算法,系统可以统筹优化车辆路径,减少拥堵,提高交通效率。协同优化方法则能够帮助建立车辆与道路基础设施的实时通信、路况反馈,从而实现车路云协同系统的智能化管理。对于端边云协同系统,其涉及到终端设备、边缘计算节点和云服务器之间的协同工作。进化计算可以用于优化边缘计算资源分配、任务调度、网络优化等问题。通过相关算法,系统可以在资源限制条件下实施资源的优化配置和利用,提高实际应用场景中的计算效率和服务质量。协同优化方法实现不同级别的计算节点之间的任务协同、资源共享,从而实现端边云协同系统的高效运行。
6.1 空天地海协同
移动通信技术的发展与革新为更快速、更远距离、更高质量的网络互联带来了可能。而为了进一步提升网络互联互通的广度与质量,空天地海协同网络的相关研究不断深入。空天地海协同网络集合了天基网络(各类卫星、地面基站、控制中心等)、空基网络(飞艇、无人机等)、地基网络(蜂窝网络、无线局域网等)与海基网络(水面网络与水下网络)。21世纪初期,美国、欧盟、日本的发达国家纷纷开始投入建设研究天地协同的相关项目,除了美国为国防部提出建设的“天地一体化”信息网[139],欧盟和日本也分别建立了SUITED项目与STICS项目。而中国也将天地一体化信息网络加入“科技创新2030—重大项目”。Liu等人[140]提出一种空地协同场景下基于孪生网络的通信干扰智能识别方法,形成了通信抗干扰识别的空中与地面布局能力。
随着空天技术的进一步发展,无人机等航空器的成本下降催生出空天地协同网络的概念与构想。例如,谷歌公司的Loon 项目和Facebook 公司的Aquila项目,分别通过平流层的热气球和高空太阳能无人机实现了偏远贫困地区的低成本网络覆盖,也能够为城市这类用户密集地区提供高性能增强覆盖。文献[141]提出了一种在线控制框架来协同分配空天地一体化网络的频谱资源。系统可以实时进行接入控制、请求调度、无人机调度和资源切片,实现资源隔离的服务供应。文献[142]提出了聚合比的概念协同网络通信资源与计算资源消耗的平衡问题。
然而对与实现全球范围互联互通的空天地海协同网络,如何保障过程中不同的用户服务质量(Quality of Service, QoS)差异化等级需求并实现协议、网络、业务、终端等方面的深度协同成为了空天地海协同的挑战。网络切片技术为空天地海协同提供了可行的方案,其利用软件定义网络(Software Defined Network, SDN)[143]和网络功能虚拟化(Network Function Virtualization, NFV)[144]可以屏蔽底层物理网络在通信协议上的差异,在通用物理基础设施上按需定制虚拟网络,为不同类型的业务提供差异化QoS保障。具体而言,NFV将网络资源虚拟化后聚合为资源池,并交由支持SDN的切片管理控制器协同管理,网络切片架构由各部分网络切片、虚拟资源池、物理网络与切片管理控制器共同组成。基于虚拟资源池,切片管理控制器将多个的虚拟网络功能模块(Virtualised Network Function, VNF)组成的服务功能链嵌入到物理网络中[145],为各个业务进行资源协同调配,构建端到端虚拟网络,以此可以满足差异化QoS需求[146]。文献[147]基于机器学习方法构建了管理功能边缘化的空天地海协同网络体系架构,根据需求进行网络服务协同化定制。而面向隐私保护与安全泄漏等问题,文献[148]将区块链技术融入到空天地海协同网络切片的架构中,针对复杂异构网络的潜在问题提出了解决方案。
6.2 车路云协同
传统车路协同系统旨在提供车辆与路侧设备之间的信息交互,辅助单车决策和提供有限车载信息服务。这种协同系统可以通过车辆与车辆之间的通信或车辆与道路设备之间的交流来改善交通流和道路安全。然而,传统车路协同系统存在一些限制,如受限的应用场景和有限的服务能力。
为了进一步提升道路交通系统的整体性能,Li等人[149]首先提出了一种创新的发展思路——车路云一体化融合控制系统。该系统利用了现代通信和计算技术,将人、车、路、云等多个维度的要素融合在一起,以实现更高水平的协同效应。其中,融合感知是车路云一体化融合控制系统的重要组成部分。通过车辆和道路设备的感知功能,系统可以准确地获取环境信息,包括路况、交通情况、行人等。这种融合感知能力使系统能够更精确地识别交通状况,并提供有效的决策基础。另一个关键特性是群体决策和协同控制。在车路云一体化融合控制系统中,车辆和道路设备形成了一个群体。通过进行群体决策和协同控制,系统能够更好地协调车辆之间的行为,并实现更高效、安全和绿色的交通。车路云一体化融合控制系统在协同控制方面还借助了云计算技术。通过与云端的数据处理和决策支持,可以更好地利用大数据分析和机器学习等技术,实现更智能、高效和精准的决策。
蜂窝车联网(C-V2X)技术创新,边缘计算网络(Edge Computing Network, ECN)和高精度定位系统(High Precision Positioning System, HPPS)等的发展与演进,为构建智能网联车路云协同系统(Intelligent Connected Vehicle-Road-Cloud Cooperative System, IC-VRCCS)提供了核心驱动力[150]。智能网联车路云协同系统将传统车路协同系统与C-V2X技术进行了融合。通过支持直连通信的PC5接口和长期演进(LTE)/5GUu接口的应用,该系统可以拓展各类“人-车-路-云”服务场景。相比传统车路协同系统,智能网联车路云协同系统具有更强大的服务能力和更广泛的应用场景。另外,智能网联车路云协同系统还引入了边缘计算网络和高精度定位系统。边缘计算网络提供了更快速的数据处理和决策反馈,通过高效的计算资源和低延迟的通信连接,提升了协同控制的效率和准确性。针对边缘计算环境的安全性,He等人[151]提出了提出边缘可信计算基这一面向边缘计算的可信协同框架。高精度定位系统则提供了精准的位置信息,有效改善车辆定位和路径规划,从而优化了协同决策和控制的结果。为了提高边缘服务器的能效,Zhang等人[152]设计了一种面向绿色计算的车辆协同任务卸载框架,车辆配备能源收集设备通过彼此间共享绿色能源和计算资源协作执行任务。除此之外,Wang等人[153]也提出一种车载边缘计算中多任务部分卸载方案,该方案在充分利用网络边缘设备的计算资源条件下,考虑邻近车辆的剩余可用计算资源,以最小化总任务处理时延。为了在车辆高速移动场景下为用户提供高效可靠的服务,Shao等人[154]提出一种基于位置预测的智慧公路边缘任务协同机制。
6.3 端边云协同
边缘计算作为一种新兴的计算模型,与传统的云计算相比,具有一些明显的优势。边缘计算通过将计算任务在离数据源头更近的位置执行,可以大大降低数据传输的延迟。相比之下,云计算需要将数据传输到远程的云服务器进行处理,可能会导致较高的延迟。然而,边缘计算并不是适用于所有类型的任务。云计算的特点是可以提供大规模的计算和存储资源,适用于处理复杂的大数据任务。对于那些对计算和存储资源要求较高的任务,例如大规模数据分析或数据统计,边缘设备的计算能力可能无法满足需求。在这种情况下,仍需要依赖云计算来完成任务。此外,边缘计算在服务稳定性方面相对较弱。边缘设备可能受限于资源限制或网络状况不佳,导致服务的可靠性下降。相比之下,云计算通过在数据中心集中管理和控制,提供更高水平的服务稳定性和可靠性。因此,边缘计算的定位是作为传统云计算的补充,以弥补现有云计算模型的一些不足之处。
边缘计算可以通过在靠近数据源头的位置执行计算任务,提供低延迟的服务,同时在处理对资源要求较高的任务时,可以借助云计算来提供高性能的计算和存储能力。这种结合边缘计算和云计算的融合模式,可以更好地满足各种应用场景的需求。对于未来的发展导向,边缘计算的重点将是实现端边云架构的高效融合。这意味着终端设备、边缘设备和云服务器之间将形成一个紧密协作的整体,实现资源的高效利用和任务的优化分配。最理想的效果是,在不同的层级上充分发挥云计算和边缘计算的优势,实现更高效、灵活和可靠的计算与服务。这将推动边缘计算在各个领域的广泛应用,促进数字化转型和智能化发展的进程。
端边云架构是一种终端边缘云协同的架构模型,可以通过纵向和横向协同来满足不同层次和方向上的需求。纵向协同主要涉及不同层次间的协作,旨在充分利用各层次设备的特点,满足不同应用场景的需求。相较于传统的云计算,边缘计算具有更低的服务响应延迟,可以实现更快速的数据处理和决策反馈。然而,边缘计算的计算能力和负载承载能力是有限的。当网络请求数量急剧上升时,边缘计算可能无法应对大量的计算负载,导致服务的响应速度下降。为了克服这个问题,Tong等人[155]将服务的架构组织成层次型的结构,它的主要思想是根据服务请求数量的不同,利用边缘计算提升服务的响应速度,当请求达到高峰超过边缘计算的处理能力时,借助云计算的计算资源提升服务的处理能力。这种层次型的架构组织可以实现边缘计算和云计算的合理分工,根据需求灵活调配实时计算和大规模计算的能力。在纵向协同的过程中,数据卸载和计算卸载是必要的步骤[156]。数据卸载是将不同层次的数据迁移到其他层次,以满足多样化的需求。例如,将边缘设备收集的数据迁移到云端进行更复杂的分析和处理。这样可以充分利用云计算的强大计算能力,同时减轻边缘设备的负担。为了满足用户日益增长的计算密集型和时延敏感型服务需求,同时最小化计算任务的处理成本,Zhou等人[157]通过改进分层自适应搜索算法设计了混合粒子群优化算法来进行计算卸载成本优化。为满足资源密集型和延迟敏感型任务的需求,Tuli等人[158]提出了一种IoT-Fog(Edge)-Cloud端边云融合框架,将终端、边缘和云3个层次作为整体的组成部分。边缘层为终端设备提供低延时的服务,而云层则提供强大的计算服务。这种纵向协同的架构模式使得终端设备可以灵活地满足多样的计算需求。
横向协同是指同一层次下多方之间的数据交互。在端边云架构中,为了满足多样的应用需求,多方之间的数据共享变得至关重要。特别是在边缘层,由于边缘设备的地理分布性质,边缘节点之间的数据共享成为必要的步骤,以支持多样化的应用场景。为了提供高效的拼车服务,Li等人[159]开发了一个车联网拼车系统。在该系统中,路边计算单元负责收集道路上的车辆和拼车用户信息,以提供高质量的拼车服务。为了实现数据的共享和协同,多个路边计算单元之间建立了连接和通信机制,以实现数据的共享和交流。不同路边计算单元之间的数据共享使得车联网拼车系统可以远离传统的单一数据来源和处理方式,从而提高整个拼车系统的性能和灵活性。
7. 结论与展望
近年来,以演化算法为核心,以多目标优化、多任务优化等面向群体智能协同方案寻优的问题成为了计算智能领域的一大热点研究。本文将这些研究问题进行归类总结,从协同的角度,创新性地将目前以演化算法为核心的相关研究总结概括为面向演化计算的群智协同研究。目前的面向演化计算的群智协同研究领域已经有了大量的高质量研究成果,但也存在如下的研究挑战与潜在研究方向:
(1)决策变量级协同方面:主要存在两个类型的问题,即问题分解与变量链接(关系)学习,子问题之间的协作。变量链接(关系)学习指的是面向演化计算中的决策变量协同,针对大量的决策变量,学习和利用变量之间的关联性和相互作用,对优化过程产生促进与帮助。对于问题分解与变量链接(关系)学习问题:(a)现有的重叠和层次变量分组大多是手工或基于领域知识进行的。如何设计一个智能的重叠和层次变量分组策略仍然是一个开放的问题。(b)虽然已经提出了很多变量分组策略,但高效的变量分组策略仍然很少,尤其是在组合优化、动态优化和鲁棒优化方面;对于子问题之间的协作问题:(c)如果子组份之间的交互作用是不可避免的,那么目前还缺乏针对不同问题选择最适合的协作者选择策略和个体适应度分配的研究。(d)自适应/时间依赖的协作者选择尚未得到很好的研究,它可能是处理链接学习错误和问题的一个候选解决方案。
(2)全局与局部级协同方面:现有的方法可在以下方面进一步改进。一是可以对局部搜索策略进行详细研究。全局与局部协同方法目前在学术研究以及广泛的现实世界问题领域中取得了的成功。许多专用的局部搜索策略已经被设计出来与种群搜索方法相结合,以更好地解决特定领域的问题。局部搜索策略作为一种精炼程序的使用能够提高传统EA的搜索效率和解决方案精度,可以被嵌入到传统EA中来解决新发现的问题。对于针对特定问题专门设计的局部搜索策略,可进一步将其扩展到问题的其他变体或其它问题上。未来研究的另一个议题是局部搜索策略的改进。在优化问题中,针对当前解向量(或解空间中的一个点),通过一定的规则或算法确定的周围解的集合可称作当前解的邻域结构。这个集合中的解与当前解在问题空间中是相邻或接近的,通常是通过对当前解进行一些特定的变化或扰动而得到的。确定当前解的邻域结构后,可以通过一系列邻域操作来生成邻域内的解。这些邻域操作可以包括变异操作、交叉操作、移动操作等。局部搜索的效果强烈依赖于用于生成当前解的邻域结构的选择,生成邻近解的过程可在未来的研究中得到改进。
(3)目标级协同方面:目标协同决策问题可分为效率优化问题,计算成本问题。对于基于遗传算法的多目标优化的应用中,如何提高重组操作的效率是一个重要的问题。如果种群广泛分布在Pareto最优解集附近,则使用随机配对进行再重组操作将不能得到好的搜索点。因此,需要一些方法来提高使用重组进行搜索的效率。此外,对于多目标决策,需要通过对决策者洞察问题的特征和对其偏好的估计来支持决策者。获得Pareto最优解集是实现该目标的第一步。类似交互进化的过程可能是实现多目标决策的有用工具。EMO领域和MCDM领域的协作可能能够设计出更复杂的方法。一组统一的标量函数可以作为一种替代指标,因为即使对于许多目标,它们的计算也很容易。其他的方法不仅关注于高维目标空间中的特定区域,不仅使用了帕累托的优势,而且还关注了决策者的偏好。
(4)任务级协同方面:相关研究挑战和潜在可能性包括:(a)探索一种新的正向知识迁移机制,其中可分为迁移时机和迁移内容两类。关于迁移时机,我们需要在迁移成本和迁移效果之间找到一个良好的平衡。关于迁移内容,目前找到的最好的解决方案都是可以迁移的好选择。但是,由于本构任务的搜索空间明显不同,这可能会适得其反。MTEC算法可以在线学习这些特征,然后及时合理地调整知识迁移策略。因此,一个重要的研究课题是建立近似的在线模型,利用优化过程中产生的数据来量化任务之间的关联。(b)开发MTEC的实际应用,如在机器学习[160,161]、智能制造和智能物流方面,我们认为MTO的概念在可用知识转移方面为改进问题解决提供了一个新的视角。科学、工程、运筹学等领域的一些复杂问题都极大地受益于这些建议。目前,大多数应用都集中在传统的连续或离散优化领域。因此,MTEC与实际问题的实际应用之间仍然存在很大的差距。
(5)协同智能系统化:未来为了将人工智能模型落地于多元复杂的应用场景,需要协同多个模型共同打造人机协同智能系统。首先,为应对应用场景下的复杂需求,基于智能框架理论,可以融合多个人工智能模型进行协同互补,实现由独立的人工智能模型完成小应用到协同智能系统解决大应用难题的转换。同时,通过融合人工智能领域的核心技术形成感知、认知、智能决策为一体的协同智能系统,能够实现产业智能化水平的提升,加速协同系统的智能化进程。随着人工智能相关理论与技术的突破以及应用领域广度和深度的拓展,协同智能系统的应用场景也将会更加丰富,这也是推动产业智能化发展与升级的主要力量。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
原文地址:https://blog.csdn.net/renhongxia1/article/details/140600575
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!