Hadoop的安装和使用
1. Hadoop简介
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
- 高可靠性。
- 高效性。
- 高可扩展性。
- 高容错性。
- 成本低。
- 运行在Linux平台上。
- 支持多种编程语言。
2. 分布式文件系统HDFS
简介
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop项目的两大核心之一,是针对谷歌文件系统(Google File System,GFS)的开源实现。
总体而言,HDFS要实现以下目标:
- 兼容廉价的硬件设备。
- 流数据读写。
- 大数据集。
- 简单的文件模型。
- 强大的跨平台兼容性。
体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。
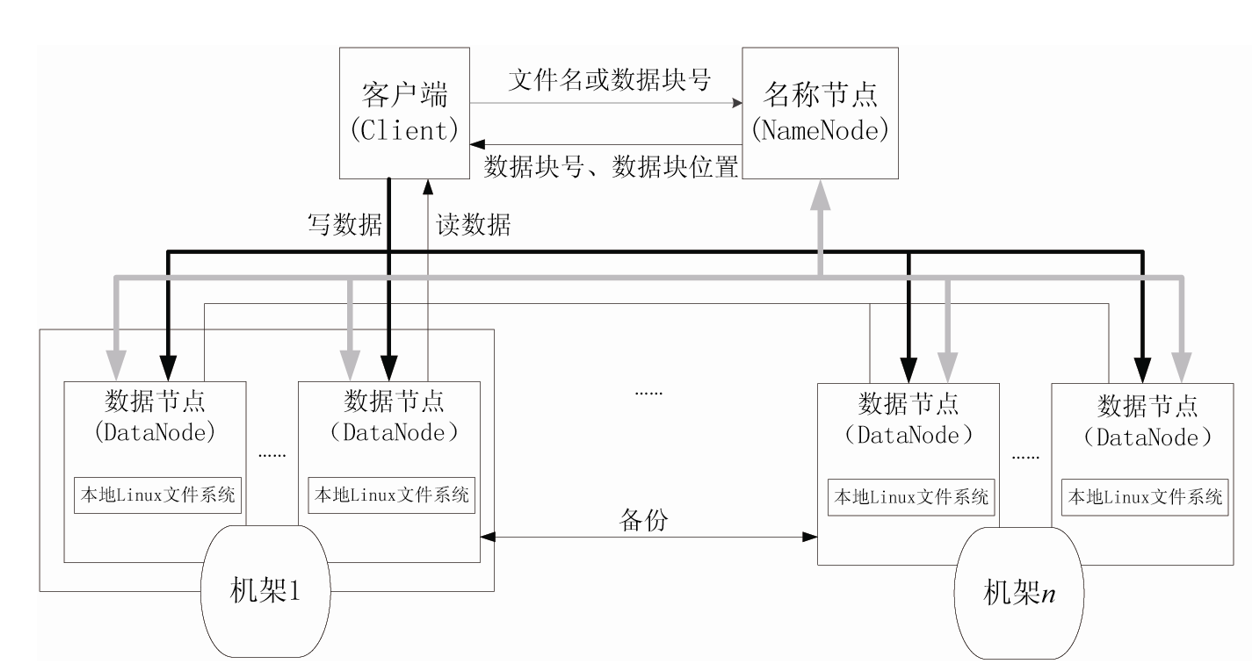
安装
Hadoop包括三种安装模式:
- 单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
- 伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
- 分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
这里介绍Hadoop伪分布式模式的安装方法。
3. Hadoop的安装
4. HDFS的基本使用方法
1>使用WEB管理页面操作HDFS
首先启动Hadoop,然后可以在浏览器中输入“http://localhost:9870”,就可以访问Hadoop的WEB管理页面
在WEB管理页面中,点击顶部右侧的菜单选项“Utilities”,在弹出的子菜单中点击“Browse the file system”,会出现HDFS文件系统操作页面,在这个页面中可以创建、查看、删除目录和文件。
2>使用命令操作HDFS
除了在浏览器中通过WEB方式操作HDFS以外,还可以在cmd窗口中使用命令对HDFS进行操作。
首先,创建一个名称为“user”的目录,命令如下:
cd c:\hadoop-3.1.3\bin
hadoop fs -mkdir hdfs://localhost:9000/user/
hadoop fs -mkdir hdfs://localhost:9000/user/xiaoming
然后,在“C:\”下创建一个文件test.txt,里面输入一行语句“I love hadoop”,使用如下命令把该文件上传到HDFS中:
hadoop fs -put C:\test.txt hdfs://localhost:9000/user/xiaoming
使用如下命令查看HDFS中的目录和文件:
hadoop fs -ls hdfs://localhost:9000/user/xiaoming
使用如下命令把HDFS中的文件内容显示到本地屏幕上:
hadoop fs -cat hdfs://localhost:9000/user/xiaoming/test.txt
把上面的HDFS中的文件test.txt下载到本地文件系统,并重命名为test1.txt:
hadoop fs -get hdfs://localhost:9000/user/xiaoming/test.txt C:\test1.txt
使用如下命令删除HDFS中的一个文件:
hadoop fs -rm hdfs://localhost:9000/user/xiaoming/test.txt
使用如下命令删除HDFS中的一个目录及其下面的文件:
hadoop fs -rm -r hdfs://localhost:9000/user/xiaoming
原文地址:https://blog.csdn.net/qq_73340809/article/details/142423650
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!