不宽的宽字符
根据提示,通过nc 202.38.93.141 14202来进行连接,可以用自己的机器进行连接,也可以直接点击“打开/下载题目”连接:
![]()



意料之中的无法打开flag,看来得下载附件看看源码了

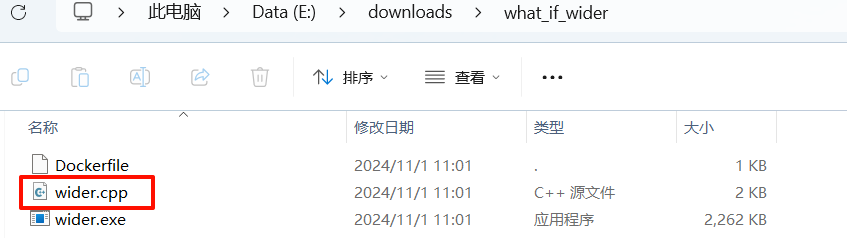
#include <iostream>
#include <fstream>
#include <cctype>
#include <string>
#include <windows.h>
int main()
{
std::wcout << L"Enter filename. I'll append 'you_cant_get_the_flag' to it:" << std::endl;
// Get the console input and output handles
HANDLE hConsoleInput = GetStdHandle(STD_INPUT_HANDLE);
HANDLE hConsoleOutput = GetStdHandle(STD_OUTPUT_HANDLE);
if (hConsoleInput == INVALID_HANDLE_VALUE || hConsoleOutput == INVALID_HANDLE_VALUE)
{
// Handle error – we can't get input/output handles.
return 1;
}
DWORD mode;
GetConsoleMode(hConsoleInput, &mode);
SetConsoleMode(hConsoleInput, mode | ENABLE_PROCESSED_INPUT);
// Buffer to store the wide character input
char inputBuffer[256] = { 0 };
DWORD charsRead = 0;
// Read the console input (wide characters)
if (!ReadFile(hConsoleInput, inputBuffer, sizeof(inputBuffer), &charsRead, nullptr))
{
// Handle read error
return 2;
}
// Remove the newline character at the end of the input
if (charsRead > 0 && inputBuffer[charsRead - 1] == L'\n')
{
inputBuffer[charsRead - 1] = L'\0'; // Null-terminate the string
charsRead--;
}
// Convert to WIDE chars
wchar_t buf[256] = { 0 };
MultiByteToWideChar(CP_UTF8, 0, inputBuffer, -1, buf, sizeof(buf) / sizeof(wchar_t));
std::wstring filename = buf;
// Haha!
filename += L"you_cant_get_the_flag";
std::wifstream file;
file.open((char*)filename.c_str());
if (file.is_open() == false)
{
std::wcout << L"Failed to open the file!" << std::endl;
return 3;
}
std::wstring flag;
std::getline(file, flag);
std::wcout << L"The flag is: " << flag << L". Congratulations!" << std::endl;
return 0;
}看得不是很懂,丢给ai分析一下
1. 控制台输出初始化

这行代码输出提示信息,要求用户输入一个文件名。
2. 获取控制台句柄
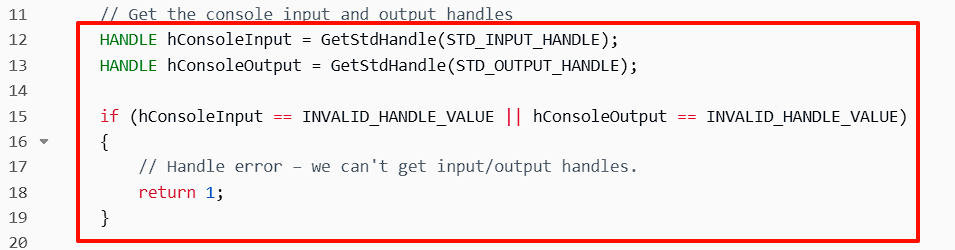
这里获取了标准输入和标准输出的句柄。如果获取失败,程序会返回错误码1。
3. 设置控制台模式

这行代码设置了控制台输入模式,启用了ENABLE_PROCESSED_INPUT标志,以便处理特殊字符(如回车、退格等)。
4. 读取用户输入
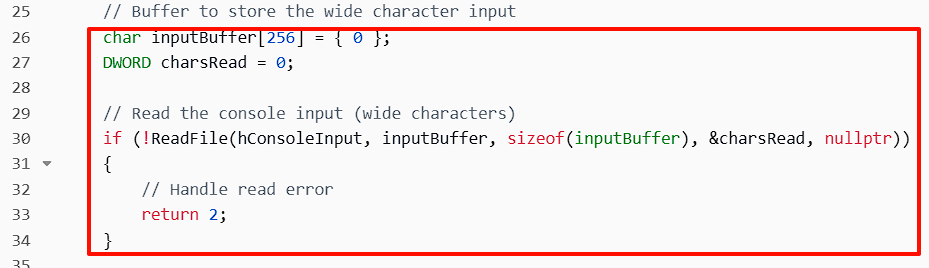
这里使用ReadFile函数从控制台读取用户的输入。如果读取失败,程序会返回错误码2。
5. 处理输入字符串

这行代码检查输入的最后一个字符是否是换行符\n,如果是,则将其替换为字符串终止符\0,并减少字符计数。
6. 转换为宽字符

这里将多字节字符转换为宽字符(wchar_t),使用的是UTF-8编码。
7. 构建文件名
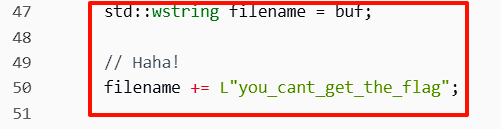
将用户输入的文件名与固定字符串"you_cant_get_the_flag"拼接起来,形成最终的文件名。
8. 打开文件

这里尝试以宽字符形式打开文件。
9. 检查文件是否打开成功
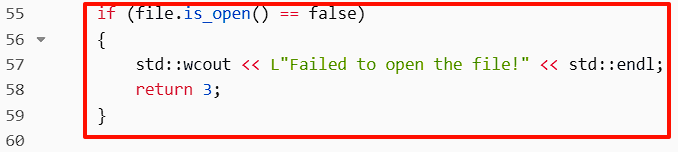
如果文件打开失败,程序会输出错误信息并返回错误码3。
10. 读取文件内容

从文件中读取第一行内容到变量flag中。
11. 输出结果

输出读取到的“flag”内容。
12. 返回0

程序正常结束,返回0。
其中,关键代码在这:

首先将输入的字符数组(char *)转变成宽字符数组(wchar_t *),导入宽字符串后又将其转换成了字符数组(char *)。
这整个过程会将输入的每一个字符(1个byte)先扩展成一个宽字符(2个byte),如果输入的是ascii码,扩展之后会在新增的1个高位byte上补 0x00. 由于大部分机型是小端存储,所以 1byte 低地址存储的应该是低位,即ascii码,高位的 1byte 存储的是 0x00。所以从宽字符串转到普通字符串时,ascii码不变,但每个ascii码后面多了个 0x00,而这又是字符串终止符 ‘\0’ 的ascii码,所以导致如果输入的字符串有ascii码,那么打印输出的字符串只能显示第一个ascii码,后面的都因终止符而不能显示。但如果输入不是ascii码,而是其他的unicode,则可以避免这种情况。中文是一种unicode,它在普通字符数组里存储是占两个字节的,而且是一体的,不会在扩展为宽字符数组时被分成两个1byte并补0x00。利用这个特性,我们就可以将目标输出 Z:\theflag 以两个byte为一组的形式转变为其他unicode。
需要将字符串Z:\theflag转成16进制ascii码:
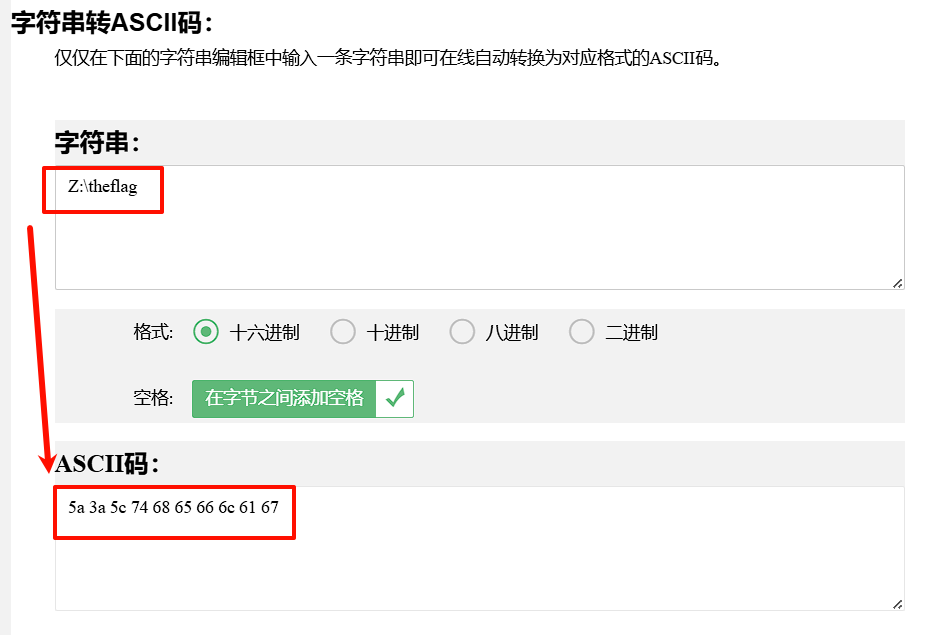
得到结果如下:
0x5a 0x3a 0x5c 0x74 0x68 0x65 0x66 0x6c 0x61 0x67
再由小端存储的规则,将转换结果变成(将每两位调换位置,为了使每个2 byte都遵循小端存储)
0x3a 0x5a 0x74 0x5c 0x65 0x68 0x6c 0x66 0x67 0x61
将每两位作为一组,变为\u3a5a \u745c \u6568 \u6c66 \u6761
此时再去unicode转中文:
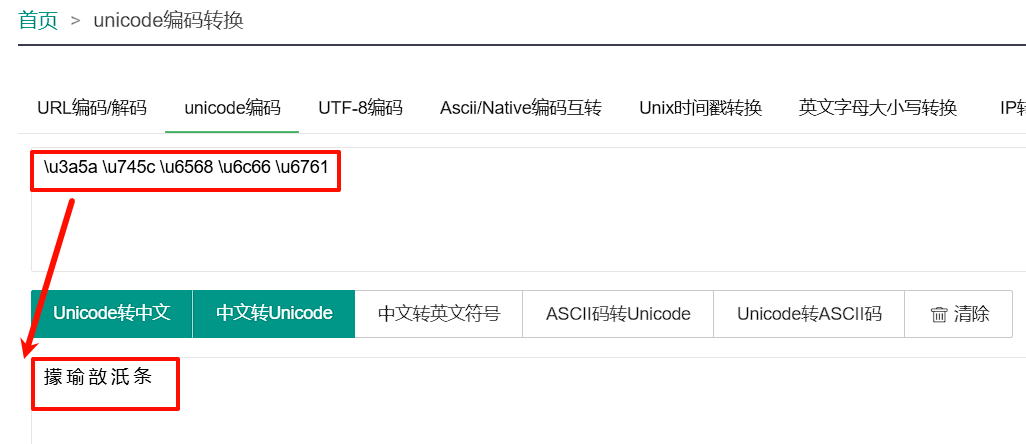
得到结果:
㩚 瑜 敨 汦 条
还要注意一点,因为filename后面被加上了一串ascii字符串,所以我们要截断后面的字符串,如果不把后面截断,就会在filename里多出现一个”f”字符。
所以要在后面加一个\uxx00(xx是两个十六进制数,而且要求选的xx要使得\uxx00是可见字符)
这里选择的加的后缀是\u9a00
\u3a5a \u745c \u6568 \u6c66 \u6761 \u9a00
进行unicode转中文:
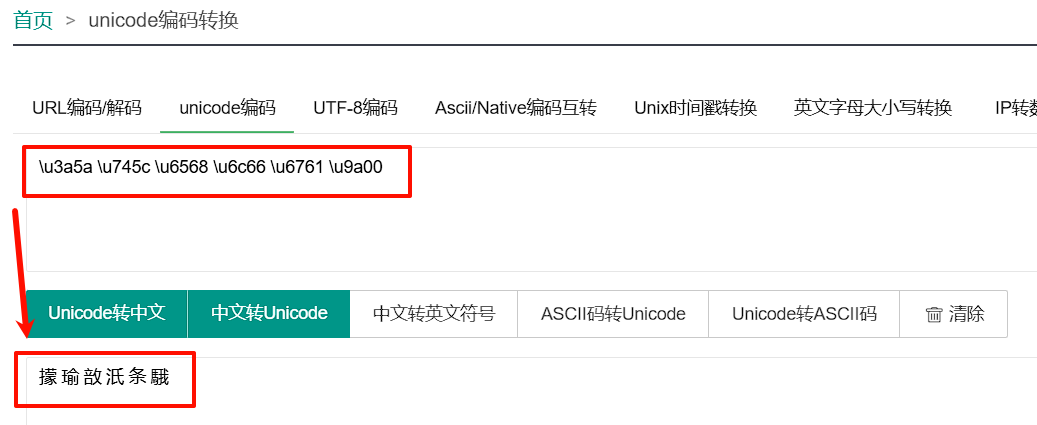
得到结果:
㩚 瑜 敨 汦 条 騀
去掉空格:
㩚瑜敨汦条騀

成功得到flag
原文地址:https://blog.csdn.net/weixin_73049307/article/details/143782054
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!