Mybatis源码分析
先附上mybatis源码,下载解压即可
📎mybatis-3.5.16.zip
ORM框架的发展历程
在进行源码分析之前,先来了解一下ORM框架的发展历程,懒得打字,我直接画了张图

JDBC
先来讲讲JDBC的操作,最初的时候我们肯定是直接通过jdbc来直接操作数据库的,本地数据库我们有一张t_user表,那么我们的操作流程是:
// 注册 JDBC 驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 打开连接
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatisdb?characterEncoding=utf-8&serverTimezone=UTC", "root", "123456");
// 执行查询
stmt = conn.createStatement();
String sql = "SELECT id,user_name,real_name,password,age,d_id from t_user where id = 1";
ResultSet rs = stmt.executeQuery(sql);
// 获取结果集
while (rs.next()) {
Integer id = rs.getInt("id");
String userName = rs.getString("user_name");
String realName = rs.getString("real_name");
String password = rs.getString("password");
Integer did = rs.getInt("d_id");
user.setId(id);
user.setUserName(userName);
user.setRealName(realName);
user.setPassword(password);
user.setDId(did);
System.out.println(user);
}具体的操作步骤是,首先在pom.xml中引入MySQL的驱动依赖,注意MySQL数据库的版本
1. Class.forName注册驱动
2. 获取一个Connection对象
3. 创建一个Statement对象
4. execute()方法执行SQL语句,获取ResultSet结果集
5. 通过ResultSet结果集给POJO的属性赋值
6. 最后关闭相关的资源
这种实现方式首先给我们的感觉就是操作步骤比较繁琐,在复杂的业务场景中会更麻烦。尤其是我们需要自己来维护管理资源的连接,如果忘记了,就很可能造成数据库服务连接耗尽。同时我们还能看到具体业务的SQL语句直接在代码中写死耦合性增强。每个连接都会经历这几个步骤,重复代码很多,总结上面的操作的特点:
1. 代码重复
2. 资源管理
3. 结果集处理
4. SQL耦合
针对这些问题我们可以自己尝试解决下
JDBC优化1.0
针对常规jdbc操作的特点,我们可以先从代码重复和资源管理方面来优化,我们可以创建一个工具类来专门处理这个问题,对应的jdbc操作代码如下:
/**
*
* 通过JDBC查询用户信息
*/
public void queryUser(){
Connection conn = null;
Statement stmt = null;
User user = new User();
ResultSet rs = null;
try {
// 注册 JDBC 驱动
// Class.forName("com.mysql.cj.jdbc.Driver");
// 打开连接
conn = DBUtils.getConnection();
// 执行查询
stmt = conn.createStatement();
String sql = "SELECT id,user_name,real_name,password,age,d_id from t_user where id = 1";
rs = stmt.executeQuery(sql);
// 获取结果集
while (rs.next()) {
Integer id = rs.getInt("id");
String userName = rs.getString("user_name");
String realName = rs.getString("real_name");
String password = rs.getString("password");
Integer did = rs.getInt("d_id");
user.setId(id);
user.setUserName(userName);
user.setRealName(realName);
user.setPassword(password);
user.setDId(did);
System.out.println(user);
}
} catch (SQLException se) {
se.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
DBUtils.close(conn,stmt,rs);
}
}
/**
* 通过JDBC实现添加用户信息的操作
*/
public void addUser(){
Connection conn = null;
Statement stmt = null;
try {
// 打开连接
conn = DBUtils.getConnection();
// 执行查询
stmt = conn.createStatement();
String sql = "INSERT INTO T_USER(user_name,real_name,password,age,d_id)values('wangwu','王五','111',22,1001)";
int i = stmt.executeUpdate(sql);
System.out.println("影响的行数:" + i);
} catch (SQLException se) {
se.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
DBUtils.close(conn,stmt);
}
}但是整体的操作步骤还是会显得比较复杂,这时我们可以进一步优化
JDBC优化2.0
我们可以针对DML操作的方法来优化,先解决SQL耦合的问题,在DBUtils中封装DML操作的方法
/**
* 通过JDBC实现添加用户信息的操作
*/
public void addUser(){
String sql = "INSERT INTO T_USER(user_name,real_name,password,age,d_id)values(?,?,?,?,?)";
try {
DBUtils.update(sql,"wangwu","王五","111",22,1001);
} catch (Exception e) {
e.printStackTrace();
}
}显然这种方式会比最初的使用要简化很多,但是在查询处理的时候我们还是没有解决ResultSet结果集的处理问题,所以我们还需要继续优化
JDBC优化3.0
针对ResultSet的优化我们需要从反射和元数据两方面入手,具体如下
/**
* 查询方法的简易封装
* @param sql
* @param clazz
* @param parameter
* @param <T>
* @return
* @throws Exception
*/
public static <T> List<T> query(String sql, Class clazz, Object ... parameter) throws Exception{
conn = getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
if(parameter != null && parameter.length > 0){
for (int i = 0; i < parameter.length; i++) {
ps.setObject(i+1,parameter[i]);
}
}
ResultSet rs = ps.executeQuery();
// 获取对应的表结构的元数据
ResultSetMetaData metaData = ps.getMetaData();
List<T> list = new ArrayList<>();
while(rs.next()){
// 根据 字段名称获取对应的值 然后将数据要封装到对应的对象中
int columnCount = metaData.getColumnCount();
Object o = clazz.newInstance();
for (int i = 1; i < columnCount+1; i++) {
// 根据每列的名称获取对应的值
String columnName = metaData.getColumnName(i);
Object columnValue = rs.getObject(columnName);
setFieldValueForColumn(o,columnName,columnValue);
}
list.add((T) o);
}
return list;
}
/**
* 根据字段名称设置 对象的属性
* @param o
* @param columnName
*/
private static void setFieldValueForColumn(Object o, String columnName,Object columnValue) {
Class<?> clazz = o.getClass();
try {
// 根据字段获取属性
Field field = clazz.getDeclaredField(columnName);
// 私有属性放开权限
field.setAccessible(true);
field.set(o,columnValue);
field.setAccessible(false);
}catch (Exception e){
// 说明不存在 那就将 _ 转换为 驼峰命名法
if(columnName.contains("_")){
Pattern linePattern = Pattern.compile("_(\\w)");
columnName = columnName.toLowerCase();
Matcher matcher = linePattern.matcher(columnName);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(sb, matcher.group(1).toUpperCase());
}
matcher.appendTail(sb);
// 再次调用复制操作
setFieldValueForColumn(o,sb.toString(),columnValue);
}
}
}封装了以上方法后我们的查询操作就可以简化为:
/**
*
* 通过JDBC查询用户信息
*/
public void queryUser(){
try {
String sql = "SELECT id,user_name,real_name,password,age,d_id from t_user where id = ?";
List<User> list = DBUtils.query(sql, User.class,2);
System.out.println(list);
} catch (Exception e) {
e.printStackTrace();
}这样一来我们在操作数据库中数据的时候就只需要关注于核心的SQL操作了。当然以上的设计还比较粗糙,这时Apache 下的 DbUtils是一个很好的选择
DbUtils
官网地址:DbUtils – JDBC Utility Component
DButils中提供了一个QueryRunner类,它对数据库的增删改查的方法进行了封装,获取QueryRunner的方式
private static final String PROPERTY_PATH = "druid.properties";
private static DruidDataSource dataSource;
private static QueryRunner queryRunner;
public static void init() {
Properties properties = new Properties();
InputStream in = DBUtils.class.getClassLoader().getResourceAsStream(PROPERTY_PATH);
try {
properties.load(in);
} catch (IOException e) {
e.printStackTrace();
}
dataSource = new DruidDataSource();
dataSource.configFromPropety(properties);
// 使用数据源初始化 QueryRunner
queryRunner = new QueryRunner(dataSource);
}创建QueryRunner对象的时候我们需要传递一个DataSource对象,这时我们可以选择Druid或者Hikai等常用的连接池工具,我这儿用的是Druid。
properties
druid.username=root
druid.password=123456
druid.url=jdbc:mysql://localhost:3306/mybatisdb?characterEncoding=utf-8&serverTimezone=UTC
druid.minIdle=10
druid.maxActive=30QueryRunner中提供的方法解决了重复代码的问题,传入数据源解决了资源管理的问题。而对于ResultSet结果集的处理则是通过 ResultSetHandler 来处理。我们可以自己来实现该接口
/**
* 查询所有的用户信息
* @throws Exception
*/
public void queryUser() throws Exception{
DruidUtils.init();
QueryRunner queryRunner = DruidUtils.getQueryRunner();
String sql = "select * from t_user";
List<User> list = queryRunner.query(sql, new ResultSetHandler<List<User>>() {
@Override
public List<User> handle(ResultSet rs) throws SQLException {
List<User> list = new ArrayList<>();
while(rs.next()){
User user = new User();
user.setId(rs.getInt("id"));
user.setUserName(rs.getString("user_name"));
user.setRealName(rs.getString("real_name"));
user.setPassword(rs.getString("password"));
list.add(user);
}
return list;
}
});
for (User user : list) {
System.out.println(user);
}
}或者用DBUtils中提供的默认的相关实现来解决
/**
* 通过ResultHandle的实现类处理查询
*/
public void queryUserUseBeanListHandle() throws Exception{
DruidUtils.init();
QueryRunner queryRunner = DruidUtils.getQueryRunner();
String sql = "select * from t_user";
// 不会自动帮助我们实现驼峰命名的转换
List<User> list = queryRunner.query(sql, new BeanListHandler<User>(User.class));
for (User user : list) {
System.out.println(user);
}
}通过Apache 封装的DBUtils是能够很方便的帮助我们实现相对比较简单的数据库操作
SpringJDBC
在Spring框架平台下,也提供的有JDBC的封装操作,在Spring中提供了一个模板方法 JdbcTemplate,里面封装了各种各样的 execute,query和update方法。
JdbcTemplate这个类是JDBC的核心包的中心类,简化了JDBC的操作,可以避免常见的异常,它封装了JDBC的核心流程,应用只要提供SQL语句,提取结果集就可以了,它是线程安全的。
在SpringJdbcTemplate的使用中,我们依然要配置对应的数据源,然后将JdbcTemplate对象注入到IoC容器中。
@Configuration
@ComponentScan
public class SpringConfig {
@Bean
public DataSource dataSource(){
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUsername("root");
dataSource.setPassword("123456");
dataSource.setUrl("jdbc:mysql://localhost:3306/mybatisdb?characterEncoding=utf-8&serverTimezone=UTC");
return dataSource;
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource){
JdbcTemplate template = new JdbcTemplate();
template.setDataSource(dataSource);
return template;
}
}在我们具体操作数据库中数据的时候,我们只需要从容器中获取JdbcTemplate实例即可
@Repository
public class UserDao {
@Autowired
private JdbcTemplate template;
public void addUser(){
int count = template.update("insert into t_user(user_name,real_name)values(?,?)","liaolong","廖龙");
System.out.println("count = " + count);
}
public void query1(){
String sql = "select * from t_user";
List<User> list = template.query(sql, new RowMapper<User>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setUserName(rs.getString("user_name"));
user.setRealName(rs.getString("real_name"));
return user;
}
});
for (User user : list) {
System.out.println(user);
}
}
public void query2(){
String sql = "select * from t_user";
List<User> list = template.query(sql, new BeanPropertyRowMapper<>(User.class));
for (User user : list) {
System.out.println(user);
}
}
}Hibernate
Apache DBUtils和SpringJdbcTemplate虽然简化了数据库的操作,但是本身提供的功能还是比较简单的(缺少缓存,事务管理等),所以我们在实际开发中往往并没有直接使用上述技术,而是用到了Hibernate和MyBatis等这些专业的ORM持久层框架。
什么是ORM?
O就是对象,M就是映射,R就是关系型数据库。
所以ORM( Object Relational Mapping) ,也就是对象与关系的映射,对象是程序里面的对象,关系是它与数据库里面的数据的关系,也就是说,ORM框架帮助我们解决的问题是程序对象和关系型数据库的相互映射的问题

Hibernate是一个很流行的ORM框架,2001年的时候就出了第一个版本。使用步骤如下:
创建一个Maven项目并添加相关的依赖即可,我们在此处直接通过 SpringDataJpa的依赖处理
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.11</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>在使用Hibernate的使用,我们需要为实体类创建一些hbm的xml映射文件
<hibernate-mapping>
<class name="com.liaolong.model.User" table="t_user">
<id name="id" />
<property name="userName" column="user_name"></property>
<property name="realName" column="real_name"></property>
</class>
</hibernate-mapping>以及Hibernate的配置文件
<hibernate-configuration>
<session-factory>
<property name="hibernate.connection.driver_class">
com.mysql.cj.jdbc.Driver
</property>
<property name="hibernate.connection.url">
jdbc:mysql://localhost:3306/mybatisdb?characterEncoding=utf8&serverTimezone=UTC
</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">123456</property>
<property name="hibernate.dialect">
org.hibernate.dialect.MySQLDialect
</property>
<property name="hibernate.show_sql">true</property>
<property name="hibernate.format_sql">true</property>
<property name="hibernate.hbm2ddl.auto">update</property>
<mapping resource="User.hbm.xml"/>
</session-factory>
</hibernate-configuration>然后在程序中我们可以通过Hibernate提供的 Session对象来实现CRUD操作
public class HibernateTest {
/**
* Hibernate操作案例演示
* @param args
*/
public static void main(String[] args) {
Configuration configuration = new Configuration();
// 默认使用hibernate.cfg.xml
configuration.configure();
// 创建Session工厂
SessionFactory factory = configuration.buildSessionFactory();
// 创建Session
Session session = factory.openSession();
// 获取事务对象
Transaction transaction = session.getTransaction();
// 开启事务
transaction.begin();
// 把对象添加到数据库中
User user = new User();
user.setId(666);
user.setUserName("hibernate");
user.setRealName("持久层框架");
session.save(user);
transaction.commit();
session.close();
}
}在映射文件的位置,我们也可以通过注解的方式来替换掉映射文件
@Data
@Entity
@Table(name = "t_user")
public class User {
@Id
@Column(name = "id")
private Integer id;
@Column(name = "user_name")
private String userName;
@Column(name = "real_name")
private String realName;
@Column(name = "password")
private String password;
@Column(name = "age")
private Integer age;
@Column(name = "i_id")
private Integer dId;
}在Spring中给我们提供的JPA对持久层框架做了统一的封装,而且本质上就是基于HibernateJPA来实现的,所以我们在使用的时候也可以通过SpringDataJPA的API来操作
dao的接口只需要继承JpaRepository接口即可,和mybatisPlus很像
public interface IUserDao extends JpaRepository<User,Integer> {
}service层正常处理
import java.util.List;
@Service
public class UserServiceImpl implements IUserService {
@Autowired
private IUserDao dao;
@Override
public List<User> query() {
return dao.findAll();
}
@Override
public User save(User user) {
return dao.save(user);
}
}Hibernate的出现大大简化了我们的数据库操作,同时也能够更好的应对更加复杂的业务场景,Hibernate实现了对象和关系型数据的完全映射,操作对象就想操作数据库记录一样
但是Hibernate在处理复杂业务的时候同样也存在一些问题,比如API中的get(),update()和save()方法,操作的实际上是所有的字段,没有办法指定部分字段,换句话说就是不够灵活,还有自定生成SQL的方式,如果要基于SQL去做一些优化的话,也是非常困难的。而且不支持动态SQL,比如分表中的表名,条件,参数变化等,无法根据条件自动生成SQL
因此我们需要一个更为灵活的框架----mybatis
Mybatis
MyBatis 是一款非常出色的持久层框架,它能够让你自由地编写 SQL 语句、使用存储过程,并支持高级的数据映射功能。通过 MyBatis,你可以大大减少甚至完全避免直接处理繁琐的 JDBC 代码,比如设置参数值或获取查询结果等操作。无论是简单的 XML 文件还是 Java 注解,MyBatis 都能轻松地帮助你将基本数据类型、接口甚至是普通的 Java 对象(我们通常称它们为 POJOs)与数据库中的记录相互转换。相较于 Hibernate 这样的全自动 ORM 框架,MyBatis 提供了更多的灵活性,因为它并不自动生成所有的 SQL 语句;相反,它专注于解决如何更有效地实现对象与数据库表之间的映射问题。
另外,关于 MyBatis 的历史背景:它的前身叫做 iBatis,这个名字结合了 "internet" 和 "abatis"(意指障碍物),从 2001 年开始开发。到了 2004 年,这个项目被捐赠给了 Apache 软件基金会。直到 2010 年,为了更好地反映其发展方向及社区特色,iBatis 正式更名为 MyBatis。
在MyBatis里面,SQL和代码是分离的,所以会写SQL基本上就会用MyBatis,没有额外的学习成本。
具体使用步骤大家都会,我就不写了,直接总结一些八股文里没有的细节一点的问题吧
MyBatis的配置文件通常包括哪些重要的内容?
“在MyBatis的配置文件里,主要有数据库连接的信息,比如数据库的URL、用户名和密码,还有一些映射器的配置。这些都能帮助MyBatis知道怎么和数据库沟通。”
在使用SqlSession时,为什么需要在操作结束后关闭会话?
“关闭SqlSession就像是结束一通电话,释放资源很重要,不然会占用数据库连接,造成性能问题。就像我们用完水龙头要关掉,不然水会一直流。”
解释“namespace + id”在MyBatis中的含义和作用。
“‘namespace + id’其实就是用来定位SQL语句的,namespace是你的映射器文件的名字,而id是具体的SQL语句。这样能确保每个SQL都是唯一的,避免冲突。”
编程式调用MyBatis的优缺点是什么?
“优点是简单直接,不需要额外的接口或配置。缺点嘛,就是有些地方得硬编码,比如ID写死了,维护起来就麻烦,如果打错了只能等程序跑起来才能发现。”
在MyBatis中,如何处理结果集的映射?
“结果集映射就是把数据库的查询结果转成Java对象。可以用注解或者XML配置,甚至可以自定义映射方式,灵活性还是蛮高的。”
什么是Mapper接口?它在MyBatis中的作用是什么?
“Mapper接口是个契约,定义了你要调用的方法。MyBatis根据这个接口生成实现,帮你处理数据库操作,简化代码。”
请描述如何通过getMapper方法获取Mapper接口的实现。
“使用getMapper很简单,直接传入你的接口类,MyBatis就会返回这个接口的实现对象。这样你就能调用定义的方法了,特别方便。”
为什么建议在MyBatis中使用Mapper接口而不是直接编程式调用?
“使用Mapper接口能让代码更清晰,更容易维护。而且,如果你需要修改SQL,只要改映射文件,接口不变,使用起来会方便很多。”
在映射文件中,如何确保SQL标签的id与Mapper接口的方法一致?
“确保一致性的方法就是在写映射文件的时候,直接把接口方法的名字用作SQL的id。这样管理起来就省心多了,容易找到对应的SQL。”
你如何处理MyBatis中的动态SQL?请举例说明。
“动态SQL很灵活,比如我们根据用户输入的条件来生成查询,可以用<if>和<choose>标签来控制SQL的拼接。这样能避免拼接字符串出错。”
在什么情况下你会选择使用MyBatis而不是Hibernate?
“如果项目需要灵活的SQL,或者对性能要求很高,我会选择MyBatis。Hibernate虽然方便,但有时它的抽象层会导致性能损失。”
MyBatis的缓存管理机制是怎样的?
“MyBatis支持一级和二级缓存,一级缓存是SqlSession的生命周期内的缓存,二级缓存可以跨SqlSession使用。配置也比较简单,能有效减少数据库访问。”
这个有对应的八股文,我就不多说了
如何将MyBatis与Spring结合使用?
“通常我们会通过Spring的配置文件来集成MyBatis,配置数据源和SqlSessionFactory,然后在需要的地方用@Autowired注入Mapper接口,这样就能很方便地使用了。”
什么是MyBatis插件?它的主要功能是什么?
MyBatis插件是一个非常强大的机制,允许开发者在MyBatis的运行过程中扩展功能。它通过预留的接口,让我们能够在不修改MyBatis核心代码的情况下,增加自己的逻辑,比如性能监控、SQL拦截、日志记录等。换句话说,插件使得MyBatis更加灵活和可扩展,适应不同的开发需求。
MyBatis中的环境配置有什么作用?
environments标签的主要作用是管理不同的数据库环境,比如开发、测试和生产环境。在MyBatis中,你可以为每个环境配置不同的数据库地址和类型,方便在不同阶段使用合适的数据库。比如,我们可以在开发时使用本地数据库,而在生产环境中使用云数据库。
能否解释一下MyBatis的transactionManager和dataSource?
当然可以,transactionManager负责管理数据库事务,如果我们使用JDBC类型的transactionManager,它会直接调用Connection对象的方法来管理事务,比如commit和rollback。而dataSource则是数据库连接的抽象,提供了连接池管理的功能。简单来说,dataSource就是数据库的“水龙头”,而transactionManager则是水流的“开关”,负责控制水流的开与关。
MyBatis中mapper的作用是什么?
mapper在MyBatis中负责定义SQL语句和Java对象之间的映射关系。通过配置<mappers>标签,我们可以让MyBatis在启动时自动加载这些映射器。这样,我们就能以更简洁的方式执行SQL语句,而不必在Java代码中写大量的JDBC代码,提升了开发效率。
什么是resultMap,它有什么用?
resultMap是MyBatis中一个非常强大且复杂的元素,它用来定义如何将数据库结果集中的数据映射到Java对象中。通过resultMap,我们可以精确控制每一列数据如何对应到对象的属性上,这样可以避免一些类型转换的问题,并且能够提高代码的可读性和可维护性。
请解释一下MyBatis的SQL映射文件中的主要元素。
SQL映射文件是MyBatis的核心,里面包含一些重要的顶级元素。比如:
cache:配置缓存设置;resultMap:定义如何将结果集映射到对象;insert、update、delete和select:分别用于处理增删改查操作; 这些元素帮助我们将SQL语句与Java对象进行高效的映射和操作,从而简化了开发过程。
MybatisPlus
MyBatis-Plus是原生MyBatis的一个增强工具,可以在使用原生MyBatis的所有功能的基础上,使用plus特有的功能。
MyBatis-Plus的核心功能:
通用 CRUD:定义好Mapper接口后,只需要继承BaseMapper<T> 接口即可获得通用的增删改查功能,无需编写任何接口方法与配置文件。
条件构造器:通过EntityWrapper<T>(实体包装类),可以用于拼接 SQL 语句,并且支持排序、分组查询等复杂的SQL。
代码生成器:支持一系列的策略配置与全局配置,比MyBatis的代码生成更好用。
另外MyBatis-Plus也有分页的功能。
MyBatis源码分析
Mybatis的整体框架分为三层,分别是基础支持层、核心处理层、和接口层。如下图

接口层是用来对外的,就是我们的客户端要通过mybatis做一些数据库的操作,那他们所面对的都是sqlsession接口,也就是我们程序员每天敲完代码都是通过sqlsession里面的API去实现我们对数据库相关的处理操作
接下来说说核心处理层,比如,用户要添加一个用户add,要查询一个用户get,那么本质上都是要执行insert、select语句,这些操作其实就是通过核心处理层实现的
基础支持层就是就是功能单一,可复用的模块,比如说反射模块,我们首先通过核心处理层查出一个结果集,要把这个结果集封装到java对象里面去,那么java对象的创建,还有对象属性的赋值,那么这些操作其实都是我们所说的反射。类型转换模块就是,比如java类型还有jdbc类型之间如何去转换。日志模块就是记录日志。资源加载模块就是比如我们有全局配置文件,有映射文件,就是通过资源加载模块加载到内存里面去的。解析器模块就是专门去解析一些表达式之类的。binding模块就可以看作是一个mapper。缓存模块就是一级缓存、二级缓存这些内容。
下面我画了一张工作流程图:

/**
* MyBatis getMapper 方法的使用
*/
@Test
public void test2() throws Exception{
// 1.获取配置文件
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
// 2.加载解析配置文件并获取SqlSessionFactory对象
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
// 3.根据SqlSessionFactory对象获取SqlSession对象
SqlSession sqlSession = factory.openSession();
// 4.通过SqlSession中提供的 API方法来操作数据库
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> list = mapper.selectUserList();
for (User user : list) {
System.out.println(user);
}
// 5.关闭会话
sqlSession.close();
}上面通过一个比较复杂的步骤实现了MyBatis的数据库查询操作。下面我们会按照这5个步骤来分析MyBatis的运行原理。
根据上面代码,引伸出一个问题:“为什么sqlsessionFactory的实例没有通过defaultSessionFactory直接获取,而是通过一个Builder对象来建造的?”
原因是:
SQLSessionFactory 的实例之所以不直接通过 defaultSessionFactory 获取,而是通过 Builder 对象来构建,主要是为了更灵活地配置和创建实例。使用 Builder 模式,可以在创建 SQLSessionFactory 的过程中,逐步设置各种参数,比如数据源、事务管理器等。这样一来,就能在创建过程中有更多的控制和定制,确保最终的实例符合你的具体需求,而不是只能使用一个固定的默认配置。
不信的话,我们可以进到build方法中验证一下


这里面调用了重载方法,传入了字节输入流,后面的环境和属性都为null,现在我们再进入到返回到这个build方法:

这段代码虽然有点复杂,但我们先不关注细节,直接看看整体逻辑。首先,parser 在这里是用来加载和解析配置的。接着,build 方法实际上会调用下面的一个 build 方法。
在这个 build 方法中,创建了一个 DefaultSqlSessionFactory 的实例,也就是工厂对象。这个对象会被返回,同时还会有一个 config 对象,它负责解析全局配置文件和映射文件。这些加载的信息都封装在这个 config 对象中。
通过这些代码,我们可以清楚地看到 Builder 在创建 SqlSessionFactory 时的结构。而 Configuration 对象则提前暴露,里面保存了配置映射文件的相关信息。后续如果需要查找配置,只需直接访问这个对象即可。
下面开始详细介绍
核心对象的生命周期
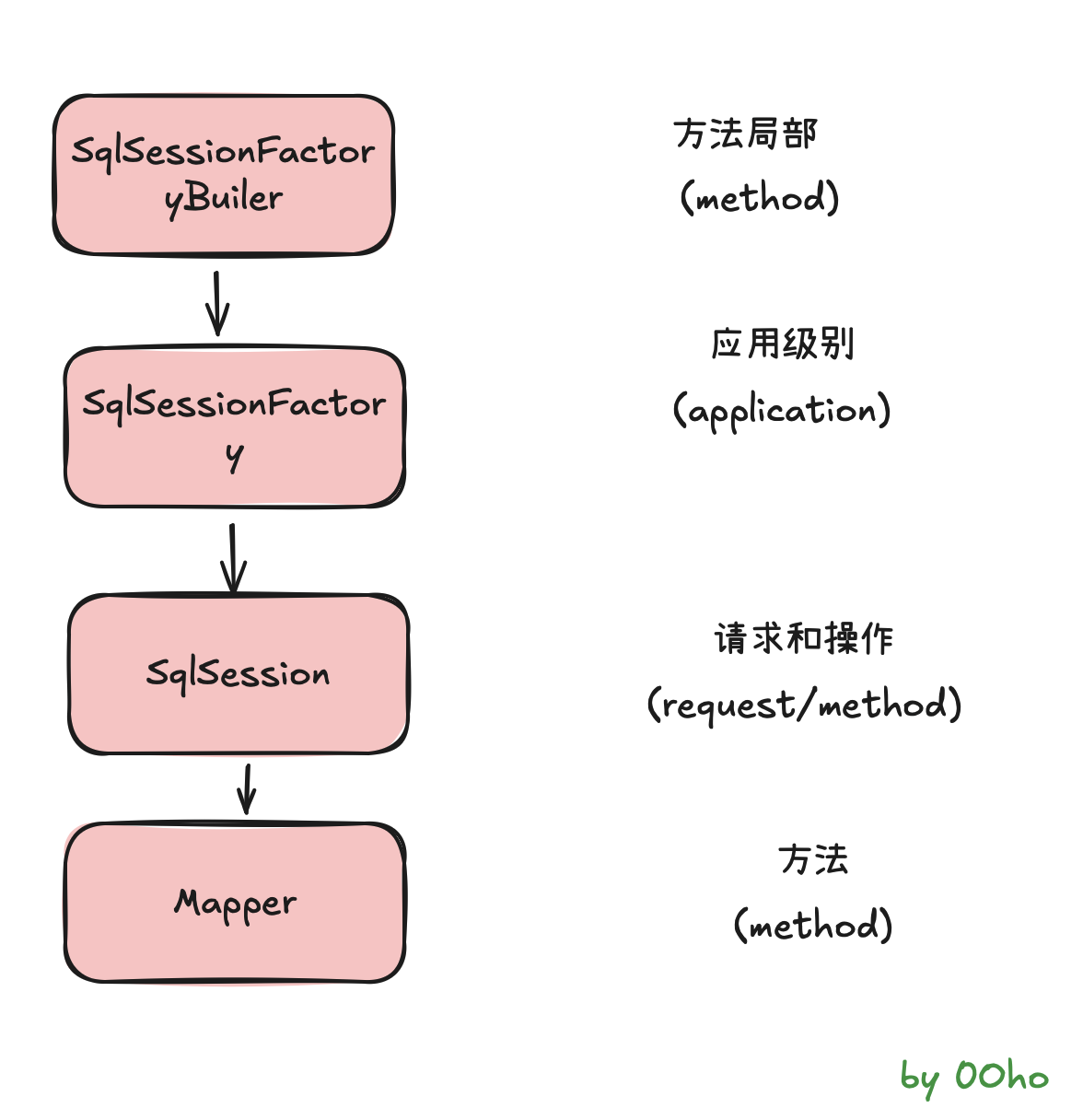
SqlSessionFactoryBuiler是什么?
首先是SqlSessionFactoryBuiler。它是用来构建SqlSessionFactory的,而SqlSessionFactory只需要一个,所以只要构建了这一个SqlSessionFactory,它的使命就完成了,也就没有存在的意义了。所以它的生命周期只存在于方法的局部。
SqlSessionFactory是什么?
SqlSessionFactory是用来创建SqlSession的,每次应用程序访问数据库,都需要创建一个会话。因为我们一直有创建会话的需要,所以SqlSessionFactory应该存在于应用的整个生命周期中(作用域是应用作用域)。创建SqlSession只需要一个实例来做这件事就行了,否则会产生很多的混乱,和浪费资源。所以我们要采用单例模式。
SqlSession是什么?
SqlSession是一个会话,因为它不是线程安全的,不能在线程间共享。所以我们在请求开始的时候创建一个SqlSession对象,在请求结束或者说方法执行完毕的时候要及时关闭它(一次请求或者操作中)。
Mapper是什么?
Mapper(实际上是一个代理对象)是从SqlSession中获取的。
UserMapper mapper = sqlSession.getMapper(UserMapper.class);它的作用是发送SQL来操作数据库的数据。它应该在一个SqlSession事务方法之内。
首先我们来看下SqlSessionFactory对象的获取
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);首先我们new了一个SqlSessionFactoryBuilder,这是建造者模式的运用(建造者模式用来创建复杂对象,而不需要关注内部细节,是一种封装的体现)。MyBatis中很多地方用到了建造者模式(名字以Builder结尾的类还有9个)。
SqlSessionFactoryBuilder中用来创建SqlSessionFactory对象的方法是build(),build()方法有9个重载,可以用不同的方式来创建SqlSessionFactory对象。SqlSessionFactory对象默认是单例的。
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
// 用于解析 mybatis-config.xml,同时创建了 Configuration 对象 >>
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// 解析XML,最终返回一个 DefaultSqlSessionFactory >>
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}在build方法中首先是创建了一个XMLConfigBuilder对象,XMLConfigBuilder是抽象类BaseBuilder的一个子类,专门用来解析全局配置文件,针对不同的构建目标还有其他的一些子类(关联到源码路径),比如:
XMLMapperBuilder:解析Mapper映射器
XMLStatementBuilder:解析增删改查标签
XMLScriptBuilder:解析动态SQL
然后是执行了:
build(parser.parse());构建的代码,parser.parse()方法返回的是一个Configuration对象,build方法的如下:
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
在这儿我们可以看到SessionFactory最终实现是DefaultSqlSessionFactory对象。
然后我们再来看下XMLConfigBuilder初始化的时候做了哪些操作
public XMLConfigBuilder(InputStream inputStream, String environment, Properties props) {
// EntityResolver的实现类是XMLMapperEntityResolver 来完成配置文件的校验,根据对应的DTD文件来实现
this(new XPathParser(inputStream, true, props, new XMLMapperEntityResolver()), environment, props);
}再去进入重载的构造方法中
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
super(new Configuration()); // 完成了Configuration的初始化
ErrorContext.instance().resource("SQL Mapper Configuration");
this.configuration.setVariables(props); // 设置对应的Properties属性
this.parsed = false; // 设置 是否解析的标志为 false
this.environment = environment; // 初始化environment
this.parser = parser; // 初始化 解析器
}然后我们可以看下Configuration初始化做了什么操作
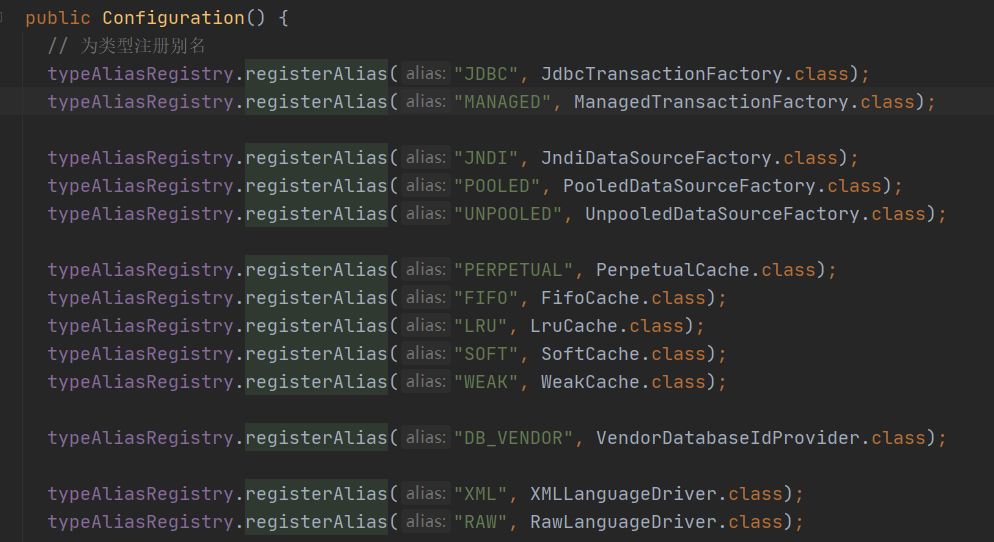
完成了类型别名的注册工作,通过上面的分析我们可以看到XMLConfigBuilder完成了XML文件的解析对应XPathParser和Configuration对象的初始化操作,然后我们再来看下parse方法到底是如何解析配置文件的
parser.parse(),进入具体的解析方法
public Configuration parse() {
// 检查是否已经解析过了
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// XPathParser,dom 和 SAX 都有用到 >> 开始解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}parseConfiguration方法:
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
// 对于全局配置文件各种标签的解析
propertiesElement(root.evalNode("properties"));
// 解析 settings 标签
Properties settings = settingsAsProperties(root.evalNode("settings"));
// 读取文件
loadCustomVfs(settings);
// 日志设置
loadCustomLogImpl(settings);
// 类型别名
typeAliasesElement(root.evalNode("typeAliases"));
// 插件
pluginElement(root.evalNode("plugins"));
// 用于创建对象
objectFactoryElement(root.evalNode("objectFactory"));
// 用于对对象进行加工
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 反射工具箱
reflectorFactoryElement(root.evalNode("reflectorFactory"));
// settings 子标签赋值,默认值就是在这里提供的 >>
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
// 创建了数据源 >>
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析引用的Mapper映射器
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}properties解析:
if (context != null) {
// 创建了一个 Properties 对象,后面可以用到
Properties defaults = context.getChildrenAsProperties();
String resource = context.getStringAttribute("resource");
String url = context.getStringAttribute("url");
if (resource != null && url != null) {
// url 和 resource 不能同时存在
throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");
}
// 加载resource或者url属性中指定的 properties 文件
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
Properties vars = configuration.getVariables();
if (vars != null) {
// 和 Configuration中的 variables 属性合并
defaults.putAll(vars);
}
// 更新对应的属性信息
parser.setVariables(defaults);
configuration.setVariables(defaults);
}
}第一个是解析\<properties>标签,读取我们引入的外部配置文件,例如db.properties。
这里面又有两种类型,一种是放在resource目录下的,是相对路径,一种是写的绝对路径的(url)。
解析的最终结果就是我们会把所有的配置信息放到名为defaults的Properties对象里面(Hashtable对象,KV存储),最后把XPathParser和Configuration的Properties属性都设置成我们填充后的Properties对象。
settings解析:
private Properties settingsAsProperties(XNode context) {
if (context == null) {
return new Properties();
}
// 获取settings节点下的所有的子节点
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory);
for (Object key : props.keySet()) {
//
if (!metaConfig.hasSetter(String.valueOf(key))) {
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
return props;
}
```
getChildrenAsProperties方法就是具体的解析了
```java
public Properties getChildrenAsProperties() {
Properties properties = new Properties();
for (XNode child : getChildren()) {
// 获取对应的name和value属性
String name = child.getStringAttribute("name");
String value = child.getStringAttribute("value");
if (name != null && value != null) {
properties.setProperty(name, value);
}
}
return properties;
}loadCustomVfs(settings)方法:
loadCustomVfs是获取Vitual File System的自定义实现类,比如要读取本地文件,或者FTP远程文件的时候,就可以用到自定义的VFS类。
根据\<settings>标签里面的\<vfsImpl>标签,生成了一个抽象类VFS的子类,在MyBatis中有JBoss6VFS和DefaultVFS两个实现,在io包中。
private void loadCustomVfs(Properties props) throws ClassNotFoundException {
String value = props.getProperty("vfsImpl");
if (value != null) {
String[] clazzes = value.split(",");
for (String clazz : clazzes) {
if (!clazz.isEmpty()) {
@SuppressWarnings("unchecked")
Class<? extends VFS> vfsImpl = (Class<? extends VFS>)Resources.classForName(clazz);
configuration.setVfsImpl(vfsImpl);
}
}
}
}最后赋值到Configuration中。
loadCustomLogImpl(settings)方法:
loadCustomLogImpl是根据\<logImpl>标签获取日志的实现类,我们可以用到很多的日志的方案,包括LOG4J,LOG4J2,SLF4J等等,在logging包中。
private void loadCustomLogImpl(Properties props) {
Class<? extends Log> logImpl = resolveClass(props.getProperty("logImpl"));
configuration.setLogImpl(logImpl);
}typeAliases解析:
这一步是类型别名的解析
private void typeAliasesElement(XNode parent) {
// 放入 TypeAliasRegistry
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String typeAliasPackage = child.getStringAttribute("name");
configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);
} else {
String alias = child.getStringAttribute("alias");
String type = child.getStringAttribute("type");
try {
Class<?> clazz = Resources.classForName(type);
if (alias == null) {
// 扫描 @Alias 注解使用
typeAliasRegistry.registerAlias(clazz);
} else {
// 直接注册
typeAliasRegistry.registerAlias(alias, clazz);
}
} catch (ClassNotFoundException e) {
throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);
}
}
}
}
}plugins:
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 获取<plugin> 节点的 interceptor 属性的值
String interceptor = child.getStringAttribute("interceptor");
// 获取<plugin> 下的所有的properties子节点
Properties properties = child.getChildrenAsProperties();
// 获取 Interceptor 对象
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
// 设置 interceptor的 属性
interceptorInstance.setProperties(properties);
// Configuration中记录 Interceptor
configuration.addInterceptor(interceptorInstance);
}
}
}objectFactory,objectWrapperFactory及reflectorFactory解析:
private void objectFactoryElement(XNode context) throws Exception {
if (context != null) {
// 获取<objectFactory> 节点的 type 属性
String type = context.getStringAttribute("type");
// 获取 <objectFactory> 节点下的配置信息
Properties properties = context.getChildrenAsProperties();
// 获取ObjectFactory 对象的对象 通过反射方式
ObjectFactory factory = (ObjectFactory) resolveClass(type).getDeclaredConstructor().newInstance();
// ObjectFactory 和 对应的属性信息关联
factory.setProperties(properties);
// 将创建的ObjectFactory对象绑定到Configuration中
configuration.setObjectFactory(factory);
}
}
private void objectWrapperFactoryElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type");
ObjectWrapperFactory factory = (ObjectWrapperFactory) resolveClass(type).getDeclaredConstructor().newInstance();
configuration.setObjectWrapperFactory(factory);
}
}
private void reflectorFactoryElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type");
ReflectorFactory factory = (ReflectorFactory) resolveClass(type).getDeclaredConstructor().newInstance();
configuration.setReflectorFactory(factory);
}
}ObjectFactory用来创建返回的对象。
ObjectWrapperFactory用来对对象做特殊的处理。比如:select没有写别名,查询返回的是一个Map,可以在自定义的objectWrapperFactory中把下划线命名变成驼峰命名。
ReflectorFactory是反射的工具箱,对反射的操作进行了封装(官网和文档没有这个对象的描述)。
以上四个对象,都是用resolveClass创建的。
settingsElement(settings)方法:
这里就是对\<settings>标签里面所有子标签的处理了,前面我们已经把子标签全部转换成了Properties对象,所以在这里处理Properties对象就可以了。
settings二级标签中一共26个配置,比如二级缓存、延迟加载、默认执行器类型等等。
需要注意的是,我们之前提到的所有的默认值,都是在这里赋值的。如果说后面我们不知道这个属性的值是什么,也可以到这一步来确认一下。
所有的值,都会赋值到Configuration的属性里面去。
private void settingsElement(Properties props) {
configuration.setAutoMappingBehavior(AutoMappingBehavior.valueOf(props.getProperty("autoMappingBehavior", "PARTIAL")));
configuration.setAutoMappingUnknownColumnBehavior(AutoMappingUnknownColumnBehavior.valueOf(props.getProperty("autoMappingUnknownColumnBehavior", "NONE")));
configuration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));
configuration.setProxyFactory((ProxyFactory) createInstance(props.getProperty("proxyFactory")));
configuration.setLazyLoadingEnabled(booleanValueOf(props.getProperty("lazyLoadingEnabled"), false));
configuration.setAggressiveLazyLoading(booleanValueOf(props.getProperty("aggressiveLazyLoading"), false));
configuration.setMultipleResultSetsEnabled(booleanValueOf(props.getProperty("multipleResultSetsEnabled"), true));
configuration.setUseColumnLabel(booleanValueOf(props.getProperty("useColumnLabel"), true));
configuration.setUseGeneratedKeys(booleanValueOf(props.getProperty("useGeneratedKeys"), false));
configuration.setDefaultExecutorType(ExecutorType.valueOf(props.getProperty("defaultExecutorType", "SIMPLE")));
configuration.setDefaultStatementTimeout(integerValueOf(props.getProperty("defaultStatementTimeout"), null));
configuration.setDefaultFetchSize(integerValueOf(props.getProperty("defaultFetchSize"), null));
configuration.setDefaultResultSetType(resolveResultSetType(props.getProperty("defaultResultSetType")));
configuration.setMapUnderscoreToCamelCase(booleanValueOf(props.getProperty("mapUnderscoreToCamelCase"), false));
configuration.setSafeRowBoundsEnabled(booleanValueOf(props.getProperty("safeRowBoundsEnabled"), false));
configuration.setLocalCacheScope(LocalCacheScope.valueOf(props.getProperty("localCacheScope", "SESSION")));
configuration.setJdbcTypeForNull(JdbcType.valueOf(props.getProperty("jdbcTypeForNull", "OTHER")));
configuration.setLazyLoadTriggerMethods(stringSetValueOf(props.getProperty("lazyLoadTriggerMethods"), "equals,clone,hashCode,toString"));
configuration.setSafeResultHandlerEnabled(booleanValueOf(props.getProperty("safeResultHandlerEnabled"), true));
configuration.setDefaultScriptingLanguage(resolveClass(props.getProperty("defaultScriptingLanguage")));
configuration.setDefaultEnumTypeHandler(resolveClass(props.getProperty("defaultEnumTypeHandler")));
configuration.setCallSettersOnNulls(booleanValueOf(props.getProperty("callSettersOnNulls"), false));
configuration.setUseActualParamName(booleanValueOf(props.getProperty("useActualParamName"), true));
configuration.setReturnInstanceForEmptyRow(booleanValueOf(props.getProperty("returnInstanceForEmptyRow"), false));
configuration.setLogPrefix(props.getProperty("logPrefix"));
configuration.setConfigurationFactory(resolveClass(props.getProperty("configurationFactory")));
}environments解析
这一步是解析\<environments>标签。
一个environment就是对应一个数据源,所以在这里我们会根据配置的\<transactionManager>创建一个事务工厂,根据\<dataSource>标签创建一个数据源,最后把这两个对象设置成Environment对象的属性,放到Configuration里面。
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
// 事务工厂
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 数据源工厂(例如 DruidDataSourceFactory )
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
// 数据源
DataSource dataSource = dsFactory.getDataSource();
// 包含了 事务工厂和数据源的 Environment
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
// 放入 Configuration
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}databaseIdProviderElement():
解析databaseIdProvider标签,生成DatabaseIdProvider对象(用来支持不同厂商的数据库)。
typeHandlerElement():
跟TypeAlias一样,TypeHandler有两种配置方式,一种是单独配置一个类,一种是指定一个package。最后我们得到的是JavaType和JdbcType,以及用来做相互映射的TypeHandler之间的映射关系,存放在TypeHandlerRegistry对象里面。
private void typeHandlerElement(XNode parent) {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String typeHandlerPackage = child.getStringAttribute("name");
typeHandlerRegistry.register(typeHandlerPackage);
} else {
String javaTypeName = child.getStringAttribute("javaType");
String jdbcTypeName = child.getStringAttribute("jdbcType");
String handlerTypeName = child.getStringAttribute("handler");
Class<?> javaTypeClass = resolveClass(javaTypeName);
JdbcType jdbcType = resolveJdbcType(jdbcTypeName);
Class<?> typeHandlerClass = resolveClass(handlerTypeName);
if (javaTypeClass != null) {
if (jdbcType == null) {
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);
} else {
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
}
} else {
typeHandlerRegistry.register(typeHandlerClass);
}
}
}
}
}
mapper解析
最后就是\<mappers>标签的解析。
根据全局配置文件中不同的注册方式,用不同的方式扫描,但最终都是做了两件事情,对于语句的注册和接口的注册。
| 扫描类型 | 含义 |
| resource | 相对路径 |
| url | 绝对路径 |
| package | 包 |
| class | 单个接口 |
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 不同的定义方式的扫描,最终都是调用 addMapper()方法(添加到 MapperRegistry)。这个方法和 getMapper() 对应
// package包
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// resource相对路径
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
// 解析 Mapper.xml,总体上做了两件事情 >>
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// url绝对路径
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// class 单个接口
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
然后开始进入具体的配置文件的解析操作
映射文件的解析
首先进入parse方法
public void parse() {
// 总体上做了两件事情,对于语句的注册和接口的注册
if (!configuration.isResourceLoaded(resource)) {
// 1、具体增删改查标签的解析。
// 一个标签一个MappedStatement。 >>
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
// 2、把namespace(接口类型)和工厂类绑定起来,放到一个map。
// 一个namespace 一个 MapperProxyFactory >>
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}configurationElement()——解析所有的子标签,最终获得MappedStatement对象。
bindMapperForNamespace()——把namespace(接口类型)和工厂类MapperProxyFactory绑定起来。
configurationElement方法
configurationElement是对Mapper.xml中所有具体的标签的解析,包括namespace、cache、parameterMap、resultMap、sql和select、insert、update、delete。
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// 添加缓存对象
cacheRefElement(context.evalNode("cache-ref"));
// 解析 cache 属性,添加缓存对象
cacheElement(context.evalNode("cache"));
// 创建 ParameterMapping 对象
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 创建 List<ResultMapping>
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析可以复用的SQL
sqlElement(context.evalNodes("/mapper/sql"));
// 解析增删改查标签,得到 MappedStatement >>
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}在buildStatementFromContext()方法中,创建了用来解析增删改查标签的XMLStatementBuilder,并且把创建的MappedStatement添加到mappedStatements中。
MappedStatement statement = statementBuilder.build();
// 最关键的一步,在 Configuration 添加了 MappedStatement >>
configuration.addMappedStatement(statement);
bindMapperForNamespace方法
private void bindMapperForNamespace() {
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
// 根据名称空间加载对应的接口类型
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
//ignore, bound type is not required
}
if (boundType != null) {
if (!configuration.hasMapper(boundType)) {
// Spring may not know the real resource name so we set a flag
// to prevent loading again this resource from the mapper interface
// look at MapperAnnotationBuilder#loadXmlResource
configuration.addLoadedResource("namespace:" + namespace);
// 添加到 MapperRegistry,本质是一个 map,里面也有 Configuration >>
configuration.addMapper(boundType);
}
}
}
}通过源码分析发现主要是是调用了addMapper()。addMapper()方法中,把接口类型注册到MapperRegistry中:实际上是为接口创建一个对应的MapperProxyFactory(用于为这个type提供工厂类,创建MapperProxy)。
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) { // 检测 type 是否为接口
if (hasMapper(type)) { // 检测是否已经加装过该接口
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// !Map<Class<?>, MapperProxyFactory<?>> 存放的是接口类型,和对应的工厂类的关系
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
// 注册了接口之后,根据接口,开始解析所有方法上的注解,例如 @Select >>
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}同样的再进入parse方法中查看
public void parse() {
String resource = type.toString();
if (!configuration.isResourceLoaded(resource)) {
// 先判断 Mapper.xml 有没有解析,没有的话先解析 Mapper.xml(例如定义 package 方式)
loadXmlResource();
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 处理 @CacheNamespace
parseCache();
// 处理 @CacheNamespaceRef
parseCacheRef();
// 获取所有方法
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
// 解析方法上的注解,添加到 MappedStatement 集合中 >>
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
如果大家感兴趣,可以继续进入到parseStatement方法中查看,我就不在去看了。
总结:
1. 我们主要完成了config配置文件、Mapper文件、Mapper接口中注解的解析。
2. 我们得到了一个最重要的对象Configuration,这里面存放了全部的配置信息,它在属性里面还有各种各样的容器。
3. 最后,返回了一个DefaultSqlSessionFactory,里面持有了Configuration的实例。
费尽九牛二虎之力,画了个时序图,如下:

SqlSession
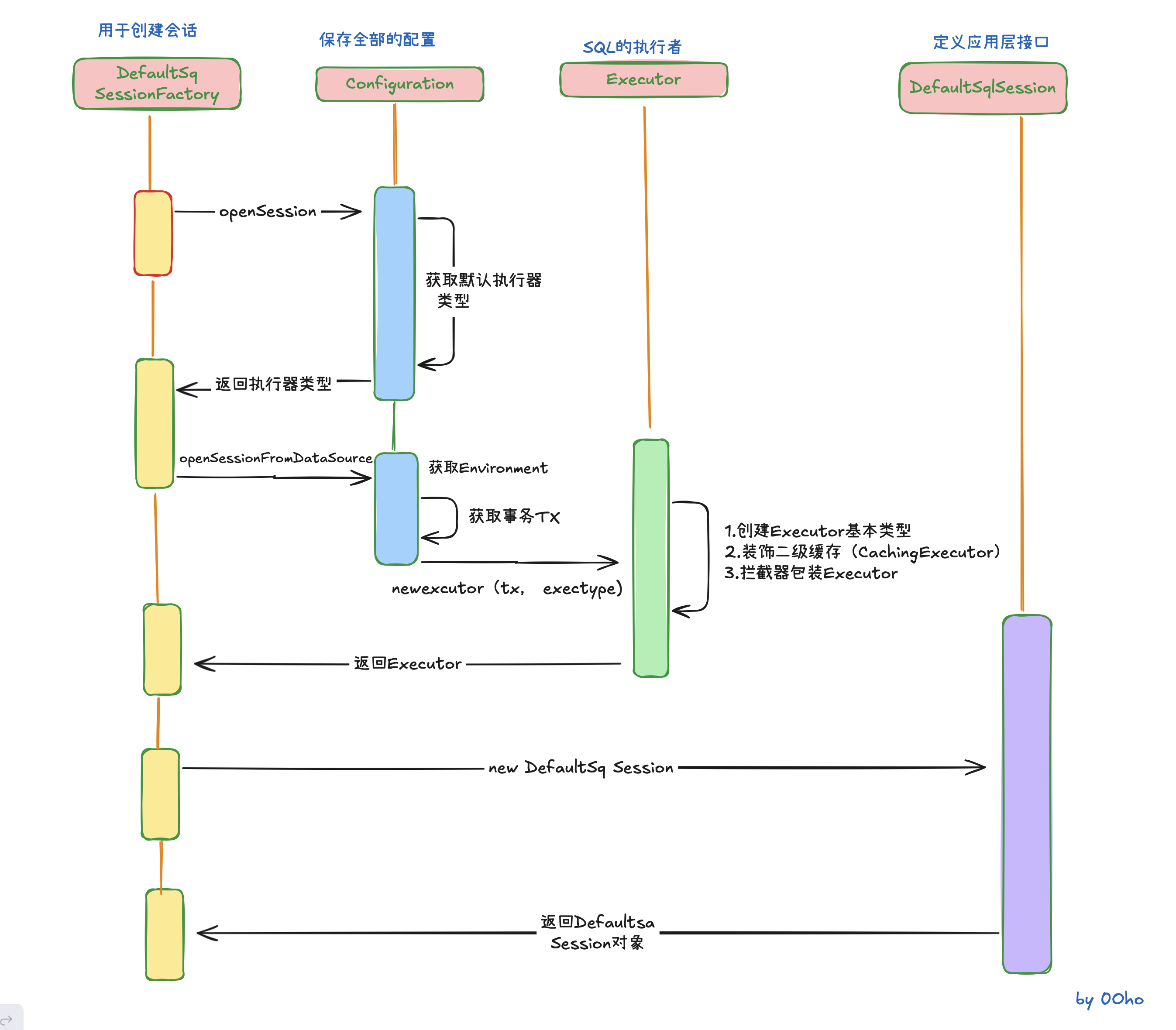
程序每一次操作数据库,都需要创建一个会话,我们用openSession()方法来创建。接下来我们看看SqlSession创建过程中做了哪些操作
SqlSession sqlSession = factory.openSession();通过前面创建的DefaultSqlSessionFactory的openSession方法来创建
@Override
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}首先会获取默认的执行器类型。默认的是simple
继续往下
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 根据事务工厂和默认的执行器类型,创建执行器 >>
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}我们在解析environment标签的时候有创建TransactionFactory对象

根据事务工厂和默认的执行器类型,创建执行器
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 默认 SimpleExecutor
executor = new SimpleExecutor(this, transaction);
}
// 二级缓存开关,settings 中的 cacheEnabled 默认是 true
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 植入插件的逻辑,至此,四大对象已经全部拦截完毕
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}最后返回的是一个DefaultSqlSession对象

在这个DefaultSqlSession对象中包括了Configuration和Executor对象
总结:创建会话的过程,我们获得了一个DefaultSqlSession,里面包含了一个Executor,Executor是SQL的实际执行对象。
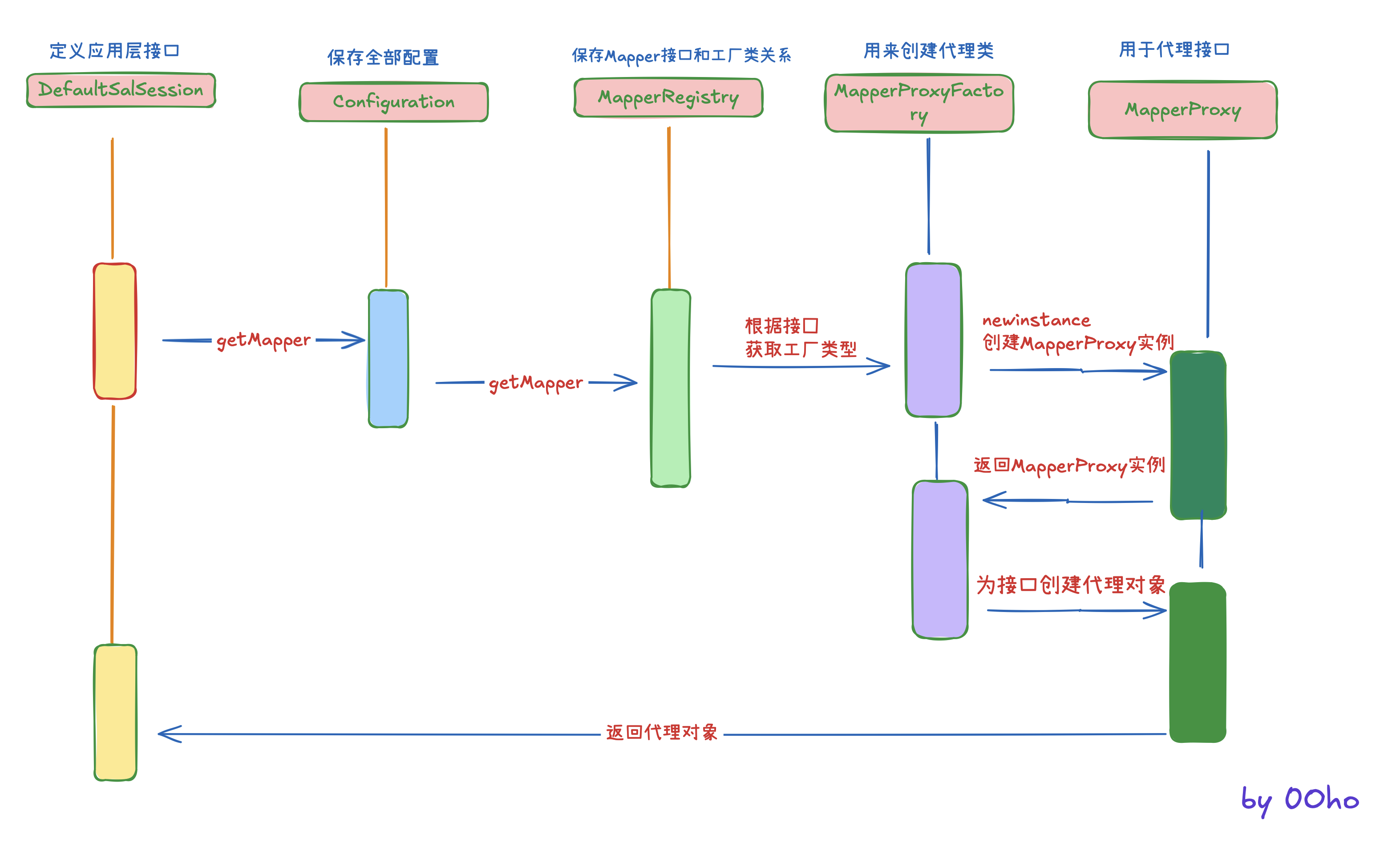
Mapper代理对象
接下来看下通过getMapper方法获取对应的接口的代理对象的实现原理
// 4.通过SqlSession中提供的 API方法来操作数据库
UserMapper mapper = sqlSession.getMapper(UserMapper.class);进入DefaultSqlSession中查看
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// mapperRegistry中注册的有Mapper的相关信息 在解析映射文件时 调用过addMapper方法
return mapperRegistry.getMapper(type, sqlSession);
}进入getMapper方法
/**
* 获取Mapper接口对应的代理对象
*/
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 获取Mapper接口对应的 MapperProxyFactory 对象
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}进入newInstance方法
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}继续
/**
* 创建实现了 mapperInterface 接口的代理对象
*/
protected T newInstance(MapperProxy<T> mapperProxy) {
// 1:类加载器:2:被代理类实现的接口、3:实现了 InvocationHandler 的触发管理类
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}最终我们在代码中发现代理对象是通过JDK动态代理创建,返回的代理对象。而且里面也传递了一个实现了InvocationHandler接口的触发管理类。
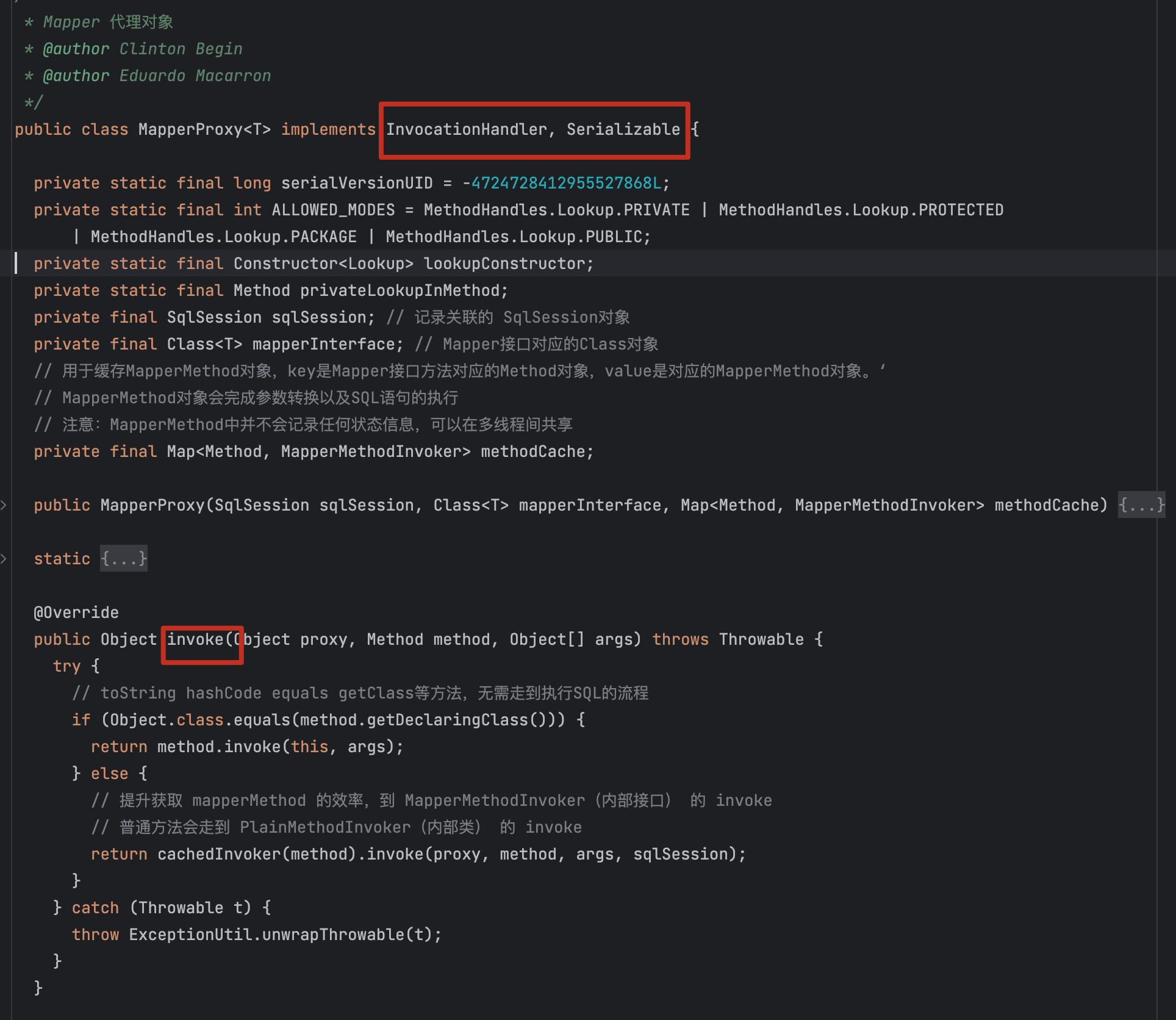
总结:获得Mapper对象的过程,实质上是获取了一个JDK动态代理对象(类型是$ProxyN)。这个代理类会继承Proxy类,实现被代理的接口,里面持有了一个MapperProxy类型的触发管理类。
SQL执行
接下来我们看看SQL语句的具体执行过程是怎么样的
List<User> list = mapper.selectUserList();由于所有的Mapper都是JDK动态代理对象,所以任意的方法都是执行触发管理类MapperProxy的invoke()方法
MapperProxy.invoke()
我们直接进入到invoke方法中
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// toString hashCode equals getClass等方法,无需走到执行SQL的流程
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 提升获取 mapperMethod 的效率,到 MapperMethodInvoker(内部接口) 的 invoke
// 普通方法会走到 PlainMethodInvoker(内部类) 的 invoke
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}然后进入到PlainMethodInvoker的invoke方法
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
// SQL执行的真正起点
return mapperMethod.execute(sqlSession, args);
}mapperMethod.execute()
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // 根据SQL语句的类型调用SqlSession对应的方法
case INSERT: {
// 通过 ParamNameResolver 处理args[] 数组 将用户传入的实参和指定参数名称关联起来
Object param = method.convertArgsToSqlCommandParam(args);
// sqlSession.insert(command.getName(), param) 调用SqlSession的insert方法
// rowCountResult 方法会根据 method 字段中记录的方法的返回值类型对结果进行转换
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
// 返回值为空 且 ResultSet通过 ResultHandler处理的方法
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
// 返回值为 单一对象的方法
Object param = method.convertArgsToSqlCommandParam(args);
// 普通 select 语句的执行入口 >>
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
在这一步,根据不同的type(INSERT、UPDATE、DELETE、SELECT)和返回类型:
1)调用convertArgsToSqlCommandParam()将方法参数转换为SQL的参数。
2)调用sqlSession的insert()、update()、delete()、selectOne ()方法。我们以查询为例,会走到selectOne()方法。
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);sqlSession.selectOne
这里来到了对外的接口的默认实现类DefaultSqlSession。
selectOne()最终也是调用了selectList()
@Override
public <T> T selectOne(String statement, Object parameter) {
// 来到了 DefaultSqlSession
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}在SelectList()中,我们先根据command name(Statement ID)从Configuration中拿到MappedStatement。ms里面有xml中增删改查标签配置的所有属性,包括id、statementType、sqlSource、useCache、入参、出参等等
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
// 如果 cacheEnabled = true(默认),Executor会被 CachingExecutor装饰
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}然后执行了Executor的query()方法。
Executor是第二步openSession的时候创建的,创建了执行器基本类型之后,依次执行了二级缓存装饰,和插件包装。
所以,如果有被插件包装,这里会先走到插件的逻辑。如果没有显式地在settings中配置cacheEnabled=false,再走到CachingExecutor的逻辑,然后会走到BaseExecutor的query()方法。
插件后面讲,这里先跳过。
CachingExecutor.query()
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 获取SQL
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 创建CacheKey:什么样的SQL是同一条SQL? >>
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}二级缓存的CacheKey是怎么构成的呢?或者说,什么样的查询才能确定是同一个查询呢?
在BaseExecutor的createCacheKey方法中,用到了六个要素:
cacheKey.update(ms.getId()); // com.msb.mapper.BlogMapper.selectBlogById
cacheKey.update(rowBounds.getOffset()); // 0
cacheKey.update(rowBounds.getLimit()); // 2147483647 = 2^31-1
cacheKey.update(boundSql.getSql());
cacheKey.update(value);
cacheKey.update(configuration.getEnvironment().getId());也就是说,方法相同、翻页偏移相同、SQL相同、参数值相同、数据源环境相同,才会被认为是同一个查询。
CacheKey的实际值举例(toString()生成的),debug可以看到:
-1381545870:4796102018:com.msb.mapper.BlogMapper.selectBlogById:0:2147483647:select * from blog where bid = ?:1:development注意看一下CacheKey的属性,里面有一个List按顺序存放了这些要素。
private static final int DEFAULT_MULTIPLIER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
private List<Object> updateList怎么比较两个CacheKey是否相等呢?如果一上来就是依次比较六个要素是否相等,要比较6次,这样效率不高。有没有更高效的方法呢?继承Object的每个类,都有一个hashCode ()方法,用来生成哈希码。它是用来在集合中快速判重的。
在生成CacheKey的时候(update方法),也更新了CacheKey的hashCode,它是用乘法哈希生成的(基数baseHashCode=17,乘法因子multiplier=37)。
hashcode = multiplier * hashcode + baseHashCode;Object中的hashCode()是一个本地方法,通过随机数算法生成(OpenJDK8 ,默认,可以通过-XX:hashCode修改)。CacheKey中的hashCode()方法进行了重写,返回自己生成的hashCode。
为什么要用37作为乘法因子呢?跟String中的31类似。
CacheKey中的equals也进行了重写,比较CacheKey是否相等。
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
if (hashcode != cacheKey.hashcode) {
return false;
}
if (checksum != cacheKey.checksum) {
return false;
}
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}如果哈希值(乘法哈希)、校验值(加法哈希)、要素个数任何一个不相等,都不是同一个查询,最后才循环比较要素,防止哈希碰撞。
CacheKey生成之后,调用另一个query()方法。
BaseExecutor.query方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
// cache 对象是在哪里创建的? XMLMapperBuilder类 xmlconfigurationElement()
// 由 <cache> 标签决定
if (cache != null) {
// flushCache="true" 清空一级二级缓存 >>
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
// 获取二级缓存
// 缓存通过 TransactionalCacheManager、TransactionalCache 管理
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 写入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 走到 SimpleExecutor | ReuseExecutor | BatchExecutor
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 异常体系之 ErrorContext
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// flushCache="true"时,即使是查询,也清空一级缓存
clearLocalCache();
}
List<E> list;
try {
// 防止递归查询重复处理缓存
queryStack++;
// 查询一级缓存
// ResultHandler 和 ResultSetHandler的区别
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 真正的查询流程
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 先占位
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 三种 Executor 的区别,看doUpdate
// 默认Simple
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 移除占位符
localCache.removeObject(key);
}
// 写入一级缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}SimpleExecutor.doQuery方法
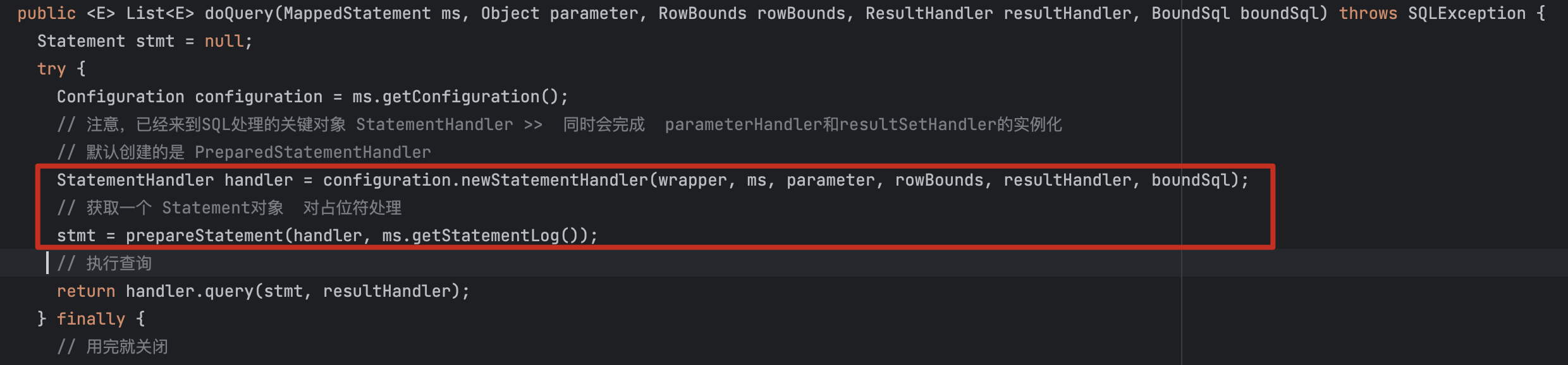
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 注意,已经来到SQL处理的关键对象 StatementHandler >>
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 获取一个 Statement对象
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 用完就关闭
closeStatement(stmt);
}
}在configuration.newStatementHandler()中,new一个StatementHandler,先得到RoutingStatementHandler。
RoutingStatementHandler里面没有任何的实现,是用来创建基本的StatementHandler的。这里会根据MappedStatement里面的statementType决定StatementHandler的类型。默认是PREPARED(STATEMENT、PREPARED、CALLABLE)。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// StatementType 是怎么来的? 增删改查标签中的 statementType="PREPARED",默认值 PREPARED
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
// 创建 StatementHandler 的时候做了什么? >>
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}StatementHandler里面包含了处理参数的ParameterHandler和处理结果集的ResultSetHandler。
这两个对象都是在上面new的时候创建的。
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
this.configuration = mappedStatement.getConfiguration();
this.executor = executor;
this.mappedStatement = mappedStatement;
this.rowBounds = rowBounds;
this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();
this.objectFactory = configuration.getObjectFactory();
if (boundSql == null) { // issue #435, get the key before calculating the statement
generateKeys(parameterObject);
boundSql = mappedStatement.getBoundSql(parameterObject);
}
this.boundSql = boundSql;
// 创建了四大对象的其它两大对象 >>
// 创建这两大对象的时候分别做了什么?
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}这三个对象都是可以被插件拦截的四大对象之一,所以在创建之后都要用拦截器进行包装的方法。
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
// 植入插件逻辑(返回代理对象)
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
// 植入插件逻辑(返回代理对象)
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 植入插件逻辑(返回代理对象)
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}创建Statement
用new出来的StatementHandler创建Statement对象。
执行查询操作,如果有插件包装,会先走到被拦截的业务逻辑。
// 执行查询
return handler.query(stmt, resultHandler);进入到PreparedStatementHandler中处理
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 到了JDBC的流程
ps.execute();
// 处理结果集
return resultSetHandler.handleResultSets(ps);
}执行PreparedStatement的execute()方法,后面就是JDBC包中的PreparedStatement的执行了。
ResultSetHandler处理结果集,如果有插件包装,会先走到被拦截的业务逻辑。
SQL执行流程时序图 (ps:这图画了将近半个小时,吐了🤮)

MyBatis核心对象
| 对象 | 相关对象 | 作用 |
| Configuration | MapperRegistry | 包含了MyBatis的所有的配置信息 |
| SqlSession | SqlSessionFactory | 对操作数据库的增删改查的API进行了封装,提供给应用层使用 |
| Executor | BaseExecutor | MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护 |
| StatementHandler | BaseStatementHandler | 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合 |
| ParameterHandler | DefaultParameterHandler | 把用户传递的参数转换成JDBC Statement 所需要的参数 |
| ResultSetHandler | DefaultResultSetHandler | 把JDBC返回的ResultSet结果集对象转换成List类型的集合 |
| MapperProxy | MapperProxyFactory | 触发管理类,用于代理Mapper接口方法 |
| MappedStatement | SqlSource | MappedStatement维护了一条<select|update|delete|insert>节点的封装,表示一条SQL包括了SQL信息、入参信息、出参信息 |
原文地址:https://blog.csdn.net/o0oho/article/details/143768764
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!