SQL Server特性
一、创建表
在sql server中使用create table来创建新表。
create table Customers(
id int primary key identity(1,1),
name varchar(5)
)该表名为Customers其中包含了2个字段,分别为id(主键)以及name。
1、数据类型
整数类型:
tinyint(1字节,从 0 到 255)
smallint(2字节,从 -32,768 到 32,767)
int(四字节,从 -2,147,483,648 到 2,147,483,647)
bigint(八字节,从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807)
浮点数类型:
float(单精度或双精度浮点数)
real(精确到 7 位小数的近似数值数据类型)
字符类型:
char(x)(固定存储,只能存储x个字符长度,最大长度为 8000 个字符)
varchar(x)(可变存储,可以存储0到x的字符长度,最大长度为 8000 个字符,如果x为max,那么可以存储2^31-1 个字符)
nchar(x)(固定长度的 Unicode 字符序列,最大长度为 4000 个字符)
nvarchar(x)(可变长度的 Unicode 字符序列,最大长度为 4000 个字符)
日期类型:
date(仅存储日期部分)
time(仅存储时间部分)
datetime(存储日期和时间部分)
datetime2(高精度的datetime)
二进制类型:
binary(x)(固定长度的二进制数据)
varbinary()(可变长度的二进制数据)
如果数据中有中文字符、日文、韩文等多字节字符,建议存放数据类型为nvarchar,可以有效避免乱码。
二、定义函数
函数通常使用BEGIN...END块来定义函数体,使用CREATE FUNCTION创建函数。以力扣177题第n高的薪水举列子:
表:
Employee+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | salary | int | +-------------+------+ 在 SQL 中,id 是该表的主键。 该表的每一行都包含有关员工工资的信息。查询
Employee表中第n高的工资。如果没有第n个最高工资,查询结果应该为null。
定义了一个名getNthHighestSalary的函数,该函数接收一个int类型参数N并且返回一个int类型值,在BEGIN后开始我们的逻辑,RETURN具体要返回的值,以END标志结尾。
CREATE FUNCTION getNthHighestSalary(@N INT) RETURNS INT AS
BEGIN
RETURN (
SELECT isnull((
SELECT newsalary.salary
FROM (SELECT DENSE_RANK() OVER (ORDER BY salary DESC) AS DenseRank ,salary FROM Employee GROUP BY Salary)
AS newsalary WHERE newsalary.DenseRank=@N
),null)
);
END
GO调用这个函数SELECT dbo.getNthHighestSalary(要传参的值);
扩展:
DENSE_RANK()窗口函数
DENSE_RANK()函数为数据集中的每一行分配一个连续的排名,这些排名是基于指定的排序顺序进行计算的,会保留排名的连续性。也就是说,如果有两个或多个相同的值,它们会获得相同的排名,并且下一个不同值的排名会紧接着前一个排名的下一个整数,而不会跳过任何数字。
基本语法:
DENSE_RANK() OVER (PARTITION BY [column] ORDER BY [column] [ASC|DESC])
ISNULL()函数
用于检查指定的表达式是否为NULL,并在表达式为NULL时返回一个指定的替代值。
基本语法:ISNULL(expression, replacement_value)
expression:要检查是否为NULL的表达式。
replacement_value:在expression为NULL时返回的替代值。
三、索引
聚集索引
表中只能有一个,它决定了表中数据的物理存储顺序,在sql server中通常会默认依据主键创建一个聚集索引。
列如我们创建一个表cs,对其中的id字段不设置主键,那么我们对这个表创建完成之后,不会有默认的聚集索引。
create table cs(
id int
) 
但是如果我们对该表cs的id字段添加primary key设置为主键,那么在创建表的同时会默认根据id这个主键创建一个索引。
create table cs(
id int primary key
) 
查看该索引的属性,我们可以看到,是根据id字段进行创建的该索引。
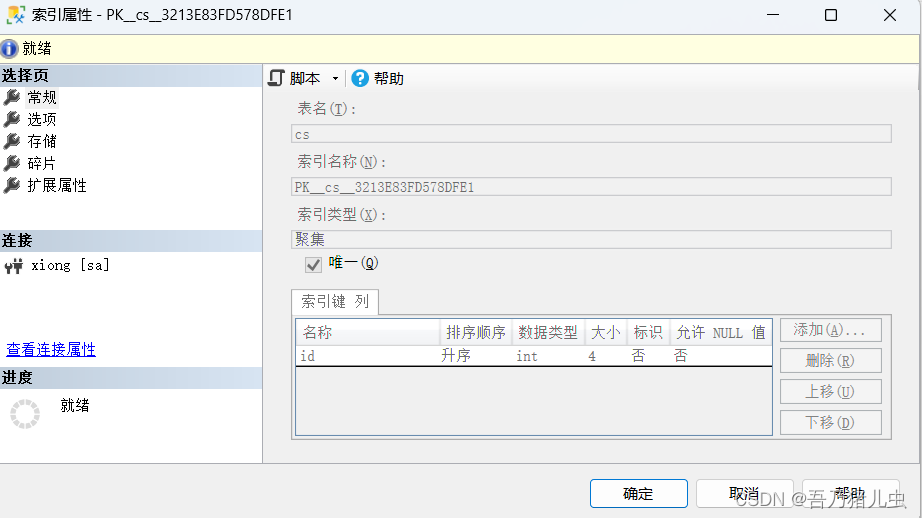
非聚集索引
聚集索引一张表中只能存在一个,而非聚集索引一张表可以存在多个,它与表中的数据分开存储,包含指向表中数据的指针。
列如创建一个school表,其中包含三个字段,现在我用name列创建一个名idx_school的非聚集索引,创建完成之后,我们对school表中的name字段进行查询。
--创建表school
create table school(
id int identity(1,1),--id
name varchar(5),--姓名
age int--年龄
)
--创建非聚集索引
CREATE NONCLUSTERED INDEX idx_school
ON school(name);
--查询
select name from school我们可以在执行计划中看到Index Scan,这表示我们成功使用了索引进行查询,使用的索引是[school].[idx_school]索引(就是school表下的idx_school索引),就是我们所创建的非聚集索引。
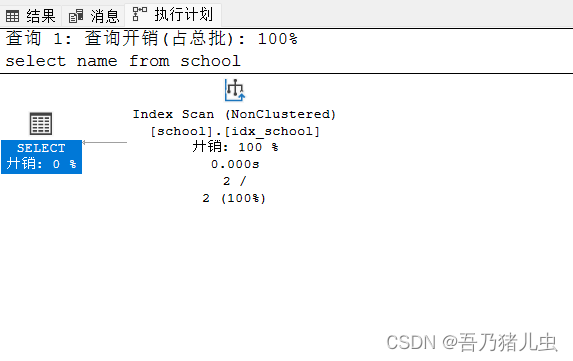
复合索引
由多个列组成的索引,根据列的顺序来决定查询速度的快慢,本质上也是非聚集索引。
同样使用非聚集索引的表,如果我们要使用非聚集索引查询年龄为多大的姓名,在使用idx_school索引时,是不会触发索引查询的。
select name from school where age=12我们在执行计划中可以看到Table Scan这表示为表扫描,对整张表[school]进行扫描查询。
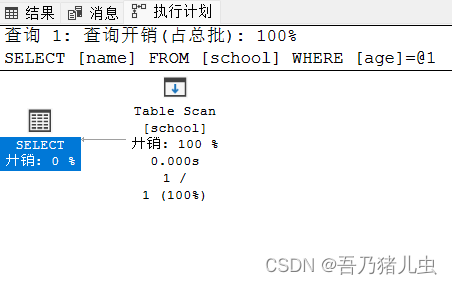
在这种情况下,我们就需要创建复合索引,创建完复合索引之后再执行相同的查询语句。
--创建复合索引
CREATE NONCLUSTERED INDEX idx_name_age
ON school (name ASC, age ASC);--ASC为升序,DESC为降序
--查询
select name from school where age=12现在我们在执行计划中就看到Index Scan,使用的是[school].[idx_name_age]索引。
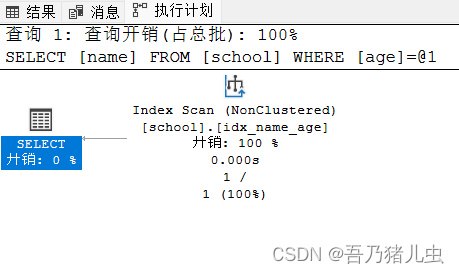
删除索引:DROP INDEX 索引名 ON 表名
四、视图
视图是一种虚拟的表,其内容由查询定义,本身不存储数据,而是根据查询结果动态生成数据,其每次查询视图时都会执行背后的SQL查询。
创建视图
对school表中的name和age字段创建一个名newschool的视图。
create view newschool as
select name,age from school使用视图
和查询普通表一样进行查询视图。
select * from newschool
原文地址:https://blog.csdn.net/qq_58159494/article/details/140082302
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!