【FPGA/IC】RAM-Based Shift Register Xilinx IP核的使用
前言
一般来讲,如果要实现移位寄存器的话,通常都是写RTL用reg来构造,比如1bit变量移位一个时钟周期就用1个reg,也就是一个寄存器FF资源,而移位16个时钟周期就需要16个FF,这种方法无疑非常浪费资源。
Xilinx FPGA的SLICEM中的一个查找表LUT可以配置为最多移位32个时钟周期的移位寄存器,这比直接用FF来搭省了31个FF资源。
这种方法可以通过调用原语SRL16E(最多16个周期)和SRLC32E(最多32个周期)来实现。
SRL16E #(
.INIT(16'h0000), // Initial contents of shift register
.IS_CLK_INVERTED(1'b0) // Optional inversion for CLK
)
SRL16E_inst (
.Q(Q), // 1-bit output: SRL Data
.CE(CE), // 1-bit input: Clock enable
.CLK(CLK), // 1-bit input: Clock
.D(D), // 1-bit input: SRL Data
// Depth Selection inputs: A0-A3 select SRL depth
.A0(A0),
.A1(A1),
.A2(A2),
.A3(A3)
);
// End of SRL16E_inst instantiation
// SRLC32E: 32-bit variable length cascadable shift register LUT (Mapped to a SliceM LUT6)
// with clock enable
SRLC32E #(
.INIT(32'h00000000) // Initial Value of Shift Register
) SRLC32E_inst (
.Q(Q), // SRL data output
.Q31(Q31), // SRL cascade output pin
.A(A), // 5-bit shift depth select input
.CE(CE), // Clock enable input
.CLK(CLK), // Clock input
.D(D) // SRL data input
);
// End of SRLC32E_inst instantiation
如果需要实现更多时钟周期的移位寄存器,则可以使用多个SRLC32E或者SRL16E来级联实现。
IP核的定制
除了用原语实现外,还可以调用 RAM-Based Shift Register 这个IP核来实现。IP核实现方法使用不如原语方便,但是其对实现方式做了一些优化,具有比原语更好的时序性能。
第一页内容
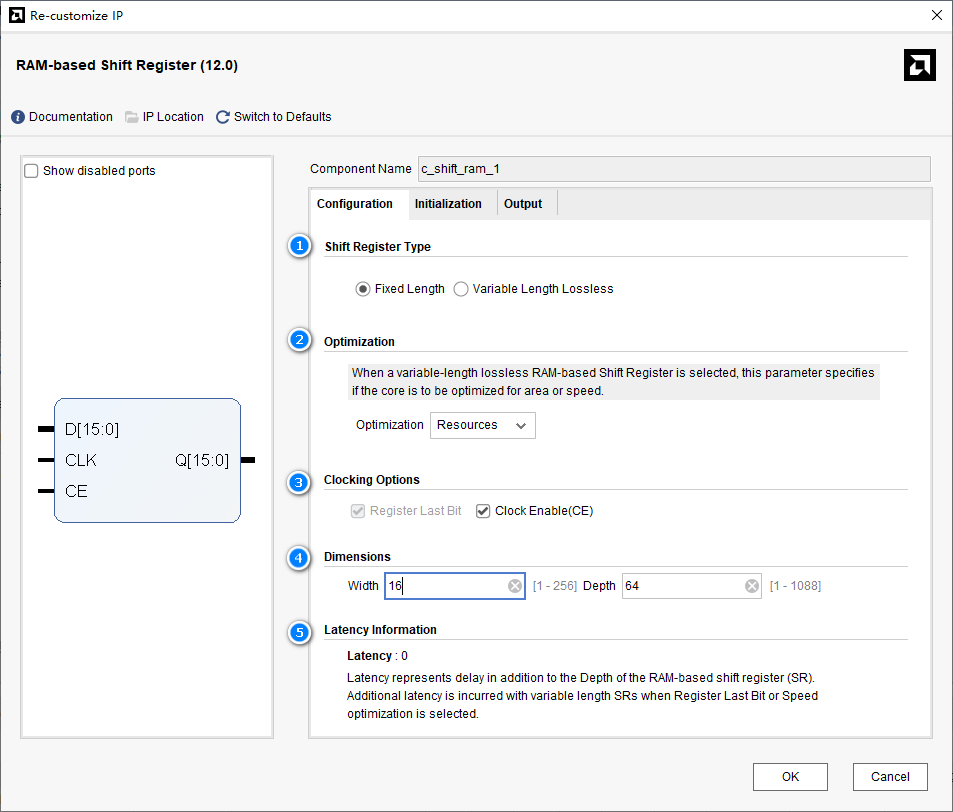
- Shift Register Type:fixed length为固定长度;variable length lossless为可变长度
- optimization:只有选择可变长度时才可选,可以选择优化面积还是优化时序。如果优化时序,则可能会多几个延迟latency。
- clocking options:Register last bit只有选择可变长度时才可选,会把输出寄存一拍以改善时序,同时增加一个时钟的延迟。clock enable(CE)时钟使能功能。
- dimensions:width移位寄存器宽度,depth移位寄存器深度。
- latency information:延迟信息,根据各个选项的不同,输出延迟可能会增加1~3个时钟周期。
第二页内容
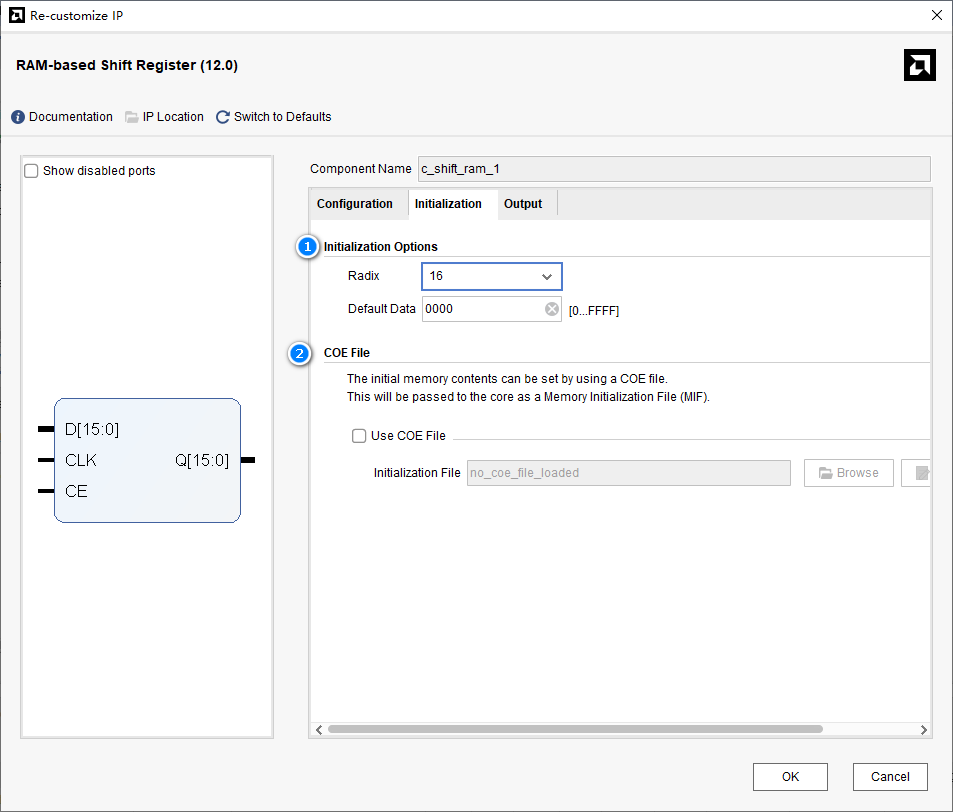
- initialization options:初始化选项,选择初始化的进制radix和默认值default data。
- COE file:初始化的值还可以选择从COE文件来载入。
第三页
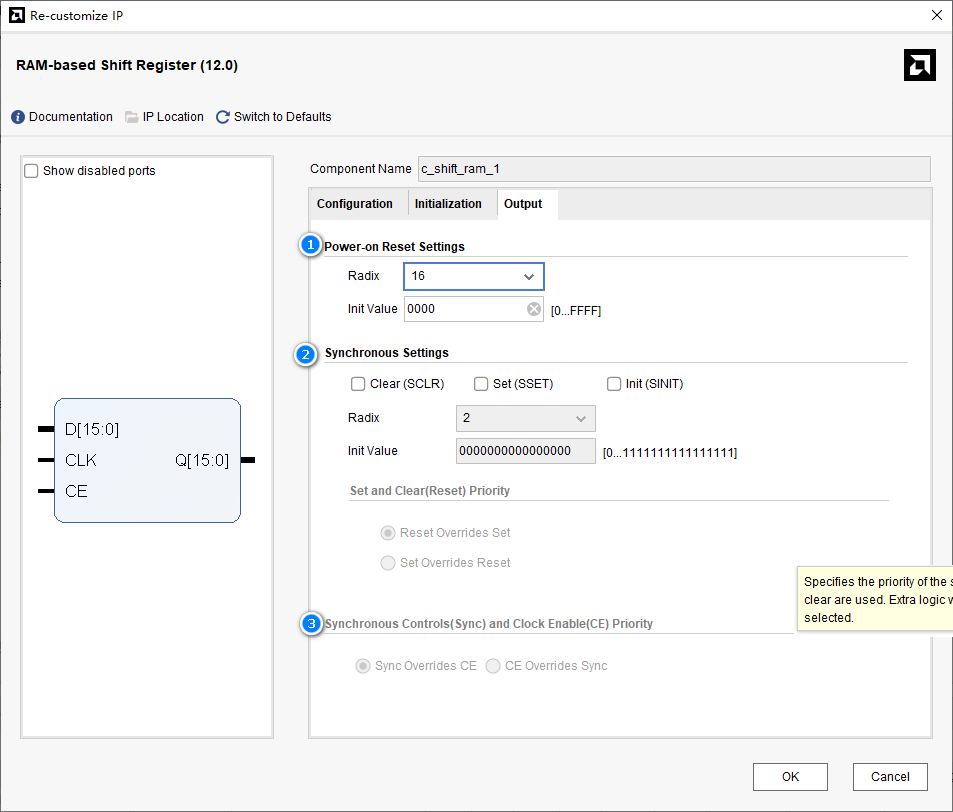
- power-on reset settings:上电复位设置选项,选择上电复位的进制radix和初始值init data。
- synchronous settings:同步设置,可以设置同步复位SCLR和同步置位SSET,二者的优先级可选,默认复位优先级高于置位,如果选择置位优先级更高,则会消耗多余的资源。复位/置位与初始化SINT二者之间互斥。这三个选项一般都没必要用。
- synchronous controls(sync) and clock enable(CE) priority:选择同步控制信号和CE信号的优先级。默认同步控制信号的优先级高于CE,反之则会消耗多余的资源。
IP核的仿真使用
定制一个深度为64,位宽为16的IP核,然后编写RTL代码:
//固定的深度64个时钟周期,位宽16的移位寄存器IP核设计
module shift_w16_d64(
inputclk,//时钟信号
input[15:0]in,//移位前的输入数据,位宽为16
inputce,//时钟使能信号
output[15:0]out//移位后的输出,位宽为16
);
//移位寄存器IP;固定移位64个时钟周期,位宽16
c_shift_ram_1 your_instance_name (
.D(in),//移位前的输入数据,位宽为16
.CLK(clk),//时钟信号
.CE(ce),//时钟使能信号
.Q(out)//移位后的输出,位宽为16
);
endmodule
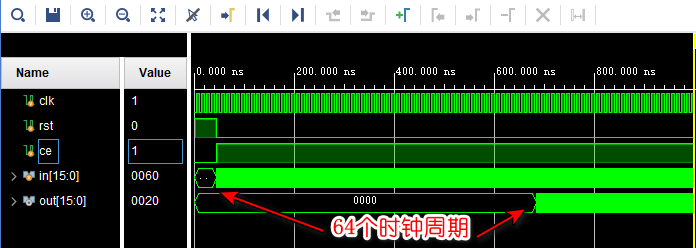
综合后的资源使用情况:32个LUT + 32个FF。

看下综合后的电路图:
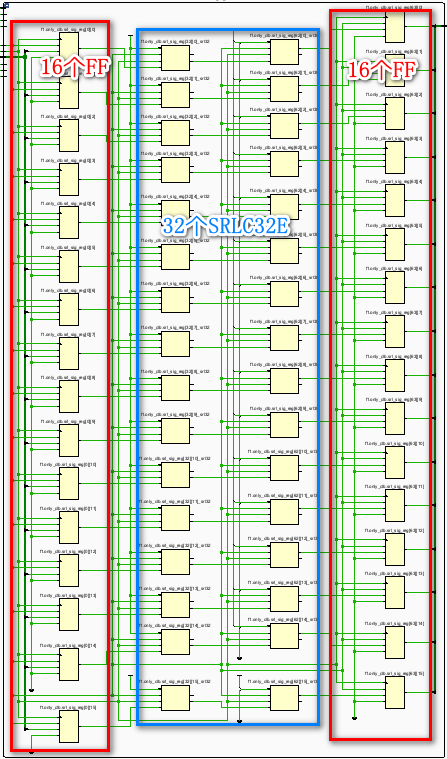
因为1个SRLC32E可以实现32个周期的移位,所以16×64的移位操作实际上只需要32个SRLC32E就可以实现了,为了改善时序性能,IP核在输入端口和输出端口一共用了2×16 = 32个FF来打拍寄存。
接下来编写TB:时钟使能信号一直拉高,输入数据从1开始累加。
`timescale 1ns/1ns
module tb_shift_w16_d64();
//信号声明
regclk;
regrst;
reg[15:0]in;
regce;
wire[15:0]out;
//被测模块实例化
shift_w16_d64inst_shift_w16_d64(
.clk(clk),
.in(in),
.ce(ce),
.out(out)
);
//生成时钟信号
initial begin
clk= 1'b0;
forever #5 clk = ~clk;
end
//生成复位信号
initial begin
rst = 1'b1;//复位
#45 rst = 1'b0; //取消复位
end
//生成输入数据与时钟使能信号
always @(posedge clk or posedge rst)begin
if(rst)begin
in <= 16'd0;
ce <= 1'b0;
end
else begin
in <= in + 1'b1;//输入数据累加1
ce <= 1'b1;//时钟使能信号一直拉高
end
end
//仿真过程
initial begin
#1000 $stop;//关闭仿真
end
endmodule
仿真结果如下:

- 📣您有任何问题,都可以在评论区和我交流📃!
- 📣本文由 孤独的单刀 原创,首发于CSDN平台🐵,博客主页:wuzhikai.blog.csdn.net
- 📣您的支持是我持续创作的最大动力!如果本文对您有帮助,还请多多点赞👍、评论💬和收藏⭐!
原文地址:https://blog.csdn.net/wuzhikaidetb/article/details/136378999
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!