YOLOv8改进 在更换的PoolFormer主干网络中增加注意力机制

一、PoolFormer的网络结构
PoolFormer采用自注意力机制和池化操作相结合的方式,同时考虑了局部和全局的特征关系。
具体的代码如(YOLOv8改进 更换多层池化操作主干网络PoolFormer_yolov8池化-CSDN博客)所示。
二、Global Attention Mechanism注意力机制
GAM_Attention专注于全局注意力的设计,在YOLOv8中加入GAM_Attention旨在通过全局信息对整个输入的图片上的火焰烟雾特征进行建模,使YOLOv8的网络能够更好地了解图像中的全局结构与关系。 GAM_Attention通常包含多个层次的注意力机制,允许模型在不同的空间尺度上进行特征建模。这有助于网络适应不同尺度和分辨率的目标,提高对多尺度目标的感知能力。
具体代码如
(YOLOv8中加入跨维度注意力机制注意力机制GAM,效果超越CMBA,NAM_yolov8添加gamattention-CSDN博客)所示。
三、Shuffle Attention注意力机制
Shuffle Attention是一种注意力机制,它在计算注意力权重时考虑了输入元素之间的顺序。传统的注意力机制通常是基于输入元素之间的相似度来计算注意力权重,但忽略了输入元素的顺序信息。而Shuffle Attention则通过引入一个可学习的参数来对输入元素进行排列,然后再计算注意力权重。这样可以使模型更加灵活地捕捉到输入元素之间的关系。
具体代码如(YOLOv8改进 加入随机化注意力权重的注意力机制Shuffle Attention 即插即用_shuffleattention原理-CSDN博客)所示。
四、整合网络结构和注意力机制的yaml文件
创建yolov8+PoolFormer+Attention.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, poolformer_s12, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# - [-1, 1, GAM_Attention, [1024]]
- [-1, 3, ShuffleAttention, [1024]]
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 9
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 12 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 15 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 5], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 18 (P5/32-large)
- [[12, 15, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)
五、运行验证

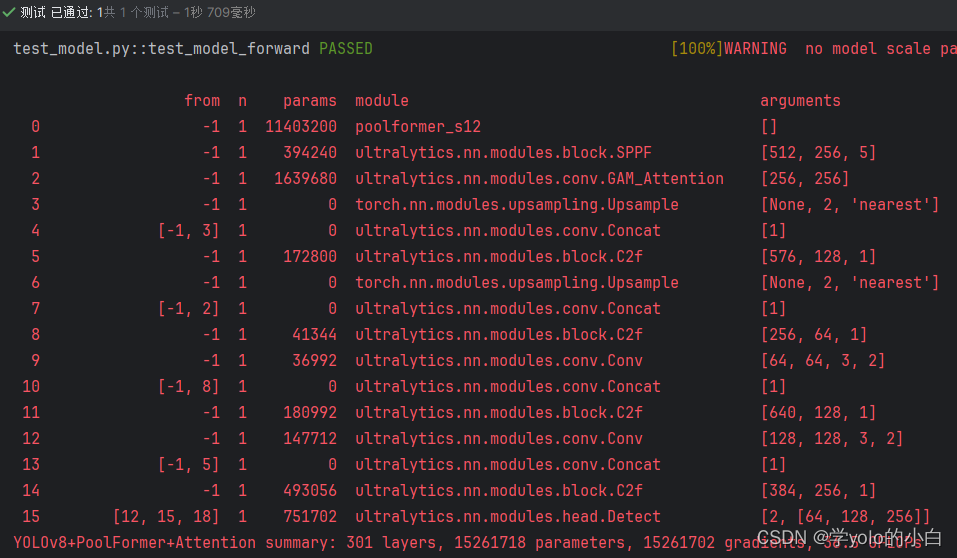
可以看出模型中已经同时包含poolformer网络结构和注意力机制。
原文地址:https://blog.csdn.net/zmyzcm/article/details/136480013
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!