[阅读笔记1][GPT-3]Language Models are Few-Shot Learners

首先讲一下GPT3这篇论文,文章标题是语言模型是小样本学习者,openai于2020年发表的。

这篇是在GPT2的基础上写的,由于GPT2还存在一些局限,这篇对之前的GPT2进行了一些完善。GPT2提出了多任务学习,也就是可以零样本地用在各个下游任务,不需要再进行微调了,这与Bert的思路差别很大。但是GPT2的结果没有特别出色,只是比部分有监督的模型高了一点,大概处在一个平均水平。
GPT3仍然沿用了2的思路,然后将模型扩大了一百倍,模型具有1750亿个参数。另外在处理任务时提供了少量带标签的样本供模型学习,不过这里并没有用这些样本微调模型,仅仅是作为prompt输入给模型。可以看到大模型和few-shot带来的提升都是巨大的。

以Bert为代表的预训练-微调范式存在一些问题,首先就是数据集,对于每个细分任务都需要带标注的数据集来微调,这个代价是很大的。第二点就是泛化性不好,因为只能应用于微调的那些任务。第三点是和人类进行类比,比如情感分析,人类不需要看完整个数据集,只需要看少量的几个例子就能学会。所以few-shot相比微调更符合人类行为。

接下来就是展示了一下GPT3使用的zero-shot、one-shot、few-shot与微调的区别。
左侧是微调的过程,右侧就是gpt3提出的方法,不需要进行梯度更新。

模型结构使用的类似GPT2,有一些改进,比如使用了稀疏transformer,类似于空洞卷积,这样模型能尽可能轻量一些。但即使这样,整个模型还是非常大的。
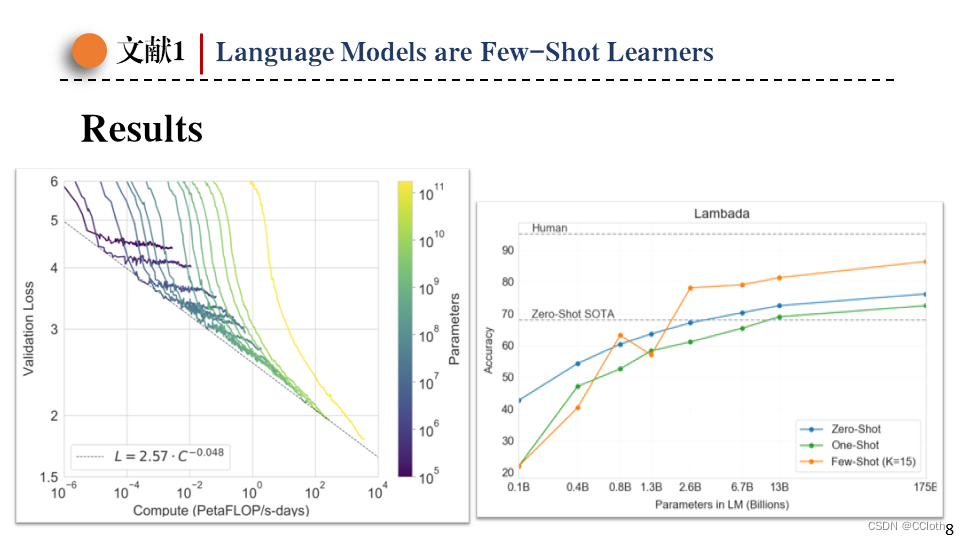
最后是模型的结果,左边的图可以看到模型越大损失越小,并且要想损失线性的下降需要模型规模指数级增大。右边的图是在lambada数据集上的结果,这里one-shot不如zero-shot结果,作者给出的解释是只给一个示例的话,模型还没有充分学习到这种交互方式,可能认为给的不是一个任务示例,而是一句普通的文本,从而干扰了正常的推理。
原文地址:https://blog.csdn.net/m0_55982600/article/details/137774351
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!