批量爬取B站网络视频信息
使用XPath爬取B站视频链接等相关信息
对于B站,目前网上的爬虫大多都是使用通过解析服务器的响应来爬取想要的内容,下面我们通过使用XPath来爬取B站上一些想要的信息
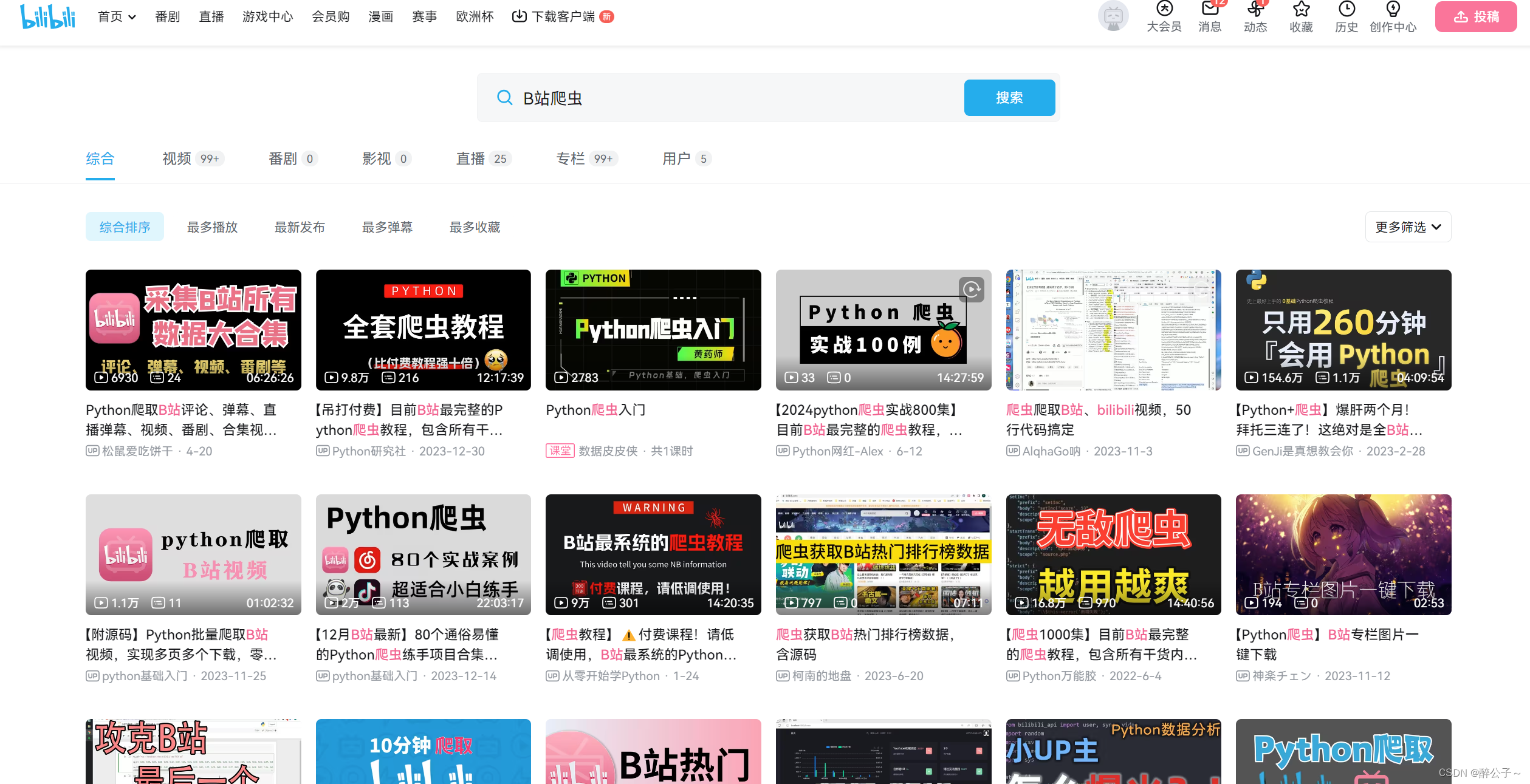
此次任务我们需要对B站搜索到的关键字,并爬取搜索的视频时间、播放量、弹幕量等信息
分析B站html框架
打开B站后,搜索关键字并按下F12进入开发者模式,就能看到页面的html代码,需要在这些代码中找到需要爬取的信息。
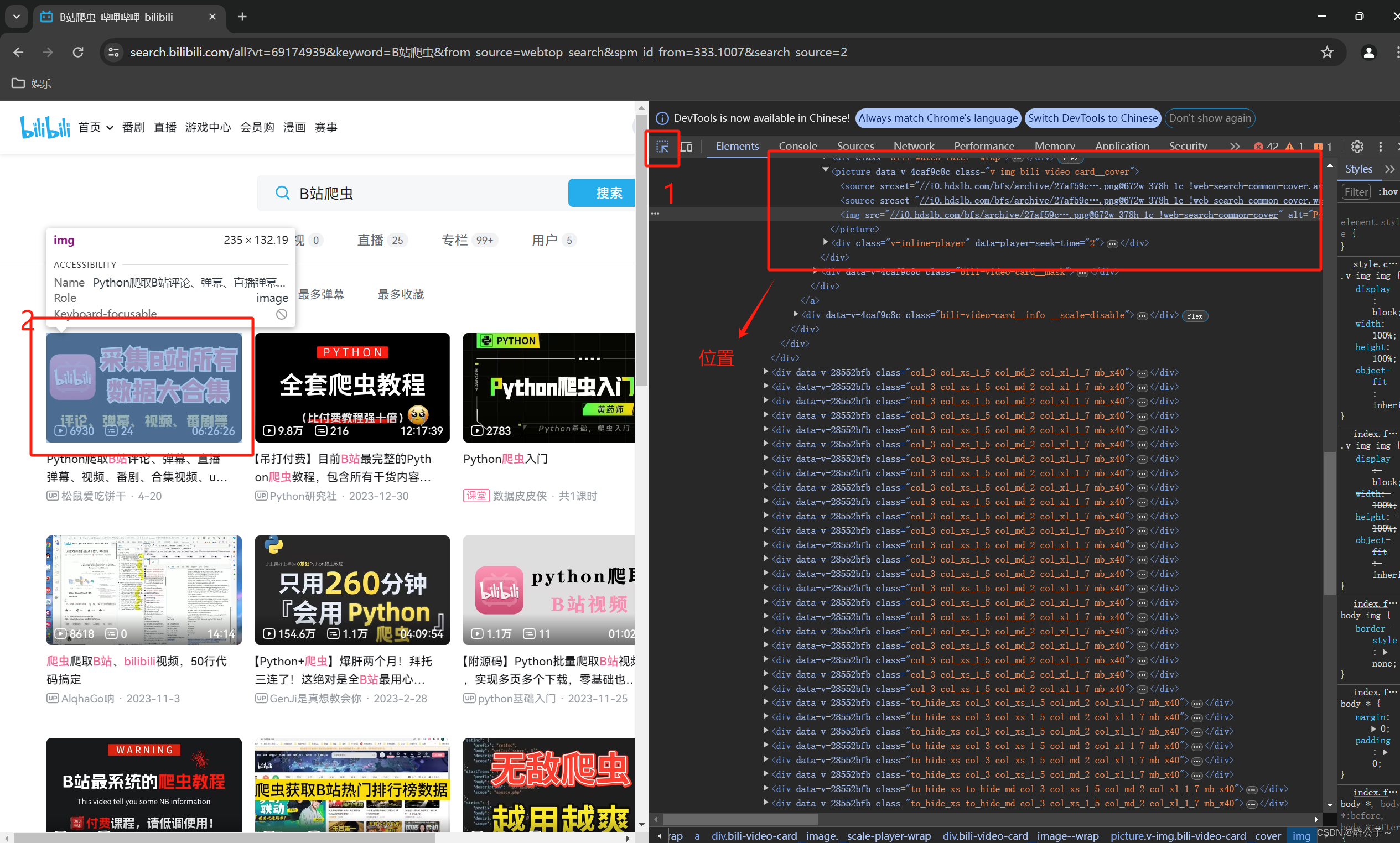
点击右上角的箭头图片,再点击想要爬取内容的信息,就会自动跳转到对应的html代码上。
获取内容
找到想要爬取的信息就得获取信息的XPath表达式,这儿可以通过如下图方法快速得到表达式。
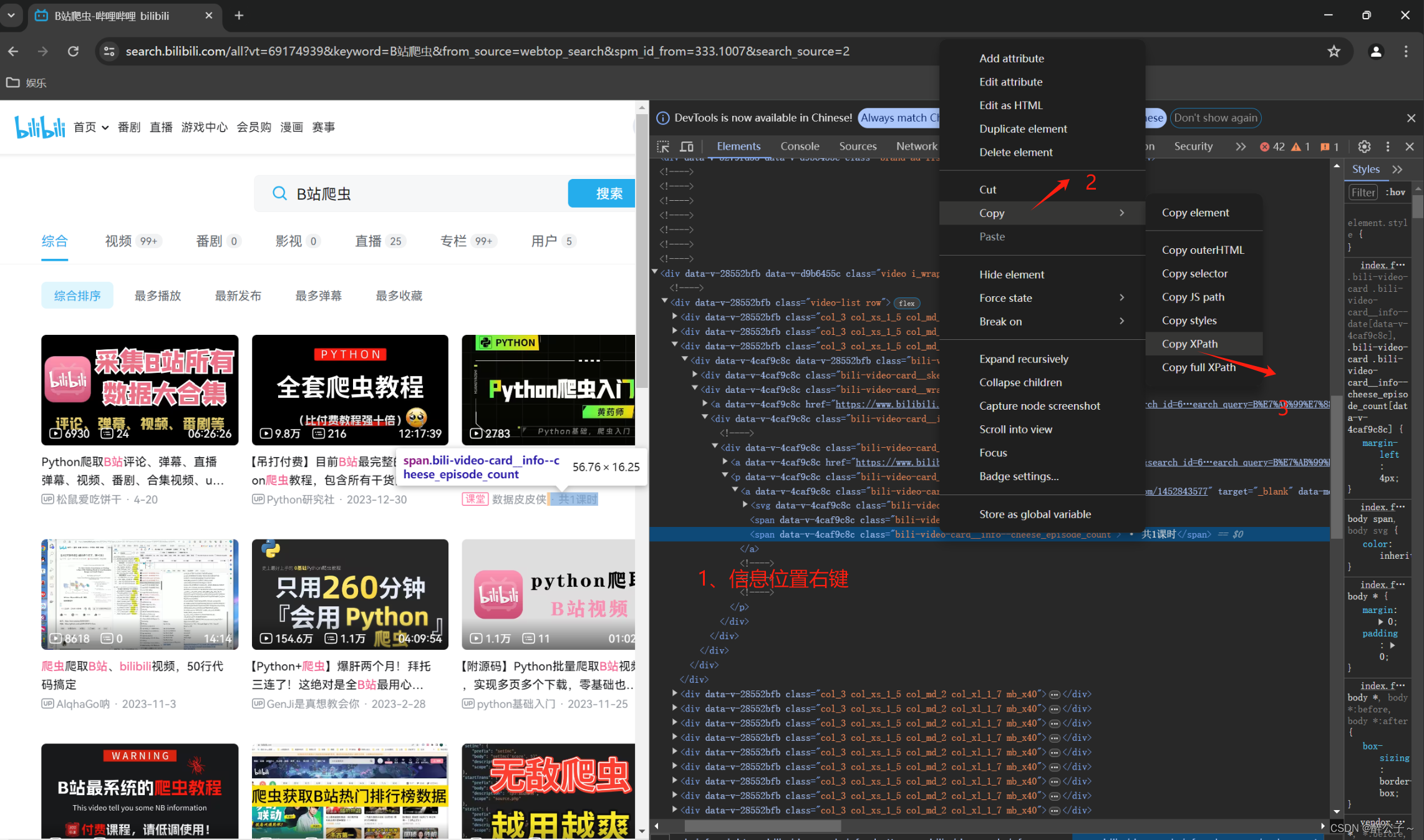
这样就可以得到该位置的XPath表达式了。
由于第一页XPath表达式与后面页的XPath表达式有些许的不同,需要通过对链接的验证来使用不同的表达式

完整代码
import requests
from lxml import etree
import time
import random
import csv
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'}
result = pd.DataFrame()
urls = [
'https://search.bilibili.com/all?vt=69174939&keyword=%E5%A4%A7%E6%95%B0%E6%8D%AE&from_source=webtop_search&spm_id_from=333.1007&search_source=2',
'https://search.bilibili.com/all?keyword=%E7%89%A9%E8%81%94%E7%BD%91%E5%B7%A5%E7%A8%8B&from_source=webtop_search&spm_id_from=333.1007&search_source=2',
'https://search.bilibili.com/all?vt=69174939&keyword=%E7%94%B5%E5%AD%90%E7%A7%91%E5%AD%A6%E4%B8%8E%E6%8A%80%E6%9C%AF&from_source=webtop_search&spm_id_from=333.1007&search_source=2',
'https://search.bilibili.com/all?vt=69174939&keyword=%E8%99%9A%E6%8B%9F%E7%8E%B0%E5%AE%9E&from_source=webtop_search&spm_id_from=333.1007&search_source=2',
'https://search.bilibili.com/all?vt=691740939&keyword=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&from_source=webtop_search&spm_id_from=333.1007&search_source=2',
]
url_key = [len(i) + 6 for i in urls]
for index, url in enumerate(urls):
for page in range(1, 10):
html = requests.get(url, headers=headers)
print(url)
bs = etree.HTML(html.text)
if url[-8:-1] == 'source=':
items = bs.xpath('//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div/div[3]/div')
else:
items = bs.xpath('//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div[1]')
for i in range(1, 43):
try:
time = items[0].xpath(f'div[{i}]/div/div[2]/div/div/p/a/span[2]')[0].text
except:
time = None
try:
up_author = items[0].xpath(f'div[{i}]/div/div[2]/div/div/p/a/span[1]')[0].text
except:
up_author = None
try:
title = items[0].xpath(f'div[{i}]/div/div[2]/div/div/a/h3/@title')[0]
except:
title = None
try:
href = items[0].xpath(f'div[{i}]/div/div[2]/div/div/a/@href')[0]
except:
href = None
try:
Playback_volume = items[0].xpath(f'div[{i}]/div/div[2]/a/div/div[2]/div/div/span[1]/span')[0].text
except:
Playback_volume = None
try:
Barrage_volume = items[0].xpath(f'div[{i}]/div/div[2]/a/div/div[2]/div/div/span[2]/span')[0].text
except:
Barrage_volume = None
try:
Video_duration = items[0].xpath(f'div[{i}]/div/div[2]/a/div/div[2]/div/span')[0].text
except:
Video_duration = None
print(time, title, up_author, href, Playback_volume, Barrage_volume, Video_duration)
df = pd.DataFrame({'time': [time], 'title': [title], 'up_author': [up_author], 'href': [href],
'Playback_volume': [Playback_volume], 'Barrage_volume': [Barrage_volume],
'Video_duration': [Video_duration]})
result = pd.concat([result, df])
if url[-8:-1] == 'source=':
url = url + '&page=2&o=36'
else:
new_page = int(url[url_key[index]]) + 1
url = url[:url_key[index]] + f'{new_page}&o={(new_page - 1) * 36}'
result.to_excel("F:/B站数据.xlsx", index=False)
原文地址:https://blog.csdn.net/qq_44936246/article/details/139727687
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!