实时数仓Hologres OLAP场景核心能力介绍
作者:赵红梅 Hologres PD
OLAP典型应用场景与痛点
首先介绍典型的OLAP场景以及在这些场景上的核心痛点,OLAP典型应用场景很多,总结有四类:第一类是BI报表分析类,例如BI报表,实时大屏,数据中台等。第二类是人群运营类,例如对人群的精准营销、用户画像、圈人圈品等。第三类为日志检索分析,例如行为分析、流量分析和广告投放。第四类是实时监控类,例如订单物流监控、网络监控、实时风控及直播监控等。这些OLAP场景被广泛应用在各个行业,例如广告、游戏、电商、互联网等。

复杂OLAP多维分析的普遍难题
基于这些OLAP场景,我们可以来分析一下,如果需要支撑复杂的OLAP多维分析,在技术上遇到的难题有哪些?首先第一点是技术栈复杂,要支撑多种OLAP分析场景,需要用到多种产品例如Mysql、ClickHouse(专用于流量分析场景)、Doris(用在多维应用)等等,导致技术上的组件会变得非常的繁多。
第二是需求的响应时间会变长,因为场景变得越来越丰富,业务需要更加灵活的 OLAP 分析,随时可以变动需求,受限于技术栈复杂,开发无法很快地响应业务的需求,导致业务的响应时间变得很长。
第三是开发和运维成本变高。对于多种技术产品共同使用在不同的场景上来说,开发和分析人员还有 BI 人员可能都需要学会不同的开发语言,导致学习和上手的难度变高。同时需要对不同组件做运维,也会变得非常复杂,就会显著的带来各种各样的成本。
第四是数据的时效性不能满足业务的需求,例如有的产品可能专注数据的实时写入与更新,查询的能力会比较弱。有些产品可能专注在查询的能力上,在数据的写入、更新等等能力上不足,这就导致无法很满足业务大部分的OLAP分析的需求,不能做更加精细化的运营分析。第五是生态兼容能力,不同的业务可能有不同的开发和分析工具,需要底层的技术产品对这些工具做一一的适配。有些产品可能在兼容度上不高,导致需要额外的开发。可能业务上还有一些额外的定制需求,例如要做专门的漏斗分析需求、留存需求等等。有些产品不支持,还需要开发人员去做额外的开发定制。
第六是业务间的相互影响。随着支持的业务变多,如果底层的技术产品没有很好的隔离机制,就会导致业务间相互的影响,非常容易影响线上的业务。

Hologres:阿里云一站式实时数仓
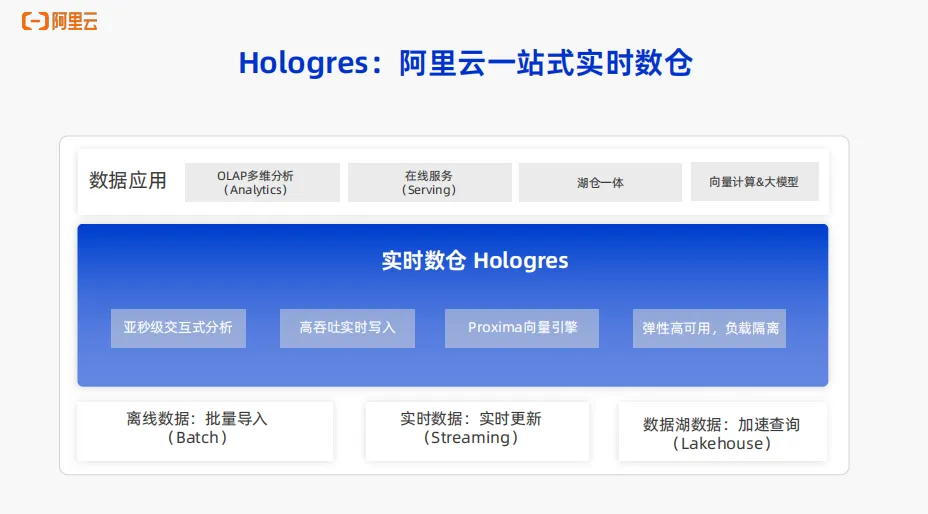
今天要介绍的产品Hologres,提供统一、实时、弹性、易用的一站式实时数仓引擎。上图可以很容易的理解Hologres 的核心能力。从下往上看,在存储层Hologres既支持离线数据的批量导入,同时也支持实时数据的写入,支持数据的实时写入与更新,同时对于数据湖的数据也可以直接加速查询。在数据应用层Hologres支持 OLAP 的多维分析,同时也支持像HBase、 Redis 这一类的在线服务的能力。刚刚提到的Hologres可以对数据湖的数据做加速,因此业务可以通过Hologres很方面的建设湖仓一体。同时Hologres也与达摩院的向量引擎Proxima 深度打通,可以支持向量和大模型的能力。
Hologres解决复杂OLAP场景的难题
下面介绍Hologres如何解决刚刚提到的OLAP场景的一些难题。

6 个难点Hologres有一一的应对方法。
-
技术栈复杂问题:Hologres采用服务分析一体化的架构,需求响应的时间短、时间长,数据时效性低。
-
数据时效性问题:基于Hologres的引擎的计算能力和高性能的写入和实施能力可以得到很好的满足。
-
开发和运维成本高问题:Hologres有 binlog 简化简化分层,有更多的函数、 JSONB等等,可以进一步的降低开发和运维成本
-
在生态兼容问题:Hologres支持多种 BI 和开发工具,能很好地满足生态兼容的问题。
-
隔离能力:在高级能力上,Hologres支持计算组隔离、解决业务间OLAP查询相互影响的问题。
下面做进一步的介绍。
Hologres 在OLAP场景的核心优势

首先 Hologres 在 OLAP 场景的核心优势如下:
-
Hologres 支持实时数仓的 OLAP分析。实时数仓在 OLAP场景上对于数据写入的时效性有着非常高的严格要求,这样可以保持数据的新鲜度。Hologres 支持高性能的实时写入与更新,数据写入就可以查。同时Hologres 采用列存的存储模式,在 OLAP 场景上使用AliORC 的压缩格式,支持多种的索引,例如簇族索引、位图、字典等等,都可以有效地提高数据的检索效率。同时是分布式的架构, MPP 的分布式计算,可以并行化地处理各种query。在 OLAP 的场景上也支持组件的更新、局部更新等,满足 OLAP 场景的不同需求。
-
在湖仓的场景上,可以对湖和仓的数据做直读加速,例如MaxCompute、OSS、 Paimon等数据都可以做直读的交互式加速。数据的性能是秒级的,不需要移动元数据,不需要做数据的搬迁。元数据会自动搬迁,不需要做额外的处理。如果想要实现更好的性能,可以把湖和仓的数据导入OSS。导入Hologres 的表,如果是MaxCompute的话同步的速度是百万行每秒的速度。
-
在生态上,Hologres 兼容 PG 生态,在上层上语法兼容标准的 PostgreSQL 开发语法。在开发工具和 BI 工具上兼容 PG ,只要能兼容 PG 的开发和 BI 工具都能够直线连Hologres 。另外也支持 PG 的多种扩展,例如PostGIS 等等都可以支持。同时在一些深耕的领域,例如留存、漏斗画像等等都可以很好的支持小流量分析、画像分析等等的场景。
Hologres OLAP场景核心能力-性能篇
1、丰富的索引能力,高效检索数据
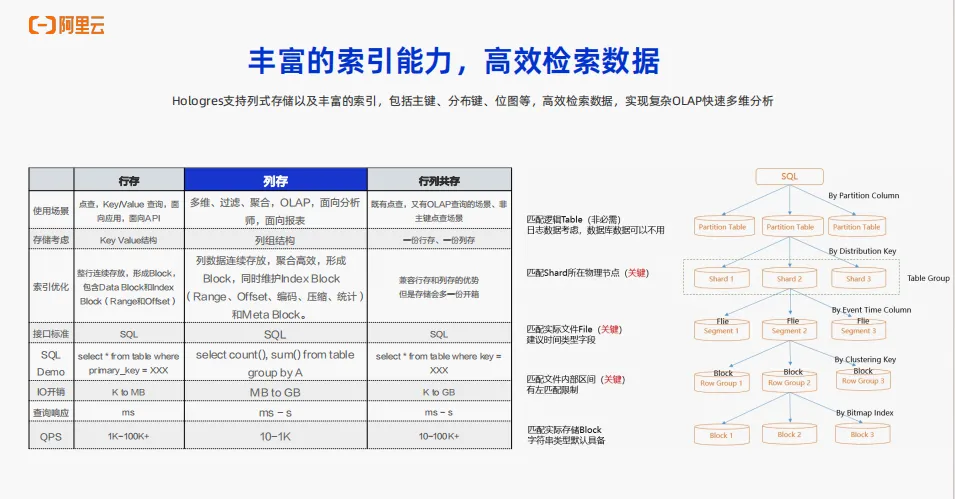
Hologres的数据存储格式,可以支持行存、列存以及行列共存。在 OLAP场景上,大多数使用列存来存储数据。列存的好处是可以支持数据的多维分析、过滤、聚合等等,非常有效的支持像面向分析师、面向报表这一类的OLAP的多维分析能力。查询的 QPS 也根据 query 的复杂程度有不同,响应时间也能从毫秒级到秒级。另外Hologres有丰富的索引,从上到下第一层是分区,可以快速地定位到数据所在分区。第二是 Distribution key,可以定位到数据所在的shard。下一层是 Event time column,可以快速地定位到数据所在的文件。下一层是分段键,可以让数据在文件内排序。基于Hologres 的这些丰富的索引,还有Hologres 的存储格式,可以做到非常高效地检索数据。即使是复杂的 OLAP 多维分析也能达到秒级甚至毫秒级的响应。
2、THC-H 30000GB标准测试世界第一
下面介绍 Hologres的查询性能。
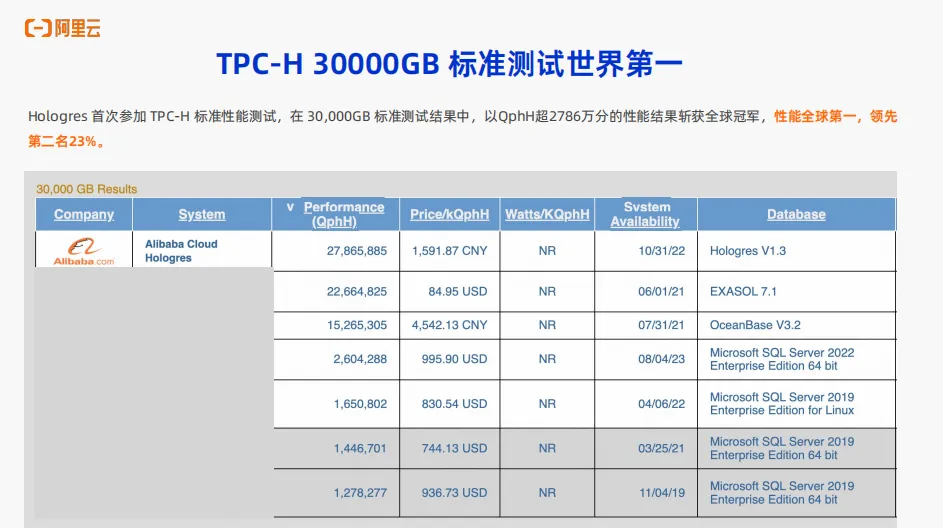
在去年Hologres首次参加了 TPCH 的标准性能测试。在 30000GB 标准测试的结果中,Hologres斩获了全球第一,领先全球第二名23%。证明Hologres的查询性能是毋庸置疑的。
3、Hologres VS ClickHouse:OLAP性能数倍提升
下面分享Hologres与同等的 OLAP 产品的一些对比,主要以 ClickHouse为主。
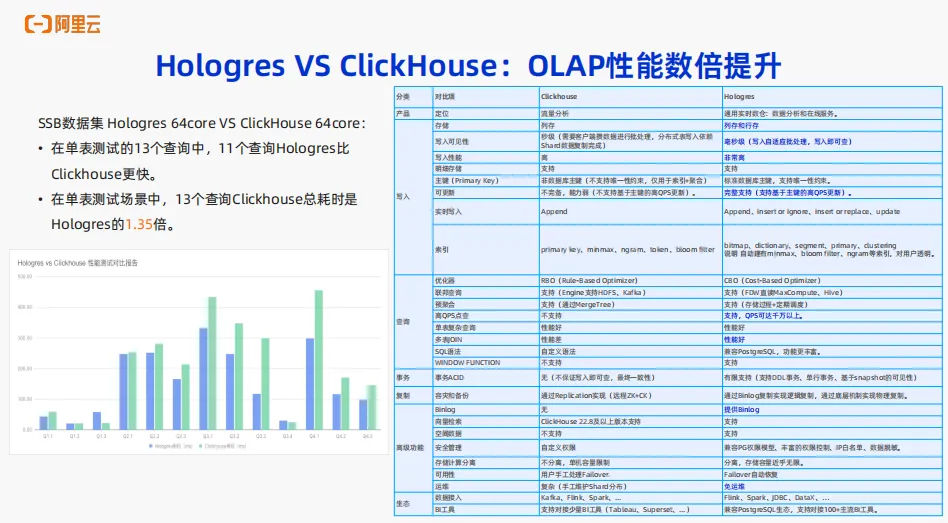
ClickHouse 更擅长的是做流量分析的场景。Hologres与ClickHouse对比有以下几方面。首先第一是性能方面,我们同样使用了 SSB 的数据集,相同的规格 64 core 实例规格来做对比。可以看到性能对比报告,Hologres在所有的查询当中,查询性能都比ClickHouse更快,这意味着Hologres的OLAP 性能相对ClickHouse更好更快。
另外简单介绍一下Hologres跟ClickHouse的一些区别。
-
ClickHouse 更多的定位是做流量分析的场景。Hologres 其实是通用的实时数仓,擅长的领域不仅是流量分析,也包括多维分析,各种 OLAP多维分析的场景,例如画像标签,实时监控等等各种 OLAP 的场景,同时也支持像HBase、 Redis 在线服务的场景存储。
-
ClickHouse 使用列式式存储,这里Hologres也可以使用列存来支撑OLAP场景。在数据的写入的时效性上,ClickHouse 因为需要对客户端做攒批处理,所以在写入的时效性上基本上都是秒级,而Hologres有自适应的批处理,可以做到毫秒级,数据写入就可以查。
-
数据的更新能力方面,ClickHouse其实是不支持完整的主键的能力的,不支持唯一键的约束。 OLAP 场景会有非常的数据更新、删除以及局部列更新,打宽、局部列更新这样的场景,ClickHouse 无法很好地支持。而Hologres有完整的主键语义,支持唯一性约束,可以在 OLAP 场景非常完整的支持像基于主键的更新删除、宽表打宽,局部列更新这样的场景。
-
在查询上,ClickHouse更多的是做大宽表的查询,而 Hologres 在查询的场景上不仅仅支持大宽表的查询,同时也支持像多表的Join,复杂的聚合分析等。像窗口函数Hologres也比ClickHouse支持的更多
-
另外在高级的企业级能力上,ClickHouse没有细力度权限、资源隔离等一系列的企业级高级功能。而Hologres不仅有各种丰富的权限控制,例如 IP 白名单、数据脱敏等等,也有资源隔离的机制,例如计算组实例、 Serverless Computing等,可以非常高效地满足企业的各种隔离的需求。
4、高性能的离线同步能力
下面介绍高性能数据同步能力。

Hologres 在底层与 MaxCompute 直接打通,可以直接查Max compute的盘古数据,相比于其他的产品查询性能更快。如果想要Maxcompute的数据直接导入到Hologres中也支持百万行数据的秒级同步。
上图是数据同步的一个性能对比结果:同样的数据集使用 TPCH 的数据集,分别使用公网copy、 VPC copy 以及 maxcomputer 写入的方式来做写入性能的对比。可以看到通过 maxcompute 制度写入的方式能够显著地提升写入的性能,数据的延迟基本上是在毫秒级。
简单分享一个直读的案例:右侧是某用户使用了MaxCompute直读 Hologres的一个反馈:没有用直读的时候, CPU 和延迟还有连接数都会消耗的比较高,使用了直读之后,延迟、连接 CPU 消耗等等都会有所下降。
5、高性能实时写入与更新
下面介绍Hologres的实时同步能力。

在 OLAP 的场景上很多的业务对数据的时效性有非常高的要求,Hologres内置了 Fixed plan的能力,可以达到非常高性能的实时写入与更新的能力。
先对Fixed plan做一个简单的介绍,例如insert on conflict 数据更新的一个SQL。如果没有用Hologres内置的 fixed plan 能力,可以看到plan 非常复杂:要实现数据更新的能力, 需要经过优化器的解析,协调器、查询引擎、存储引擎等多个组件,导致 SQL 最终的耗时其实变得非常高。如果用Hologres内置的 Fixed plan ,首先在plan 就会变得非常的简单,只有一个 fixed insert 的算子,这就意味着SQL不需要经过那么多的组件例如优化器、协调器等等,就可以直接查存储引擎的数据。
这里有一个标准的更新对比:使用不同的存储模式和 Fixed plan 的数据更新的性能对比。可以看到在使用了 fixed plan 之后,与没有使用 fixed plan 的性能相差几倍到几十倍。
另外 fixed plan 目前现在已经广泛地用在众多的业务当中,支持的场景也非常多,例如单行写入、多行写入、局部类更新、写入父表等等,可以满足业务的不同需求。
Hologres OLAP场景核心能力-开发体验篇
1、Hologres Binlog:全链路的实时开发体验,简化数仓分层
下面介绍Hologres如何通过Binlog的来简化数仓分层的开发效率问题。
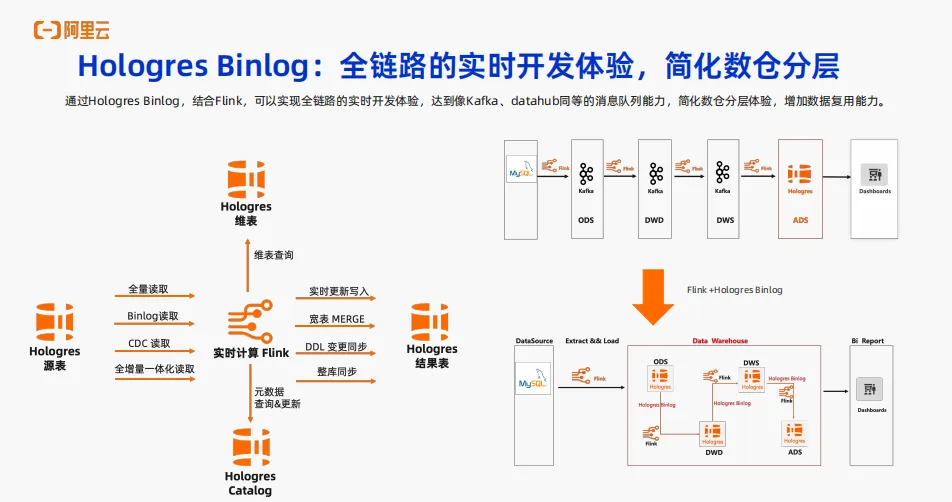
一般OLAP 场景上数据量非常多,数据链路较长,通常业务上会去做一定的数仓分层。传统的做法可能是Flink直接写到Kafka,然后 Flink 再消费 Kafka 的topic,通过这样的方式,最后把 ADS层写到数仓来服务上层业务。而Hologres提供 Binlog 能力, Hologres的 binlog 可以记录单表的 DML 变更记录。有了Hologres binlog后就可以通过 Flink 直接去读取Hologres binlog,然后实时读取数据的变更,达到数据分层的目的。以前是用Kafka,现在可以直接用 Flink + Hologres binlog 来做数仓分层,也可以达到像Kafka、 Datahub 同等的消息队列的能力。有了binlog,在 Hologres中一张表既可以做 Flink 的sink表,也可以做 Flink 的实时表,增加了数据复用的能力,同时也简化了数仓分层的体验。
2、Runtime Filter:自动优化大小表Join效率

首先第一是 Runtime filter。在 OLAP 场景有很多关联的场景,例如在画像分析的场景上需要使用用户的行为表跟用户的属性表做Join来计算用户的画像。用户的行为表通常是明细表,存储的数据量会比较多,属性表可能是小表,就会有大小表Join的场景。而 Runtime Filter 要解决的问题就是大小表 Join 的效率问题。
Runtime Filter的原理:传统上如果使用Join会有 build 端和 probe 端,如果大小表的数据量差异很大会导致 Join 时 IO 比较高。而Runtime Filter 就是在 Join 前会生成一个轻量的过滤器,会把Join 所需要的数据先过滤出,从而减少 Join 的数据量,以及减少数据在网络传输的量,有效地提升 Join 的性能。通过 Runtime Filter可以很好地提升大小表的 Join 效率。Runtime Filter是数据的底层能力,是引擎的底层能力,不需要做额外的设置就可以自动优化,自动使用。
简单分享Runtime Filter的一个效率问题,例如两个表,单个 Join 字段,开启了 Runtime Filter和不开启Runtime Filter的效率,可以看到基本上开启Runtime Filter后不管在 CPU 还是内存耗时上都比没有开启的更低。随着 Query 变得越来越复杂,例如在两个表Join,多表 Join 中有非常多个 Join 字段时,runtime filter 的能力更强。可以看到这里有两个 Join 字段,如果开启了Runtime Filter,在 CPU 的消耗上更加省 ,同时耗时也会比没有开启 Runtime Filter更高。
3、漏斗、留存等函数简化流量分析
下面介绍Hologres专用的一些流量函数。
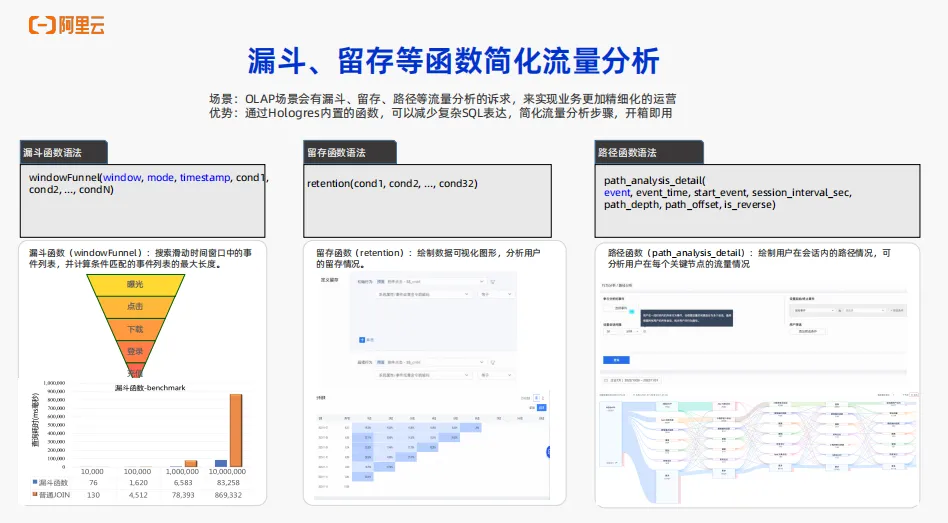
在 OLAP 的场景提到的画像,流量分析、行为分析等等,可能都需要对用户的一些行为路径做精细化分析,对此Hologres提供专门的函数。例如漏斗函数、留存函数、路径函数等等都可以满足流量分析的诉求,在业务上可以直接使用这些函数来满足业务更加精细化的运营需求。可能有一些 OLAP 的产品不能支持漏斗、留存还有路径这样的函数,常见的做法可能都需要用到开窗、 Join 等等非常复杂的 SQL 写法,才能满足业务需求。而在Hologres中如果要实现流量分析的诉求,可以直接使用漏斗函数、留存函数、路径函数这些内置的函数,开箱即可以用,不需要写复杂的 SQL 就能够满足业务的需求,同时也可以简化各种各样的流量分析步骤,达到非常好的性能。例如像这里漏斗函数的一个性能,之前没有漏斗函数时用户通常使用多表 Join 的方式,在漏斗函数后可以看到效率显著提升。
4、列式JSONB,提升半结构化数据分析与存储效率
下面介绍列式JSONB。

通常来说,例如日志数据、标签数据等等业务上可能有多维分析的诉求,会用 JSON 或者用 array 的方式存储数据。用 JSON 或者 array 的方式来做存储的好处是使用上可以灵活,可以随意加字段,缺点是性能可能不能满足业务的强需求。以上述一个 case 为例,有一个 JSON 的字段,JSON中嵌套了JSON。如果想要查某个 JSON 中某个 key 的value,需对这个 JSON 所有的 key 都去做一遍扫描,才能查到value,就会导致 IO 消耗特别高, CPU 利用率特别高,延迟也会变高。
Hologres支持 列式JSONB能力,在底层就可以把 JSON 的数据按列存储。按列存储的好处是想要去查某一个 key 时直接能查这个key,不需要把整个 json 的数据扫描出,可以有效地降低 IO 消耗以及CPU,从而提升查询性能。同时因为按列存储,可以非常有效地利用ORC压缩能力,让存储更加省。
分享一个使用JSONB的收益:某阿里客户,业务以前使用array存储标签数据,例如查询PV 这两张大表,延迟基本上都是秒级,但用 ;列式JSONB后延迟到了毫秒级,同时在存储上也下降百分之五六十,可以帮助帮助业务进一步的降本增效。
5、RoaringBitmap,助力高效画像多维分析

RB的主要应用场景是对数值类数据的去重和标记计算,例如要计算电商店铺的加购 UV ,直播中的成交UV、访问 UV 、APP 中的访问 UV 等场景。通常对于这种数值类的数据做精确去重时常见的做法有两种,一种是使用预聚合的方式,另外一种方式是使用明细表直接 count distinct 的方式。这两种方式各有优缺点,最大的缺点是使用预聚合的方式没有办法支持任意的周期查询。使用明细表的方式虽然在开发效率上可以灵活,但是在 QPS 上没有办法达到很高的 QPS ,而且 QPS 一旦高了后延迟会降低。
而通过Hologres RB 预聚合方案,可以支持任意周期、任意长周期的基数计算。这里有一个示例,以前计算 UV 时使用明细表和维表 Join 的方式来查UV,这里 unique 就是在计算UV,Unique product 也是在计算商品UV,可以看到如果查一天或者查几天的数据,它数据的时效性很好。但当把时间周期拉得更长,查询半年或者一年的数据,因为明细表的数据会特别大。页面上想要任意周期的查询后,它不能很好地满足业务的需求, IO 会变特别高,查询的效率也会变得特别低。使用RB 预聚合后,每天生成一个预聚合的结果表来构建RB,可以支持任一周期的查询。不管在时间维度上选什么样的周期力度, RB 每天都可以构建好,可以显著降低查询的延迟。
这里也有一个RB 和Join效率的对比。可以看到在支持像 7 天、 30 天、 90 天,还有 100 天这种随着时间越来越长的一个即席查询时,RB 的效率显著比Join更高。这里只是单秒的查询,像 180 天Hologres是毫秒级,而原来 Join 的方式是秒级。如果把并发加的更高,那原来的 Join方式的效率可能会更低,而RB 的方式不会,因为它单个 SQL 的查询足够的快,所以它的并发能够支持更高。
6、Hologres丰富的生态对接

Hologres兼容 PG 的生态,只要能连接 PG 的开发工具或者是 BI 工具都可无缝的对接Hologres,例如 DataV、Quickbi、 Metabase、PowerBI等等都可以无缝对接Hologres。像市面上主流的一些开发工具、BI 工具也可以直接对接,就可以开箱直接使用,无需要再做额外的开发。生态上也更加兼容,可以满足业务的不同需求。
Hologres OLAP场景核心能力-高可用篇
1、计算组(Warehouse)实例:资源隔离、弹性、自动切流
随着技术的产品对业务的支持变多,不同的业务可能有不同的负载。那如何做有效的隔离?

Hologres有 Warehouse计算组实例的功能。通过计算组实例可以有效地隔离不同的负载,例如在 Warehouse 实例内可以分不同的计算组,可以根据业务的负载来分,也可以根据业务不同的来源分。例如根据负载来分,可以把写入可以分成离线写入计算组、实时写入计算组,有效地避免写入之间的相互影响。在查询上也可以根据不同的业务来分不同的计算组,例如可以分为 OLAP 查询计算组和在线服务计算组,就可以有效地把查询隔离开。不同的计算组之间完全隔离,写入与查询之间相互不影响,写入写入之间不影响,查询与查询之间不影响,可以做到非常干净的隔离。在对外上只有一个endpoint,可以实现业务的自动切流。例如当某一个计算组负载较高或者遇见其它等等问题,可以快速将流量切到其他的计算组,无需做应用的各种变更。同时可以对计算组做单独的扩缩容,例如OLAP计算组可能要上一个新业务,并发QPS 也更高,那我们就可以对 OLAP 计算组做单独的扩容,以满足业务的快速需求。
2、Serverless Computing:提供大作业隔离与弹性处理
在 OLAP 场景上会有一些大型的任务,例如大型的写 DML 任务,做 ETL 处理等等。
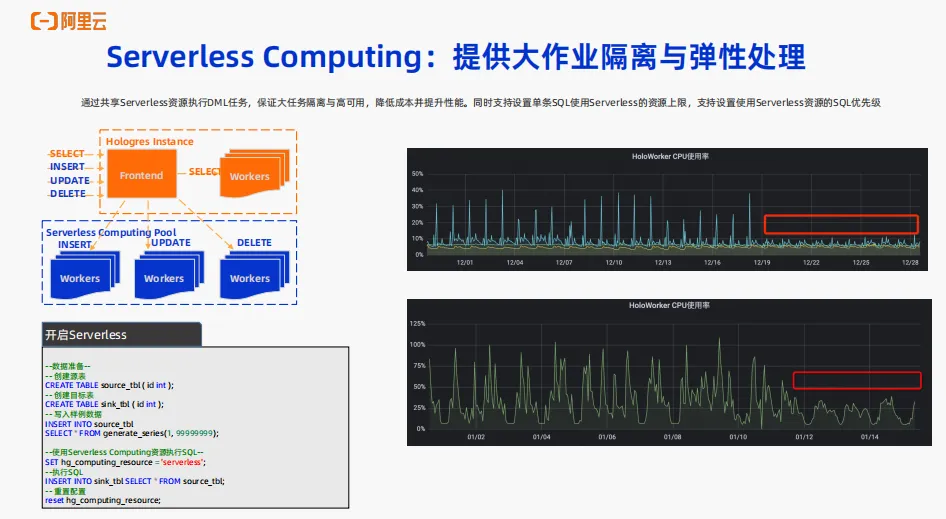
Hologres提供Serverless Computing 功能。Serverless Computing是Hologres会内置一个 service pool,可以把DML 的任务路由到Hologres内置的Serverless Computing Pool 上,有效地把本实例的大任务做一个隔离,本实例中只需要跑一些小的任务,而大的任务全部由 Hologres共享的 Serverless Pool 来执行,不仅可以降低成本,同时也可以提升性能。本地的实例可能规格比较小,例如32core、 64 core,而Hologres的 Serverless Pool 是一个大的共享池子,资源会更多,会使得DML 的效率更快。
例如这里分享用户使用反馈:这个业务是一个有周期性处理数据的场景,每天晚上定时的调度任务来对数据做调度,白天是查询,白天查询的负载不是特别高。在没有用Serverless功能前,为了支持晚上的大任务周期性调度不得不将实例资源扩大规模,使用了Serverless Computing功能后,把这些周期性的调度任务完全由 serverless 来承载,本实例就只在白天承接查询的流量,这样业务可以将实例资源进行缩容,可以把资源很好地节约下来,进一步地帮助节省成本。
开启Serverless 功能的语法非常简单,只需要使用一个GOC,就可以把指定的 DML 任务路由到Serverless Pool上做执行。
典型客户案例
1、小红书:替换ClickHouse,亿级多维分析实践

小红书以种草笔记内容的方式被大家所知道。这个客户是小红书搜索推荐团队,其主要的场景是对首页的客户做人群精准的、高效的匹配,然后为用户推荐最精准的内容。典型的 OLAP 场景包括实时的指标告警、实时的指标分析等等。原来他们使用开源自建的ClickHouse来承载 OLAP 的分析业务。随着业务的发展,他们的痛点变得越来越明显:
-
笔记的数据非常多,自建ClickHouse 存储只能存 7 天以内的数据,超过 7 天存储就会爆炸。因为ClickHouse不是存储计算分离的架构,存储会随着数据量变多爆炸。
-
查询慢,通常ClickHouse 只能查小于 3 天的数据。如果需要对用户做更精准的匹配,需要更长时间范围内的数据,ClickHouse没办法很好地支持。
-
ClickHouse 没有主键,当ClickHouse Failover后不能自动重追数据,数据有正确性问题。没有主键就没有数据的唯一性,容易出现数据的正确性问题。
-
同时自建的ClickHouse运维也越来越复杂, 需要有专门的人去运维,运维成本变得特别高。
于是小红书将自建的ClickHouse替换成Hologres,原有的架构不变,只是把ClickHouse 替换成Hologres。Hologres对业务上带来的显著的收益是多、快、省。
-
用户不需要自己运维一套ClickHouse的集群, Hologres免运维,可以显著地节省人力成本。
-
因为是存储计算分离的架构,Hologres不仅可以支持 7 天,也可以支持更长周期的数据,例如 15 天更长周期等等。如果存储不够,可以直接按需扩缩容,同时在查询性能上也比ClickHouse更快
-
Hologres有完整的组件,可以实现业务的更新、去重逻辑,即使上游挂掉也可以自动地追数据,不会出现正确性问题。
2、乐元素:替换Hive+Presto构建高性能游戏运营分析平台

乐元素是一个游戏公司,著名的产品有开心消消乐、海滨消消乐等等。乐元素的 OLAP 分析平台支持的场景是用户的行为分析、活动分析、留存分析等等常见的游戏分析场景。技术上通过 Hive + Presto 的方式来支撑业务的分析需求。但是随着业务的快速迭代, Hive + Presto没有办法很好地支持实时的能力,运维和性能等方面都没有办法很好地满足需求。同时乐元素有非常多的用户行为分析、流量分析的诉求,Hive + Presto没有办法很好地支持留存、漏斗这些的场景,没有专门的函数,不得不自己手写 SQL 支持业务,就会导致业务效率变得特别慢。
于是乐元素从Hive + Presto迁移到Hologres,运营效率得到了显著的提升:
-
Hologres有专门的留存漏斗和路径的函数,能满足游戏行业的用户的行为分析查询效率,相比原来的sql提升近 10 倍。
-
另外稳定性也得到了提升,以前Hive + Presto两个技术产品,只要业务有高峰期时就不断去扩缩容,对于人运维的压力比较大。而Hologres有存储、计算分离的架构,可以根据业务的需求动态的扩缩容、弹性扩缩容,极大地避免运维成本,提升弹性的能力
-
成本节省。相比于原来的Hive + Presto自建,现在通过Hologres之后,整体的成本节约了50%,同时人力成本也节省了近几十万元。
以上就是今天所有的分享,希望大家能够通过Hologres OLAP 能力支持公司更多的 OLAP 的分析场景
原文地址:https://blog.csdn.net/weixin_48534929/article/details/140142989
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!