大模型常用微调方法LORA和Ptuning的原理
Lora方法的核心是在大型语言模型上对指定参数增加额外的低秩矩阵,也就是在原始PLM旁边增加一个旁路,做一个降维再升维的操作。并在模型训练过程中,固定PLM的参数,只训练降维矩阵A与升维矩阵B。
Ptuning方法的核心是使用可微的virtual token替换了原来的discrete tokens,且仅加入到输入层,并使用prompt encoder(BiLSTM+MLP)对virtual token进行编码学习。
这两种方法都是为了在保持模型核心参数不变的前提下,以较低的计算和存储成本,实现模型的有效自定义和优化。以下详细解释这两种方法的核心机制和用途。
LoRA (Low-rank Adaptation)低阶自适应参数高效微调
LoRA 的核心思想是通过向预训练语言模型(PLM)中的特定层(通常是自注意力层和/或前馈层)添加低秩矩阵来进行微调。这种方法的具体步骤包括:
- 选择层:确定哪些层的参数需要通过添加低秩矩阵进行调整。
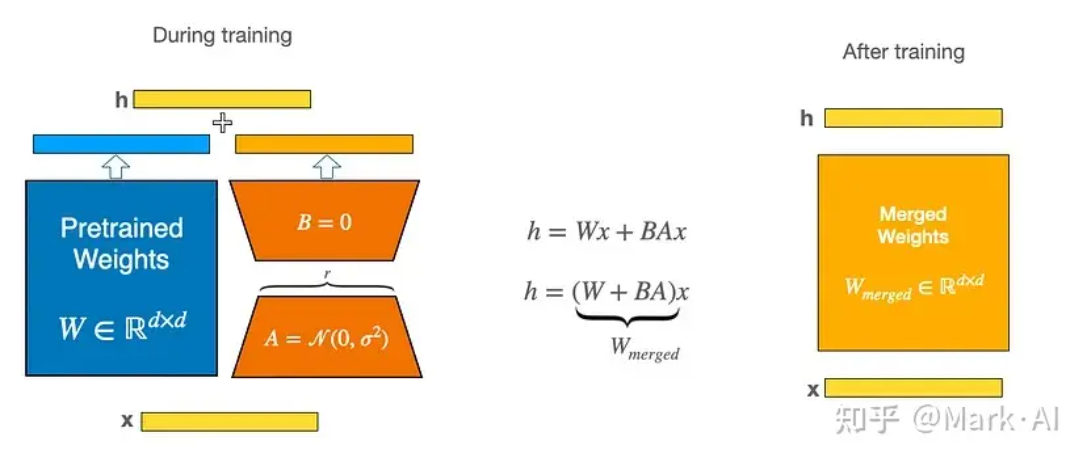
- 降维和升维:引入两个小矩阵 ( A A A ) 和 ( B B B )。原始的参数矩阵 ( W ) 被改写为 ( W + A × B W + A \times B W+A×B ),其中 ( A ) 和 ( B ) 分别是降维和升维矩阵。这两个矩阵的积形成了一个低秩矩阵,用来近似参数矩阵的修改。
- 固定原始参数:在训练过程中固定预训练模型的原始参数 ( W ),只更新 ( A ) 和 ( B )。这样可以显著减少需要训练的参数数量,降低训练成本。
通过这种结构,LoRA 允许用户针对特定任务进行高效的模型调整,而无需重新训练庞大的原始模型。
Ptuning
Ptuning 是另一种优化预训练语言模型的技术,它通过引入可微分的虚拟 token 来增强模型的输入表示。其核心步骤包括:
- 虚拟 Token:在输入序列中插入特殊的可训练虚拟 token,这些 token 旨在在训练过程中学习到有用的表示。
- Prompt Encoder:使用一种特殊的编码器,如双向长短期记忆网络(BiLSTM)加上多层感知机(MLP),来编码这些虚拟 token。
- 集成到模型:这些经过编码的虚拟 token 被加入到模型的输入层,与原始的输入 token 一起参与到后续的处理中。
Ptuning 方法利用可训练的 prompt 来调整模型对特定任务的适应性,而不改变模型的主体结构。这种方法尤其适合于少量数据的场景,因为它允许模型通过少量的调整来快速适应新任务。
这两种技术各有优势,LoRA 更侧重于通过低秩结构调整内部参数,而 Ptuning 则是通过增强输入表示来提升模型性能。两者都是当前自然语言处理领域中用于提升模型表现和适应性的重要工具。
一些微调的最佳实践包括使用强正则化、使用较小的学习率和少量的epochs。一般来说,像卷积神经网络用于图像分类的神经网络并不完全微调,这样做很昂贵,可能导致灾难性遗忘。我们只微调最后一层或最后几层。
对于LLM,我们使用一种类似的方法,称为参数高效微调(PEFT)。其中一种流行的PEFT方法是低秩适应(LoRA),LoRA 是低秩适应 (Low-Rank Adaptation) 的缩写,其是一种用于微调深度学习模型的新技术,它在模型中添加了少量可训练参数模型,而原始模型参数保持冻结。LoRA 是用于训练定制 LLM 的最广泛使用、参数高效的微调技术之一。
LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。
LoRA 将权重矩阵分解为两个较小的权重矩阵,如下所示,以更参数有效的方式近似完全监督微调。

在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 原理对应伪代码
LoRA 的实现相对简单。我们可以将其视为 LLM 中全连接层的修改前向传递。在伪代码中,如下所示:
import torch
import torch.nn as nn
import math
input_dim = 768 # 输入维度,例如预训练模型的隐藏层大小
output_dim = 768 # 输出维度,例如层的输出大小
rank = 8 # 低秩适应的秩 'r'
W = ... # 预训练网络的权重矩阵,形状为 input_dim x output_dim
# 定义 LoRA 的权重矩阵 A 和 B
W_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA 的权重 A,形状为 input_dim x rank
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA 的权重 B,形状为 rank x output_dim
# 初始化 LoRA 的权重
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5)) # 使用 Kaiming 均匀分布初始化 W_A
nn.init.zeros_(W_B) # 使用零初始化 W_B
def regular_forward_matmul(x, W):
h = x @ W # 常规矩阵乘法
return h # 返回结果
def lora_forward_matmul(x, W, W_A, W_B, alpha=1.0):
h = x @ W # 常规矩阵乘法
h += x @ (W_A @ W_B) * alpha # 加上缩放的 LoRA 权重的矩阵乘法结果
return h # 返回结果
在上面的伪代码中,alpha 是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这可以平衡预训练模型的知识和新的特定于任务的适应 - 默认情况下,alpha 通常设置为 1。另请注意,虽然 W A 初始化为小的随机权重,WB 初始化为 0,因此
ΔW = WA WB = 0 < /span> 在训练开始时,意味着我们用原始权重开始训练。
LORA微调示例数据集代码
为了实现基于 LaMini-instruction 数据集的 LoRA 微调,以下是每一步的详细代码示例:
第 1 步 — 加载 LaMini 指令数据集 使用 Huggingface 中的 load_dataset
from datasets import load_dataset
# 加载 LaMini 指令数据集
dataset = load_dataset("tatsu-lab/lamini-instruction")
第 2 步 — 加载 Dolly Tokenizer 并使用 Huggingface 进行建模
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载 Dolly Tokenizer
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b")
# 加载 Dolly 模型
model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-12b")
第 3 步 — 数据准备 — Tokenize, 分割数据集并准备批处理
from transformers import DataCollatorForLanguageModeling
from sklearn.model_selection import train_test_split
# 定义数据处理函数
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=512)
# 对数据集进行分词处理
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 分割数据集为训练集和验证集
train_dataset, eval_dataset = train_test_split(tokenized_datasets["train"], test_size=0.1)
# 准备数据批处理
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
第 4 步 — 配置 LoRA 并获取 PEFT 模型
我们需要定义 LoRA 的低秩矩阵,并将其应用到模型中。这里使用 PEFT(Parameter Efficient Fine-Tuning)库来实现。
from peft import get_peft_model, LoraConfig
# 定义 LoRA 配置
lora_config = LoraConfig(
r=8, # 低秩矩阵的秩
lora_alpha=16, # LoRA 的缩放因子
target_modules=["q_proj", "v_proj"], # 需要应用 LoRA 的目标模块
lora_dropout=0.1, # dropout 概率
)
# 获取 PEFT 模型
peft_model = get_peft_model(model, lora_config)
第 5 步 — 训练模型并保存
使用 Trainer 进行模型训练,并保存微调后的模型。
from transformers import Trainer, TrainingArguments
# 定义训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
)
# 定义 Trainer
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
)
# 训练模型
trainer.train()
# 保存模型
trainer.save_model("./finetuned_model")
第 6 步 - 使用微调模型进行预测
加载微调后的模型并进行预测。
# 加载微调后的模型
finetuned_model = AutoModelForCausalLM.from_pretrained("./finetuned_model")
# 进行预测
input_text = "Your custom question here."
inputs = tokenizer(input_text, return_tensors="pt")
outputs = finetuned_model.generate(inputs["input_ids"], max_length=100)
# 解码并输出结果
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
以上是完整的 LoRA 微调流程代码示例。通过这些步骤,我们可以加载数据集、配置模型、进行微调,并使用微调后的模型进行预测。这种方法既适用于 LaMini-instruction 数据集,也适用于自定义企业 QnA 数据集。
原文地址:https://blog.csdn.net/qq_36372352/article/details/140184307
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!