【CVPR2023】《A2J-Transformer:用于从单个RGB图像估计3D交互手部姿态的锚点到关节变换网络
这篇论文的标题是《A2J-Transformer: Anchor-to-Joint Transformer Network for 3D Interacting Hand Pose Estimation from a Single RGB Image》,作者是Changlong Jiang, Yang Xiao, Cunlin Wu, Mingyang Zhang, Jinghong Zheng, Zhiguo Cao, 和 Joey Tianyi Zhou。他们来自华中科技大学、阿里巴巴集团、新加坡科学、技术和研究局(A*STAR)的前沿人工智能研究中心(CFAR)以及高性能计算研究所(IHPC)。
摘要
3D交互手部姿态估计(IHPE)是一个挑战性的任务,因为手部存在严重的自遮挡和相互遮挡,两只手的外观模式相似,以及从2D到3D的病态关节位置映射等问题。为了解决这些问题,作者提出了A2J-Transformer,这是一种基于Transformer的非局部编码-解码框架,用于改进A2J(一种最先进的基于深度的单手3D姿态估计方法),以适应交互手部情况的RGB域。A2J-Transformer的主要优势包括:局部锚点通过自注意力机制建立全局空间上下文感知,以更好地捕获关节的全局线索;每个锚点被视为可学习的查询,具有自适应特征学习能力,以提高模式拟合能力;锚点位于3D空间而非2D,以利用3D姿态预测。
主要贡献
- 首次将A2J从深度域扩展到RGB域,用于单RGB图像的3D交互手部姿态估计,并取得了有希望的性能。
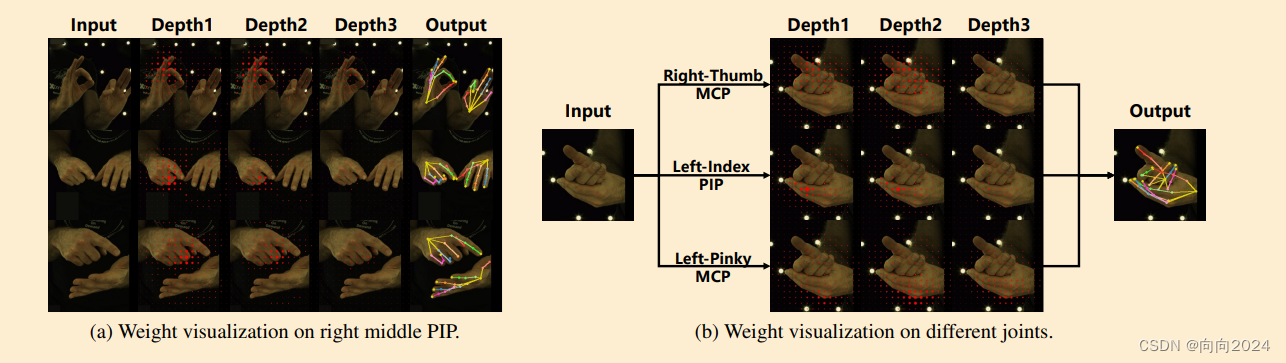
- 通过Transformer的非局部自注意力机制和自适应局部特征学习,使A2J的锚点能够同时感知关节的局部细节和全局上下文。
- 提出了将锚点设置在3D空间而不是2D空间的方法,以便于基于单目RGB信息解决2D到3D的病态姿态提升问题。
相关工作
论文回顾了3D手部姿态估计的相关研究,包括基于模型的方法和无模型(model-free)方法,以及基于Transformer架构的方法。
方法
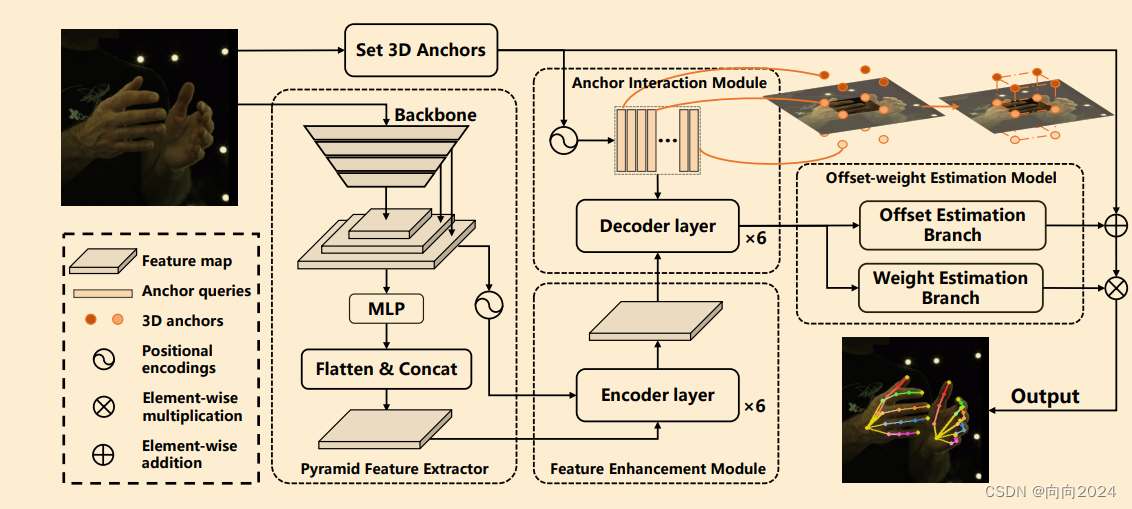
A2J-Transformer由三个主要部分组成:特征金字塔提取器、锚点细化模型和锚点偏移权重估计模型。特征金字塔提取器使用ResNet-50作为骨干网络来提取输入RGB图像的金字塔特征。锚点细化模型包含特征增强模块和锚点交互模块,用于增强图像特征并建立锚点之间的交互。锚点偏移权重估计模型用于估计每个锚点相对于每个手部关节的3D偏移和权重。
实验
作者在InterHand2.6M、RHP、NYU和HANDS 2017数据集上进行了实验。结果表明,A2J-Transformer在InterHand2.6M数据集上取得了最先进的无模型(model-free)性能,并且在RHP数据集上展示了良好的泛化能力。此外,作者还对A2J-Transformer的不同组件进行了消融研究,以验证其有效性。
结论
A2J-Transformer是一种有效的3D单目RGB交互手部姿态估计方法,它结合了局部细节和全局上下文信息,并使用3D锚点来更好地拟合深度信息和估计准确的3D坐标。作者计划在未来的工作中尝试表示锚点的运动,并将方法扩展到基于模型的区域。
原文地址:https://blog.csdn.net/weixin_49090702/article/details/137993723
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!