多模态—图文匹配
可能最近大家已经发现了chatgpt可以根据自己的描述生成图片,其实这就是一个图文匹配的问题,可以理解为这是一个多模态的问题。
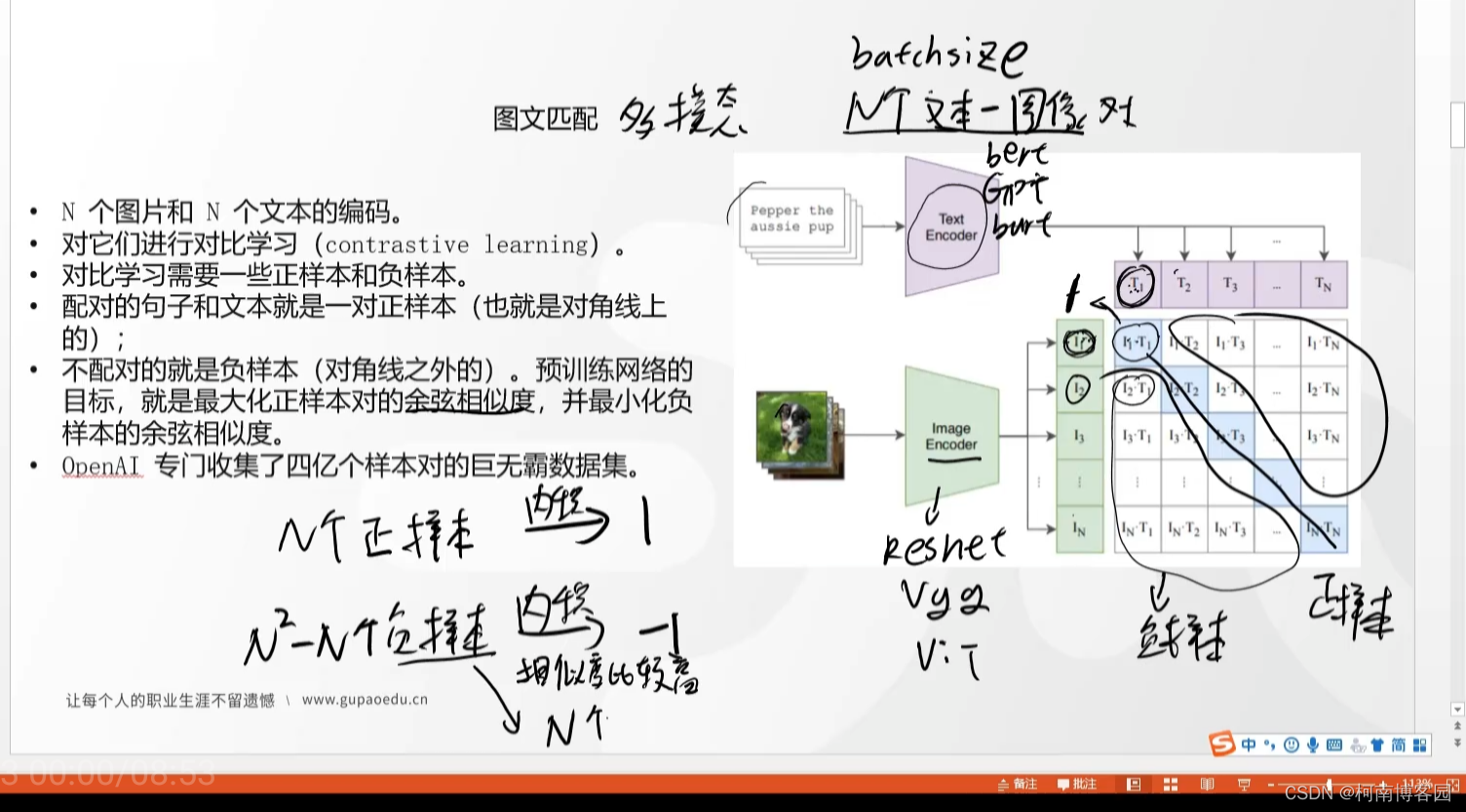
在模型训练时我们需要N个图片和N个文本对进行训练,文本通过text encoder形成文本语义向量,text encoder可以采用BERT,GPT,Bart等,图片也需要通过image encoder进行转化为图片向量,可以采用resnet,Vgg,ViT等。
如下图所示,其对角线表示文图匹配对,我们作为正样本1,其余均是负样本-1,这里可以知道正样本是N个,负样本是N*N-N个,当N足够大时,正负样本数据不均衡问题会很明显,怎么做呢,我们需要对负样本采样。
采样的策略是随机,还是顺序?其实最好的方法应该是采样相似度较高的负样本 这样增加训练难度,可以让模型达到更好的效果。
余弦范围是-1~1,训练模型目的,是为了让正样本最大化余弦相似度,负样本最小化余弦相似度。
原文地址:https://blog.csdn.net/qq_51925699/article/details/142709107
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!