在线深度学习:爱奇艺效果广告分钟级模型优化
01#
背景
在效果广告投放场景中,媒体侧需要准确衡量每次请求的价值,模型预估值在广告竞价中扮演着核心角色。模型预估精度的提升,是改善媒体侧变现效率、提升广告收益的核心技术驱动力。
此前,爱奇艺效果广告预估模型为小时级模型,从广告投放到效果反馈线上模型有数个小时的延迟。从23年下半年开始,我们致力于从模型时效性优化的方向提升模型能力,将小时级模型升级为分钟级在线深度学习(ODL),在爱奇艺流量取得了6.2%的收入提升。与小时级等离线模型相比,ODL的应用面临着来自工程和效果两方面的挑战,本文总结了ODL落地中遇到的挑战、思考及相应的解决方案。
02#
ODL挑战及解决方案
从整个系统架构来看,ODL的落地需要重点关注如下几个要求和问题:
工程框架:
稳定性:流式链路鲁棒性要求较高,需避免积压或中断;
时效性:推理端模型更新应具备较高的时效性;
兼容性:框架需有良好的灵活性,能够兼容离线/在线、pCTR/pCVR等模型。
模型效果:
解决实时样本延迟反馈问题;
模型灾难遗忘问题;
样本独立同分布要求。
工程框架
1.服务鲁棒性
ODL简要流程如下图所示,为了流式服务鲁棒性,关键节点进行了相应的优化:
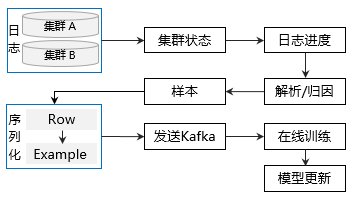
图1
a.样本持续稳定输出
在线样本每5分钟生产1个批次。为了从源头保证整个链路正常运转,样本的基础数据源——基于数据湖特征快照,部署了两个集群的高可用方案,样本生产模块能够在集群服务异常时自动切换。
b.模型高效训练
ODL初版上线时,每条样本序列化为json类型发送至Kafka,导致下游分布式训练环节存在大量解析、对齐特征的操作,CPU负载上限仅40%,模型训练效率较低。为了避免Kafka样本积压,只能增加并行训练节点,但异步训练场景中,训练节点增加容易带来梯度过期问题。
为了解决问题,通过在样本发送至Kafka时直接序列化为tensorflow原生支持的Example类型,在同资源下,将Kafka消费QPS上限提升了10倍,CPU负载从40%提升至100%,解决了ODL训练效率瓶颈问题,同时大幅减少分布式训练节点数。
2.模型更新时效性
a.模型训练和导出
天级/小时级等离线训练任务一般是在训练任务完成后,由chief节点导出模型文件。但对于ODL任务来说,chief/worker节点需要持续不断地接收新的样本,因此需要对于evaluator节点进行改造,以在满足batch_size增量要求和10分钟的间隔要求后,导出新版模型。
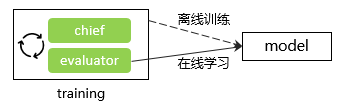
图2
b.模型部署
模型推理出于灾备和性能考虑,需进行多地、多机房部署。为提高模型更新效率,首先上线了多地机房并行更新,但这也引入了新的性能问题:多地机房数千个容器节点同时从S3下载模型时会遇到速度瓶颈,为了解决该问题导致的模型更新瓶颈,通过icache功能实现机房内P2P分发,降低S3服务压力。
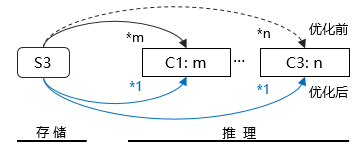
图3
3.框架灵活性
a.兼容不同场景
为保证模型效果(详见02-模型效果),ODL模型每天使用天级模型参数进行初始化,故调度框架在设计时对于天级/小时级/在线模型训练应具备较好的兼容性。同时调度框架支持自定义归因窗口,以兼容不同模型所需求的差异化正样本回收。
b.灾备处理
在监控和灾备处理方面,不仅需要关注服务的执行进度,同时必须对于线上服务质量(样本相关指标/离在线模型预估指标)进行监控。若线上模型学偏(如AUC/预估偏差异常),自动回退至当天warm start版本。
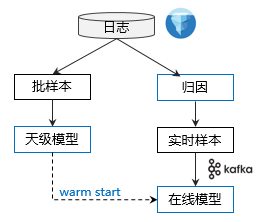
图4
模型效果
1.延迟反馈问题
训练样本的label准确性对于模型学习效果有着直接的影响。
首先,即使样本中混杂比例极低的label冲突样本,仍会导致模型效果严重退化。
其次,在线训练对于样本时效性要求也比较高,从而能够快速感知用户/广告/上下文的变化。
因此,ODL样本需要在准确性和时效性中进行平衡。在实践中进行了如下几点优化:
离线样本:如2.1.3所述,构建天级样本,label准确性高,训练天级模型作为当天ODL模型基线。
ODL样本:首先让曝光日志等待一段时间(归因窗口),归因窗口结束后,发送1条样本至Kafka。若归因窗口内回收到点击,则标记为正样本,反之为负样本。
PU-loss思想:若点击在归因窗口外回收到,且归因时长在有效窗口范围内,则再次发送1条正样本,但是该样本会进行特殊标记,对于此类样本,借鉴了PU-loss思想,在交叉熵损失基础上进行调整,用于修正此前发送的负样本对于损失函数的影响。
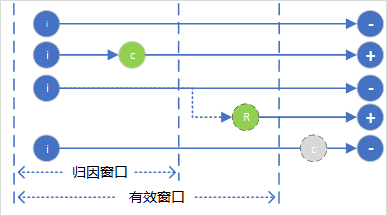
图5
2.模型灾难遗忘问题
实时样本顺序发送至Kafka,与完整天全局样本相比,局部的实时样本分布可能会存在差异。为了避免ODL模型被实时样本带偏,ODL模型借鉴了蒸馏学习思想:将天级模型和ODL模型预估值计算的交叉熵损失作为soft loss加入到原损失函数中,约束模型效果,避免ODL模型严重偏离。
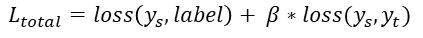
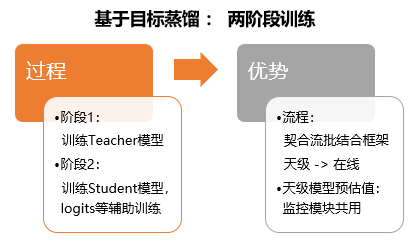
图6
3.样本独立同分布要求
独立同分布是机器学习的基础要求,对于"hour"特征来讲,天级样本能够覆盖24个取值并充分打散,但ODL样本由于顺序到达,hour特征短时间内仅有一种取值,影响模型泛化性。为此,针对hour特征,天级模型正常训练和更新权重,而在ODL模型训练时进行冻结,使用天级模型训练好的权重但不进行更新。
03#
总结
本文介绍了我们在ODL方案落地中遇到的问题以及实践的解决方案。目前,爱奇艺效果广告的点击率预估(pCTR)、转化率预估(pCVR)等核心稀疏大模型均已完成在线学习升级,模型时效性整体提升10倍以上,助力效果广告收入进一步提升。
远期,在ODL框架基础上,我们也在持续优化行为序列、多模态等信息在预估模型中的应用,这类信息的融合,在模型训练和高效更新等方面带来了新的挑战,探索实践仍在持续进行中,后续有机会再与大家分享。
参考资料:

也许你还想看
原文地址:https://blog.csdn.net/weixin_38753262/article/details/142836977
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!