LLM之RAG实战(四十二)| 如何在LlamaIndex和LangChain中正确选择RAG开发框架

大型语言模型 (LLMs) 是这个时代最新兴的 AI 技术之一。早在 2022 年 11 月,OpenAI 就发布了自己的生成式 AI 聊天机器人 ChatGPT,当时引起了很大的轰动。之后不久,各大企业和高校纷纷推出自己的大模型,然而,除了开发大模型之外,企业对大模型的应用开发需求也开始爆发,这导致了对大模型工具/框架的需求激增,这些工具/框架有助于 Gen AI 模型的开发、集成和管理。
目前有两个突出的框架处于领先地位:LlamaIndex 和 LangChain,这两个框架的目标是帮助开发人员创建自己的自定义LLM应用程序。这些框架中的每一个都有自己的优点和缺点。本文将揭示 LlamaIndex 和 LangChain 之间的主要区别,帮助用户为特定用例选择正确的框架。
一、LlamaIndex 简介
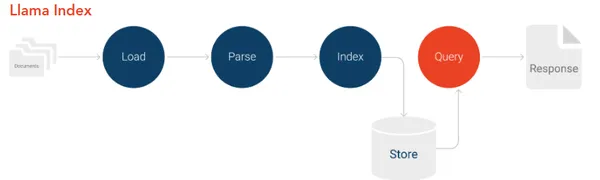
LlamaIndex 是一个专为RAG开发的应用框架,旨在让LLMs根据用户自定义数据进行索引和查询。它支持通过各种来源(如结构化(如关系数据库)、非结构化数据(如 NoSQL 数据库)和半结构化数据(如 Salesforce CRM 数据))的连接数据。
1.1 LlamaIndex工作原理
LlamaIndex 促进了 LLMs应用级定制化开发,它获取您的专有数据并将其嵌入到内存中,以便模型在提供基于上下文的响应方面逐渐变得更好。LlamaIndex 将大型语言模型转变为领域知识专家;可以充当 AI 助手或对话聊天机器人,根据事实来源回答您的查询(例如,包含业务特定信息的 PDF 文档,只有销售副总裁才能回答)。
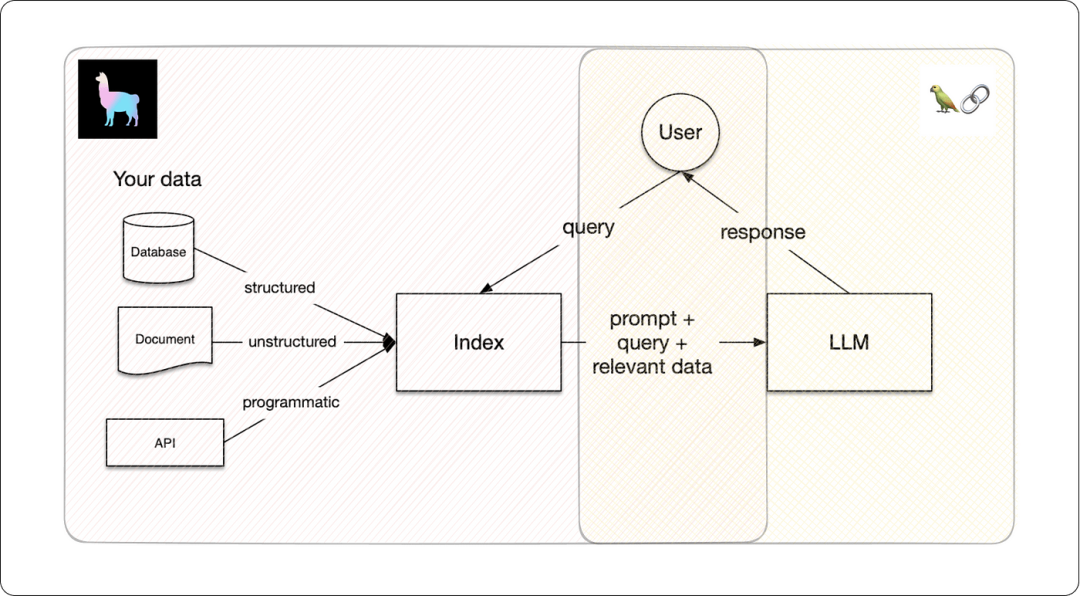
为了LLMs基于专有数据进行定制,LlamaIndex 使用了一种称为检索增强生成 (RAG) 的技术。RAG主要由两个关键阶段组成:
-
索引阶段:将专有数据有效地转换为向量索引。在索引阶段,数据被转换为具有语义含义的向量嵌入或数字表示。
-
查询阶段:在此阶段,每当查询系统时,都会以信息块的形式返回语义相似度最高的查询。这些信息块,加上原始的提示查询,被发送到 LLM 以获得最终响应。在这种机制的帮助下,RAG 可用于生成高度准确和相关的输出,否则LLMs基础知识是不可能实现的。
1.2 LlamaIndex 入门
首先,要开始安装 llama-index:
pip install llama-index需要 OpenAI API 密钥才能使用 OpenAI LLM的 .获得密钥后,将其设置为.env文件,如下所示:
import osos.environ["OPENAI_API_KEY"] = "your_api_key_here"
关于LlamaIndex的更多示例可以参考:https://docs.llamaindex.ai/en/stable/
关于llamahub的更多示例可以参考:https://llamahub.ai/
1.3 🦙使用 LlamaIndex 构建 QnA 应用程序
为了演示 LlamaIndex 的功能,我们使用 QnA 应用程序代码进行演练,该应用程序可以根据自定义文档回答查询。
安装相关包
pip install llama-index openai nltk接下来,使用 LlamaIndex 的函数SimpleDirectoryReader 来加载docs目录的文档并开始构建索引:
from llama_index.core import (VectorStoreIndex,SimpleDirectoryReader)# Define the path inside SDR function and then build an indexdocuments = SimpleDirectoryReader("docs").load_data()index = VectorStoreIndex.from_documents(documents,show_progress=True)
查询索引并检查响应:
# Query enginequery_engine = index.as_query_engine()response = query_engine.query("If i miss my assignments and projects,what grade and percentage will i end up with?")print(response)

查询引擎将搜索数据索引,并返回相关代码片段作为响应。
我们也可以通过修改函数将这个查询引擎变成一个有内存的聊天引擎:
chat_engine = index.as_chat_engine()response = chat_engine.chat("If i miss my assignments and projects,what grade and percentage will i end up with?")print(response)follow_up = chat_engine.chat("And if i only miss my projects,then what grade would i get?")print(follow_up)
若要避免每次都重新生成索引,可以将其保存到磁盘:
index.storage_context.persist()稍后再加载:
from llama_index.core import (StorageContext,load_index_from_storage,)storage_context = StorageContext.from_defaults(persist_dir="./storage")index = load_index_from_storage(storage_context)
上面的代码是部署到huggingface spaces的 QnA 聊天机器人 Gradio 应用程序的一部分。源代码和数据集可在[此处](https://huggingface.co/spaces/Suhaib-88/ChatbotDeploy/tree/main)获得。
二、LangChain简介

LangChain是另一个用于LLMs基于自定义数据源构建定制的框架。LangChain可以连接来自各种来源的数据,如关系数据库(如表格数据)、非关系数据库(如文档)、编程源(如API),甚至是自定义知识库。
LangChain利用了一种链的机制,链本身不做任何事情,只是把上一步输出与下一步输入串起来。
2.1 LangChain的工作原理

2.2 LangChain入门
安装LangChain软件包
pip install langchain 在本 LangChain 教程中,我们将使用 cohere API 密钥。使用 .env 文件中的 API 密钥设置 cohere 环境变量:
import osos.environ["cohere_apikey"] = "your_api_key_here"
LangChain的更多应用,请参考:https://python.langchain.com/v0.2/docs/introduction/
Langchain Hub的更多应用,请参考:https://smith.langchain.com/hub
2.3 🦜🔗使用 LangChain 构建 QnA 应用程序
为了实时演示 Langchain 的功能,我将进行代码演练,介绍如何开发一个 QnA 应用程序,该应用程序可以根据自定义文档回答查询。
第一步是安装所有依赖项:
pip install langchain cohere chromadb ## instead of openai's LLM we'll' go for cohere然后加载并创建文档数据的索引。我们还将使用相干嵌入生成嵌入:
from langchain.document_loaders import OnlinePDFLoaderfrom langchain.vectorstores import Chromafrom langchain.embeddings import CohereEmbeddingsfrom langchain.text_splitter import RecursiveCharacterTextSplitterloader = OnlinePDFLoader(document)documents = loader.load()# Initialzing Text Splittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=chunksize,chunk_overlap=10,separators=[" ", ",", "\n"])# Intializing Cohere Embdeddingembeddings = CohereEmbeddings(model="large", cohere_api_key=st.secrets["cohere_apikey"])texts = text_splitter.split_documents(documents)global dbdb = Chroma.from_documents(texts, embeddings)retriever = db.as_retriever()global qa
查询索引并检查响应:
query = "Compare indian constitution's approach to secularism withthat of other countries?"result = db.query(query)print(result)

查询将按语义搜索数据,并检索对查询的相应响应。
当然,也可以通过langchain使用 RetrievalQA 模块进行链接,这里我们也将使用cohere的LLM:
from langchain.llms import Coherefrom langchain.chains import RetrievalQAqa = RetrievalQA.from_chain_type(llm=Cohere(model="command-xlarge-nightly",temperature=temp_r,cohere_api_key=st.secrets["cohere_apikey"],),chain_type="stuff",retriever=retriever,return_source_documents=True,chain_type_kwargs=chain_type_kwargs,)
上面显示的代码是 QnA Streamlit 应用程序的一部分。源代码和数据集可在[此处](https://github.com/Suhaib-88/MyDocumentor)获得。
三、LlamaIndex 与 LangChain 的最佳用例
3.1 LlamaIndex:
-
构建具有特定知识库的基于查询和搜索的信息检索系统。
-
开发一个 QnA 聊天机器人,该聊天机器人只能提供相关信息块作为对用户查询的响应。
-
大型文档摘要、文本补全、语言翻译等
3.2 LangChain:
-
构建端到端对话式聊天机器人和 AI 代理
-
将自定义工作流集成到LLMs
-
扩展 API 和其他数据源的数据连接选项LLMs。
3.3 Langchain 和 LlamaIndex 的组合用例:

-
构建专家 AI 代理:LangChain 可以集成多个范围的数据源,而 LlamaIndex 可以由于相似性语义搜索功能而策划、总结和生成更快的响应。
-
高级研发工具:使用LangChain的链来同步管理工具和工作流程,同时使用LlamaIndex有助于生成更符合上下文的感知LLM并获得最相关的响应。
3.4 LlamaIndex vs LangChain:选择正确的框架
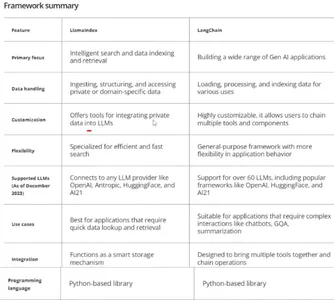
图片来自:https://www.youtube.com/watch?v=1eym7BTnuNg
框架选择需要开率如下几个问题:
-
项目要求是什么?比如:索引、查询搜索和检索应用程序,我们可以选择 LlamaIndex。但是对于我们需要集成自定义工作流程的应用程序,那么LangChain是更好的选择。
-
它的使用简单性和可访问性如何?虽然 LlamaIndex 提供了更简单的界面,但 LangChain 需要更深入地了解 NLP 概念和组件。
-
您想进行多少定制?LangChain具有模块化设计,便于定制和工具集成,但是,LlamaIndex更像是一个基于搜索和检索的框架。
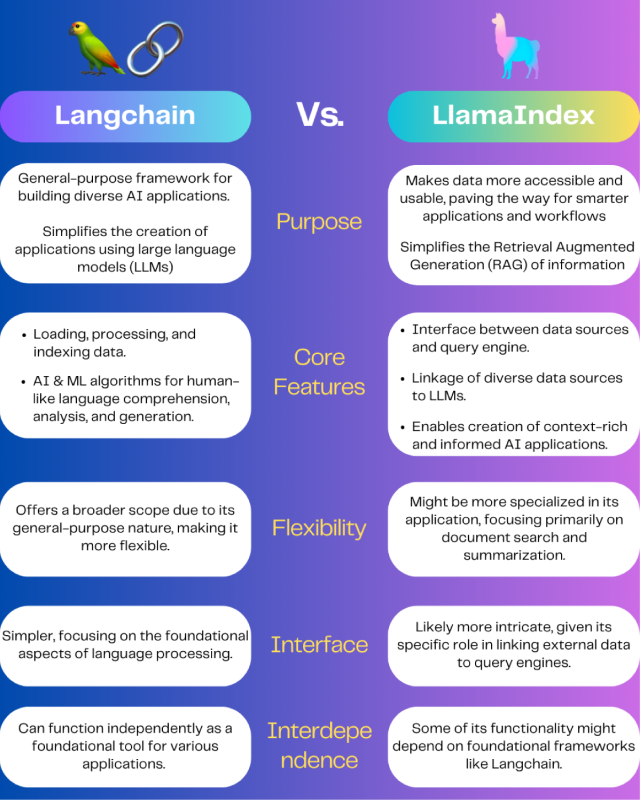
四、结论
LlamaIndex 和 LangChain 对于想要构建基于自定义LLM的应用程序的开发人员来说都是非常有用的框架。LlamaIndex 的 USP 具有卓越的搜索和检索功能,为用户提供简化的索引和查询解决方案。LangChain的独特卖点在于其模块化设计和可集成性,可与LLM空间中的各种工具和组件集成。
如果您在两者之间做出选择时处于两难境地,那么请考虑问自己一些问题,例如项目要求是什么?它的使用简单性和可访问性如何?您想进行多少定制?
如果您想在更广泛的框架中使用多种工具,LangChain 是最适合的。例如具有多任务处理能力的人工智能智能代理。
但是,如果您的目标是构建一个智能搜索和检索系统,那么请选择 LlamaIndex。它的功能在于索引和检索信息,因此使用 LlamaIndex 构建深度数据浏览器应用程序LLMs成为可能。
五、FAQs
Q1:LlamaIndex 和 LangChain 在主要关注点上有何不同?
A1:LangChain的主要关注点是开发和部署LLMs,以及使用微调方法的LLMs定制。然而,LlamaIndex旨在提供端到端的ML工作流程,以及数据管理和模型评估。
Q2:哪个平台更适合机器学习初学者?
A2:LlamaIndex 因其简单直观的实现而更适合初学者。与此相反,LangChain需要对LLMsNLP概念有更深入的理解。
Q3:我可以同时使用 LlamaIndex 和 LangChain 吗?
A3:是的,可以结合这两个平台的强大功能为您的用例开发解决方案。LlamaIndex 可以负责数据预处理和初始模型训练阶段,而 LangChain 可以促进微LLM调、工具集成和部署。
Q4:我应该为我的自定义LLM应用程序使用哪个框架?
A4:LangChain适用于依赖于自然语言处理任务和与外部数据的复杂交互的用例,例如文本摘要、情感分析、对话式AI机器人以及任何需要高级语言模型功能的应用程序。相比之下,LlamaIndex 更适合需要与外部数据进行一般交互的任务(快速数据查找和检索,如问答聊天机器人)。
Q5:使用LlamaIndex或LangChain有什么限制吗?
A5:LlamaIndex 不太适合高度专业化的 NLP 任务。相反,LangChain可能被过度限定,无法解决并不真正需要高级语言模型功能的机器学习工作流。
推荐学习资料:
[1] https://github.com/kyrolabs/awesome-langchain
[2] https://github.com/run-llama/
[3] https://lmy.medium.com/comparing-langchain-and-llamaindex-with-4-tasks-2970140edf33
[4] https://www.youtube.com/watch?v=KmQOlg5YfU0&list=PLZoTAELRMXVOQPRG7VAuHL--y97opD5GQ&pp=iAQB
[5] https://www.youtube.com/watch?v=1eym7BTnuNg&list=PLZoTAELRMXVNOWh1SDXt5NFujQMOt-CWy&pp=iAQB
原文地址:https://blog.csdn.net/wshzd/article/details/140572812
免责声明:本站文章内容转载自网络资源,如本站内容侵犯了原著者的合法权益,可联系本站删除。更多内容请关注自学内容网(zxcms.com)!